はじめに
DBSCANは、密度ベースのクラスタリング手法の1つです。sklearnライブラリを用いることで簡単に実装できます。...できますが、前処理(正規化)や後処理(クラスタリング結果とデータの紐づけ、クラスタごとにデータの分割)を毎回行うのが面倒だなー、と思ってます。
ですので、今回の記事は前処理・後処理を含めて2次元配列を対象としたDBSCANを関数化を行いました。
今回の記事では、関数化にフォーカスを当てて記事を作成するため、理論的な部分については最低限となります。
DBSCAN
クラスタリングといえば距離ベースのk-meansが有名ですが、外れ値との相性がよくない・クラスタ数をしてする必要があり、結果への影響が大きい などのデメリットがあります。(理解しやすく実装しやすい・大規模なデータセットをうまく扱える などのメリットもあるため、全然使えないと手法ではありません。)
DBSCANは、密度ベースのクラスタリング手法で、データ点の密集領域を1つのクラスターとし、逆に低密度の領域はノイズとみなすという手法です。
外れ値を簡単に特定できノイズの多いデータセットに向いている・クラスタ数は自動で決定されるといったメリットがあります。
疎なデータセットではあまりうまく動作しない・epsやminPtsパラメータの影響を受けやすいというデメリットがあります。(eps、minPtsについては、後述します。)
パラメーター
- eps
最大でどの程度離れた2点を同じクラスターに属するとみなすかを決めるパラメーター - minPts
クラスターとみなすための最小限の点の数。minPts未満の点しかない場合は、ノイズとして扱われます。
アルゴリズム
各点について、他のすべての点からの距離を計算し、もし距離がeps以下ならば、その点xに隣接する点としてマークする。その点がminPts以上の隣接点がある場合には、クラスターとしてマークします。
この手順を繰り返すことでクラスタリングを行っていきます。
ざっくり説明ですので、詳細を知りたい方は、以下をご覧ください。
コード
前処理(正規化)
epsを0-1に収めるため、Min-Max normalizationにて正規化を行います。
列ごとに指標が異なる場合は、引数axis=1を使用して、列ごとに正規化を行ってください。
#正規化
normalize_dataset = preprocessing.minmax_scale(dataset)
クラスタリング
DBSCANを行います。eps,min_sample, metricにはそれぞれ以下の値を指定してください。
- eps:0-1。大きくすると離れた点をクラスタに取り込みやすくなります。
- min_sample:2以上の整数。クラスタを形成する最低の数を指定して下さい。
#クラスタリング
dbscan_dataset = cluster.DBSCAN(eps = eps, min_samples = min_sample).fit_predict(normalize_dataset)
後処理(各クラスタを要素とするリスト作成)
DBSCANを実行して出力された各点のクラスタを基準に、各クラスタを要素とするリストを作成します。
#クラスタ数抽出
data_class = np.unique(dbscan_dataset)
#各クラスタのデータ数を取得
class_list = [np.count_nonzero(dbscan_dataset == dc) for dc in data_class]
#データセットにクラスタを紐づけ
cluster_dataset = np.insert(dataset, col, dbscan_dataset, axis = 1)
#クラスタ順にソート
sorted_dataset = cluster_dataset[np.argsort(cluster_dataset[:, col])]
#データセットをクラスタごとにlistに格納
start, end = 0, 0
cluster_list = []
for cl in class_list:
end += cl
cluster_list.append(sorted_dataset[start:end, :col])
start = end
全体
データ作成から、出力までの全コードを以下に記載します。
データは0-30の整数を50行2列でランダム作成し、ランダムシードは11としています。
今回は、eps=0.2, min_sample=3としています。
import numpy as np
from sklearn import cluster, preprocessing
def DBSCAN_(dataset, eps = 0.5, min_sample = 4):
col = dataset.shape[1]
#正規化
normalize_dataset = preprocessing.minmax_scale(dataset)
#クラスタリング
dbscan_dataset = cluster.DBSCAN(eps = eps, min_samples = min_sample).fit_predict(normalize_dataset)
#クラスタ数抽出
data_class = np.unique(dbscan_dataset)
#各クラスタのデータ数を取得
class_list = [np.count_nonzero(dbscan_dataset == dc) for dc in data_class]
#データセットにクラスタを紐づけ
cluster_dataset = np.insert(dataset, col, dbscan_dataset, axis = 1)
#クラスタ順にソート
sorted_dataset = cluster_dataset[np.argsort(cluster_dataset[:, col])]
#データセットをクラスタごとにlistに格納
start, end = 0, 0
cluster_list = []
for cl in class_list:
end += cl
cluster_list.append(sorted_dataset[start:end, :col])
start = end
return data_class, cluster_list
if __name__ == "__main__":
#データ作成
np.random.seed(seed = 11)
data = np.random.randint(0, 30, (50, 2))
#DBSCANにてクララスタリング
data_class, cluster_list = DBSCAN_(data, eps = 0.2, min_sample = 3)
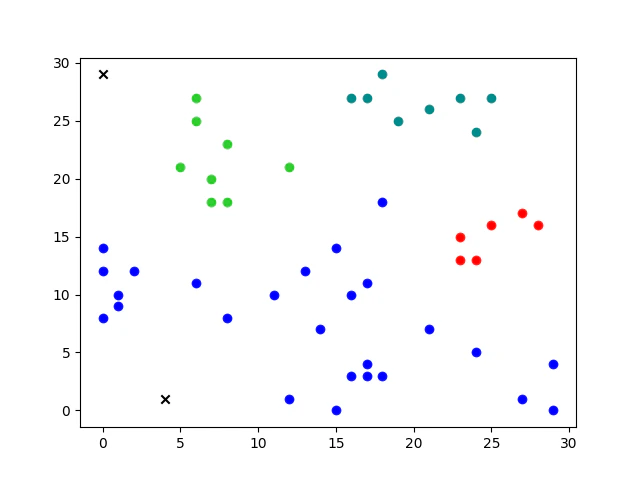
実行結果
plotする部分のコードは本題から逸れるため、割愛させていただきます。
xは外れ値、その他は各色ごとに1クラスタとなっております。
最後に
今回は、前処理・後処理を含めたDBSCANの関数化を行いました。今後も、面倒だなーと感じている部分を関数・クラス化して、楽をできるようにしていこうと思います。