はじめに
Pycaretの 冬のコードに 雪解け水
こんにちは、「Pycaret」という語句を用いてChatGPTに俳句を作ってもらいました。
Pycaretの: 「Pycaret」というのは、データサイエンスと機械学習のためのPythonライブラリです。この言葉を使うことで、俳句に現代的なテクノロジーの要素を取り入れています。
冬のコードに: 「コード」という言葉は二重の意味を持っています。一つは文字通りのプログラミングコード(Pycaretを使う際のコード)を指し、もう一つは「冬の寒さや厳しさ」を暗示しています。つまり、Pycaretを使用している冬の情景が想起されます。
雪解け水: 冬の終わりに雪が溶けて水に変わる様子を表しています。これは季節の変わり目、特に冬から春への移り変わりを象徴しています。
総合すると、この俳句は、冬の寒さの中でPycaretを使用している情景を描きつつ、季節の変化、具体的には雪が溶けて春が近づいていることを表現しています。技術と自然の季節の変わり目が融合している独特なイメージです。
素晴らしいですね。才能あり、特待生に昇格です。
さて、みなさんAutoMLしていますか?私はデータの前処理をするのに重宝しています。
そんなAutoMLライブラリとして有名なPycaretのポテンシャルをどこまで引き出せるかを本記事では検証してみます。
(Pycaretの実力はそんなもんじゃねぇ!なめんな!という方はごめんなさい。精進します(´・ω・`))
今回はSignateの適当なコンペに参加して、Pycaret"だけ"(手動で前処理や特徴量エンジニアリングもしない)でどこまでランキング上位に食い込めるか試してみますね。
Pycaretの使い方もできるだけ丁寧に説明したのでよかったら最後までご覧ください。
・GooglColabo
・Pycaret==3.2.0
中身興味ねえから結果だけ教えろ!って方は以下のプルダウンをどうぞ。
結果
結果、235/465人でギリギリ上位50%に食い込めませんでしたが、Pycaretの実力はそれなりに証明できたのではないでしょうか。
コンペ
今回の検証はSignateの「SIGNATE Student Cup 2021春:楽曲のジャンル推定チャレンジ!!」を使用します。
・SIGNATE Student Cupは、SIGNATEが学生向けに提供する「SIGNATE Campus」の一環として、データサイエンススキルの学生No.1を決めるコンペティションイベントです。
・本コンペは、2021年4月~5月に開催した「SIGNATE Student Cup 2021春【予測部門】」のSOTAチャレンジとなります。(学生でなくてもご参加可能です
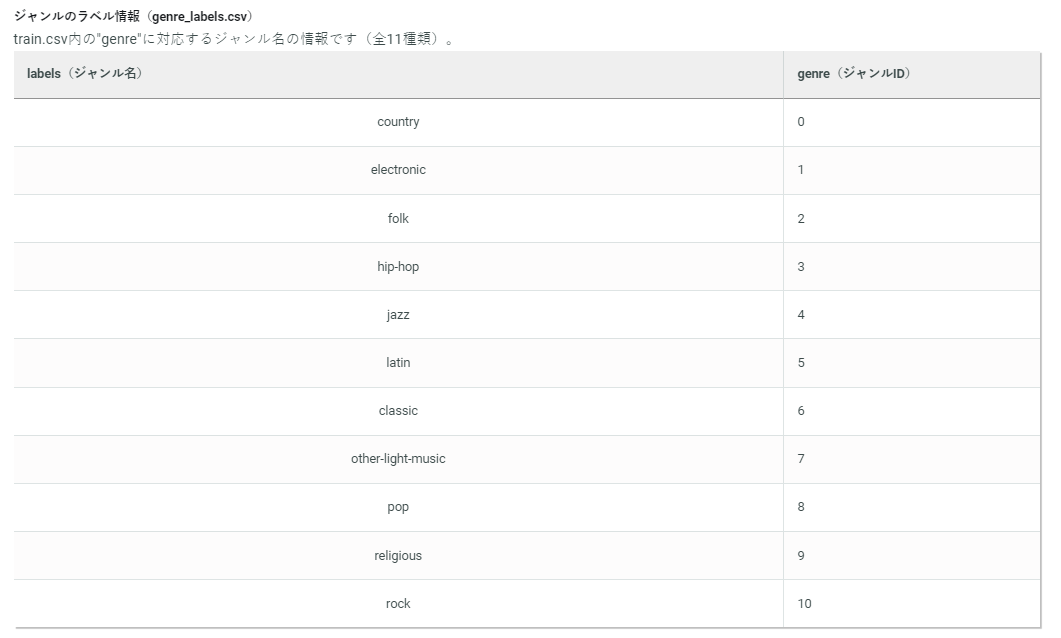
楽曲の長さや人気度、アコースティック度といった様々な曲の特徴から、その曲がどのジャンル(全11種類)に該当するかを分類するタスクとなります。
以下はカラムの説明です。11種類の'genre'を予測する多項分類になります。
パット見抽象的なデータが多いですね。'~性'といった特徴はどうやって数値化しているのか気になるところではあります。

'genre'の情報です。ヒストグラムを書けばわかりますが、'pop'と'rock'にデータがだいぶ偏っているデータです。手動でやるなら段階的な予測をしても面白そうですね。
モデル実装
Pycaretのインストール
!pip install pycaretでは'catboost'などのモデルが使えないので、!pip install pycaret[full]でインストールします。
!pip install pycaretをしてから、!pip install pycaret[model]をすれば追加モデルをインストールできるはずなのですが、私はうまくいかず、[full]に落ち着きました。
使用できるモデルは、setup()した後、models()で確認できます。

setup()
Pycaretはまずsetup()関数で環境の設定をします。今回設定した環境は以下の通りです。
from pycaret.classification import *
setup(data=train_dataset,target="genre",session_id=123,fold = 10,
imputation_type = "iterative",numeric_iterative_imputer = "lightgbm",
categorical_iterative_imputer = "lightgbm",max_encoding_ohe = 25,
normalize = True,normalize_method = "zscore",fix_imbalance = True,transformation = True,)
| 引数 | 型 | デフォルト | 説明 |
|---|---|---|---|
| data | dataframe-like | - | - |
| target | float, int, str or sequence | -1 | 目的変数のカラム名。デフォルトは最後のカラム。 |
| session_id | int | None | ランダム性の制御、再現性の確保 |
| fold | int | 10 | クロスバリデーションで使用するfold数。クロスバリデーションの手法を選択することもでき、'fold_strategy'で指定できます。'stratifiedkfold'の他に、'kfold', 'groupkfold', 'timeseries', などが使用できます。 |
| imputation_type | string | 'simple' | 欠損値の補完方法。'simple'あるいは'iterative'が選べます。'None'の場合は欠損値の補完は行われません。 'simple'の場合、何かしらの統計値や指定した数値で補完します。補完方法は'numeric_imputation'で指定できます。 デフォルトは'mean'(平均値)ですが、他にも'drop'(欠損値を含む行を削除)、'median'(中央値)、'mode'(最頻値)、'knn'(k-最近傍法によるアプローチ)、'int or float'(指定数値)が使用できます。 'iterative'の場合、何かしらの推定値で補完します。以下の'numeric_iterative_imputer'や'categorical_iterative_imputer'で推定器を設定します。 |
| numeric_iterative_imputer | str or sklearn estimator | 'lightgbm' | 数値型カラムの欠損値の推定器の設定です。デフォルトはLightGBMですが、Catboostやランダムフォレストも使えます |
| categorical_iterative_imputer | str or sklearn estimator | 'lightgbm' | カテゴリカルカラムの欠損値の推定器の設定です。 |
| max_encoding_ohe | int | 25 | OneHotEncodingを行う際のユニーク値の上限です。指定した数値を超えるユニーク値を持つカラムは推定器が使用されます。 推定器はデフォルトでcategory_encoders.leave_one_out.LeaveOneOutEncoderが使用されます。 OHEでカラム数を増やしたくない場合はこの数値を小さくすればいいです。 |
| normalize | bool | False | Trueにすると以下の'normalize_method'で指定された方法で正規化を行います。 |
| normalize_method | string | 'zscore' | 標準的な正規化です。各データから平均値を引いて標準偏差で割った値です。 その他、'minmax '、'maxabs'、'robust 'が使用できます。 |
| fix_imbalance | bool | False | トレーニングデータセットにターゲットクラスの不均等な分布がある場合、セットアップのfix_imbalanceパラメータを使用して修正することができます。Trueに設定すると、SMOTE (Synthetic Minority Over-sampling Technique) がデフォルトのリサンプリング方法として使用されます。リサンプリングの方法は、'fix_imbalance_method'で変更できます。 |
| transformation | bool | False | Trueに設定すると、データをより正規/ガウス的にするために累乗変換が適用されます。これは、異分散性に関連する問題や、正規性が望まれるその他の状況をモデル化するのに便利です。分散を安定させ、歪度を最小化するための最適なパラメータは、最尤法によって推定されます。 |
他にも引数はたくさんあり、試したけど精度が上がらなかったものは以下の通りです。
| 引数 | 型 | デフォルト | 説明 |
|---|---|---|---|
| remove_outliers | bool | False | PyCaretのremove_outliers関数を使うと、モデルを学習する前にデータセットから外れ値を識別して除去することができます。外れ値は、Singular Value Decomposition テクニックを用いた PCA 線形次元削減によって識別されます。これは、setup 内の 'remove_outliers' パラメータを使用して実現できます。外れ値の割合は'outliers_threshold'パラメータで制御します。 |
| rare_to_value | float or None | None | カーディナリティの高い特徴が数値にエンコードされている場合、結果の行列はスパース行列になります。これは、特徴数の多様な増加、ひいてはデータセットのサイズの増加により、実験が遅くなるだけでなく、実験にノイズをもたらします。スパース行列は、高いカーディナリティを持つ特徴のレアレベルを組み合わせることで回避することができます。 |
| polynomial_features | bool | False | 多項式の特徴量を生成します。 |
| feature_selection | bool | False | True に設定すると、'feature_selection_estimator'によって決定された特徴量重要度スコアに基づいて、特徴量のサブセットが選択されます。 'feature_selection_estimator'はデフォルトでは'lightgbm'であり、'n_features_to_select'によって選択する特徴量の数の最大値を指定できます。 |
| remove_multicollinearity | bool | False | True に設定すると、定義した閾値以上の相互相関を持つ特徴量が削除されます(多重共線性の回避)。'multicollinearity_threshold'で閾値を設定できます。 |
| low_variance_threshold | float or None | None | データセットに複数のレベルを持つカテゴリ特徴があることがあるが、そのようなレベルの分布は偏っており、1つのレベルが他のレベルより優位に立つことがある。これは、そのような特徴によって提供される情報にはあまりばらつきがないことを意味する。 MLモデルにとって、このような特徴量はあまり情報を追加しないため、モデリングには無視することができます。 トレーニングセットの分散が指定された閾値より小さい特徴を削除します。0の場合、分散が0でないすべての特徴を保持する、つまり、すべてのサンプルで同じ値を持つ特徴を削除します。 |
詳細は以下を参照してください。
setupが終了するとこんな設定をしましたよ~的な出力が得られます。行も列も増加しましたね。列が増えたのはOHEの影響で、行数が増えたのは'fix_imbalance 'の影響で、でクラスの不均衡を解消するためにオーバーサンプリングやアンダーサンプリングが行われ、特定のクラスのサンプル数が増加することがあるみたいです。

実際にPycaretにより前処理されたデータを取り出して見ます。get_config関数を使用すると取り出せます。
X = get_config('X_transformed')
y = get_config('y_transformed')
setup_df = pd.merge(X, y,left_index=True,right_index=True)
setup_df.head()

列が多すぎて全部載せられませんでした。でも正規化されているのは見えると思います。.info()の結果を以下に示します。

これも全部載せられませんでした。'tempo'と'region'がOHEされていて、欠損値もすべて補完されています。
compare_models()
setupが完了したら次はcompare_modelsで各モデルの性能を比較します。簡単にcompare_models()とすれば実行できるのですが、ここでは引数にn_select=3を設定することで上位3つのモデルを変数に格納しておきます(後でアンサンブルしたいので)。
その他、引数としてはsortで指標の並び替えができます。例えば、compare_models(sort = 'F1')とすることでF1スコア順に上から並ぶようになります。
includeを使うとモデルの指定ができます。例えば、compare_models(include = ['catboost', 'rf', 'lightgbm'])とすることで指定した3つのモデルのみ精度の比較が実行されます。逆にexcludeを渡すことで不要なモデルを除外することもできます。
base_model = compare_models(n_select=3)
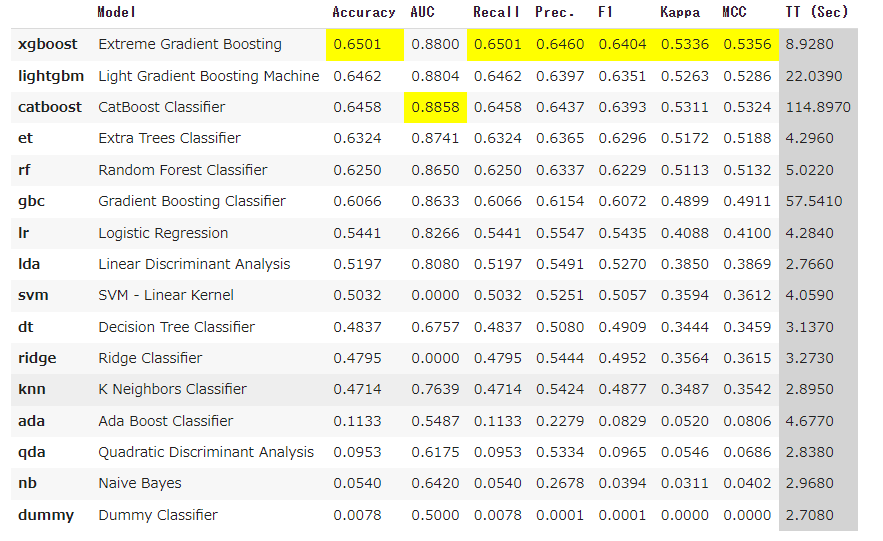
ブースティング系が上位を占めましたね。ではこの上位3つをアンサンブルして最終モデルとしたいと思います。
blend_models()
Pycaretにはblend_models()とstack_models()という関数が存在します。blend_models()はデフォルトではSoft Votingで、各モデルの予測結果の確率を平均して最終的な予測とします。stack_models()はいわゆるスタッキングです。各モデルのクロスバリデーションによる予測値を新たな説明変数としてロジスティック回帰などの線形モデルでブレンドして最終モデルとする手法です。
どちらも試しましたが、blend_models()の方が精度が良かったです。
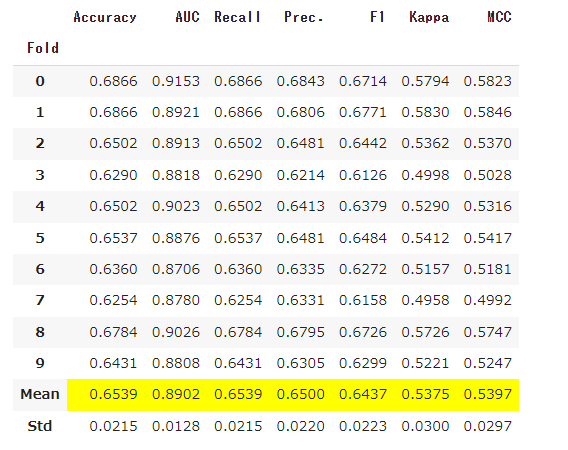
blender = blend_models(base_model)
以下のようにcompare_models()とまとめて行うこともできます。これによりオートマティックなモデルの構築が可能になり、スクリプトを変更することがなく、毎回上位3つのモデルをブレンドすることができます。
blender = blend_models(compare_models(n_select = 3))
以下がブレンド結果です。精度が向上していることが分かりますね。
ブレンドしたモデルをtune_model()関数でチューニングすることもできます。すなわち、各モデルの重みを最適化してくれます。また、引数にweightsを渡すことで手動で重みを設定することもできます。
ここではchoose_betterという引数を渡していますが、これを'True'にすることで、チューニングしてもモデルの性能が向上しない場合、元のモデルを返してくれます。
tuned_blender = tune_model(blender, choose_better = True)
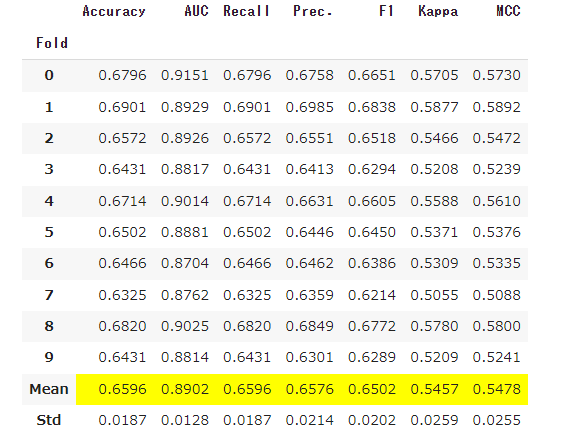
若干精度が上がりました。重みを確認する場合は、変数の'tuned_blender'をprintすればわかります。最終行にweights = 〇〇が出力されています。
VotingClassifier(estimators=[('Extreme Gradient Boosting',
XGBClassifier(base_score=None, booster='gbtree',
callbacks=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, device='cpu',
early_stopping_rounds=None,
enable_categorical=False,
eval_metric=None,
feature_types=None, gamma=None,
grow_policy=None,
importance_type=None,
interaction_con...
min_split_gain=0.0,
n_estimators=100, n_jobs=-1,
num_leaves=31, objective=None,
random_state=123, reg_alpha=0.0,
reg_lambda=0.0, subsample=1.0,
subsample_for_bin=200000,
subsample_freq=0)),
('CatBoost Classifier',
<catboost.core.CatBoostClassifier object at 0x798a55486ec0>)],
flatten_transform=True, n_jobs=-1, verbose=False,
voting='soft', weights=[0.93, 0.47000000000000003, 0.93])
finalize_model()
モデルが決まったのでfinalize_model()関数を使用して、setup()で分割されたテストデータも含めてモデルを再構築して、最終モデルとします。
final_model = finalize_model(tuned_blender)
predict_model()
構築した最終モデルを使ってSignateから与えられたテストデータの予測を行います。
prediction_test_data = predict_model(final_model, data = test_dataset)
prediction_test_data.head()

予測ラベルは最後から二番目の列にあるので、抜き出してコンペに提出します。
結果
発表します。。。どぅるるるるるるる・・・どぅん!

235/465人でギリギリ上位50%に食い込めませんでした!メダルは100位以内に入らないといけないのでもっと精度を上げる必要がありますね。でも大健闘ではないでしょうか。Pycaretの可能性を大いに感じる検証でした!
おわりに
今回はPycaret'のみ'という縛りプレイでしたが、Pycaretの可能性を大いに感じていただけたのではないでしょうか。私自身もPycaretのポテンシャルを引き出すために様々な引数を調べて、大変勉強になりました。
前処理やモデル構築はPycaretをはじめとするAutoMLにお任せして、人間は特徴量の生成に注力するというのが今後の機械学習のスタンダードになる気がします(もうなってる?)。
何なら特徴量の生成はChatGPTにお任せすればいいのでは?
そんな記事を次回は書きたいと思います(たぶん)。
それでは、次の記事でお会いしましょう(゚∀゚)