はじめに
前の記事からはや3ヶ月、試用期間も終わり本採用を果たした筆者はAIの普及に全力を注いでいます。本採用されたからそんな簡単に解雇されないしめちゃくちゃやってやろ
↓前記事
ポケモンのデータ
みなさんご存知のKaggleでポケモンのデータを見つけたので遊んでみようと思います。見つけた時は何に使うデータなんだと思いましたし、今もよくわかっていません。遊びたい方は以下からどうぞ!
主成分分析されている方もいらっしゃるので、こちらも興味深いです。
データ解析
さて、まずはデータを読み込んで俯瞰してみます。でもあれこれコードを書くのは面倒くさいですよね?そんな時はコレ。てれれれってれ~(某猫型ロボットを思い浮かべながら読んでください)、fasteda〜。
前職の後輩と情報交換をしていたら、こんな便利なライブラリを教えてくれました。ここ1、2年で出てきたライブラリなのであまり情報はないですが、使ってみましょう。
githubはこちら
まずは必要なライブラリのインストールしちゃいましょう。fastedaはあらかじめpip installしてくださいね。
import pandas as pd
import numpy as np
from fasteda import fast_eda
df = pd.read_csv('pokemon.csv')
df
とりあえずデータを見てみると、801匹のポケモンデータですね。筆者はルビサファで止まっている30代のおっさんなので半分以上わかりません。
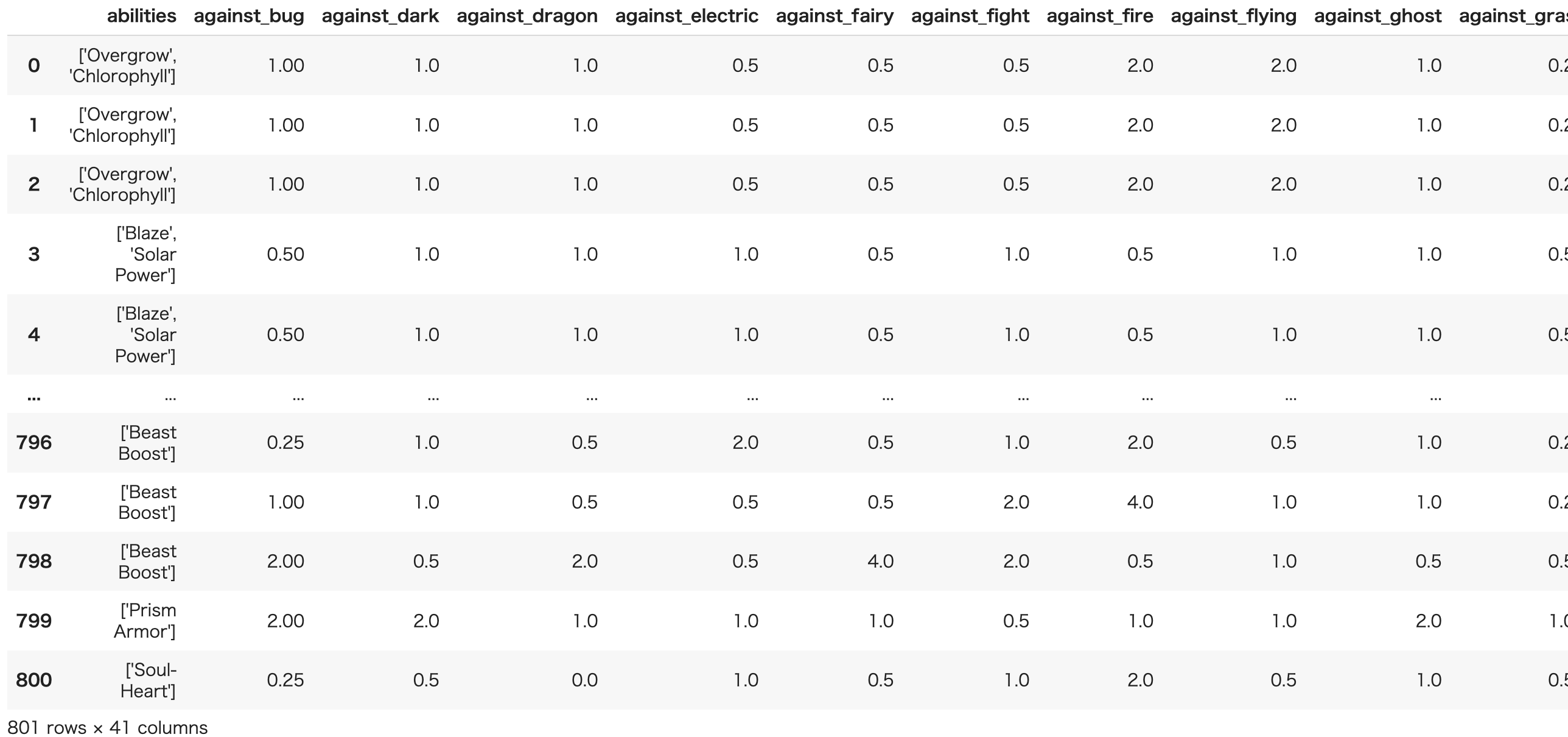
Kaggleのデータセットの説明を見ると、カラムは以下のようになっているそうです。DeepLにぶち込んだのをそのまま載せていますので悪しからず。ポケデックスってなんでしょう、ポケモン図鑑のことですかね。あと幸福度はなつき度のことみたいです。
・name: ポケモンの英語名
・japanese_name: そのポケモンのオリジナルの日本語名
・pokedex_number: ポケデックスに登録されている番号。
・percentage_male: 種族に占めるオスの割合。性別がない場合は空白。
・type1: ポケモンの主なタイプ
・type2: ポケモンの二次タイプ
・classification サン・ムーンのポケデックスに記載されているポケモンの分類。
・height_m: ポケモンの身長(メートル
・weight_kg: ポケモンの重さ(キログラム
・capture_rate: ポケモンの捕獲率
・base_egg_steps: そのポケモンのタマゴを孵化させるのに必要な歩数
・abilities: そのポケモンが持つことのできる能力の文字列化されたリスト。
・experience_growth: ポケモンの経験値成長率
・base_happiness: そのポケモンの基本幸福度
・against_? 特定のタイプの攻撃に対して受けるダメージの量を表す18の特徴
・hp :ポケモンの基本HP
・attack: ポケモンの基本攻撃
・defense: そのポケモンの基本防御力
・sp_attack: そのポケモンの基本特攻
・sp_defense: そのポケモンの基本特防
・speed:そのポケモンの基本素早さ
・generation そのポケモンが最初に登場した世代の番号。
・is_legendary: そのポケモンが伝説であるかどうかを表す。
さて、fastedaで爆速でデータを解析してみましょう。以下の一行で終わりです。
fast_eda(df, target='is_legendary')
targetはgithubによると2クラス分類で最適に動作するみたいです。今回は伝説かそうでないかの2クラス分類になるのでtargetも設定しておきましょう。そうでない場合はデータフレームだけ渡せばokです。
target: string, optional | target variable of (binary) classification dataset, works best with 2 classes (not recommended when there are > 3 classes). Enables hue of target variable in pairplot and hist_box_plot.
コードを実行すると以下のようなデータを出してくれます。
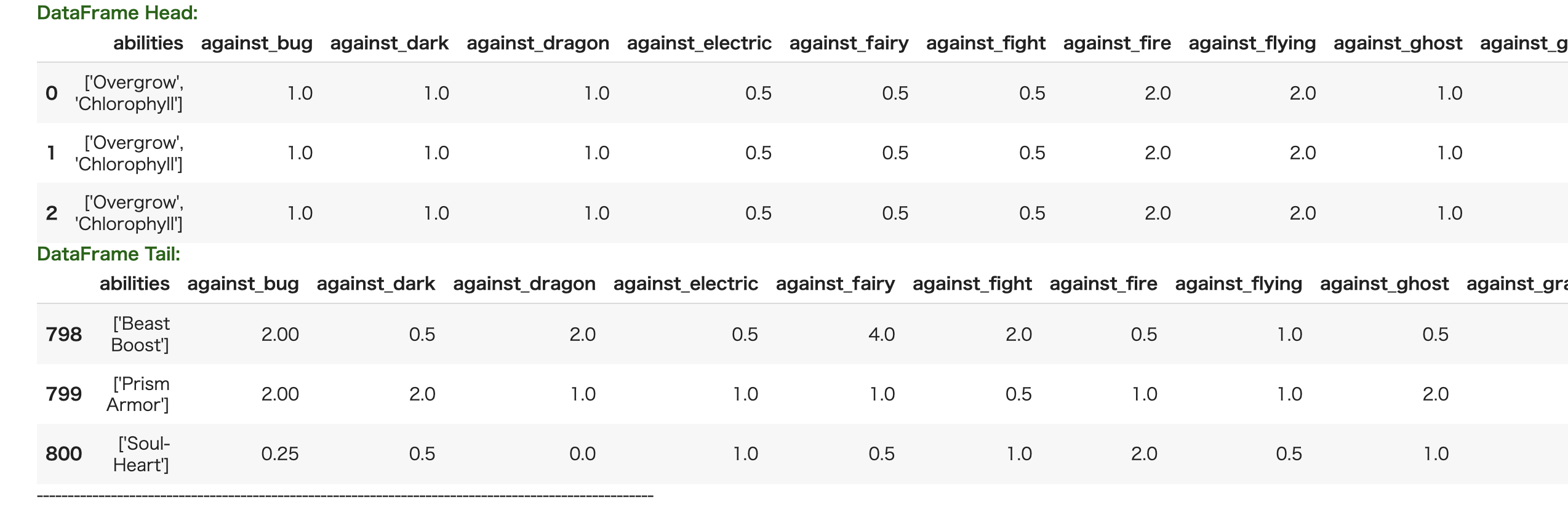
まずはデータの上三行と下三行です。
続いて欠損値の数と可視化もしてくれます。

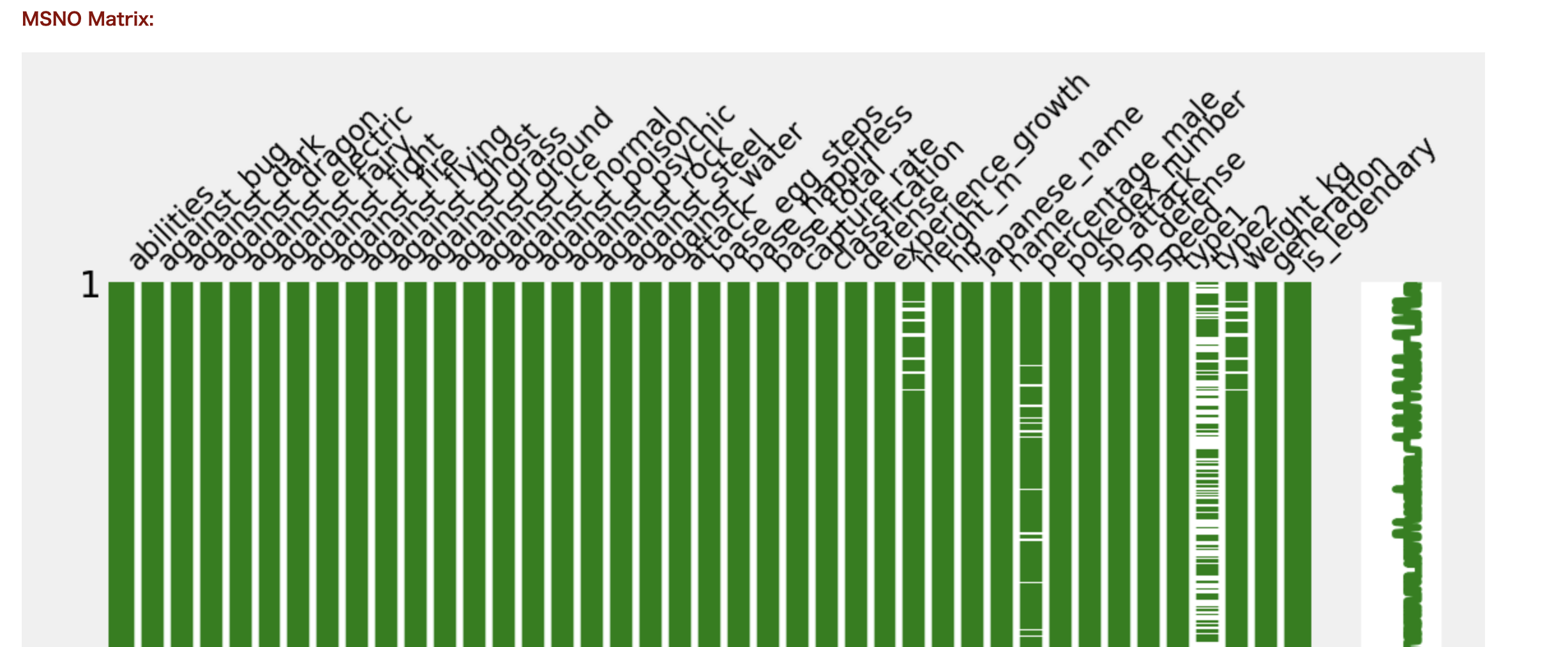
type2に欠損値が多いので、一つのタイプしか持たないポケモンが多いと予想できます。
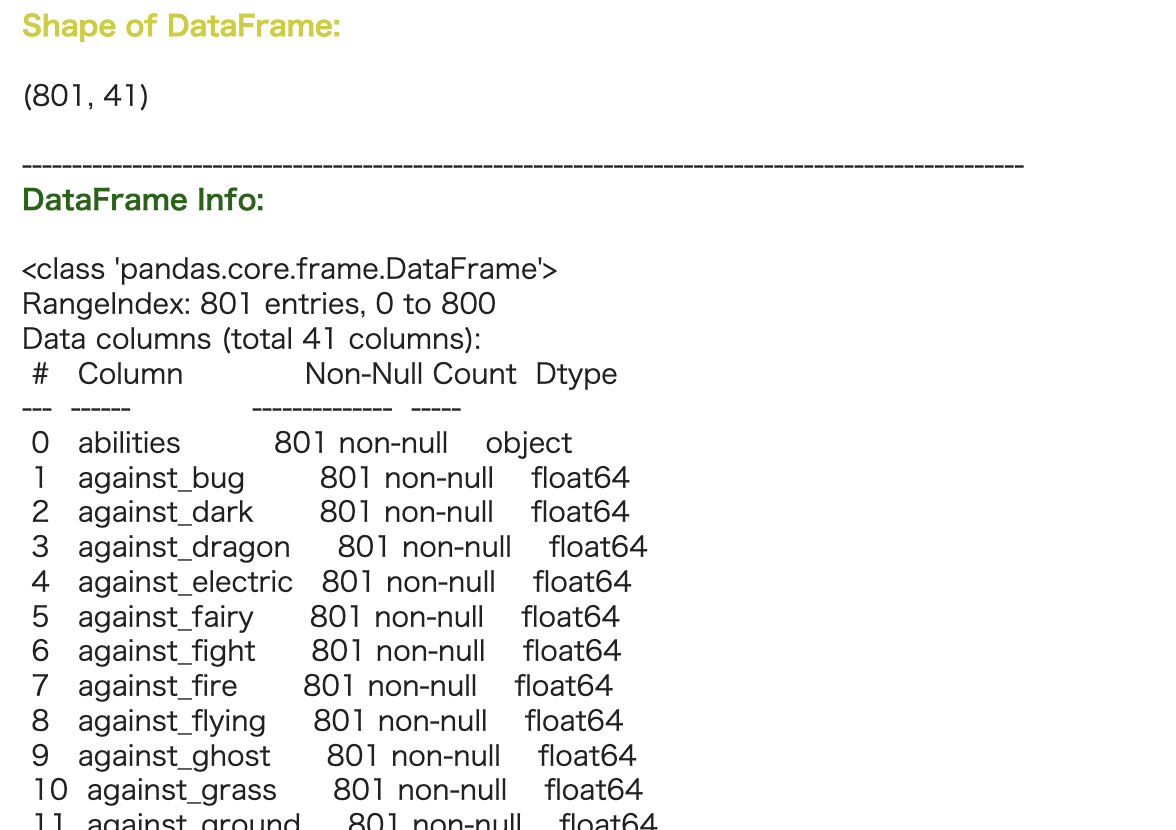
続いてShapeとinfoですね。
続いて統計量です。
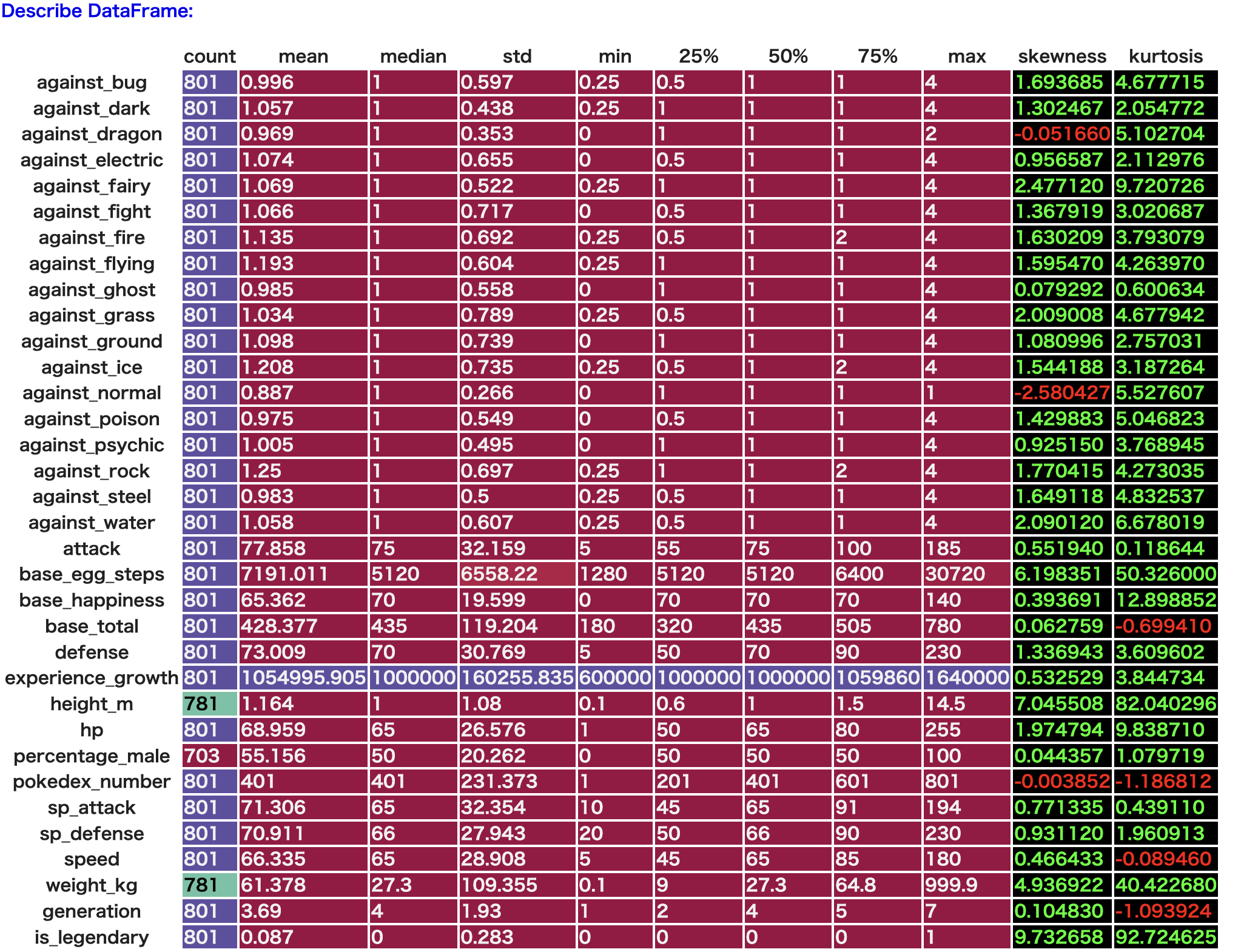
skewnessは歪度と言って、正規分布からどれだけ歪んでいるかの指標で、0だと正規分布とみなされます。
kurtosisは尖度といい、名前の通りどれだけ分布の形が尖っているかの指標で、数値が大きいほど尖っています。is_legendaryはもちろんバチボコに尖ってますね。あとはheight_mも尖っているので、ポケモンの体長はみんな似たり寄ったりということなんですかね。
続いてヒートマップです。
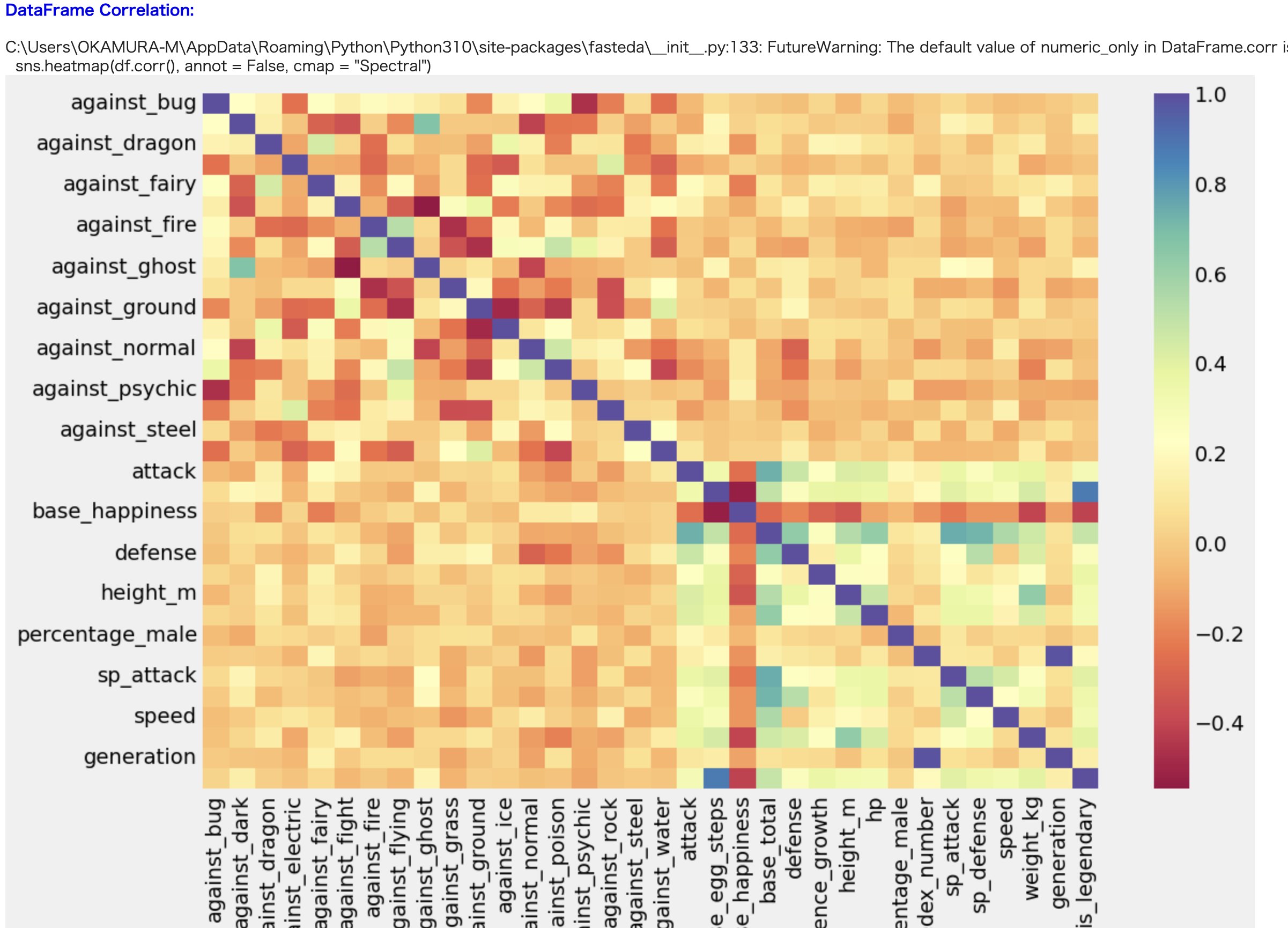
is_legendaryと相関が高そうなのは卵の歩数ですね。あとは体重とかすばやさは攻撃力とそこまで相関はないんですね(速度は重さ・・・光の速度で蹴られたことはあるかい?と某海軍大将が言っていたのですが)。
あとはヒストグラムとかカウントプロットとかです。
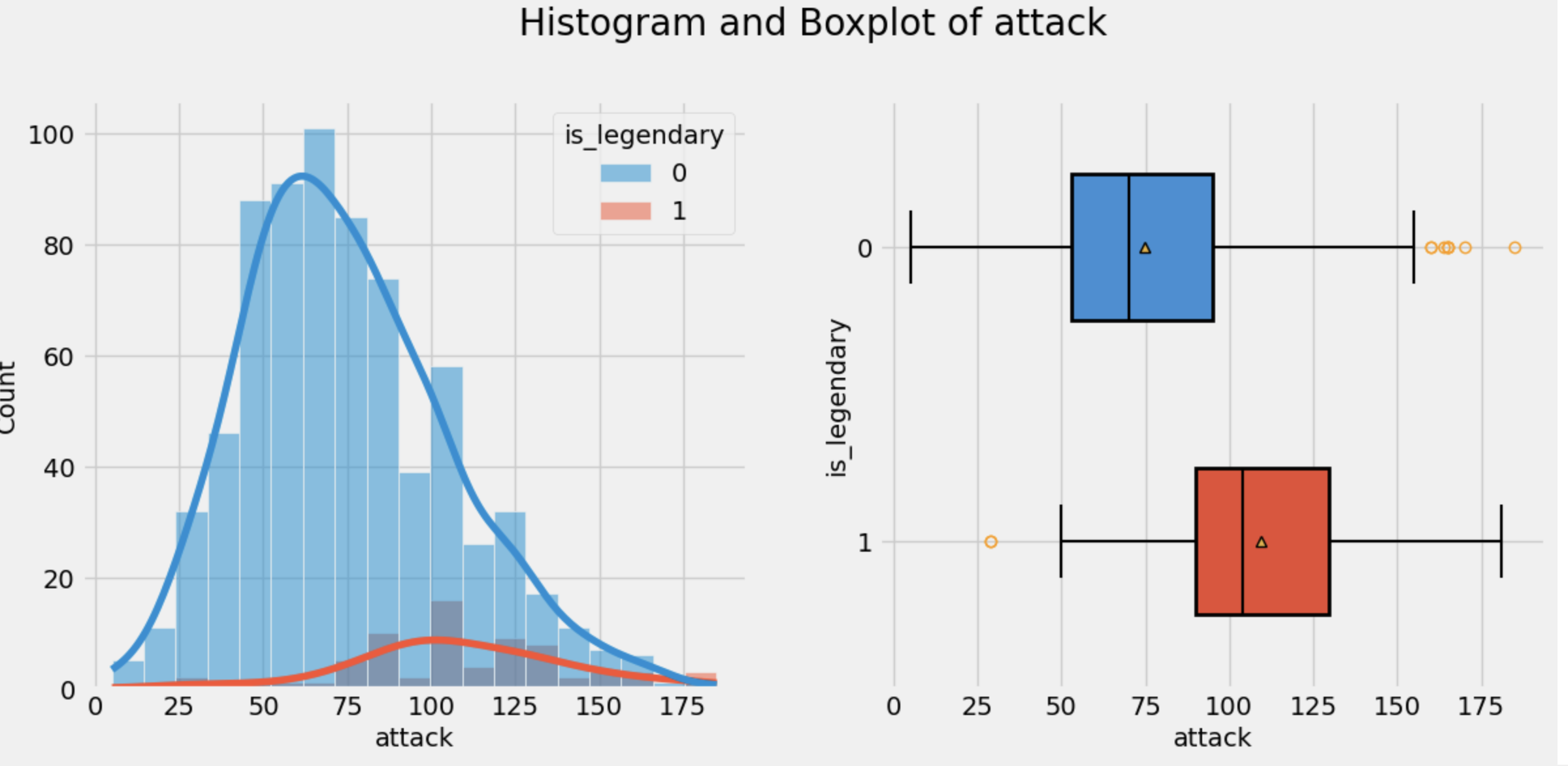
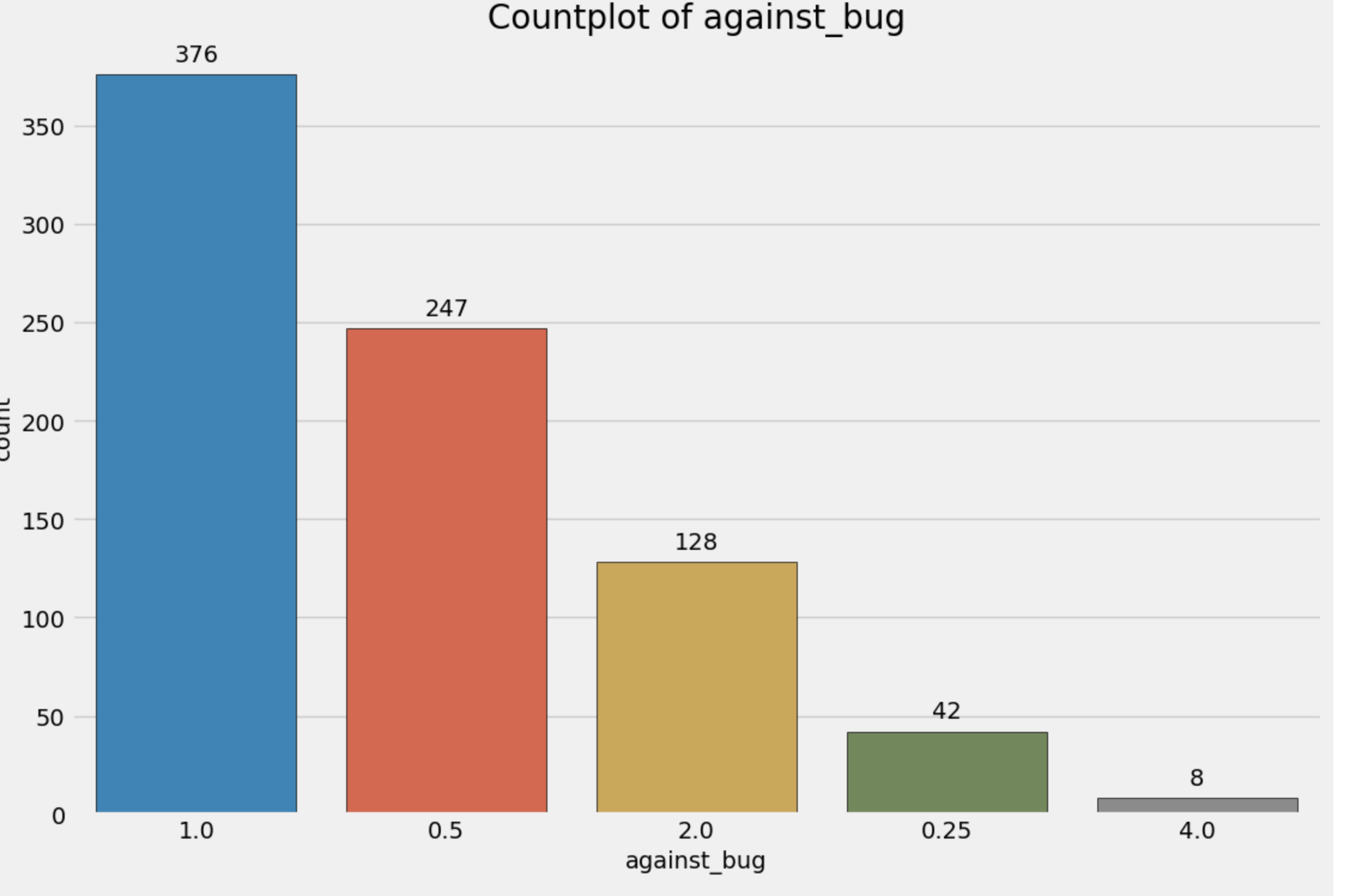
これだけの情報がたった一行で手に入るのは便利ですね!!!後輩よ、ありがとう。
まだリリースされて日が浅いので今後のアップデートにも期待ですね。
モデリング
ではPyCaretを使って伝説のポケモンかどうか判定するモデルを爆速で作っちゃいます。
公式はこちら↓
先人たちの記事も載せておきます↓
何はともあれimportしましょう。回帰の場合はclassificationをregressionにしてください。
from pycaret.classification import *
続いてセットアップです。トレーニングとテストの分割や欠損値処理などしてくれます。
analysis = setup(df, target = 'is_legendary')
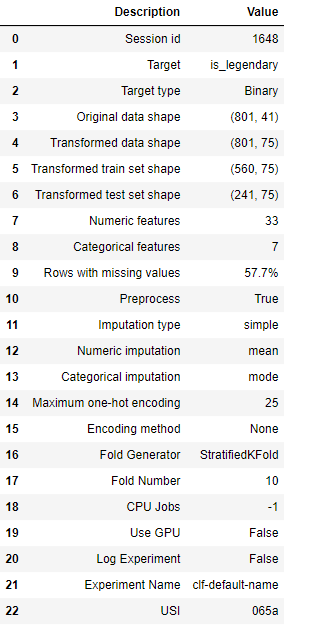
次の一行だけでモデルを比較してくれます。評価方法はK-foldクロスバリデーションで、fold数は引数で指定できます。デフォルトは10-foldですね。今回は800データしかないので10-foldで行います。
compare_models()
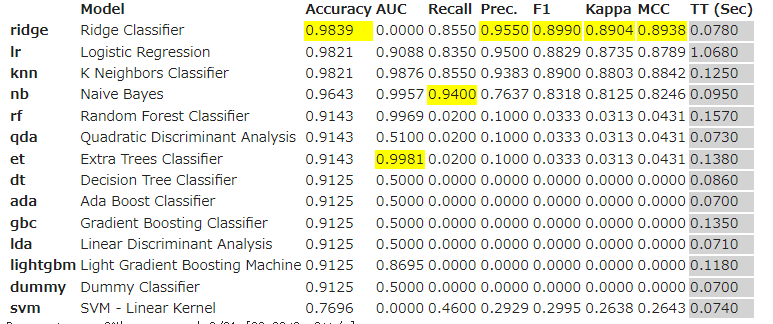
だいぶ接戦ですが、一番上のリッジ回帰を使ってみます。以下のコードでK-foldのスコアを見れます。
ridge = create_model('ridge')
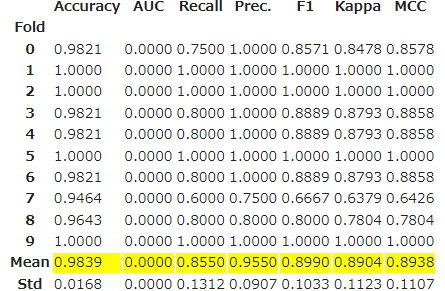
PyCaretのさらにすごいところがハイパーパラメータのチューニングもしてくれます。クロスバリデーションとグリッドサーチを使っているみたいです。
tuned_ridge = tune_model(ridge)
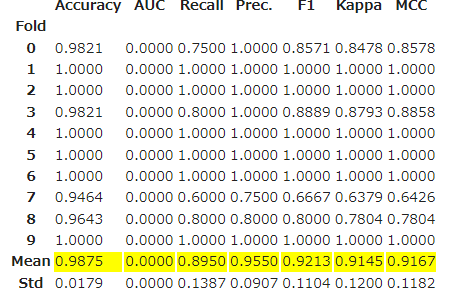
若干精度が向上しました!このチューニング後のモデルを最終モデルとします。
final_ridge = finalize_model(tuned_ridge)
では、出来上がったモデルで分類させてみましょう。今回は元データを目的変数と説明変数に分けて、使いまわしてます。
estimated = predict_model(final_ridge, data = x)

小さくて申し訳ないですが、一番最後の列に予測されたLabelが追加されています。混同行列を確認します。
confusion_matrix = pd.DataFrame(metrics.confusion_matrix(y, estimated.iloc[:, 40]))
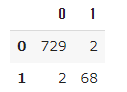
伝説なのに伝説と分類されなかった、伝説でないのに伝説と分類されたポケモンがそれぞれ2匹いますが、いい感じに予想できてます。簡単で素晴らしいですね。正解率も確認しておきます。
metrics.accuracy_score(y, estimated.iloc[:, 40])
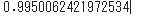
ちなみにモデルの可視化もしてくれます。
evaluate_model(final_ridge)
では、どんなポケモンが外れたのか、もう少し見やすくします。正解データと予測データを比較して正しければTrue、間違いであればFalseを列に追加します。
y_for_save = pd.DataFrame(y)
y_for_save.columns = ['actual_class']
y_error = y_for_save.iloc[:, 0] == estimated_y.iloc[:, 0]
y_error = pd.DataFrame(y_error)
y_error.columns = ['TRUE_if_estimated_class_is_correct']
results = pd.concat([x.iloc[:, 29], y_for_save, estimated_y, y_error], axis=1)
results
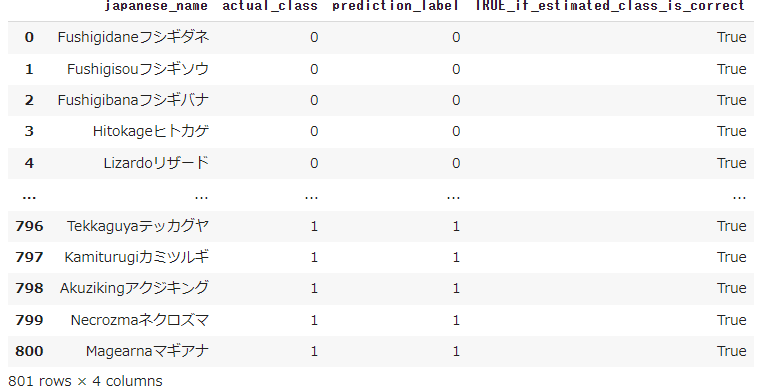
Falseだけ抜き出してみます。
false_rows = results[results['TRUE_if_estimated_class_is_correct'] == False]
false_rows

さて、ここでルビサファで止まっている30代おっさんはマナフィしか知りませんでした(なんか映画やってませんでした?)。特に、Null・・・?欠損値・・・????
まぁそんなわけはなくて、シルヴァディType:Nullだそうです、ちょっとよくわかりません。あと色々調べたら準伝説ポケモン?ってのがあって、ヒードランやシルヴァディはそれにカウントされるみたいですね。それならモデルが間違えたのもうなずけますかね。でもここら辺よくわからないので有識者の方、コメントいただけたら幸いです。
おわりに
何はともあれ、非常に簡単にデータ分析とモデリングができました!ありがとう、fasteda!ありがとう、PyCaret!
また面白そうなデータセット見つけたら解析したいと思います。
ではまた。
※k-近傍法でモデリングしたら正解率100%になりました。上位3つくらいのモデルを試すのがいいかもしれませんね。