はじめに#
今回は主成分分析を勉強し直したのでまとめていきます。
主成分分析自体は前にも勉強したことあったのですが、分散共分散行列から固有値ベクトル算出して次元圧縮するであったり、scikit-learnを使って実装くらいの知識しかありませんでした。
しかしなぜ分散共分散行列の固有値から軸を求められるのか等、知らなかったので私なりに初歩的なところから計算上での理論をまとめてみることにしました。(私は忘れやすいので)
そして最後は理論をもとにpythonで実装して見ました。
よければ最後までお付き合いください。
主成分分析とは(概要)#
まず主成分分析についてと流れを簡単に説明します。
主成分分析とはデータの次元が大きいときに次元を圧縮して見やすくするために使用される手法です。
下図のようにある方向に軸を取りその軸に垂直に点を落としてみると効率よく2次元データを1次元で表すことができます。
もちろん軸と実際の点との距離(各点から伸びる線)の分が持つ情報は落ちてしまいます。
そのため最も情報が落ちないように分散が最大になるように軸を決めます。(詳しくは後ほど)
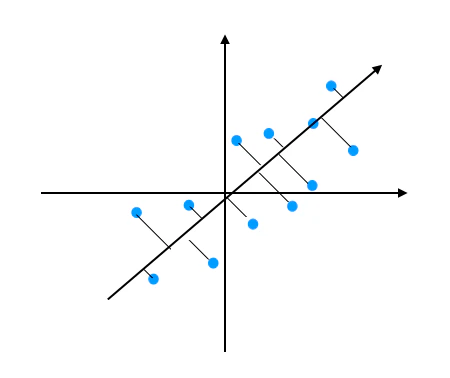
今回は2次元データを1次元にしていますが、高次元のデータをこのように圧縮することで私たちにも解釈しやすくなったり、分類の精度をあげたりすることができます。
具体例##
具体的な例を考えます。
ある5人の5教科の成績が
| 名前 | 国語 | 社会 | 英語 | 算数 | 理科 |
|---|---|---|---|---|---|
| A | 60 | 70 | 70 | 40 | 30 |
| B | 70 | 60 | 80 | 30 | 30 |
| C | 40 | 20 | 30 | 70 | 80 |
| D | 30 | 20 | 40 | 80 | 80 |
| E | 30 | 30 | 30 | 80 | 70 |
だったとします。明らかに偏ってますが...
この人たちの傾向はどのようなものか考えたとき一つの手段としてグラフ化があります。
しかし5次元のデータに対してプロットをするときは図示や理解共になかなか難しいです。
ちなみにこれを3次元空間+色(赤具合と青具合)で表すと次のようになりました。
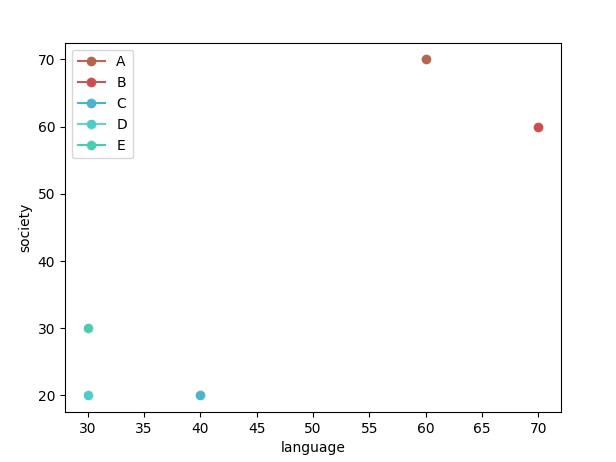
やはり、このグラフでは何を言っているのかわかりにくいかと思います。(今回は5教科であるためわからないこともないのですが、これがもしよくわからないデータの集まりだとあたりをつけるのが難しいです)
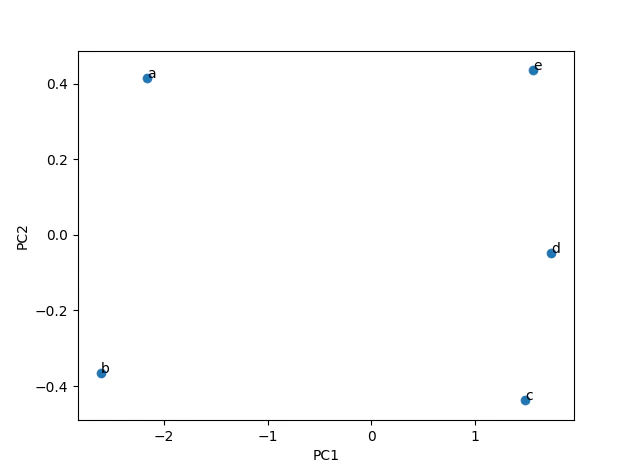
今度はこれを主成分分析で次元圧縮して2次元で図にしてみると次のようになりました。
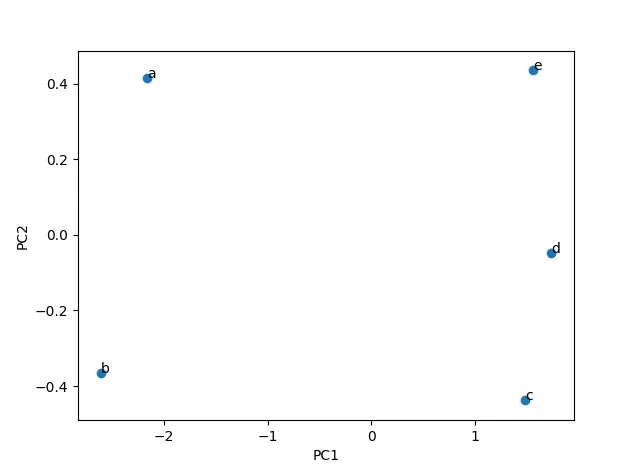
(PCとは主成分:principal componentの事です)
主成分分析の結果のそれぞれの軸が何を表しているかの解釈は私たちが行わなければなりません。
今回の例の場合はPC1は理系科目が高い人は高い値、理系科目が不得意な人が低い値を取っているように感じられます。そのためPC1は理系の得意度を示しているのではないかと解釈します。
PC2ですが、こちらは正直何を示しているのか私には解釈できません(これからもうちょっと解釈の仕方は勉強していきます)。しかしここで寄与率をみてみます。
寄与率とは各軸がどの程度元のデータを説明できているか、の値です。
詳しくは先で説明しますが、今回の寄与率は
| PC | 寄与率 |
|---|---|
| PC1 | 9.518791e-01 |
| PC2 | 3.441020e-02 |
| PC3 | 1.275504e-02 |
| PC4 | 9.556157e-04 |
| PC5 | 8.271560e-35 |
となり、PC1の成分で95%説明できていて、PC2で3.4%説明できている事がわかります。
そのためPC1だけでほとんどこのデータが説明できているのかもしれません。
今回はイメージしやすいように文系科目理系科目で点数を偏らせて示しましたが、このように主成分分析は次元が多いデータをイメージしやすいようにする分析方法の一つです。
今回はこの主成分分析を私のような人でも理解できるように説明していきたいと考えています。
主成分分析とは(理論)#
主成分分析の理論を細かく見ていきます。上の図は前述したように2次元のデータを新しい1次元のデータに変換しています。軸とデータ点の距離が大きいほどデータの損失があると考えられるため分散が最も大きい方向を求める必要があります。(一番分散が大きい方向が第一主成分)
この方向はどのように見つけるかと言うと分散共分散行列の一番大きい固有値に対応する固有ベクトルを求めれば良いのですが、なぜそれで考えられるのか見ていきたいと思います。
まず1点だけを考えてみます。
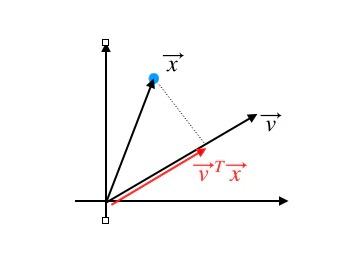
あるデータ点と軸となるベクトルを次のように定義します。
\vec{x}= \left[ \begin{array}{r} x_1 \\\ x_2 \end{array} \right] \\\
\vec{v}= \left[ \begin{array}{r} v_1 \\\ v_2 \end{array} \right] \\\
ただし\|\vec{v}\|=1 \\\
するとベクトル$\vec{x}を$ベクトル$\vec{v}$軸に垂直に落とした時の長さは
\vec{v}^\mathrm{T}\vec{x}=\left[ \begin{array}{r} v_1 & v_2 \end{array} \right]\left[ \begin{array}{r} x_1 \\\ x_2 \end{array} \right]=v_1 x_1+v_2 x_2
で示されます。
ここで余談となるのですが、長さが$\vec{v}^\mathrm{T}\vec{x}$で示される証明を行います。
気になる人だけみていただければと思います。
まずベクトル$\vec{a}$とベクトル$\vec{a}$を$\theta$回転させたベクトル$\vec{b}$を次のように定義します。
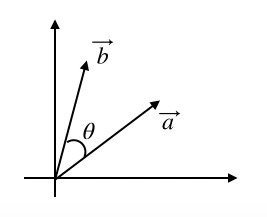
$\vec{a}= \left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$
$\vec{b}= \left[ \begin{array}{r} b_1 \\ b_2 \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$
基本的なことですがベクトル$\vec{a}$にかけられている
$\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]$
はベクトル$\vec{a}$を$\theta$回転させる行列です。
ばぜこの行列で回転する変換ができる理由は加法定理によって証明することができます。加法定理による証明
ベクトルの長さをrとするとベクトル$\vec{a}$とベクトル$\vec{b}$は次のように表される。
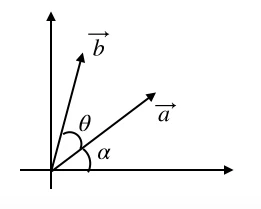
$\vec{a}= \left[ \begin{array}{r} rcos\alpha \\ rsin\alpha \end{array} \right]$
$\vec{b}= \left[ \begin{array}{r} rcos(\alpha + \theta) \\ rsin(\alpha + \theta) \end{array} \right]=\left[ \begin{array}{r} rcos(\alpha)cos(\theta) - rsin(\alpha)sin(\theta) \\ rsin(\alpha)cos(\theta)+rcos(\alpha)sin(\theta) \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} rcos(\alpha) \\ rsin(\alpha) \end{array} \right]=\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\vec{a}$
よって証明される。
証明するのはベクトル$\vec{b}$をベクトル$\vec{a}$軸状に垂直に落とした時の長さが等しくなれば良いため
$|\vec{b}|cos\theta=\vec{v}^\mathrm{T}\vec{b}$
が示されれば良いということになります。
ベクトル$\vec{v}$はベクトル$\vec{a}$と同じ方向で大きさが1であるため$\vec{v}=\frac{1}{\sqrt{a_1^2+a_2^2}}\vec{a}$
である。
そのため
$\vec{v}^\mathrm{T}\vec{b}=\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} b_1 \\ b_2 \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} cos\theta&-sin\theta \\ sin\theta & cos\theta \end{array} \right]\left[ \begin{array}{r} a_1 \\ a_2 \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}\left[ \begin{array}{r} a_1 & a_2 \end{array} \right]\left[ \begin{array}{r} a_1cos\theta-a_2sin\theta \\ a_1sin\theta+a_2cos\theta \end{array} \right]$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}(a_1^2cos\theta-a_1a_2sin\theta+a_1a_2sin\theta+a_2^2cos\theta)$
$\quad\ =\frac{1}{\sqrt{a_1^2+a_2^2}}(a_1^2+a_2^2)cos\theta$
$\quad\ =\sqrt{a_1^2+a_2^2}cos\theta$
$\quad\ =|\vec{b}|cos\theta$
よって$\vec{v}^\mathrm{T}\vec{x}$によってベクトル$\vec{x}$をベクトル$\vec{v}上に垂直に落とした時の長さを求めることができる。$
つまり求める$\vec{v}$はデータ点がn個ある時のこの長さ$\vec{v}^\mathrm{T}\vec{x}$の分散が大きくなるベクトルとなります。
$\vec{v}^\mathrm{T}\vec{x}$の分散は
$$\frac{1}{n-1}\sum_{i=1}^{n}\left[\vec{v}^\mathrm{T}(\vec{x_i}-\hat{\mu})\right]^2\ ;=; \vec{v}^{\mathrm{T}}\frac{1}{n-1}\sum_{i=1}^n(\vec{x_i}-\hat{\mu})(\vec{x_i}-\hat{\mu})^\mathrm{T}\vec{v}$$
$(\vec{a}\vec{b})^\mathrm{T}=\vec{a}^{\mathrm{T}} \vec{b}^{\mathrm{T}}$である。
ここでベクトル$\vec{v}$で囲まれ他部分は分散共分散行列の形であるため
$$\Sigma=\frac{1}{n-1}\sum_{i=1}^n(\vec{x_i}-\hat{\mu})(\vec{x_i}-\hat{\mu})^\mathrm{T}\ $$
と置くと
分散は
$$\vec{v}^\mathrm{T}\Sigma\vec{v}$$
と置く事ができる。
つまりこの分散が最大となる方向のベクトル$\vec{v}$を求めるために
$$\max_{v:|v|=1}(\vec{v}^\mathrm{T}\Sigma\vec{v})$$
を考えます。
ここで$\Sigma$は半正定値行列であるため直行行列で対角化する事ができます。
全ての零ベクトルでない $x∈ℝ^n$ について $x^TAx≥0$ が成り立つとき半正定値(positive semidefinite)という
--Horn and Johnson(2013) Definition 4.1.11--
つまり
$$\Sigma\vec{v_i}=\lambda_i\vec{v_i}$$
となる固有ベクトルと固有値を考え
V=[v_1,v_2,...,v_d] \\\
\Lambda=diag(\lambda_1,\lambda_2,...,\lambda_d)
と置いた時
$\Sigma V$とはVベクトルをそれぞれ対応する固有値倍に変換しているため
$$\Sigma V=V\Lambda$$
であり
$V$は直交行列であるので
$$\Sigma = V\Lambda V^\mathrm{T} \quad V^\mathrm{T}\Sigma V=\Lambda$$
これをもとに分散が最大化されるベクトルを求めていきます。
私が参考にした物では以下のように最大化解が一番大きい固有値であると証明されていました。(参考文献[1])
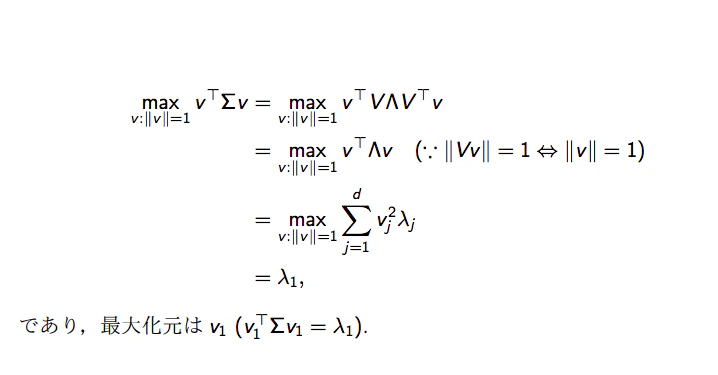
しかし私はこれがいまいち理解できなかったため私なりに考えて見ました。(間違っていればご指摘ください)
計算の簡略化のため2次元の場合を考えます、
まず
\begin{align}
V&=\left[\begin{array}{cc} v_1 & v_2\end{array} \right]=\left[\begin{array}{cc} v_{1x} & v_{2x} \\\ v_{1y} & v_{2y}\end{array} \right] \\\
\vec{v}&=\left[\begin{array}{c} v_x \\\ v_y \end{array}\right] \\\
\Lambda&=\left[\begin{array}{cc} \lambda_1 &0 \\\ 0 & \lambda_2 \end{array}\right]
\end{align}
と置きます。
そしてかっこの中身を式変形していきます。
\begin{align}
\vec{v}^\mathrm{T}\Sigma\vec{v} &= \vec{v}^\mathrm{T}V\Lambda V^\mathrm{T}\vec{v} \\\\
&= \vec{v}^\mathrm{T}\left[\begin{array}{cc} v_{1x} & v_{2x} \\\ v_{1y} & v_{2y}\end{array} \right]\left[\begin{array}{cc} \lambda_1 &0 \\\ 0 & \lambda_2 \end{array}\right] \left[\begin{array}{cc} v_{1x} & v_{1y} \\\ v_{2x} & v_{2y}\end{array} \right]\vec{v} \\\\
&=\vec{v}^\mathrm{T}\left[ \begin{array}{cc} v_{1x}^2\lambda_1+v_{2x}^2 \lambda_2 & v_{1x} v_{1y} \lambda_1 +v_{2x} v_{2y} \lambda_2 \\\ v_{1x} v_{1y} \lambda_1 +v_{2x} v_{2y} \lambda_2 & v_{1y}^2\lambda_1+V_{2y}^2 \lambda_2 \end{array} \right] \vec{v} \\\\
&=\vec{v}^\mathrm{T}\left( \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\lambda_1+\left[ \begin{array}{cc} v_{2x}^2& v_{2x} v_{2y} \\\ v_{2x} v_{2y} &V_{2y}^2 \end{array} \right]\lambda_2\right) \vec{v} \\\\
&=\vec{v}^\mathrm{T} \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\vec{v}\lambda_1+\vec{v}^\mathrm{T}\left[ \begin{array}{cc} v_{2x}^2& v_{2x} v_{2y} \\\ v_{2x} v_{2y} &V_{2y}^2 \end{array} \right]\vec{v}\lambda_2 \\\
\end{align}
$\lambda_1$の項のみを取り出して考えて見ると
\begin{align}
\vec{v}^\mathrm{T} \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\vec{v}\lambda_1&=\left[\begin{array}{c} v_x & v_y \end{array}\right] \left[ \begin{array}{cc} v_{1x}^2 & v_{1x} v_{1y} \\\ v_{1x} v_{1y} & v_{1y}^2 \end{array} \right]\left[\begin{array}{c} v_x \\\ v_y \end{array}\right]\lambda_1 \\\\
&=(v_{1x}^2 v_x^2+2v_{1x}v_{1y}v_xv_y+v_{1y}^2 v_y^2)\lambda_1 \\\\
&=(v_{1x}v_x+v_{1y}v_y)^2\lambda_1 \\\\
&=\left(\left[\begin{array}{c}v_{1x} & v_{1y} \end{array}\right]\left[\begin{array}{c} v_x \\\ v_y \end{array}\right]\right)^2\lambda_1 \\\\
&=\left(\vec{v_1}^\mathrm{T} \vec{v}\right)^2\lambda_1
\end{align}
となる。
つまり
\begin{align}
\max_{v:|v|=1}\left(\vec{v}^\mathrm{T}\Sigma\vec{v}\right) &=\max_{v:|v|=1}\left(\left(\vec{v_1}^\mathrm{T}\vec{v}\right)^2\lambda_1+\left(\vec{v_2}^\mathrm{T}\vec{v}\right)^2\lambda_2\right) \\\
&=\max_{v:|v|=1}\left(\sum_{i=1}^2\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right) \\\
一般化すると \\\
&=\max_{v:|v|=1}\left(\sum_{i=1}^d\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right)
\end{align}
となる。
この時$\vec{v},\vec{v_i}$は単位ベクトルで$\vec{v_1},\vec{v_2},...,\vec{v_d}$は互いに直行している。
そのため、$\vec{v}=\vec{v_i}$の時
$$\max_{v:|v|=1}\left(\vec{v_i}^\mathrm{T}\vec{v}\right)=1$$
となる。(同じ方向の単位ベクトルの内積は1をとる)
同じように$i\neq j$の時
$$\max_{v:|v|=1}\left(\vec{v_j}^\mathrm{T}\vec{v}\right)=0$$
である。(直行するベクトルの内積は0)
つまり最大値をとるときはベクトルvが最大の固有値と対応する固有ベクトルと等しくなるときであるため
$$\max_{v:|v|=1}\left(\sum_{i=1}^d\left(\vec{v_i}^\mathrm{T}\vec{v}\right)^2\lambda_i\right)=\lambda_1$$
となる。
また、同じように2番目に分散の大きい軸を取りたいときは$\vec{v}$を2番目に大きい固有値に対応する固有ベクトルと同じ方向に合わせれば良いという事になります。
分散共分散行列と相関行列#
主成分分析を行う時、分散共分散行列の固有ベクトルをとる時と相関行列の固有ベクトルをとる方法があると聞いた事がある方がいるかと思います。
そもそも相関行列とはデータをそのデータの標準偏差で割ったものの分散共分散行列です。
先に平均も引いてしまって問題ないため、標準化されたデータの分散共分散行列でもあります。
つまりデータを先に標準化(z-score)してしまえば先ほどの理論とやることは同じとなるため、標準偏差の固有ベクトルでも主成分分析できる事がわかると思います。
そのため実際どちらの方法をとっても主成分分析を行う事ができますが、相関行列の固有ベクトルをとった方が良いと言われています。
なぜならデータそのままの分散共分散行列だとデータの単位がバラバラでそこを考慮しなくてはいけないからです。
そのため単位をない状態にして主成分分析を行なった方が良いと言われています。(具体的にどのように影響が出るのかは例で説明できなかったので何か遭遇したら追記したいと思います)
寄与率#
最後に寄与率についてです。
寄与率とはそのデータがどのくらいデータを示しているかを差します。
そしてその値は理論でもお話したように分散の大きさで示す事ができ、分散の大きさはある方向ベクトルを取った時の固有値となりました。
その固有値の割合を求めれば良いため、寄与率PVは
$$PV_i=\frac{\lambda_i}{\sum_{j=1}^{d}\lambda_j}$$
によって求められます。
実装#
それではこの理論を用いて実装して見たいと思います。
ここで使用するデータは最初の概要でも使った5人の成績データを用います。
| 名前 | 国語 | 社会 | 英語 | 算数 | 理科 |
|---|---|---|---|---|---|
| A | 60 | 70 | 70 | 40 | 30 |
| B | 70 | 60 | 80 | 30 | 30 |
| C | 40 | 20 | 30 | 70 | 80 |
| D | 30 | 20 | 40 | 80 | 80 |
| E | 30 | 30 | 30 | 80 | 70 |
まず正解としてscikit-learnのPCAの実装を見て見ます。
実装したところこのようになりました。pandasを使用しているのは私が使い慣れていないための勉強を兼ねているだけです
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
import pandas as pd
# データの作成
name = ['a','b','c','d','e']
a = np.array([60,70,70,40,30])
b = np.array([70,60,80,30,30])
c = np.array([40,20,30,70,80])
d = np.array([30,20,40,80,80])
e = np.array([30,30,30,80,70])
# フレームワークに格納
df = pd.DataFrame([a,b,c,d,e],columns=['language','society','english','math','science'],index=name)
dfs = df.iloc[:,:].apply(lambda x:(x-x.mean())/x.std(),axis=0) #データの標準化
# scikit-learnでのPCAインスタンス化と学習
pca = PCA()
pca.fit(dfs)
feature=pca.transform(dfs)
# 結果の出力
print(pd.DataFrame(feature,columns=["PC{}".format(x+1) for x in range(len(dfs.columns))]).head())
plt.figure()
for i in range(len(name)):
plt.annotate(name[i],xy=(feature[i,0],feature[i,1]))
plt.scatter(feature[:,0],feature[:,1],marker='o')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.show()
print(pd.DataFrame(pca.explained_variance_ratio_,index=["PC{}".format(x+1) for x in range(len(dfs.columns))]))
結果は以下のようになりました。
$python scikit_pca.py
PC1 PC2 PC3 PC4 PC5
0 -2.161412 0.414977 -0.075496 -0.073419 4.163336e-17
1 -2.601987 -0.364980 0.088599 0.064849 4.163336e-17
2 1.479995 -0.437661 -0.290635 -0.037986 4.163336e-17
3 1.727683 -0.047103 0.382252 -0.035840 -1.387779e-17
4 1.555721 0.434767 -0.104720 0.082396 -1.457168e-16
0
PC1 9.518791e-01
PC2 3.441020e-02
PC3 1.275504e-02
PC4 9.556157e-04
PC5 8.271560e-35
続いて理論に基づいて実装して見ました。
クラスとしてMyPCAを定義し、scikit-learnと同様に使えるようにfit()メソッドで学習、transform()メソッドで新しい空間に射影する処理をしています。
クラスの定義以外は前のプログラムの
pca=PCA()
を
pca=MyPCA()
に変更するだけなので省略して、クラスの定義のみ載せていますが、次のようになりました。
# myPCA program
class MyPCA:
e_values = None #固有値の保存
e_covs = None #固有ベクトルの保存
explained_variance_ratio_ = None
def fit(self,dfs):
#pandasデータでもnumpyデータでも使えるようにするための処理
if(type(dfs)==type(pd.DataFrame())):
all_data = dfs.values
else:
all_data=dfs
data_cov=np.cov(all_data,rowvar=0,bias=0) #分散共分散行列処理
self.e_values,self.e_vecs=np.linalg.eig(data_cov) #固有値と固有ベクトルの算出
self.explained_variance_ratio_= self.e_values/self.e_values.sum() #寄与率の計算
def transform(self,dfs):
#pandasデータでもnumpyデータでも使えるようにするための処理
if(type(dfs)==type(pd.DataFrame())):
all_data = dfs.values
else:
all_data=dfs
feature = []
for e_vec in self.e_vecs.T:
temp_feature=[]
for data in all_data:
temp_feature.append(np.dot(e_vec,data)) #内積計算
feature.append(temp_feature)
return np.array(feature).T
そして結果です。
PC1 PC2 PC3 PC4 PC5
0 2.161412 -0.414977 -0.075496 -7.771561e-16 0.073419
1 2.601987 0.364980 0.088599 1.665335e-15 -0.064849
2 -1.479995 0.437661 -0.290635 -4.996004e-16 0.037986
3 -1.727683 0.047103 0.382252 -5.551115e-16 0.035840
4 -1.555721 -0.434767 -0.104720 0.000000e+00 -0.082396
Attribute Qt::AA_EnableHighDpiScaling must be set before QCoreApplication is created.
0
PC1 9.518791e-01
PC2 3.441020e-02
PC3 1.275504e-02
PC4 2.659136e-17
PC5 9.556157e-04
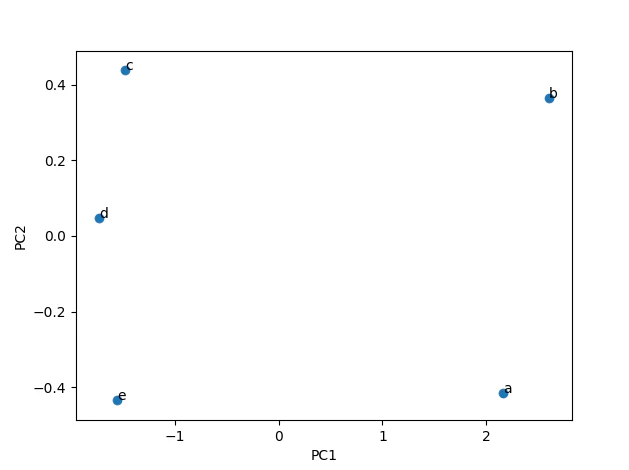
このようになりました。
おそらく固有ベクトルが反転してしまったため正負逆転してしまっているところもありますが、同じような解析結果が出せたかと思います。
終わりに#
今回は主成分分析の理論について個人的備忘録も兼ねて書いて見ました。
証明をところどころ挟んだので読みにくい記事になってしまった感が否めないのですが、私のような人は細かいところが気になって進めないこともあるかと考えできるだけ証明しました。
今回取り上げた主成分分析はscikit-learnで簡単に使えてしまうので中身をあまり理解せず使うのが気持ち悪く感じていたので今回一応理解ができた気がするのでスッキリしました。
ただ、scikit-learnでの実装をのぞいて見たところ特異値分解によって実装しているようです。
ただ対称行列の場合は固有値分解と特異値分解の結果は同じになるようなので、今回のような分散共分散行列や相関行列に適用するときはどちらでもいいのかと感じました。
もし機会があれば一般化以外で特異値分解を使う利点も調べて見たいと思います。
参考文献#
[1]http://ibis.t.u-tokyo.ac.jp/suzuki/lecture/2015/dataanalysis/L7.pdf データ解析 第七回「主成分分析」
[2]https://seetheworld1992.hatenablog.com/entry/2017/03/17/104807 分散共分散行列(と相関行列)は半正定値であることを証明する