背景
某大学の某研究の某街興しの研究で、某地域の住民の方に対してヒアリングを行ったそうなのですが、そのヒアリングの内容からその地域の人達が無意識に意識している何かがないか…という分析をしたいとのことで、やってみることになりました。
使ったもの
MeCab
こちらも、おなじみの形態素解析エンジンです。
形態素解析とは
文書を単語の品詞情報をもとに,形態素(単語が意味を持つ最小の単位)に分解することですね。
よくすももも…の例があるので、他の例で実行したものをお見せすると、以下のような形で単語に分解し、その品詞を示してくれます。
echo '町長ちょっとチョウチョとった調書とってちょうだい' | Mecab
町長 名詞,一般,*,*,*,*,町長,チョウチョウ,チョーチョー
ちょっと 副詞,助詞類接続,*,*,*,*,ちょっと,チョット,チョット
チョウチョ 名詞,一般,*,*,*,*,チョウチョ,チョウチョ,チョーチョ
とっ 動詞,自立,*,*,五段・ラ行,連用タ接続,とる,トッ,トッ
た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ
調書 名詞,一般,*,*,*,*,調書,チョウショ,チョーショ
とっ 動詞,自立,*,*,五段・ラ行,連用タ接続,とる,トッ,トッ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
ちょうだい 名詞,動詞非自立的,*,*,*,*,ちょうだい,チョウダイ,チョーダイ
wakati
先ほどの値は -Ochasen というオプションを付けてもでてくるののですが、、Mecabのコマンドのオブションに -Owakatiというものがあります。
これを使うと、単語毎に区切った文字列を得ることができます。
文書の前処理をするのによく使います。
echo '町長ちょっとチョウチョとった調書とってちょうだい' | Mecab -Owakati
町長 ちょっと チョウチョ とっ た 調書 とっ て ちょうだい
インストール
MacならHomebrewを使ってしまえば早いです。
brew install mecab
brew install mecab-ipadic # 標準のシステム辞書
# Web上の文書に強い、mecab-ipadic-NEologd という辞書もあります。 (https://github.com/neologd/mecab-ipadic-neologd)
### 辞書のインストール
cd
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
cd mecab-ipadic-neologd
./bin/install-mecab-ipadic-neologd -n -a
WindowsであればReleaseされているインストーラを実行してしまうのがいいです。
https://github.com/ikegami-yukino/mecab/releases
Word2Vec
テキストマイニングでおなじみword2vecを使いました。
テキストデータを解析し、単語をベクトル化するライブラリですね。
パッケージはgensimを使いました。
ベクトル化って何してるの
簡単に言ってしまうと単語と単語の関係姓を数値化すると言ってしまうのが良いでしょうか。
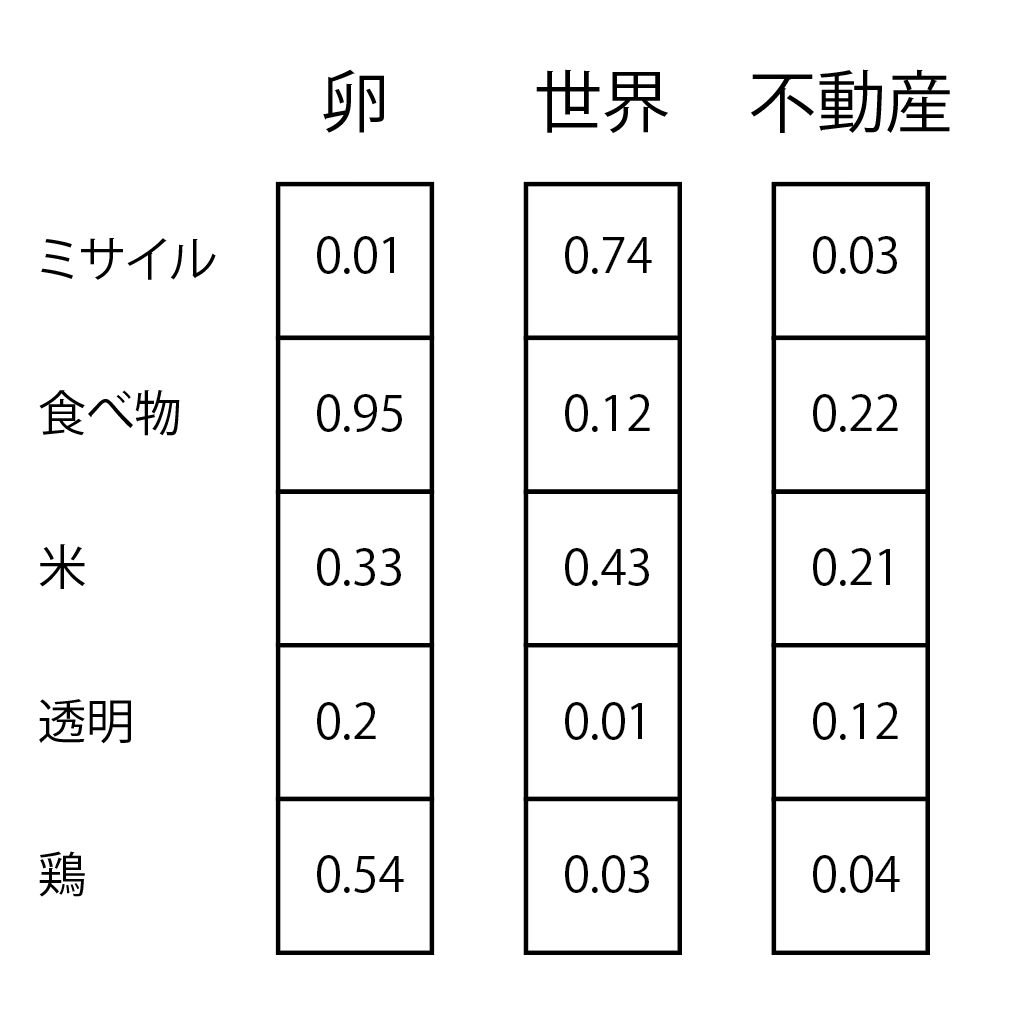
分散表現(Word Embeddings)※1という高次元ベクトルでの表現方法が使われているのですが、各単語に対して、以下の図のような形で、単語間の類似度を測っているわけです。
※1. one-hot表現の問題を解決した表現方法
学習アルゴリズム
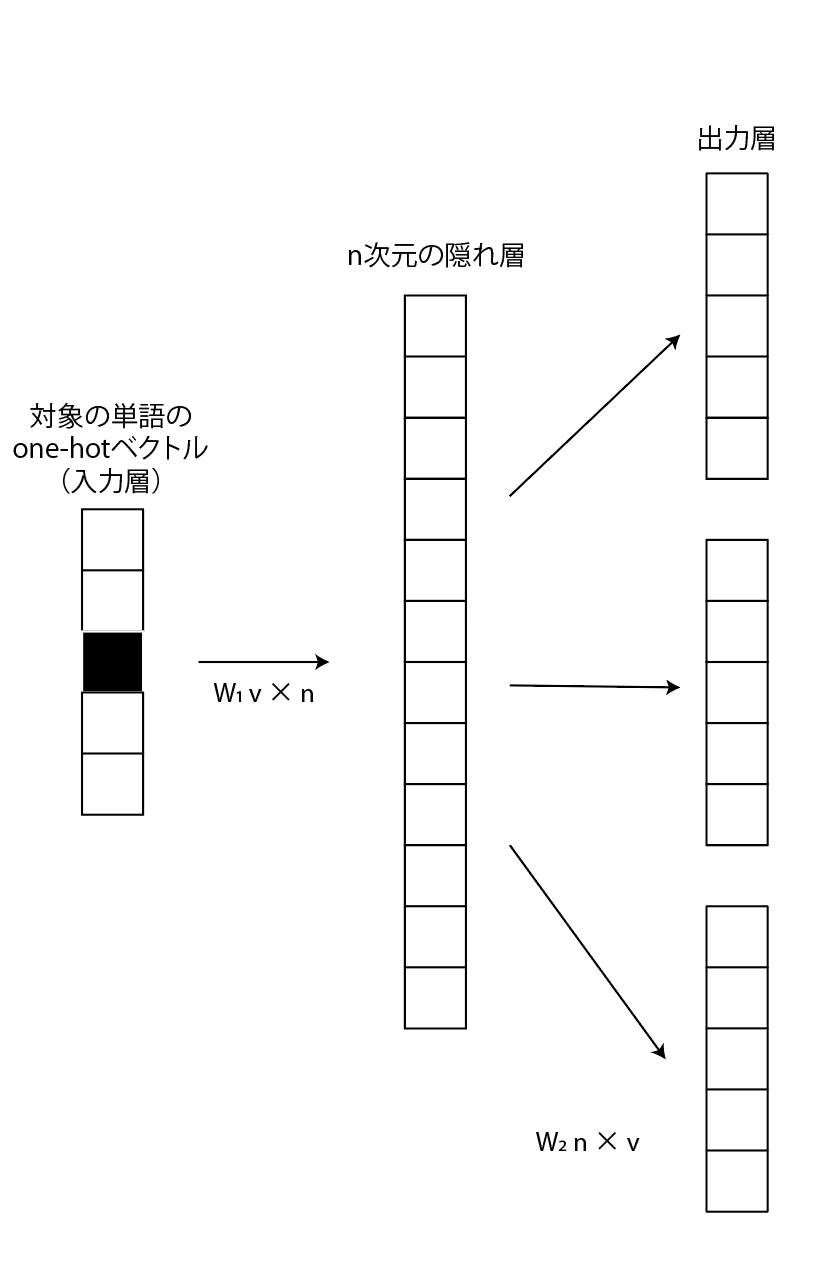
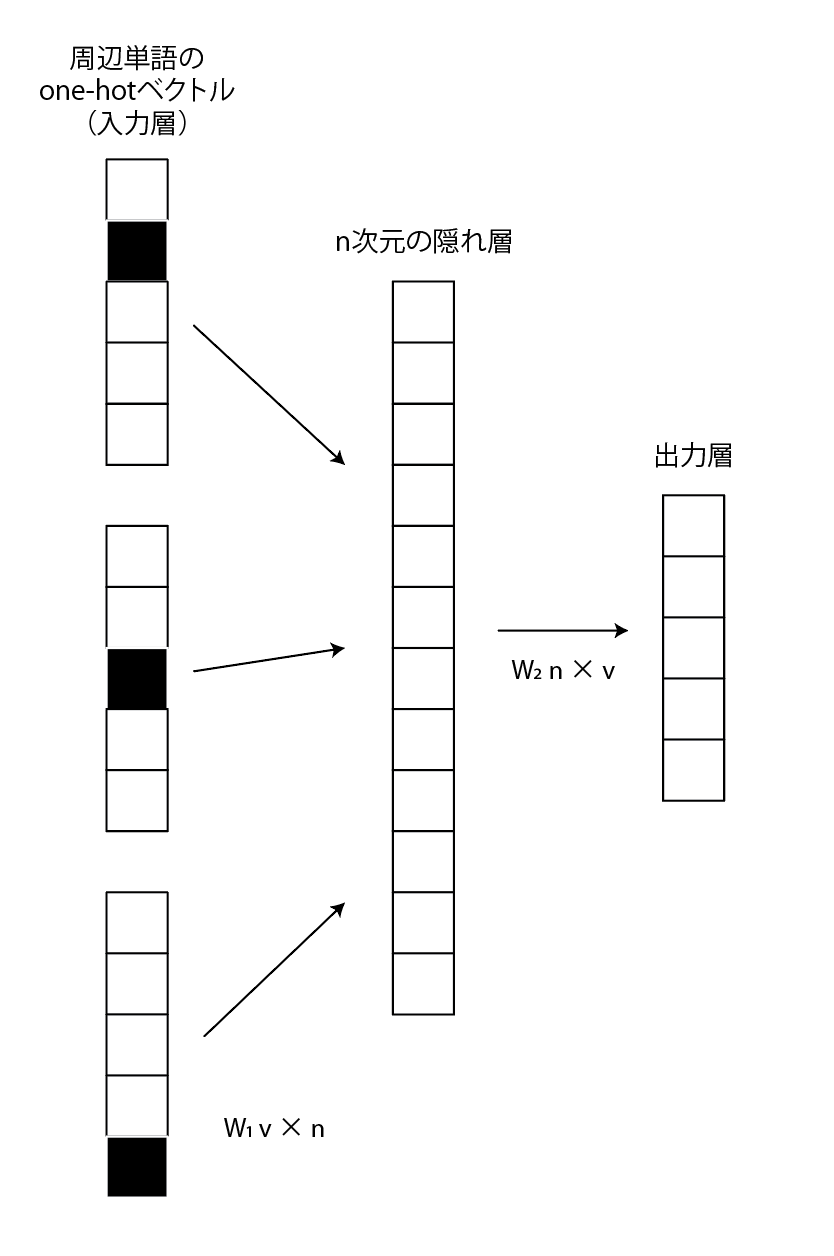
gensimのword2vecには2種類の学習アルゴリズム(モデル)が含まれてます。
どちらもone-hotベクトルを入力層とし、n次元の隠れ層を介して出力層に変換される構造のニューラルネットです。
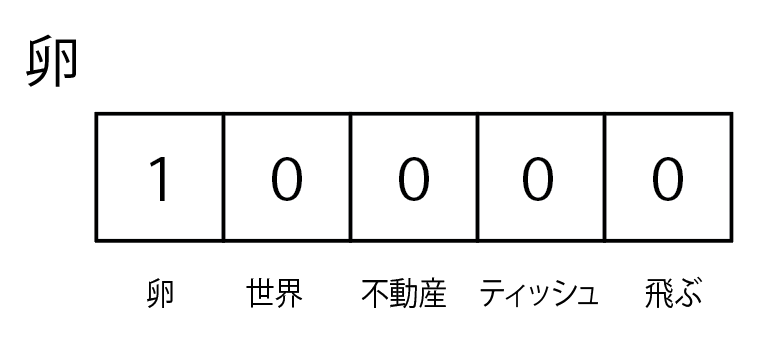
ちなみに、one-hotベクトルとは単語数分の次元ベクトルの各要素に単語を割り当てたもので、要するに単語帳のようなものをイメージしてもらったらいいですかね。
卵を現したいなら卵のフラグが立つ感じです。
-
Skip-gramモデル
対象の単語から周辺単語を学習するモデルです。
-
Countinuous Bag-of-Wordsモデル(CBOW)
周辺単語から対象の単語を学習するモデルです。
基本的にSkip-gramの方が少ないデータで精度が出るため、こちらで実行するのがお薦めです。
インストール
gensimに含まれているword2vecを今回は使ったので、インストールは以下のコマンドだけで行いました。
pip install gensim
類似パッケージ
- GloVe
- WordNet
- Doc2Vec ← 今回使うべきはこっちだったかもしれない
- fastText ← Facebookの人工知能研究所が公開した自然言語処理を高速化するライブラリ。開発者はWord2Vecを作ったMikolov氏なので、上位互換?
scikit-learn
機械学習のオープンソースライブラリといえば…という感じですが、今回は出てきた単語のクラスタリングをするために使いました。
scikit-learnって何ができるの
書くのが疲れてきたので、ざっくりですが…以下のことができます。
分類(classification)
教師あり学習の分類問題を解けます。以下の手法が利用できます。
- SGD(stochastic gradient descent)
- カーネル近似
- Linear SVC
- k近傍法
回帰(regression)
回帰分析を行えます。機械学習のチュートリアルなんかで、やったりするやつですね。
使える手法は以下の通りです。
- SGD(stochastic gradient descent)
- LASSO、ElasticNet
- Ridge、Liner SVR
- SVR(ガウスカーネル)、Ensemble
クラスタリング(clustering)
教師なし学習のクラスタリング問題を解くことができます。
今回は教師なしで実施したかったので、これを用いました。
使える手法は以下の通りです。
- KMeans
今回はこの手法でやっています。 - スペクトラルクラスタリング、GMM
KMeansではうまく分析できない場合に利用する、非線形なクラスタリング分析手法…だそうです。
ちゃんと勉強できてません。 - MeanShift、VBGMM
やったこと
まず、ヒアリングデータをMecabで形態素分析しました。
# 初期化
chasen = MeCab.Tagger('-Ochasen -d ./resource/dictionary/') # ./resource/dictionary/ ← これは辞書をいれたディレクトリです。
# テキストの形態素分析
raw = self.get_chasen(s) # sは
# 分析結果の文書を列ごとに分割
chunks = raw.splitlines()[:-1]
# 各項目毎の変数に保存し、その後の計算に利用してます。
surface, yomi, origin, feature = chunk.split('\t')[:4]
それから、Word2Vecに入れるためのテキストを -Owakati オプションを使って作成し、word2Vecに取込ます。
# 初期化
file_path = 'hoge.txt'
f = open(file_path, 'w', encoding="utf-8_sig")
wakati = MeCab.Tagger('-Owakati -d ./resource/dictionary/')
raw = wakati.parse(s)
f.write(raw)
# 文毎に読み込みを行います。
sentences = word2vec.LineSentence(file_path)
今書いているのは最終的に用いた方法の内容を書いてますが、最初別の方法で実装し、しかも、少ない文字起こしデータでやっていた時には、全然欲しいデータにならず、クラスタリングもバラバラ。
そんな理由から、既存の学習済みのモデルを利用し、そこに、ヒアリングデータを追加して学習させ、分析するという方法をとるようにしました。
なので、ネットからとってきた学習済みのモデルを読み込みさせます。
学習済みモデルについて
model = word2vec.Word2Vec.load(学習済みモデルのパス)
# トレーニングデータの追加
model.build_vocab(sentences, update=True)
# トレーニングデータに対して、biasをかける処理 (既存の学習モデルに飲まれてしまうため少し過学習をさせてます)
for epoch in range(BIAS):
model.train(sentences, epochs=model.epochs, total_examples=model.corpus_count)
model.alpha -= 0.002 # 学習率の設定
model.min_alpha = model.alpha # 学習率の修正
トレーニングさせた後は、単語をモデルにいれてやることで、ベクトルを得ることができます。
model.wv[単語]
次にclusteringです。
from sklearn.cluster import KMeans
# KMeansをsklernからimportし、モデルを呼び出しておきます。
kmeans_model = KMeans(n_clusters=CLUSTER_NUM, verbose=1, random_state=42, n_jobs=-1)
# ここに先ほどの手に居たベクトルの配列をツッコめばクラスタリングされます。
kmeans_model.fit(vectors)
ざっくり流れとしてはそんな感じです。
詳細はソースコードにて: https://github.com/AMDlab/questionnaire_mining
結果こんな感じの値を得られるのですが、
cluster name, words
cluster_0,研究,建築,仕事,雑誌,職人,物件
cluster_1,営業,地域,独立,下,企画,フリー,交換,用意,上の,情報,メディア,友人,紹介,販売,メンバー,中心,経営,趣旨,自身,協会,出身,写真,ギャラリー,フォーク,ロケ,美術,そうだ,展示,デザイナー,ライター,フリーランス,ホテル,事務所,ありません,地図,百貨店,従業員,作業,協力,業務用,スタッフ,業務,ビル,社長,鈴木,ストリート,倉庫,にも,青山,インタビュー,出荷,勉強,実演,町おこし,アルバイト,買い物,クライアント,お礼,弁当,書店,インターネット,お願い,工房,デパート,カメラマン,昭和26年,クラフト,打ち合わせ,商店,オフィス,知り合い,友達,カフェ,ドコモ,フード,ケーキ,思い出,伺い,あいさつ,目黒,催事,取引先,カルチャー,肩書,おじさん,六本木,台東,フィーチャー,お父さん,お伝え,名刺,飲み会,パティシエ,タウンページ,フードコーディネーター
cluster_2,時代,理由,関係,世界,スタイル,内容,バランス,過程,声,一つ,文化,芸術,方法,部分,名前,流れ,プロセス,意味,背景,逆,しよう,いない,ある意味,お互い,商品,店舗,男性,女性,父親,つながり,建物,興味,方向,想像力,観察,エリア,世代,実験,きっかけ,家族,反対,表,横,関心,技術,個人,意識,価値,状況,記憶,環境,タイミング,両方,イメージ,良さ,日常,アプローチ,チャンス,親,気持ち,地下,動き,メニュー,印象,事情,業種,スーパー,口,やろう,お金,雰囲気,若者,コミュニケーション,裏,天,モチベーション,本当,感覚,世の中,エネルギー,悩み,商売,周り,キーワード,若手,仕方,からだ,モノ,夫婦,グラフィック,食べ物,やる気,どこか,せがれ,自分たち,アドバイス,目線,癖,発想,お客さん,ブログ,素地,こだわり,散歩,手触り,悪いこと,コミュニティー,皆さん,使い勝手,横丁,持論,平気,子どもたち,思い入れ,上下関係,心地,かっこ,お母さん,のれん分け,いいもの,ラーメン屋,私自身,ジュエリー,町工場,深み,お話,におい,美大,若い人,五感,居心地,さい子
cluster_3,1,一,学校,母親,地元,隣,不動産,角,子ども,一緒,松屋,私たち,近所,おでん,浅草,谷中,蔵前,向こう,屋台,鳥越,芸大,コロッケ,おやじ,この辺,銭湯,肉屋,お子さん,餓鬼,焼き豚
cluster_4,放送,移動,撤退,提供,2代,3人,剣,敵,ストーリー,ベース,開発,マップ,バトル,説明,演出,条件,固定,最終,組織,身,再生,表示,再現,理屈,製作,ポスター,一般,アクセス,別,位置,設計,対応,基本的,構成,指定,幅,しない,考え方,手法,実現,周辺,テーマ,自体,理解,表現,可能性,日本,した,象徴,外国,関連,ブランド,ロゴ,和,専門店,公開,連絡,相談,究極,二つ,シフト,基本,タイトル,交流,都市,面積,本人,成功,話題,確信,プロジェクト,2008年,一人,ページ,車,そのもの,技,全国,字,活動,収集,撮影,1999年,試み,歌舞伎,準備,節約,調査,親近感,道具,下火,約束,同期,募集,体験,段階,プロデュース,オリジナル,魅力,電動,東,創業,2本,しながら,連携,具体,ボタン,印刷,賛成,資料,外,素材,種類,年齢,構造,扉,追加,地方,スペース,戦略,交渉,還元,具体的,パフォーマンス,はさん,駅,設計事務所,記録,母体,継承,平屋,誘導,解析,活性,実験室,開放,ラーメン,勝負,分解,下請け,工程,チーム,大手,感情,引き合い,意味合い,秘伝,質問,プレー,本格的,加工,デベロッパー,キー,西側,プレ,コスト,オンエア,装飾,再開発,貢献,大きめ,復活,集積,改装,一大,床,感動,才能,オブジェ,おかげさま,電話,待た,ベスト,傍ら,カメラ,派生,指示,格好,何人,血縁,作業員,プラットフォーム,ハードル,根本,引き出し,水槽,氷,血,ネットワーク,要望,現状,労力,競合,シェア,後ろ,意匠,誰か,パッケージ,共有,表紙,応援,完結,邪魔,認知,空気,民衆,GPS,団結,カー,後悔,納得,びっくり,決めて,喜び,追及,リング,常設,大量生産,戦略的,それなり,実感,仕掛け,アイデア,町並み,手元,出版社,インテリア,矢印,プロダクト,在庫,出店,自信,モダン,一点,酸素,スケッチ,剣道,回遊,罵声,試行錯誤,宝飾,通行人,差別化,可視,年寄り,子育て,ポテンシャル,好意,率先,イヤリング,主語,しゃべる,目的地,フィルター,冷蔵庫,小売り,バックボーン,経費,経済成長,承諾,温かみ,余談,共存,プラス,参加者,C4,継,前書き,同業,失礼,リピート,ブックマーク,門戸,共感,口コミ,ないと,斜陽,社会実験,ロット,包丁,普通に,肥やし,手数,スケルトン,気合,コンタクト,タブレット,車いす,カーナビ,トライ,おやつ,懐かしさ,コンサルティング,物量,ギャラリスト,激変,茶漬け,幾何学模様,やり口,オーバーラップ,仕方がない,はやり,ディスプレー,一読,食い物,直射,クリエーション,ブランディング,クオリティー,彫金,協力会社,ルーティン,店構え,お断り,お話し,作りました,1410,2521
cluster_5,卵,色,中国,産地,貴金属,値段,油,牛,魚屋,1本,グラム,火,塩,水,天井,袋,コーヒー,3本,銀,松,パック,宇治,ブタ,香り,肉,食材,メロン,ジュース,着物,竹,豆腐,焼き物,肩,お菓子,飯,味付け,イチゴ,お茶,手作り,コップ,高温,衣,服,居酒屋,貝,幾ら,チョコレート,アサリ,しば,餅,豚肉,鶏,コンロ,フライ,ナス,ウリ,調味料,ハム,まめ,郡司,畜産,ネギ,鶏肉,葉っぱ,みそ,おにぎり,煮物,串,カレー,サツマイモ,具材,味噌,芋,漬物,梱包,ウズラ,かまぼこ,しょうゆ,量り売り,ラード,片栗粉,ショウガ,ウズラの卵,パン粉,焼き魚,カラメル,ブローチ,マヨネーズ,総菜,揚げ物,ロース,蕪,きょうは,かけら,素揚げ,フライドポテト,豚カツ,チャーシュー,シジミ,ミョウガ,練り物,あずき,メンチ,もも肉,そぼろ,ベーグル,ラー油,七味
cluster_6,ネット,沖縄,旅,家,男,3年,妹,子,長男,父,妻,14歳,娘,仲間,作品,場所,代,3,同士,ザ,2,タイ,言葉,ご飯,大学,学生,合い,看板,株式会社,交差点,俳優,アメリカ,知人,マンション,道,中学,縁,向かい,アート,ボン,息子,出会い,緑,文句,昭和,実家,先輩,民芸,民芸運動,ドイツ,ブーム,スタート,そば屋,老舗,一緒に,昔ながらの,西,並び,専門,修行,世,自宅,田中,家で,養子,万,面識,琉球,壁,土,木,会長,誰も知らない,幼稚園,保育園,奥,駐車場,時計,2丁目,花,区,工場,ライフ,1期,3代目,95,東側,出て,住まい,商,長老,一番町,所帯,東北,6人,現役,同級生,商店街,おいで,立ち話,正月,行事,1階,手紙,ストレート,塊,たま,真ん中,400円,観光地,NTT,入り口,財布,ファッション,銀座,2代目,缶,パッケージデザイン,下町,サクラ,コンテナ,そば,大人,行き来,仲,神社,研究室,神田,料理,スター,コンビニ,出口,会い,籠,暇,とんでも,小道具,申し訳,問屋,繁盛,剛,建築家,親族,ホームページ,前回,個人的,フライヤー,屋号,威勢,呼び方,望月,0001,換気扇,小島町,はん,バラ,開店,NPO法人,革,神奈川,佐竹,ジャン,0041,441,スズキ,和菓子,斜め,一杯,大学院生,弟子入り,150円,田舎,飲食店,食料品,何回,10人,好きだから,いつの,三角形,フォークソング,左側に,グループ会社,1929,飲み屋,じいさん,アキ,お客,うわさ,久しぶり,文京区,ブリキ,八百屋,あるとき,御徒町,被災地,まつり,江東区,食料品店,日常的,米屋,不動産会社,モガミ,雑貨,モト,墨田区,ヨシ,森岡,徳島,お花,クラシコ,木村拓哉,お土産,MEN'S NON-NO,1500円,おばさん,ノブ,丸亀,酒屋,長屋,ヒツジ,美容師,1905,ディナー,晴れ男,おじいさん,コーヒーショップ,2227,1202,台東区,グール,一歩,切り出し,つばめ,ランチ,2127,お祭り,あの日,インド料理,9回目,ミズ,ひいき,9年前,なじみ,おばあちゃん,忘年会,さんま,ミヤ,もも,蕪木,交流会,2550,らいい,死活問題,雷門,1224,すき焼き,帽子屋,フラワーアーティスト,ぶっちゃけ,1307,兄ちゃん,キタ,2225,茅場町,誰々,乾物,マロニエ,かに,ヨコ,ヤマ,入船,15年前,仏生山,田中さん,軽食,工務店,話して,ベビーカー,駄菓子屋,入谷,キャッチー,おんぶ,1200円,買い方,3901,花屋,チク,1329,カミさん,ダラ,桜木,お薦め,愚痴,珈琲,定食屋,引っ掛かり,いいね,トリイ,0052,いやいや,お茶屋,5150,2204,なのはな,馬喰町,マチ,盛会,神山町,うれしいこと,1527,ますが,ミライ,にす,先ほど,1411,お嬢さま,ばあちゃん,ギョーザ,かたがた,ヨシノ,デパ地下,2117,真裏,古道具,和菓子屋,よろしくお願いします,みぞれ,みその,アガタ,大黒屋,ここだけの話,チャリ,セガール,竹澤,1547,0125,でんと,NTT都市開発,3744,女子美,1518,米久,イシイ,0814,タカオ,3039
cluster_7,9年,番組,開始,範囲,海外,4月15日,10年,10月7日,4月,限定,10,2年,1人,20年,最後,間,1995年,後継者,4年,状態,4,次,数,週,顔,5月,5,きた,ラジオ,生産,テレビ,11月,9月,7月,2回,小学校,十,20,2時間,1回,民放,20代,11月4日,百,冬,1年,変化,1年間,具合,需要,これだけ,延長,2月,頭,予定,注文,1時間,オープン,1日,2位,夏,FM,雨,家賃,春,NHK,30歳,ジャズ,東大,売り上げ,1週間,出して,祭り,ストップ,1週,5時間,DVD,食事,40,30代,大雨,10時,25年,限界,6年間,80,1期生,30年,40年,曜日,4日,7時間,3時,このまま,早め,6時,年末年始,土日,受注,40代,卸,取材,おかず,5日,パレード,1歳,昼食,Facebook,3カ月,休業,AM,80人,6時間,5秒,50代,晩,完売,1時,昼休み,5年前,2時,45年,15時,明かり,かき氷,80代,50本
cluster_8,イベント,最初,会社,デザイン,編集,発信,食,自転車,ヒアリング,ものづくり,SyuRo
cluster_9,自分,人たち,町,おかず横丁
この後も値の調整などもろもろ行ってて、最終的にどんな特色があるか出していった感じです。