4記事目なので過去の記事も参照ください
3か月目
当初の目的を考える
このプロジェクトの元々の目的は、深層学習を使って株式市場またはもっと広義に金融市場で収益を上げることでした。その目的を達成するためには以下に示すように関係するいくつかの要素があり、収益可能性はそれらの要素を少しずつまた一つずつ向上させることによって上昇していくと考えました。今回は最初にそれらの要素をここに記し、どのような方法を取ってきたか、またそれらを改良するためにどのような計画が立てられるかについて記したいと思います。
- 学習データの量と質
- 学習データに対する深層学習の”層“の適応度
- 完成したAIの運用方法
1. 学習データの量と質
より良い結果を出すには、過学習を防ぐ必要がある。過学習を防ぐには主に2つの方法があり、一つにはデータの量を増やすこと、もう一つは正則化を導入することであるが後者は2.学習データに対する深層学習の”層”の適応度に関するものである。
データの量を増やすことに関して難しい面もある。単純に色々な株価データを学習データに追加することでその量を増やすことはできるが、米国株、日本株その他のデータをごちゃまぜにしたデータを学ばせるのは賛否両論がある上に経験上あまり結果が良くない。一方で、データの種類の範囲を一部の種類(例えば日本株)のみに絞るまたはETFのみに絞ると、今度はデータの量が足りずに困る。学習データの多様化を防ぎながらデータ量を増やす方法はあるだろうか。
試行錯誤の結果ある方法を思いついた。
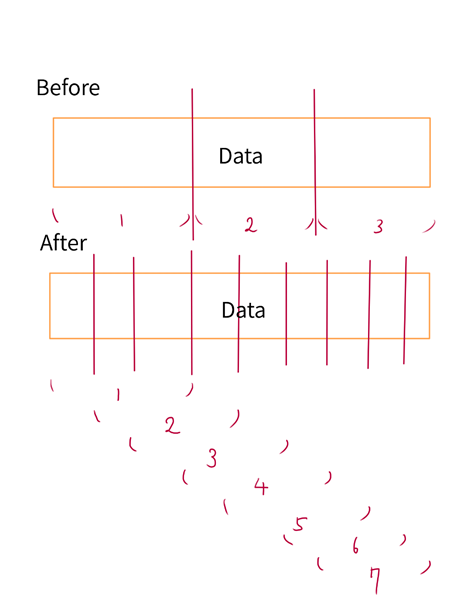
この図を見るとわかるように今までは元のデータを単に分割して学習データにしていたため、学習データの量に限界があった。一方で新しい方法を使えば、一つの元データからより多くの学習データを取り出し、適宜学習データ量を増やすことができる。尚、画像で抽象的に示した”Data”とは、具体的には例えば次のような画像データである。
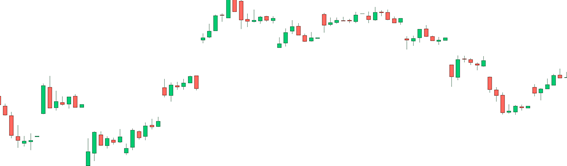
この方法にはもう一ついい点がある。学習データの質を向上させるために価格変動が少なかったデータを除外することができるが、それによってデータ量が減るデメリットを緩和することができる。
今後は、データの種類を絞り、かつ学習に不要と思われるデータを適宜排除しつつ、データ量は上記の方法で増やしデータの可能性を最大限に引き出すことを目標にします。
2. 学習データに対する深層学習の”層“の適応度
この部分が一番難しいかつ勉強する価値があると思います。
最初はどこかから拾ってきたSequential modelを訳もわからず使って学習させていましたが、それでは限界があったので背景にある理論について少し学びました。
おそらく一番重要なのはレイヤーの基本的な順番でそれらは以下のようになっています。
- Convolution
- Relu
- Pooling
- Flatten
- Fully Connected(Dense)
- Softmax
また、Convolution, ReluそしてPoolingはひとまとまりにして繰り返すことが可能です。理由がわかりませんが、以下のようにこれらを繰り返すと結果がよくなる傾向にあります。

未だわからないことが多くめちゃくちゃなSequential modelを使っている可能性がありますのでご注意ください。
今後、レイヤーに係る理論をなるべく深く理解し、より目的にあった効率的なSequential modelを自分で構築できるように頑張ります。
3. 完成したAIの運用方法
今まで実用的な運用、バックテストをサボっていたのでここがあまり進んでいません。
AIによる民主主義的意思決定を導入し、AIの判断の信憑性と精確性をある程度確保する方法を考案しましたがどのタイミングでAIを起動するか(起動したタイミングで株価チャートを読み込み判断を下す)、またその結果どのような売買行動を起こさせるかということが収益に大きく影響すると思われます。
今回、コロナウィルスの影響で株価が暴落していたので直近で以下の範囲の価格チャートを3人のAIに見せ、多数決によってどのような結果が出るのか見てみました。
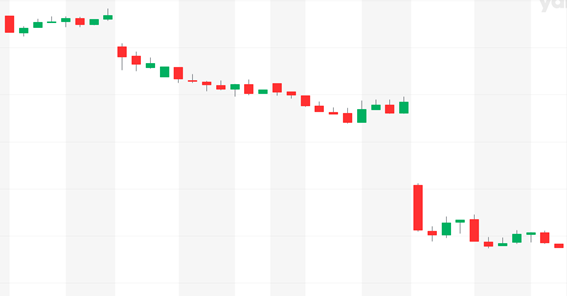
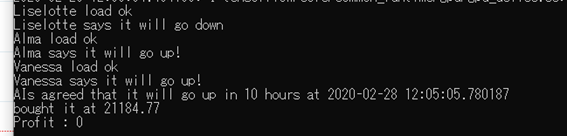
3分の2のAIが上がると予測し、結果は上がるでした。来週、株式市場はどうなってしまうのでしょうか。