医療統計ソフトではよくRが使われています。
しかし医療職はプログラミングの専門化ではないので「Rコマンダー」や「EZR」というソフトを使うことが多いです。
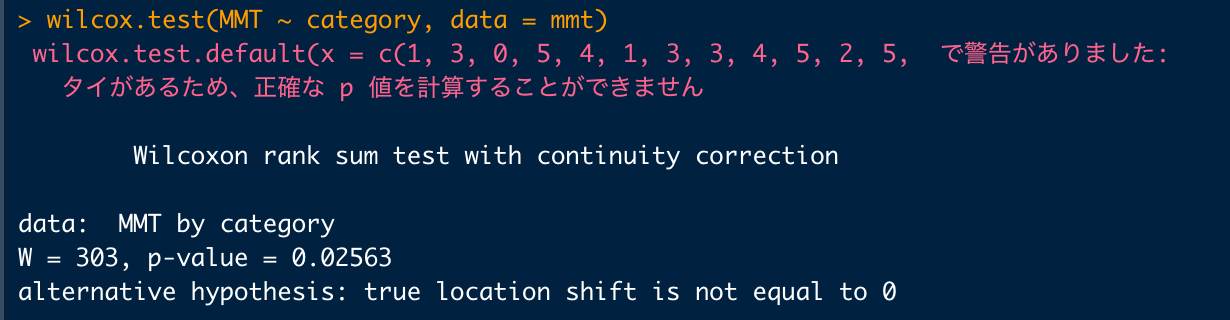
RやEZRでマン・ホイットニーのU検定(Mann-Whitney U 検定)を行うにはwilcox.test()を使うのですが、「タイがあるため、正確な p 値を計算することができません」という警告が出ることがあります。
いつもこれでいいのか?悩むので情報を整理してみました。
こういった警告が出ます
タイがあるため、正確な p 値を計算することができません
cannot compute exact p-value with ties
タイとは同じ数値
タイ(ties)とは同じ数値(同順位)のことを示します。
タイがないデータ:1,2,4,5,7,10,11,12
タイがあるデータ:1,2,2,4,6,6,6,7,9,11
詳細は成書に譲りますがMann-Whitney U 検定は平均ではなくデータを少ない順に並べてデータに順位を付け計算するため、同順位があるとそれをどう計算するかといった問題や様々な対処法が出てきます。
タイに対しての対処法と今回の目的
タイに対処する方法としてcoinパッケージのwilcox_test()があります。
wilcox_test関数の使い方や解釈の仕方は【4-2】RでMann-Whitney U 検定を行う方法で紹介しました。
ただwilcox.testにも設定がいくつかあり、coinパッケージのwilcox_testとどこが同じで、どこが違うのかが気になりましたのでいくつかシュミレーションをしてみます。
使用するパッケージ
# Mann-Whitney U 検定を行うためにcoinパッケージのインストール
# 1度でもしていればしなくてOK
install.packages("coin")
# もしtidyverseパッケージをインストールしていなければインストール。
# 1度でもしていればしなくてOK
install.packages("tidyverse")
# パッケージの読み込み
library(coin)
library(tidyverse)
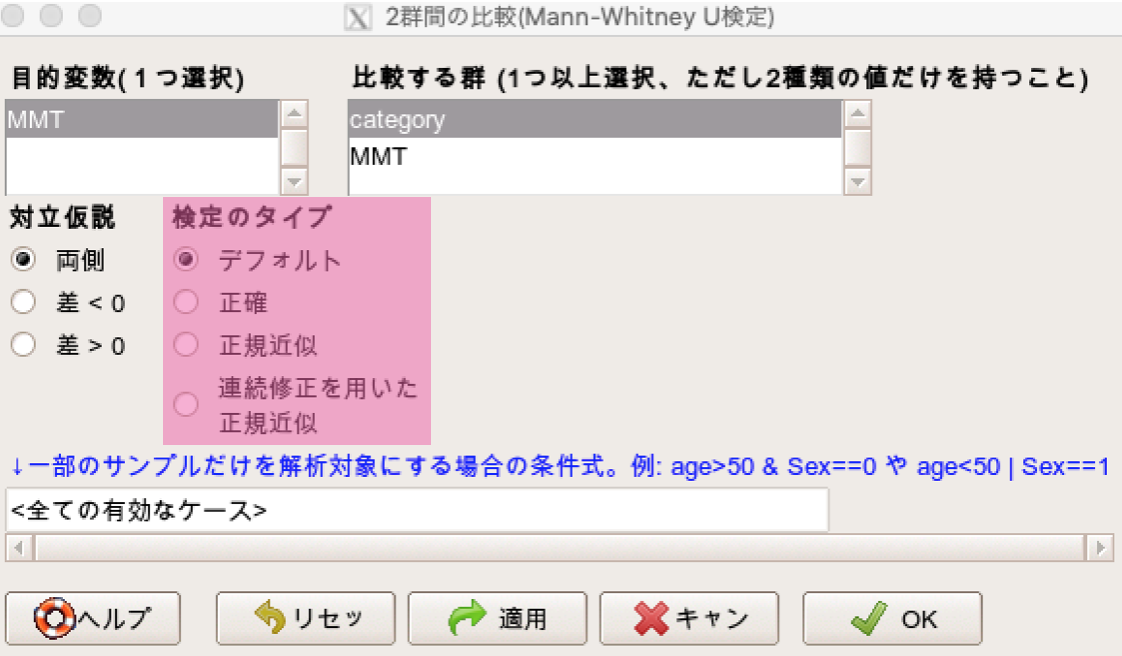
wilcox.testの設定(EZRも含む)
wilcox.test()にはいくつか設定があるのですがその中の2つを紹介します。
exact = TRUE or FALSE
logical indicating whether an exact p-value should be computed.
(wilcox.testのhelpより)
正確なp値を計算するかどうか?
しかしexact = TRUEにしてもタイがあると正確なp値を計算してくれず警告が出ます。
correct = TRUE or FALSE
a logical indicating whether to apply continuity correction in the normal approximation for the p-value.
(wilcox.testのhelpより)
p値の正規近似に連続性補正を適用するかどうか?
wilcox.testのデフォルトは?
これもwilcox.tstのヘルプを確認すると出てきます。
これを見るとexact = NULL, correct = TRUEとなっています。
?wilcox.test.default
wilcox.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, exact = NULL, correct = TRUE,
conf.int = FALSE, conf.level = 0.95, ...)
そして気になるのがDetails。
症例数でデフォルトの設定が自動で切り替わるようです。
By default (if exact is not specified), an exact p-value is computed if the samples contain less than 50 finite values and there are no ties. Otherwise, a normal approximation is used.
デフォルトでは(exactが指定されていない場合)、サンプルに含まれる有限値が50未満で、同順位がない場合、正確なp値が計算されます。それ以外の場合、通常の近似が使用されます。(google翻訳)
coinパッケージのwilcox_testの設定
wilcox_testにもいくつか設定がありますがここでは1つ紹介します。
?wilcox_test
distribution="exact"
これをつけると正確なp値を計算します。
シュミレーションしてみる
これでwilcox.test, wilcox_testでは7つのパターンが考えられます。
wilcox.test
1.何も入力しない(デフォルトの設定)←EZRのデフォルト
2.exact = TRUE, correct = TRUE
3.exact = FALSE, correct = TRUE ← EZRの連続修正を用いた正規近似
4.exact = TRUE, correct = FALSE ← EZRの正確
5.exact = FALSE, correct = FALSE ← EZRの正規近似
wilcox_test
6.何も入力しない(デフォルトの設定)
7.distribution="exact"
この7つの設定でタイの有無、サンプルサイズの違いで結果がどうなるかをシュミレーションします。
タイのないデータでのシュミレーション
今回は1〜2nの数をランダムにn個ずつa群,b群に割り振り検定をかけてみます。
ランダムなので有意差は出ないでしょうがまれに出るかもしれません。
map.dfrを使ってnの数変える予定なのでtidyverseパッケージを使います。
non_ties_p_list <- map_dfr(c(3,5,seq(10,40,10),48:52,seq(60,100,10)), function(n){
set.seed(2019)
a <- sample(seq(1,n*2), size = n, replace = FALSE)
b <- seq(1,n*2)[-a]
value <- c(a, b)
cat <- c(rep("a", n), rep("b", n))
dat <- data.frame(value, cat)
wilcox_default <- wilcox.test(value ~ cat, data = dat)
wilcox_TT <- wilcox.test(value ~ cat, exact = TRUE, correct = TRUE, data = dat)
wilcox_FT <- wilcox.test(value ~ cat, exact = FALSE, correct = TRUE, data = dat)
wilcox_TF <- wilcox.test(value ~ cat, exact = TRUE, correct = FALSE, data = dat)
wilcox_FF <- wilcox.test(value ~ cat, exact = FALSE, correct = FALSE, data = dat)
coin_default <- wilcox_test(value ~ cat, data = dat)
coin_exact <- wilcox_test(value ~ cat, distribution = "exact", data = dat)
list(n = n*2,
wilcox_default = round(wilcox_default$p.value, 5),
wilcox_TT = round(wilcox_TT$p.value, 5),
wilcox_FT = round(wilcox_FT$p.value, 5),
wilcox_TF = round(wilcox_TF$p.value, 5),
wilcox_FF = round(wilcox_FF$p.value, 5),
coin_default = round(pvalue(coin_default), 5),
coin_exact = round(pvalue(coin_exact), 5)
)
})
knitr::kable(non_ties_p_list)
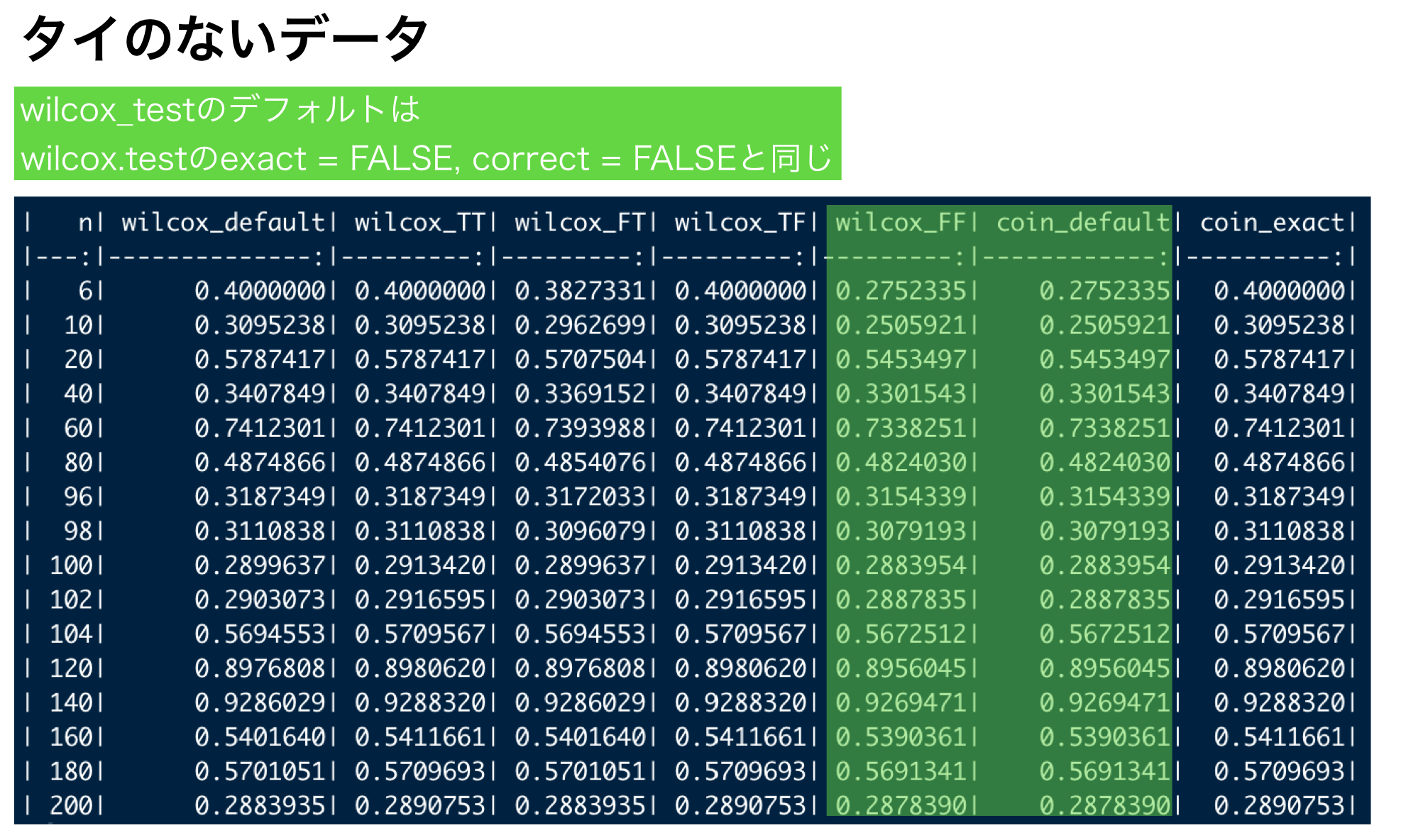
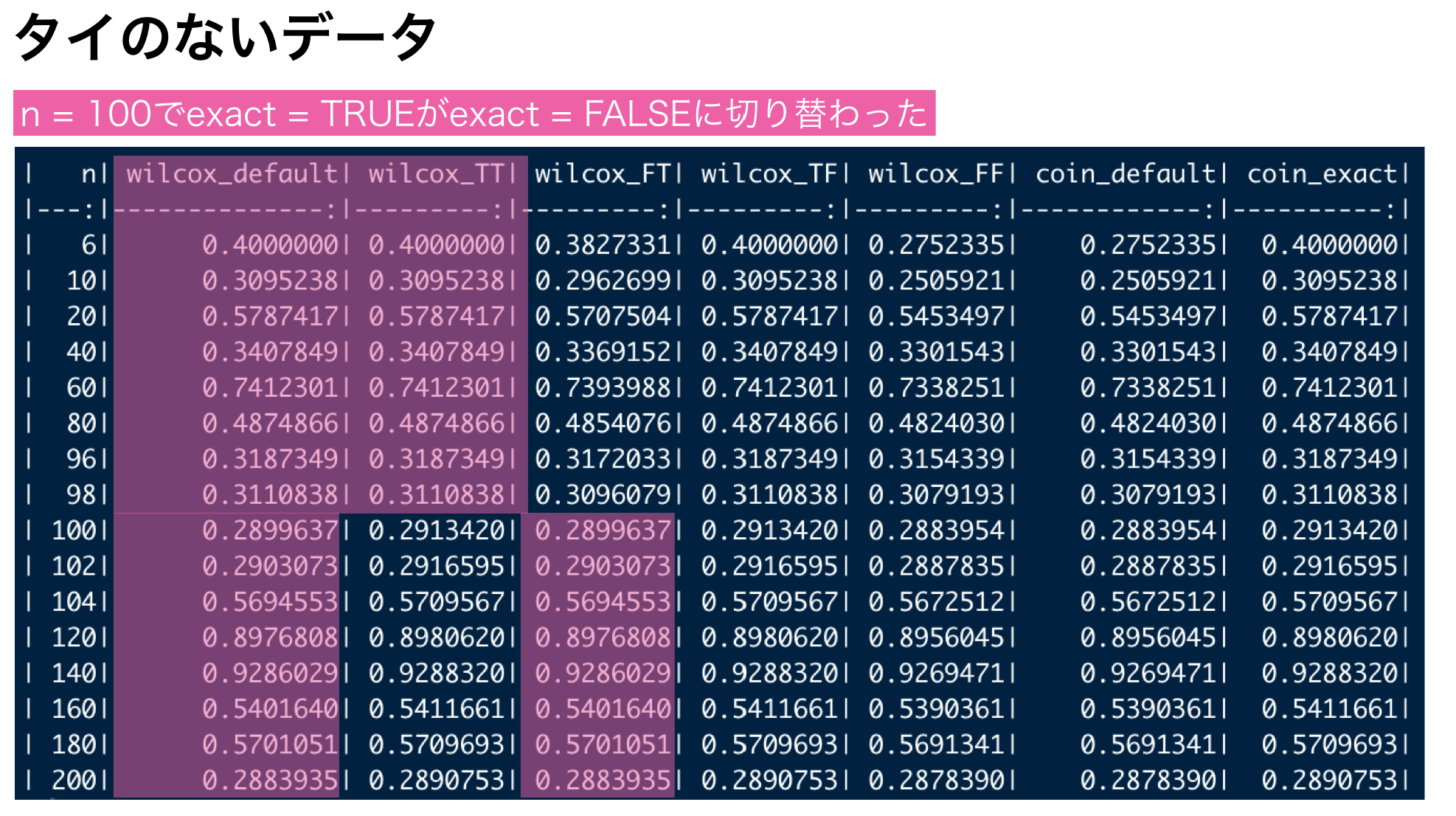

具体的なn数をシュミレーション
シュミレーションではa群50, b群50のデータで設定が切り替わりました。
ただこれでは両方とも50以上なのかどちらかが50以上なのか合計50以上なのかわかりません。
そこでn数の設定を変えてみます。
non_ties_p_list_n_change <- map_dfr(c(seq(30,60,2)), function(n){
set.seed(2019)
a <- sample(seq(1,n*2), size = n+10, replace = FALSE)
b <- seq(1,n*2)[-a]
value <- c(a, b)
cat <- c(rep("a", length(a)), rep("b", length(b)))
dat <- data.frame(value, cat)
wilcox_default <- wilcox.test(value ~ cat, data = dat)
wilcox_TT <- wilcox.test(value ~ cat, exact = TRUE, correct = TRUE, data = dat)
wilcox_FT <- wilcox.test(value ~ cat, exact = FALSE, correct = TRUE, data = dat)
wilcox_TF <- wilcox.test(value ~ cat, exact = TRUE, correct = FALSE, data = dat)
wilcox_FF <- wilcox.test(value ~ cat, exact = FALSE, correct = FALSE, data = dat)
coin_default <- wilcox_test(value ~ as.factor(cat), data = dat)
coin_exact <- wilcox_test(value ~ as.factor(cat), distribution = "exact", data = dat)
list(n = paste0("a=",length(a), ", b=", length(b)),
wilcox_default = wilcox_default$p.value,
wilcox_TT = wilcox_TT$p.value,
wilcox_FT = wilcox_FT$p.value,
wilcox_TF = wilcox_TF$p.value,
wilcox_FF = wilcox_FF$p.value,
coin_default = pvalue(coin_default),
coin_exact = pvalue(coin_exact)
)
})
knitr::kable(non_ties_p_list_n_change)

タイのあるデータでシュミレーション
今度はタイのあるデータでシュミレーションします。
aとbで違うポワソン分布からn個ずつ抽出して比べてみます。
ties_p_list <- map_dfr(c(3,5,seq(10,40,10),48:52,seq(60,100,10)), function(n){
set.seed(2019)
a <- rpois(n, 4)
set.seed(2019)
b <- rpois(n, 5)
value <- c(a, b)
cat <- c(rep("a", n), rep("b", n))
dat <- data.frame(value, cat)
wilcox_default <- wilcox.test(value ~ cat, data = dat)
wilcox_TT <- wilcox.test(value ~ cat, exact = TRUE, correct = TRUE, data = dat)
wilcox_FT <- wilcox.test(value ~ cat, exact = FALSE, correct = TRUE, data = dat)
wilcox_TF <- wilcox.test(value ~ cat, exact = TRUE, correct = FALSE, data = dat)
wilcox_FF <- wilcox.test(value ~ cat, exact = FALSE, correct = FALSE, data = dat)
coin_default <- wilcox_test(value ~ cat, data = dat)
coin_exact <- wilcox_test(value ~ cat, distribution = "exact", data = dat)
list(n = n*2,
wilcox_default = wilcox_default$p.value,
wilcox_TT = wilcox_TT$p.value,
wilcox_FT = wilcox_FT$p.value,
wilcox_TF = wilcox_TF$p.value,
wilcox_FF = wilcox_FF$p.value,
coin_default = pvalue(coin_default),
coin_exact = pvalue(coin_exact)
)
})
knitr::kable(ties_p_list)


結果
今回は以下の結果になりました。
- wilcox.test(EZR)のデフォルトではタイがなくそれぞれ50未満のデータなら正確な値が計算される
- データが多くてもタイがなければwilcox.testの
exact = true(EZRの正確)で正確な値が計算される - タイがあればデータ数に関わらずwilcox.test(EZR)のデフォルトや
exact = TRUEにすると正確な値で計算されず警告を出し、correct = TRUEのみの設定で計算される - coinパッケージwilcox_testの
distribution="exact"だと正確な値が出る。
追記
ただ必ず正確な計算をしないといけないか?ということに関しては議論があるようです。そこに関しては以下のサイトをご参照ください。
Wilcoxon-Mann-Whitney検定(WMW検定)
wilcox.test と wilcox_test 前者だったら残念ですね!
【4-2】RでMann-Whitney U 検定を行う方法