Oracle Database 便利SQL
1.インスタンス作成
pfile起動でnomount状態へDB起動した上で、CREATE DATABASE実行
sed -i 's/XXX/<インスタンス名>/g' createdb.sql init.ora
======[createdb.sql]===============================================
startup nomount pfile='init.ora';
CREATE DATABASE XXX
USER SYS IDENTIFIED BY P#ssw0rd
USER SYSTEM IDENTIFIED BY P#ssw0rd
SET DEFAULT BIGFILE TABLESPACE
LOGFILE GROUP 1 ('+DG01/XXX/ONLINELOG/redo_grp1','+DG02/XXX/ONLINELOG/redo_grp1') SIZE 200M BLOCKSIZE 512,
GROUP 2 ('+DG01/XXX/ONLINELOG/redo_grp2','+DG02/XXX/ONLINELOG/redo_grp2') SIZE 200M BLOCKSIZE 512,
GROUP 3 ('+DG01/XXX/ONLINELOG/redo_grp3','+DG02/XXX/ONLINELOG/redo_grp3') SIZE 200M BLOCKSIZE 512
MAXLOGHISTORY 1
MAXLOGFILES 16
MAXLOGMEMBERS 3
MAXDATAFILES 1024
CHARACTER SET AL32UTF8
NATIONAL CHARACTER SET AL16UTF16
EXTENT MANAGEMENT LOCAL
ARCHIVELOG
DATAFILE '+DG03/XXX/DATAFILE/SYSTEM' SIZE 700M
SYSAUX DATAFILE '+DG03/XXX/DATAFILE/SYSAUX' SIZE 800M
DEFAULT TABLESPACE TBLSP01 DATAFILE '+DG03/XXX/DATAFILE/TBLSP01' SIZE 15360M
BIGFILE DEFAULT TEMPORARY TABLESPACE TEMPTBLSP01 TEMPFILE '+DG03/XXX/TEMPFILE/TEMPTBLSP01' SIZE 512M
BIGFILE UNDO TABLESPACE UNDOTBLSP01 DATAFILE '+DG03/XXX/DATAFILE/UNDOTBLSP01' SIZE 512M;
alter database mount;
alter database open;
@?/rdbms/admin/catalog.sql
@?/rdbms/admin/catproc.sql
@?/rdbms/admin/utlrp.sql
conn system/premera
@?/sqlplus/admin/pupbld.sql
conn / as sysdba
create spfile='+DG03/XXX/spfileXXX.ora' from pfile='/home/oracle/createdb/init.ora';
host echo SPFILE='+DG03/XXX/spfileXXX.ora' > /opt/app/oracle/product/dbhome_1/12.2.0/dbs/initXXX.ora
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
その他SQLスクリプトは以下参照
https://docs.oracle.com/en/database/oracle/oracle-database/12.2/refrn/sql-scripts.html#GUID-C308549C-A3DC-4CF2-9433-90650AD0F6DB
======[init.ora(Sample初期化パラメータファイル)]==========================
*._complex_view_merging=TRUE
*._fix_control='17760375:OFF'
*.audit_trail='XML','EXTENDED'
*.compatible='12.2.0.1.0'
*.control_file_record_keep_time=15
*.control_files='+DG01/XXX/CONTROLFILE/control01.ctl','+DG01/XXX/CONTROLFILE/control02.ctl'
*.db_block_checking='TRUE'
*.db_block_checksum='TRUE'
*.db_block_size=8192
*.db_cache_size=50331648
*.db_create_file_dest='+DG03'
*.db_create_online_log_dest_1='+DG01'
*.db_create_online_log_dest_2='+DG02'
*.db_domain=''
*.db_name='XXX'
*.db_writer_processes=4
*.ddl_lock_timeout=60
*.fast_start_mttr_target=1
*.log_archive_dest_1='LOCATION=+DG04'
*.log_archive_format='%T_%S_%R.dbf'
*.memory_target=0m
*.open_cursors=300
*.pga_aggregate_limit=0
*.pga_aggregate_target=10485760
*.processes=200
*.recyclebin='OFF'
*.remote_login_passwordfile='EXCLUSIVE'
*.sga_target=1073741824
*.statistics_level='TYPICAL'
*.streams_pool_size=16777216
*.undo_retention=900
*.undo_tablespace='UNDOTBLSP01'
SET LINESIZE 300;
SET PAGESIZE 100;
COLUMN PROPERTY_NAME FORMAT A30;
COLUMN PROPERTY_VALUE FORMAT A35;
COLUMN DESCRIPTION FORMAT A100;
SELECT * FROM DATABASE_PROPERTIES ORDER BY PROPERTY_NAME;
2.セッションとサーバープロセスの確認
set lin 10000 pagesize 10000 colsep |
col username format a10;
col program format a35;
col osuser format a10;
col spid format a10;
select sid,s.serial#,p.spid,s.username,s.osuser,
s.program,s.server,s.type,
round(p.PGA_USED_MEM/1024/1024) as "PGA_USED_MEM(MB)",
round(p.PGA_ALLOC_MEM/1024/1024) as "PGA_ALLOC_MEM(MB)",
round(p.PGA_MAX_MEM/1024/1024) as "PGA_MAX_MEM(MB)"
from V$session s,v$process p where s.paddr=p.addr;
set lin 10000 pagesize 10000 colsep |
col username format a10;
col program format a35;
col osuser format a10;
col spid format a10;
select sid,s.serial#,p.spid,s.username,s.osuser,
s.program,s.server,s.type,
round(p.PGA_USED_MEM/1024/1024) as "PGA_USED_MEM(MB)",
round(p.PGA_ALLOC_MEM/1024/1024) as "PGA_ALLOC_MEM(MB)",
round(p.PGA_MAX_MEM/1024/1024) as "PGA_MAX_MEM(MB)"
from V$session s,v$process p where s.paddr=p.addr
and s.type != 'BACKGROUND';
※SQL項目一覧
| 列名 | 説明 |
|---|---|
| sid | セッション識別子 |
| serial# | セッションシリアル番号。各セッションはsidとserial#の組み合わせで識別される |
| username | セッション接続しているユーザー名 |
| type | セッションタイプの識別。 「USER」は通常のセッション、「BACKGROUND」がバックグランドプロセスによる接続を表す |
| spid | OS上での該当セッションのプロセスID |
set lin 10000 pagesize 10000
col SQL_EXEC_START format a23;
col username format a20;
col PROGRAM(Client) format a30;
col sql_id format a15;
col sql_address format a20;
col STATUS format a10;
col PROGRAM(Oracle) format a40;
col sql_text format a40;
select distinct s.SQL_EXEC_START,s.sid,s.serial#,s.sql_id,s.username,s.program "PROGRAM(Client)",s.status,(sysdate - s.SQL_EXEC_START) *60*60*24 as "time(s)",p.sql_text from V$session s, V$sql p where s.sql_address = p.address and s.SQL_HASH_VALUE = p.HASH_VALUE order by 1;
set lin 10000 pagesize 10000
col SQL_EXEC_START format a23;
col username format a20;
col PROGRAM(Client) format a30;
col sql_id format a15;
col sql_address format a20;
col STATUS format a10;
col PROGRAM(Oracle) format a40;
col sql_text format a40;
select distinct s.SQL_EXEC_START,s.sid,s.serial#,s.sql_id,s.sql_address,s.SQL_HASH_VALUE,s.username,s.program "PROGRAM(Client)",s.status,(sysdate - s.SQL_EXEC_START) *60*60*24 as "time(s)",p.sql_text from V$session s, V$sql p,V$PROCESS v where p.sql_text LIKE '%BEGIN%SYS_EXPORT%' order by 1;
3.SQL調査関係
col SQL_ID format a20;
col SQL_TEXT format a100;
col FIRST_LOAD_TIME format a20;
col PARSING_SCHEMA_NAME format a20;
SELECT SQL_ID,FIRST_LOAD_TIME, PARSING_SCHEMA_NAME,SQL_TEXT FROM V$SQL
WHERE SQL_ID='&1' and FIRST_LOAD_TIME
BETWEEN TO_CHAR(SYSDATE - (120 / 24 / 60), 'YYYY-MM-DD/HH24:MI:SS')
AND TO_CHAR(SYSDATE, 'YYYY-MM-DD/HH24:MI:SS')
ORDER BY FIRST_LOAD_TIME;
※全く同一のSQL文は初めのものしか出ない。
set linesize 800
set pagesize 1000
set trimspool on
set verify off
set tab off
set colsep ‘|’
alter session set nls_date_format='yyyy/mm/dd HH24:mi:ss';
col username for a10
col opname for a30
col target for a25
col target_desc for a15
col sql_id for a15
select username, opname, target, target_desc, sql_id,start_time,max(elapsed_seconds) seconds
from v$session_longops
where username is not null
and elapsed_seconds > 1
group by username, opname, target, target_desc, start_time, sql_id
order by 2, 3;
※実行に6秒以上かかっているものを表示
4. Extent管理に関して
set pagesize 1000 linesize 10000
col SEGMENT_NAME for a24
select SEGMENT_NAME, TABLESPACE_NAME, EXTENT_ID, BYTES, BLOCKS
from USER_EXTENTS order by 1,2,3;
●エクステント管理方式によって以下相違点があり(ローカル管理前提)
自動割当てエクステント「AUTOALLOCATE」を設定した場合、次のような動作となります。
・記号セグメント・サイズが1MBまでのエクステント・サイズは64KB
・セグメント・サイズが64MBまでのエクステント・サイズは1MB
・セグメント・サイズがそれ以上の場合のエクステント・サイズは8MB or 64MB
(検証の結果、1GB越えるとエクステントサイズ64MBになることも・・・)
一方で「UNIFORM」指定の表領域の場合はセグメントのサイズに関わらずエクステントサイズが一定
create table時のinitial指定だが、initialに指定したサイズを最適に割り当てるようにエクステントが割り当てされる。(520Mだと64M×8+8MB×1のような)
※truncateしてもinitial値まではエクステントの解放はされない。
※alter table ・・・ shrink spaceだと使っていないブロックレベルまで解放する。その後の領域追加は、元と同じようにエクステント確保。
create table時のnextは指定しても無視される。
5. HWM調査
set pagesize 1000 linesize 10000
col TABLE_NAME for a30
col BLOCKS for a40
SELECT TABLE_NAME,BLOCKS * 8 / 1024 as "HWM(MB)" from user_tables;
※注意点として、上記SQL上としては最新の統計情報を取らないと正確な情報は得られない。
6. SGA・PGA関連
select pool,bytes/1024/1024 MB from v$sgastat where name = 'buffer_cache';
select pool,sum(bytes) / 1024/1024 MB from v$sgastat where name != 'free memory' group by pool;
select pool,sum(bytes) / 1024/1024 MB from v$sgastat group by pool;
7. 共有プール拡張モード閲覧
col COMPONENT format a20;
col OPER_TYPE format a20;
col OPER_MODE format a20;
select COMPONENT,OPER_TYPE,OPER_MODE,INITIAL_SIZE,TARGET_SIZE,FINAL_SIZE,START_TIME,END_TIME from v$sga_resize_ops where COMPONENT = 'shared pool' or COMPONENT = 'buffer cache';
8. 待機イベント
col EVENT format a50;
col sql_id format a15;
col username format a20;
col WAIT_CLASS format a20;
col sql_text format a70;
col status format a13;
select a.sid,a.username,a.sql_id,a.event,a.wait_class,a.status,b.sql_text from v$session a,v$sql b where a.sql_id=b.sql_id and a.username='DP';
col WAIT_CLASS format a20;
select SID,EVENT,WAIT_CLASS,TOTAL_WAITS,TIME_WAITED from v$session_event where sid=&1 order by 5 desc;
9. AWRレポート
select dbid, snap_id, to_char(end_interval_time, 'yyyy/mm/dd hh24:mi') getsnapshot_time, snap_level from DBA_HIST_SNAPSHOT order by dbid, snap_id;
EXECUTE DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT();
@?/rdbms/admin/awrrpt.sql
10. SQLトレース取得
⒈自セッション
-- ALTER SESSION SET EVENTS '10046 trace name context forever, level 12'; と同じ
EXECUTE DBMS_SESSION.SESSION_TRACE_ENABLE(waits => true, binds => true);
-- ALTER SESSION SET EVENTS '10046 trace name context forever, level 16'; と同じ
EXECUTE DBMS_SESSION.SESSION_TRACE_ENABLE(waits => true, binds => true, plan_stat=>'ALL_EXECUTIONS');
ALTER SESSION SET TRACEFILE_IDENTIFIER = "XXXXXXXXX";
EXECUTE DBMS_SESSION.SESSION_TRACE_DISABLE;
set linesize 100
col TRACEFILE for a100
SELECT p.tracefile FROM v$session s JOIN v$process p ON s.paddr = p.addr WHERE s.sid = SYS_CONTEXT('userenv','sid');
2.他セッション
BEGIN
DBMS_MONITOR.SESSION_TRACE_ENABLE(
session_id => 611,
serial_num => 32130,
waits => true,
binds => true,
plan_stat=>'ALL_EXECUTIONS');
END;
/
EXECUTE DBMS_MONITOR.SESSION_TRACE_DISABLE(session_id => 611, serial_num => 32130);
11. 断片化状態確認
set lin 10000
col segment format a60
select tablespace_name tablespace,file_id,block_id,blocks,owner||'.'||segment_name segment
from dba_extents where tablespace_name='TBLSP01'
union
select tablespace_name tablespace,file_id,block_id,blocks,' '
from dba_free_space where tablespace_name='TBLSP01'
order by 1,2,3;
12.パスワードファイル
パスワードファイルはsysdbaやsysoper権限を持つユーザーがパスワードログインするために利用するファイル。
orapwdコマンドはこのパスワードファイルを作成するためのコマンド。
また、初期化パラメータ REMOTE_LOGIN_PASSWORDFILE が NONE 以外である必要性がある。
### パスワードファイル作成
orapwd file=$ORACLE_HOME/dbs/orapwXXX password=P#ssw0rd entries=10
### パスワードファイルの情報から、どのユーザーに特権が付与されているか確認
select * from v$pwfile_users;
3.各Database構成コンポーネント
①制御ファイル
■制御ファイルパス確認
ruby:制御ファイルのパス確認
col name format a100;
select name from v$controlfile;
■制御ファイル多重化手順
1.制御ファイルのパス変更
ALTER SYSTEM SET control_files = '<new path1>','<new path2>' SCOPE = SPFILE;
2.データベースを停止
3.存在している制御ファイルを新しい場所へコピー
4.データベースを起動
②オンラインREDOログファイル
■オンラインREDOログファイルのパス確認
col member format a100;
SELECT A.GROUP#,A.BYTES,A.STATUS,B.TYPE,B.MEMBER from v$LOG A right outer join v$logfile B ON A.group# = B.group#;
■オンラインREDOログファイル多重化手順
1.データベースをMOUNT状態で起動
2.REDOロググループ作成
alter database add logfile group x ('<newパス>') SIZE xxxM;
3.REDOログメンバー作成
alter database add logfile member '<newパス>' to group x;
4.データベースOPEN
※REDOログバッファからREDOログファイル書き込みタイミング
・トランザクションcommit時
・DBWnがREDOデータの書き込みを要求した時
・3秒ごとのタイムアウトが発生した時
・REDOログバッファが不足した時
・未書き込みのREDOデータがREDOログバッファの3分の1を超えた時
※強制ログスイッチ実行
alter system switch logfile;
→振り逃げ
alter system archive log current;
→アーカイブログ完了ををもって終了。バックアップ前等に推奨。
RMANではバックアップ時に内部的に利用されている。
③アーカイブREDOログファイル
ARCHIVE LOG LIST;
SELECT NAME,LOG_MODE from V$DATABASE;
ALTER DATABASE ARCHIVELOG;
col name format a100;
SELECT name,sequence# from V$ARCHIVED_LOG order by 2;
④表領域・データファイルの状態確認
col TABLESPACE_NAME for a15
col EXTENT_MANAGEMENT for a17
col ALLOCATION_TYPE for a15
col SEGMENT_SPACE_MANAGEMENT for a24
col BIGFILE for a7
select TABLESPACE_NAME,EXTENT_MANAGEMENT,ALLOCATION_TYPE,SEGMENT_SPACE_MANAGEMENT,BIGFILE,STATUS from DBA_TABLESPACES;
col TABLESPACE_NAME format a30
col FILE_NAME format a50
col STATUS format a10
col MBYTES format 9,999,990
col INCRE format 9,999,990
col AUTOEXTENSIBLE format a5
col ONLINE_STATUS format a6
select tablespace_name,file_name,status,bytes/1024/1024 mbytes,increment_by,autoextensible,online_status from dba_data_files;
select
tablespace_name,
to_char(nvl(total_bytes / 1024,0),'999,999,999') as "Total(KB)",
to_char(nvl((total_bytes - free_total_bytes) / 1024,0),'999,999,999') as "Used(KB)",
to_char(nvl(free_total_bytes/1024,0),'999,999,999') as "Free(KB)",
round(nvl((total_bytes - free_total_bytes) / total_bytes * 100,100),2) as "Utilization(%)"
from
( select tablespace_name,sum(bytes) total_bytes
from dba_data_files group by tablespace_name)
left join
( select tablespace_name as free_tablespace_name,sum(bytes) free_total_bytes
from dba_free_space group by tablespace_name)
on tablespace_name = free_tablespace_name order by 1;
col TABLESPACE_NAME format a30;
select * from dba_temp_free_space;
◆dba_temp_free_spaceのカラム説明
TABLESPACE_SIZE:一時表領域のサイズ
ALLOCATED_SPACE:使用中領域+再利用可能領域
FREE_SPACE:再利用可能領域+未使用領域(shrink spaceで圧縮可能なサイズ)
⑤メモリ使用状況の確認
select * from v$sga; #簡易
select * from v$sgastat; #詳細
SGAの障害の問題切り分けのために必要な情報
- データベース・バッファ・キャッシュ
- データベース・バッファ・ヒット率
-
共有プール
- ライブラリ・キャッシュ・ヒット率
- ディクショナリ・キャッシュ・ヒット率
-
V$BUFFER_POOL_STATISTICS
- DB_BLOCK_GETS 読み込んだブロック数
- CONSISTENT_GETS メモリから読み込めたブロック数
- PHYSICAL_READS ディスクから読み込んだブロック数
SET SERVEROUTPUT ON;
DECLARE
d_gets NUMBER;
c_gets NUMBER;
p_reads NUMBER;
result NUMBER;
BEGIN
select DB_BLOCK_GETS into d_gets from V$BUFFER_POOL_STATISTICS where NAME='DEFAULT';
select CONSISTENT_GETS into c_gets from V$BUFFER_POOL_STATISTICS where NAME='DEFAULT';
select PHYSICAL_READS into p_reads from V$BUFFER_POOL_STATISTICS where NAME='DEFAULT';
result:=round((1-(p_reads/(d_gets+c_gets))),3)*100;
DBMS_OUTPUT.PUT_LINE('Database Buffer Cache Hit =>>' || result || '(%)');
END;
/
- DEFAULT バッファプール
- KEEPやRECYCLEなど以外の残りのテーブル用として必ず存在します。これが一番大きな領域になります。
col OWNER for a8
col OBJECT_NAME for a16
select OWNER, OBJECT_NAME, count(*) "BUFFERS", count(*)*8/1024 "MB"
from V$BH, DBA_OBJECTS
where OBJD = DATA_OBJECT_ID and OWNER = '&1' and V$BH.STATUS != 'free'
group by OWNER, rollup(OBJECT_NAME)
order by 4 ;
- KEEP バッファプール
- 常に頻繁に使用するような小さなテーブルがある場合などは、それをKEEPプールに指定すると良い。
- オブジェクトのサイズよりプールサイズが大きくないと意味がないので注意。すべて載らないと再度アクセスしたら読込みし直してしまうため。
- あまり大きいテーブルを指定するのは現実的ではないと思います。
col OWNER format a20
col OBJECT_NAME format a40
select o.owner,o.object_name,o.object_type,o.status,s.buffer_pool,count(*) as blocks
from dba_objects o,x$bh b,dba_segments s
where b.obj=o.data_object_id
and o.owner = &1
and s.owner = &1
and o.object_name=s.segment_name
and o.object_type=s.segment_type
group by o.owner,o.object_name,o.object_type,o.status,s.buffer_pool
order by blocks;
※ buffer_pool列がKEEP
set lines 150 pages 5000
col NAME for a48
select S.NAME, M.VALUE
from V$MYSTAT M, V$STATNAME S
where M.STATISTIC# = S.STATISTIC#
and S.NAME like 'physical read%'
order by 1 ;
●V$LIBRARYCACHE
PINS
データ・オブジェクトに関する情報要求の合計件数
RELOADS
あるオブジェクトの任意のPIN(ただし、オブジェクト・ハンドルの作成後に実行された最初のPIN以外)。ディスクからそのオブジェクトをロードするように要求する。
SET SERVEROUTPUT ON;
DECLARE
pins NUMBER;
reloads NUMBER;
result NUMBER;
BEGIN
select SUM(PINS) into pins from V$LIBRARYCACHE;
select SUM(RELOADS) into reloads from V$LIBRARYCACHE;
result:=round((1-(reloads/pins)),3)*100;
DBMS_OUTPUT.PUT_LINE('Library Cache Hit =>>' || result || '(%)');
END;
/
●V$ROWCACHE;
GETS
データ・オブジェクトに関する情報要求の合計件数
GETMISSES
結果的にキャッシュ・ミスになったデータ要求の数
SET SERVEROUTPUT ON;
DECLARE
gets NUMBER;
getmisses NUMBER;
result NUMBER;
BEGIN
select SUM(GETS) into gets from V$ROWCACHE;
select SUM(GETMISSES) into getmisses from V$ROWCACHE;
result:=round((1-(getmisses/gets)),3)*100;
DBMS_OUTPUT.PUT_LINE('Dictionary Cache Hit =>>' || result || '(%)');
END;
/
select * from v$pgastat;
⑥STATSPACK利用
select snap_id, to_char(snap_time, 'yy-mm-dd hh24:mi:ss') snap_time from stats$snapshot order by snap_id;
select snap_level from stats$statspack_parameter;
execute statspack.snap;
execute statspack.snap(i_snap_level=> 6)
@?/rdbms/admin/spreport.sql;
ご参考
https://qiita.com/sugitk/items/7a7183e75bd9872d380f
★STATSPACK見方
オプティマイザに関して
⑴テーブルには適切なサンプル・サイズの統計
-テーブルのオプティマイザ統計収集にはソート処理を行う必要があり、大規模テーブルでは非常に時間がかかる
-通常は5%程度で構わない。
-Oracle10gからOracle内部で最適な値を決めるようになったのでそれに任せるも可
(estimate_percent=>DBMS_STATS.AUTO_SAMPLE_SIZE)
select num_rows,sample_size,last_analyzed from dba_tables where table_name='<TABLE名>';
⑵索引には完全な統計
-索引はソート済みになっている(ソート処理が必要ない)ので、完全に(100%で)収集
-Oracle Database 10gからは索引作成または再構築時にオプティマイザ統計が自動的に収集される。
-DBMS_STATS パッケージのパラメータの値も、Oracle Database 10gからのデフォルトはcascade=>DBMS_STATS.AUTO_CASCADE(索引の統計を収集する必要があるかどうかと最適なサンプル・サイズを Oracle が決定する)になる
select index_name,sample_size,last_analyzed from dba_indexes where table_name='<TABLE名>';
⑶データに偏りがある列はヒストグラム統計
-データの分布に偏りがある列をWHERE句の条件に使用したSQL文は実行計画が最適でない可能性がある(苗字が'鈴木'さんと'林'さんでは該当件数が異なりますので、最適な実行計画も異なる可能性がある)
-DBMS_STATS パッケージのパラメータの値も、通常はmethod_opt=>'FOR ALL COLUMNS SIZE AUTO'(Oracle Database 10gR2からのデフォルト)で問題ありません(Oracleが自動的にどの列がヒストグラムを必要とするかどうかと、各ヒストグラムが必要とするバケットの数(多いほど精度が高い)を判別します)。
select num_backets from dba_tab_columns where table_name='<TABLE名>' and column_name='<列名>'
4.ロックの仕組み
参考)
http://typea.info/tips/wiki.cgi?page=Oracle+Database10g+%A5%ED%A5%C3%A5%AF%A4%CE%BC%EF%CE%E0
https://www.insight-tec.com/mailmagazine/ora3/vol054.html
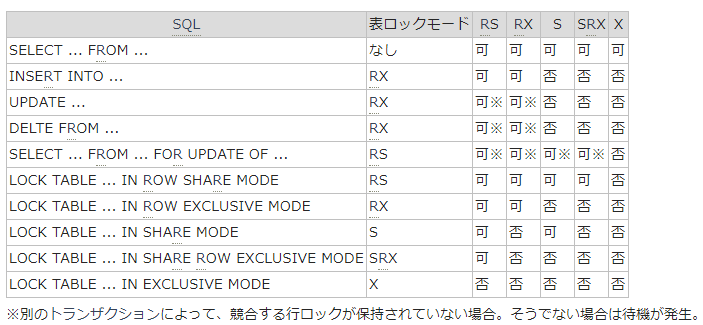
表ロック(TM)種類一覧↓
col username format a15
col object_name format a30
col machine format a15
col osuser format a15
col last_sql_text format a100
SELECT a.sid,a.serial#,e.pid,e.spid,a.username,d.object_name,a.status,a.machine,a.osuser,b.type,b.lmode,a.program,b.CTIME lock_time,b.block,b.request,a.sql_id last_sql_id,(select sql_text from V$SQLAREA where sql_id=a.sql_id) as last_sql_text
FROM V$SESSION a,V$LOCK b,V$LOCKED_OBJECT c,dba_objects d,V$PROCESS e
WHERE
a.SID = b.SID
AND a.SID = c.SESSION_ID
AND b.TYPE IN ('TX','TM')
AND c.OBJECT_ID = d.OBJECT_ID
AND a.PADDR=e.ADDR
order by a.sid,b.type asc
;
alter system kill session '<SID>,<#SERIAL>';
補足
- TX ロックは行ロック。TM はテーブル全体に対するロック。TX ロックが取られているときは、少なくとも TM ロックは取得される。
- block=1のロックについては、他のトランザクションからのロック要求をブロックしている
- request=1以上のロックはロックをリクエストしているが、他のトランザクションでロックを既に取得されているため、ロックを取得できていない状況。
- CTIME の単位は秒数。
- LMODEとREQUESTはロックモードを表す。
- 0 なし
- 1 NULL
- 2 行共有ロック(RS)
- 3 行排他ロック(RX)
- 4 表共有(S)
- 5 表共有/行排他(SRX)
- 6 排他(X)
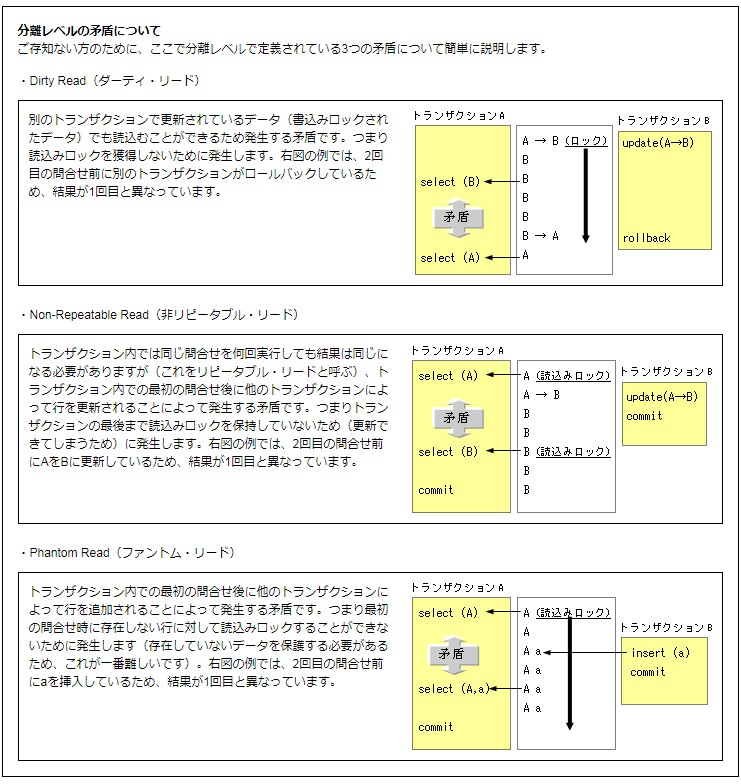
5.トランザクションの分離レベルに関して
https://www.oracle.com/technetwork/jp/database/articles/tsushima/tsm18-1610822-ja.html
(2)分離レベルについて/(3)Oracleデータベースの分離レベル
OracleはREAD COMMITTEDがデフォルト。
READ COMMITTEDだと以下の読み取り一貫性に関する事象のうちでNon-Repeatable ReadとPhantom Readは起きうるが、
SERIALIZABLEだと全て起きえない。パフォーマンスはREAD COMMITTEDの方が高い。
変更時は以下で可。
SQL> SET TRANSACTION ISOLATION LEVEL <分離レベル> ;
99.高度な例
表領域暗号化(Advanced Security)
https://www.insight-tec.com/mailmagazine/ora3/vol366.html
https://enterprisezine.jp/dbonline/detail/3538?p=2
$ ls $ORACLE_BASE/wallet
ewallet.p12
$ orapki wallet create -wallet $ORACLE_BASE/wallet -pwd "wallet_pass" -auto_login
$ ls $ORACLE_BASE/wallet
cwallet.sso ewallet.p12
SELECT t.name, e.encryptionalg algorithm FROM v$tablespace t, v$encrypted_tablespaces e WHERE t.ts# = e.ts#;
便利スクリプト集
http://www.doppo1.net/index.html
99.PSU/DBBP適用手順
1.Oracle/Grid停止
${ORACLE_HOME}/OPatch/opatch prereq CheckConflictAgainstOHWithDetail -oh ${ORACLE_HOME} -phBaseDir <パッチTOP-DIR>
${ORACLE_HOME}/crs/install/roothas.sh -prepatch
※GridHomeのみ。rootで実行
${ORACLE_HOME}/OPatch/opatch apply -silent -oh ${ORACLE_HOME} <パッチTOP-DIR>
${ORACLE_HOME}/rdbms/install/rootadd_rdbms.sh
${ORACLE_HOME}/crs/install/roothas.sh -postpatch
※GridHomeのみ。rootで実行
2.スケジューラーを利用した処理実行
BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'job1',
job_type => 'STORED_PROCEDURE',
job_action => 'MARIO.TEST_PROC',
start_date => to_date('2015/01/01 00:00:00','yyyy/mm/dd hh24:mi:ss'),
repeat_interval => 'FREQ=DAILY;INTERVAL=5',
end_date => to_date('2015/12/31 00:00:00','yyyy/mm/dd hh24:mi:ss'),
auto_drop => FALSE,
enabled => TRUE);
END;
/
BEGIN
DBMS_SCHEDULER.ENABLE('job1');
END;
/
BEGIN
DBMS_SCHEDULER.DISABLE('job1');
END;
/
BEGIN
DBMS_SCHEDULER.DROP_JOB('job1');
END;
/
999.テストデータ系
SET LINESIZE 10000
SET PAGESIZE 0
SET SQLPROMPT OFF
SET FEEDBACK OFF
SET TERMOUT OFF
SET TRIMSPOOL ON
SET SERVEROUTPUT OFF
SPOOL test.csv
SELECT col1 ||','|| col2 FROM tbl1;
SPOOL OFF
QUIT
100.SYSスキーマ統計情報系
・ディクショナリ統計
prompt 'Statistics for SYS tables'
SELECT NVL(TO_CHAR(last_analyzed, 'YYYY/MM/DD HH:MI'), 'NO STATS') last_analyzed, COUNT(*) dictionary_tables
FROM dba_tables
WHERE owner = 'SYS'
GROUP BY TO_CHAR(last_analyzed, 'YYYY/MM/DD HH:MI')
ORDER BY 1 DESC;
EXEC DBMS_STATS.GATHER_DICTIONARY_STATS;
・固定オブジェクト統計
prompt 'Statistics for Fixed Objects'
select NVL(TO_CHAR(last_analyzed, 'YYYY/MM/DD HH:MI'), 'NO STATS') last_analyzed, COUNT(*) fixed_objects
FROM dba_tab_statistics
WHERE object_type = 'FIXED TABLE'
GROUP BY TO_CHAR(last_analyzed, 'YYYY/MM/DD HH:MI')
ORDER BY 1 DESC;
EXEC DBMS_STATS.GATHER_FIXED_OBJECTS_STATS;
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=378719737545820&id=1450820.1&displayIndex=7&_afrWindowMode=0&_adf.ctrl-state=eud18fe8d_154#aref_section22
https://support.oracle.com/epmos/faces/DocumentDisplay?_afrLoop=379813878027888&id=1474937.1&_afrWindowMode=0&_adf.ctrl-state=eud18fe8d_439
リソースマネージャの利用方法
https://www.oracle.com/technetwork/jp/database/focus-areas/performance/resource-manager-twp-133705-ja.pdf
複数のワークロードのためのリソース・マネージャの構
Cursor_Sharing
https://www.istudy.co.jp/blog/plsql/095
文字化け(NLS関連)
http://www.atmarkit.co.jp/ait/articles/0901/21/news124.html
http://otndnld.oracle.co.jp/tech/globalization/htdocs/nls_lang%20faq.htm
マルチテナントデータベース
https://www.ashisuto.co.jp/corporate/column/technical-column/detail/1197775_2274.html
・オプション一覧(追加費用情報含む)
https://docs.oracle.com/cd/E49329_01/license.121/b71334/editions.htm
オプティマイザ統計/実行計画
概要
SQL実行時の処理にかかるコストを計算して、最少コストの実行計画を決定するのがコストベース・オプティマイザ(CBO)。
(これに対してSQL文のルールによって実行計画を決定するのがルールベース・オプティマイザ(RBO)です。以前のバージョンでは両方使用できたが今はCBO)。
- オプティマイザ統計の例
- テーブル統計(行数、ブロック数、平均行長など)
- 列統計(カーディナリティ、NULLの数、最小値、最大値、ヒストグラムなど。ヒストグラムがない場合は、最小値と最大値でデータ分布を均一とする)
- 索引統計(リーフブロック数、ツリーの高さ、クラスタ化係数などの索引の有効性)
- システム統計(CPU性能、I/O性能など)
CBOはオプティマイザ統計情報を元にフルスキャン、索引スキャン、テーブル結合順序などのコストを算定してもっとも低いコストの実行計画を選択する。
SQLの内部動作のどこでこれが実施されるかというと以下の「最適化」の部分である。
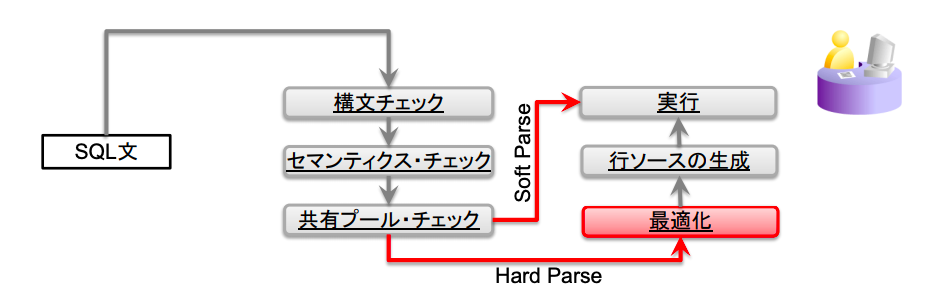
解析フェーズ(1)
-
構文チェック
- SQL構文の妥当性をチェック
-
セマンティクスチェック
- SQL文内のオブジェクト及び列が存在するか等の文の意味の有効性を確認
解析フェーズ(2)
- 共有プール(ライブラリ・キャッシュ)に同一SQL文の実行計画が存在するかチェックする。
- 有 -> ソフトパース
- 無 -> ハードパース ※ライブラリキャッシュはLRUアルゴリズムにより使用頻度の少ないSQL実行計画を破棄していく仕組みなので、頻繁にアクセスされるSQLは追い出されないような適切な共有プールサイズの設計が必要。
統計情報の収集はDBMS_STATSパッケージを利用する。
##テーブル統計情報収集
set lin 10000 pagesize 10000 time on timing on colsep |
col table_name format a25
col partition_name format a25
select table_name,partition_name,object_type,num_rows,blocks,chain_cnt,
sample_size,avg_row_len,global_stats,stattype_locked,last_analyzed
from user_tab_statistics order by 1;
##インデックス統計情報収集
set lin 10000 pagesize 10000 time on timing on colsep |
col index_name format a25
col table_name format a25
col partition_name format a25
select index_name,blevel,leaf_blocks,clustering_factor,table_name,
partition_name,sample_size,global_stats,stattype_locked,last_analyzed
from user_ind_statistics order by 1;
※インデックスは作成時またはREBUILD時に索引統計が取られるので明示的に取得することは基本的には不要。
###SQL実行時に実行結果と実行計画出力
set autotrace on;
###SQL実行時に実行計画のみ出力
set autotrace traceonly;
###同一セッションで直前に実行したSQLの実行計画取得(共有カーソルに残っている必要があり)
select * from table(DBMS_XPLAN.DISPLAY_CURSOR());
###SQLIDを指定して実行計画取得(共有カーソルに残っている必要があり)
1)SQLIDをSQLTEXTのwhere条件で出力
select sql_id, sql_text from v$sql where sql_text like 'select emp.first_name%';
2)実行計画取得
select * from table(DBMS_XPLAN.DISPLAY_CURSOR(<SQLID>));
###実行計画の見方
1.実行計画は、インデントがされていて、インデントが右に行くほど深い。そして深い順に実行される。
2.深さが同じ場合は、上から順。
下記の例だと、
1.XXX1のフルスキャン
2.XXX2のフルスキャン
3.XXX1とXXX2のHash Join結合
(例)
01:18:38 SQL> select a.col1,b.col2 from XXX11 A inner join XXX12 B on a.col1 = b.col1;
1000000 rows selected.
Elapsed: 00:00:15.69
Execution Plan
----------------------------------------------------------
Plan hash value: 3006947627
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 996K| 12M| | 10508 (1)| 00:00:01 |
|* 1 | HASH JOIN | | 996K| 12M| 16M| 10508 (1)| 00:00:01 |
| 2 | TABLE ACCESS FULL| XXX11 | 996K| 4867K| | 4365 (1)| 00:00:01 |
| 3 | TABLE ACCESS FULL| XXX12 | 1002K| 7829K| | 4366 (1)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("A"."COL1"="B"."COL1")
Statistics
----------------------------------------------------------
45 recursive calls
15 db block gets
98443 consistent gets
31742 physical reads
3024 redo size
22721309 bytes sent via SQL*Net to client
733934 bytes received via SQL*Net from client
66668 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
1000000 rows processed
01:20:02 SQL>
統計情報失効
統計情報を収集する場合、時間短縮のために全てではなく、失効した統計情報のオブジェクトのみ取得する方法がある。
統計情報を最後に収集してから指定した更新割合を超えているオブジェクトについては、統計情報が失効されたと認識される。
exec DBMS_STATS.GATHER_SCHEMA_STATS(ownname => 'TRY', options => 'GATHER STALE');
-- 閾値変更
exec DBMS_STATS.SET_SCHEMA_PREFS(ownname => 'TRY', pname => 'STALE_PERCENT', pvalue => 5);
-- 閾値が変更されたかの確認
select TABLE_NAME, DBMS_STATS.GET_PREFS(pname => 'STALE_PERCENT', ownname => 'TRY', tabname => TABLE_NAME) "STALE_PERCENT" from USER_TABLES;
select TABLE_NAME, INSERTS, UPDATES, DELETES, TRUNCATED from USER_TAB_MODIFICATIONS ;
-- どうやら統計情報更新後はそのテーブルに関しては記録されないらしい。
SET SERVEROUTPUT ON
DECLARE
obj_list DBMS_STATS.ObjectTab := DBMS_STATS.ObjectTab() ;
BEGIN
DBMS_STATS.GATHER_SCHEMA_STATS(ownname=>'TRY', objlist=> obj_list, options=>'LIST STALE') ;
FOR i in obj_list.FIRST.. obj_list.LAST LOOP
dbms_output.put_line(obj_list(i).objtype || ' ' ||
obj_list(i).ownname || '.' ||
obj_list(i).objname || ' ' ||
nvl(obj_list(i).partname, 'NonPartition') || ' – ' ||
nvl(obj_list(i).subpartname, '*'));
END LOOP;
END;
/
統計情報保留
対象のオブジェクトに対する統計情報保留の設定をしておくことで、実際に統計情報収集を行なった場合でも、新しく取得された統計情報の公開を一時的に遅らせることが可能。
新しく取得した統計情報のテストなどしたいときに重宝します。
exec DBMS_STATS.SET_TABLE_PREFS(ownname => 'TRY', tabname => 'TBL10', -
pname => 'PUBLISH', pvalue => 'FALSE');
select DBMS_STATS.GET_PREFS(pname => 'PUBLISH', ownname => 'TRY', tabname => 'TBL10') from DUAL ;
DBMS_STATS.GET_PREFS(PNAME=>'PUBLISH',OWNNAME=>'TRY',TABNAME=>'TBL10')
--------------------------------------------------------------------------------
FALSE
exec DBMS_STATS.GATHER_TABLE_STATS(ownname => 'TRY', tabname => 'TBL10');
set head off trim on linesize 1000 pagesize 0 long 1000000 longchunksize 1000000
select REPORT, MAXDIFFPCT from table(DBMS_STATS.DIFF_TABLE_STATS_IN_PENDING('TRY', 'TBL10'));
-- OPTIMIZER_USE_PENDING_STATISTICS を TRUE にする。
alter session set OPTIMIZER_USE_PENDING_STATISTICS = TRUE ;
-- Publish or DELETE Pending Statistics
BEGIN
DBMS_STATS.PUBLISH_PENDING_STATS(ownname => 'TRY', tabname => 'TBL10', no_invalidate => FALSE);
END;
/
(参考)
1.統計情報に関して詳しい記事
https://www.oracle.com/assets/20151015-optimizer-2348097-ja.pdf
https://www.oracle.com/technetwork/jp/database/articles/tsushima/tsm05-1598251-ja.html
2.インデックス種類や各インデックススキャン、インデックスのメンテナンスについて詳細
https://www.oracle.com/technetwork/jp/ondemand/database/db-basic/performance-tuning-251737-ja.pdf
3.結合(JOIN)処理(Nested Loop/Hash Join/Sort Merge)
https://www.meganii.com/blog/2015/06/01/how-to-move-join-nestedloops-hash-sortmerge/
パラレル処理についておまとめ
パラレル化とは1プロセスで実施していた処理を複数プロセスに分割してそれぞれが異なるブロックを処理することによって全体での処理の高速化を図る方法。ちなみに、Oracleデータベースで可能なパラレル処理。
1.検索処理のパラレル化(パラレルクエリー)
select文による問い合わせ処理に関してパラレルクエリが可能。
- 全表スキャン(FULL TABLE SCAN)
- 索引高速スキャン(INDEX FAST FULL SCAN)
- パラレル索引スキャン
- すべての結合
- ソート
- グループ関数の集計
*セッション単位
ALTER SESSION FORCE PARALLEL QUERY PARALLEL 2;
*オブジェクト単位
スキーマオブジェクトのparallel属性に設定
*文単位
SELECT /*+ PARALLEL(XXX,2) */ ... from XXX;
2.パラレルDDL
表および索引に対するDDL文はそれらの表や索引がパーティション化されているかどうかにかかわらずパラレル化可能。
- CREATE TABLE ... AS SELECT ...
- CREATE INDEX ...
- ALTER INDEX ... REBUILD
ヒント句でパラレル指定するか、セッション単位でパラレル指定する。
例
<セッション単位>
ALTER SESSION FORCE PARALLEL DDL PARALLEL 4;
<文単位>
CREATE TABLE ... PARALLEL 4 AS SELECT...
CREATE INDEX ... PARALLEL 4;
ALTER INDEX ... REBUILD PARALLEL 4;
(注意)CREATE TABLE ... AS SELECT ...に関してはCREATE操作がパラレル化されれば問い合わせ(SELECT)部分も同一パラレル度でパラレル化される。仮にCREATE部分がパラレル化されない場合は、問い合わせ(SELECT)部分は、SELECT部分にPARALLELヒントがある場合、または選択される表(またはパーティション索引)にパラレル宣言がある場合のみパラレル化される。
3.パラレルDML(INSERT/UPDATE/DELETE)
更新DML文に対してもパラレル処理が可能。
1実行されている状態かつ、表定義または1で既にパラレル度を付与している場合は普通にDML文実行するとパラレル化される。
またはヒント句をつけて明示的にパラレル化する。
1.DML実行前にパラレルDMLを有効化する。これをしないと、後続で仮にント句をつけてもパラレル化されない。
alter session force parallel dml parallel 2;
2.パラレル処理は下記の優先順位で反映される。
DML文のパラレル・ヒントに指定されている値
alter session force parallel dml parallel 文で指定した値
表作成時に指定したパラレル度
<特殊なケース: INSERT INTO ... SELECT ...文の場合>
INSERT処理とSELECT処理両方に対して、ヒント句または対象表定義により、パラレル度を分割指定可能できる。
ダイレクトパスインサートを用いる。INSERT INTO ... SELECT ...で高速にデータを挿入する。
ダイレクトパスインサートはバッファキャッシュを経由せず、またREDOを生成せずに、
直接ディスク上のデータファイルに書き込みができるので高速にデータ挿入ができる。
バッファキャッシュを経由しないので、データをキャッシュから追い出すことがないというメリットもある。
*APPEND句付与
INSERT /*+ APPEND */ INTO 新テーブル SELECT * FROM 旧テーブル;
<ダイレクトパスインサートの注意点>
1. REDO情報が書き込まれないので、コミット処理やロールバック処理等のトランザクションを制御することができない。(実行したらコミットかロールバックを実行しないと後続処理は実行不可)
2. 実行すると「テーブルロック」がかかる。
3. ハイウォーターマーク以降からインサート処理が実行される。
表圧縮に関して
Oracleには表のデータを圧縮できる機能がある。圧縮によってデータブロック内の重複値を削除可能である。
同じ値を多く含む表の場合、圧縮を使うことでディスク領域が節約され、データバッファキャッシュ内で使用されるメモリ量が削減される。
主に以下の2種類の圧縮方法が存在する。
| 表圧縮方法 | 圧縮率 | CPUオーバーヘッド | 圧縮タイミング | 適しているアプリケーション |
|---|---|---|---|---|
| 基本表圧縮 | 高い | 最小 | バルクロード時 (※1) | DSS |
| 拡張表圧縮 | 低い | 最小 | 全てのDML | OLTP,DSS |
※1 バルクロードとは・・・
- ダイレクトパスSQL* Loader
- CREATE TABLE AS SELECT
- パラレルINSERT
- APPENDヒント句を利用したINSERT
alter table ... row store compress basic;
alter tablespace ... row store compress basic;
alter table ... move row store compress basic;
基本表圧縮ではデータブロックのPCTFREEに基づいてブロックが一杯になるとデータが自動的に圧縮されるメカニズムである。再度データブロックが一杯になるまでデータブロックが挿入され再度一杯になるとまた圧縮されるる。PCTFREEの値は圧縮表定義時に明示的に指定しない限り0となる。
また基本表圧縮の制約としては
- 列の削除はできない
- 列の追加はデフォルト値を指定できない
alter table ... row store compress advanced;
alter tablespace ... row store compress advanced;
alter table ... move row store compress advanced;
拡張行圧縮では行および列の重複値がデータブロック内の先頭部分のシンボル表に一度コピーされる。
その値の重複値はシンボル表へのポインタとして定義される。また、基本表圧縮とは違い、
PCTFREEは特に指定しない限り、デフォルトの10が用いられる。
一般的に・・・
- 列データ長が長いほど、圧縮効果は高い
- Cardinality(値の種類)が小さいほど、圧縮効果は高い
- データブロックサイズが大きいほど圧縮効果が高い
1.検索処理のパラレル化(パラレルクエリー)
select segment_name,bytes/1024/1024 as mb,inmemory_size/1024/1024 as inmemory_mb,populate_status from V$im_segments;
alter table INMEM inmemory MEMCOMPRESS FOR QUERY LOW;
alter table MEM inmemory MEMCOMPRESS FOR QUERY LOW;
select
select count(),sum(col1),max(col1),min(col1),sum(col3),max(col3),min(col3),max(col6),min(col6) from INMEM;
select count(),sum(col1),max(col1),min(col1),sum(col3),max(col3),min(col3),max(col6),min(col6) from MEM;
ダイレクトパスインサート
INSERT + SELECT 文に APPEND 句をつけることで処理を高速化することが可能。
メリット
通常のINSERT文はバッファ・キャッシュ上のデータ・ブロックにデータを書き込みますが、ダイレクト・パス・インサート方式ではバッファ・キャッシュを経由しないで、ダイレクトにデータ・ファイルへ書き込みを行う為、通常よりも高速に大量データを格納できます。また、UNDOブロックの生成量も抑制される点も高速化に貢献しています。
デメリット
INSERT対象の表に対する排他ロックが取られるため、INSERT完了まで他のセッションからその表に対するDML文は同時に実行できません。また、既存の空き領域にデータをINSERTするのではなく、そのテーブルのHigh Water Mark(HWM)より先に新しく領域を割り当てて、INSERT終了後に既存のテーブルにマージされるような内部挙動になります。
insert /*+ APPEND */ into ITEM1 select * from ITEM;
エクステント割当ての方式(ALLOCATION_TYPE)
AUTOALLOCATE
エクステント追加対象のセグメントのサイズに応じてOracle Databaseが自動的に決定する最適サイズを決定。この場合、DBA_TABLESPACESディクショナリ・ビューのALLOCATION_TYPE列には「SYSTEM」と表示される点に注意が必要。エクステント割り当て方式によって以下相違点があり(ローカル管理前提)自動割当てエクステント「AUTOALLOCATE」を設定した場合、次のような動作
- 記号セグメント・サイズが1MBまでのエクステント・サイズは64KB
- セグメント・サイズが64MBまでのエクステント・サイズは1MB
- セグメント・サイズがそれ以上の場合のエクステント・サイズは8MB or 64MB (検証の結果、1GB越えるとエクステントサイズ64MBになることも・・・)
UNIFORM
全てのエクステントを均一に割り当てられる。UNIFORM句の後ろにサイズ指定可能ですが、指定しない場合はデフォルトの1MBが適用される。
set pagesize 1000 linesize 10000
col SEGMENT_NAME for a24
select SEGMENT_NAME, TABLESPACE_NAME, EXTENT_ID, BYTES, BLOCKS from USER_EXTENTS order by 1,2,3;
その他Tips
- create table時のinitial指定だが、initialに指定したサイズを最適に割り当てるようにエクステントが割り当てされる。(520Mだと64M×8+8MB×1のような)
- truncateしてもinitial値まではエクステントの解放はされない。
UNDO 表領域の管理
Oracle では UNDO 表領域というロールバックやMVCCのために利用される専用の表領域がある。
用途
- トランザクションのロールバック
- 読み取り一貫性読み取り
- インスタンスリカバリ時のロールバック
- フラッシュバック機能を利用
自動UNDO管理
UNDO_MANAGEMENT を AUTO にした場合、UNDO_RETENTIONの値は以下のように決定される。
自動拡張可能な表領域
システムでアクティブな最長実行問合せよりも若干長くなるように自動的にチューニングされる。
固定サイズの表領域
表領域のサイズと現行のシステムの負荷に対して最適な保存期間を確保するように、自動的にチューニングされる。通常この最適な保存期間は、アクティブな最長実行問合せのの期間より長くなる
UNDOサイジング
今までのデータベースの稼働状況でどの程度、UNDOブロックが生成されたか、最も長い問い合わせは何だったのかは以下の統計情報から閲覧可能。
10分間隔で以下の統計情報が取得されている。
SELECT TO_CHAR(BEGIN_TIME,'MM/DD HH24:MI') AS BEGIN_TIME, TO_CHAR(END_TIME,'MM/DD HH24:MI') AS END_TIME, UNDOBLKS, MAXQUERYLEN,MAXQUERYID,TUNED_UNDORETENTION FROM V$UNDOSTAT order by BEGIN_TIME;
UNDO 表領域サイジング式
UNDO表領域必要容量 (byte) = UNDO保存期間 (秒) x 1 秒あたりUNDOブロック生成数 × ブロックサイズ + (バッファ)
*1秒あたりUNDOブロック生成数は、上記の統計情報で取得した値を取得間隔の600秒で割って算出。
ステータス別UNDO使用量
col bytes for 999,999,999,999
select status, sum(bytes)/1024/1024 as mbytes from dba_undo_extents where tablespace_name = 'UNDOTBLSP01' and status in ('ACTIVE','UNEXPIRED','EXPIRED') group by status order by status;
col bytes for 999,999,999,999
select sum(bytes)/1024/1024 as mbytes from dba_free_space where tablespace_name = 'UNDOTBLSP01';
-
ACTIVEトランザクションのロールバックでまだ利用する想定のUNDO領域。 -
UNEXPIREDトランザクションのロールバックではもう利用しないが、UNDO_RETENTIONが経過していない領域。 -
EXPIREDUNDO_RETENTIONが経過してもう上書き可能なUNDO領域。
*** UNDO表領域の使用率 = [A] / [A]+[B]+[C]
[A] = ACTIVE + UNEXPIRED,[B] = EXPIRED,[C] = FREE
Oracle Scheduler
OS の Cron のように Oracle ではジョブを処理をスケジューリングしておく機能があるので一例。
BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'statspack_remove',
job_type => 'PLSQL_BLOCK',
job_action => 'BEGIN statspack.purge(2); END;',
start_date => TO_DATE('2021/01/31 17:00:00','yyyy/mm/dd hh24:mi:ss'),
repeat_interval => 'FREQ=HOURLY',
enabled => TRUE
);
END;
/
BEGIN
DBMS_SCHEDULER.DROP_JOB('statspack_remove');
END;
/
col owner format a20
col job_name format a20
col job_action format a70
col start_date format a40
col end_date format a40
col last_start_date format a40
select OWNER,JOB_NAME,JOB_TYPE,JOB_ACTION,START_DATE,END_DATE,ENABLED,STATE,RUN_COUNT,FAILURE_COUNT,LAST_START_DATE from ALL_SCHEDULER_JOBS;
自動化メンテナンス・タスク
データベースのメンテナンス操作を自動的に決められたウィンドウ内でOracleデータベースで実施してくれる機能。
Oracle 製品デフォルトでは以下の 3 つの自動化メンテナンス・タスクを実行する。
- 自動オプティマイザ統計収集
データベース内に統計情報がないか、古い統計のみがある全てのオブジェクトに対してオプティマイザ統計を収集します。
- 自動セグメント・アドバイザ
再生可能な領域が存在しているセグメントを識別し、それらのセグメントの断片化を解消する方法を推奨事項生成。
- 自動SQLチューニング・アドバイザ
高負荷のSQL文のパフォーマンスを調査し、それらの文のチューニング方法についての推奨事項生成。
col CLIENT_NAME format a50
col MEAN_JOB_DURATION format a30
col MAX_DURATION_LAST_7_DAYS format a30
select CLIENT_NAME,STATUS,WINDOW_GROUP, MEAN_JOB_DURATION,MAX_DURATION_LAST_7_DAYS from DBA_AUTOTASK_CLIENT;
CLIENT_NAME |STATUS |WINDOW_GROUP |MEAN_JOB_DURATION |MAX_DURATION_LAST_7_DAYS
--------------------------------------------------|--------|----------------------------------------------------------------|------------------------------|------------------------------
sql tuning advisor |ENABLED |ORA$AT_WGRP_SQ |+000000000 00:00:00.065306122 |+000 00:00:00
auto optimizer stats collection |ENABLED|ORA$AT_WGRP_OS |+000000000 00:00:37.436734694 |+000 00:07:07
auto space advisor |ENABLED |ORA$AT_WGRP_SA |+000000000 00:00:05.044897959 |+000 00:00:29
BEGIN
DBMS_AUTO_TASK_ADMIN.DISABLE(
client_name => 'auto optimizer stats collection',
operation => NULL,
window_name => NULL);
END;
/
BEGIN
DBMS_AUTO_TASK_ADMIN.ENABLE(
client_name => 'auto optimizer stats collection',
operation => NULL,
window_name => NULL);
END;
/
DBA_AUTOTASK_CLIENT を参照した時に各自動化メンテナンス・タスクに対してWINDOW_GROUP(ウィンドウグループ)というものが定義されているが、これは要するにそのタスクが実行されるメンテナンスウィンドウ帯を定義しているもの。ウィンドウグループに所属するウィンドウメンバーを以下で確認可能。
-- WINDOW_GROUP_NAME に確認したいWINDOW_GROUPを指定。
select * from DBA_SCHEDULER_WINGROUP_MEMBERS where WINDOW_GROUP_NAME = 'ORA$AT_WGRP_OS';
そして上記ウィンドウメンバーの詳細情報はこちらで可能。
- WINDOW_NEXT_TIME: 曜日ウィンドウの次回起動予定日時
- REPEAT_INTERVAL: ウィンドウの実行周期
- DURATION: 開始時間以降のそのウィンドウの ACTIVE 期間(デフォルトの場合、平日は短くて土日は長い)
- WINDOW_ACTIVE : ウィンドウが現在 Active かどうか
- AUTOTASK_STATUS : 自動化メンテナンス・タスク (全体)のStatus
- OPTIMIZER_STATS : 自動オプティマイザ統計収集 タスクのStatus
- SEGMENT_ADVISOR : 自動セグメント・アドバイザ タスクのStatus
- SQL_TUNE_ADVISOR: 自動SQLチューニング・アドバイザ タスクのStatus
col WINDOW_NAME format a30
col REPEAT_INTERVAL for a70
col DURATION for a15
col ENABLED for a7
col WINDOW_NEXT_TIME for a50
col AUTOTASK_STATUS for a15
col OPTIMIZER_STATS for a15
col SEGMENT_ADVISOR for a15
col SQL_TUNE_ADVISOR for a16
select s.WINDOW_NAME
,s.REPEAT_INTERVAL
,s.DURATION
,s.ENABLED
,a.WINDOW_NEXT_TIME
,a.WINDOW_ACTIVE
,a.AUTOTASK_STATUS
,a.OPTIMIZER_STATS
,a.SEGMENT_ADVISOR
,a.SQL_TUNE_ADVISOR
from DBA_SCHEDULER_WINDOWS s,
DBA_AUTOTASK_WINDOW_CLIENTS a
where s.WINDOW_NAME = a.WINDOW_NAME;
WINDOW_NAME |REPEAT_INTERVAL |DURATION |ENABLED|WINDOW_NEXT_TIME |WINDO|AUTOTASK_STATUS|OPTIMIZER_STATS|SEGMENT_ADVISOR|SQL_TUNE_ADVISOR
------------------------------|----------------------------------------------------------------------|---------------|-------|--------------------------------------------------|-----|---------------|---------------|---------------|----------------
MONDAY_WINDOW |freq=daily;byday=MON;byhour=22;byminute=0; bysecond=0 |+000 04:00:00 |TRUE |08-FEB-21 10.00.00.000000 PM ETC/UTC |FALSE|ENABLED |ENABLED |ENABLED |ENABLED
TUESDAY_WINDOW |freq=daily;byday=TUE;byhour=22;byminute=0; bysecond=0 |+000 04:00:00 |TRUE |09-FEB-21 10.00.00.000000 PM ETC/UTC |FALSE|ENABLED |ENABLED |ENABLED |ENABLED
WEDNESDAY_WINDOW |freq=daily;byday=WED;byhour=22;byminute=0; bysecond=0 |+000 04:00:00 |TRUE |10-FEB-21 10.00.00.000000 PM ETC/UTC |FALSE|ENABLED |ENABLED |ENABLED |ENABLED
THURSDAY_WINDOW |freq=daily;byday=THU;byhour=22;byminute=0; bysecond=0 |+000 04:00:00 |TRUE |11-FEB-21 10.00.00.000000 PM ETC/UTC |FALSE|ENABLED |ENABLED |ENABLED |ENABLED
FRIDAY_WINDOW |freq=daily;byday=FRI;byhour=22;byminute=0; bysecond=0 |+000 04:00:00 |TRUE |12-FEB-21 10.00.00.000000 PM ETC/UTC |FALSE|ENABLED |ENABLED |ENABLED |ENABLED
SATURDAY_WINDOW |freq=daily;byday=SAT;byhour=6;byminute=0; bysecond=0 |+000 20:00:00 |TRUE |06-FEB-21 06.00.00.000000 AM ETC/UTC |TRUE |ENABLED |ENABLED |ENABLED |ENABLED
SUNDAY_WINDOW |freq=daily;byday=SUN;byhour=6;byminute=0; bysecond=0 |+000 20:00:00 |TRUE |07-FEB-21 06.00.00.000000 AM ETC/UTC |FALSE|ENABLED |ENABLED |ENABLED |ENABLED
7 rows selected.
特定のウィンドウメンバーで特定の自動化メンテナンス・タスクを無効化する例:
BEGIN
DBMS_AUTO_TASK_ADMIN.DISABLE(
client_name => 'auto optimizer stats collection',
operation => NULL,
window_name => 'SUNDAY_WINDOW');
END;
/
特定のウィンドウメンバーの設定を変更する例:
BEGIN
DBMS_SCHEDULER.SET_ATTRIBUTE(
name => 'FRIDAY_WINDOW',
attribute => 'REPEAT_INTERVAL',
value => 'freq=daily;byday=FRI;byhour=21;byminute=0; bysecond=0');
DBMS_SCHEDULER.SET_ATTRIBUTE(
name => 'FRIDAY_WINDOW',
attribute => 'DURATION',
value => numtodsinterval(3, 'hour'));
END;
/
自動化メンテナンス・タスクジョブの過去の実行履歴はこちらで確認する。エラーが発生していたらORAエラーなど詳細がJOB_INFOから分かる。
COLUMN CLIENT_NAME FORMAT A33
COLUMN WINDOW_NAME FORMAT A20
COLUMN WINDOW_START_TIME FORMAT A20
COLUMN JOB_START_TIME FORMAT A30
COLUMN JOB_DURATION FORMAT A20
COLUMN JOB_DURATION_HMS FORMAT A12
SELECT CLIENT_NAME
, WINDOW_NAME
, JOB_STATUS
, TO_CHAR(WINDOW_START_TIME, 'YYYY/MM/DD HH24:MI:SS') AS WINDOW_START_TIME
, TO_CHAR(JOB_START_TIME, 'YYYY/MM/DD HH24:MI:SS') AS JOB_START_TIME
, JOB_DURATION
, JOB_ERROR
, JOB_INFO
FROM DBA_AUTOTASK_JOB_HISTORY
ORDER BY CLIENT_NAME, JOB_START_TIME;
注意点としてスケジューラーのタイムゾーンは、インスタンス作成時のOSタイムゾーンにデフォルトではなっているので、要件が異なる場合は変更が必要。
あくまでDBのタイムゾーンやDBへ接続するアプリケーションのタイムゾーンとは設定が独立している。
SELECT VALUE FROM DBA_SCHEDULER_GLOBAL_ATTRIBUTE WHERE ATTRIBUTE_NAME='DEFAULT_TIMEZONE';
begin
dbms_scheduler.set_scheduler_attribute(
attribute => 'default_timezone',
value => 'Asia/Tokyo'
);
end;
/
表領域の断片化状態の確認
テーブルスペースの使用状況によって各セグメントのブロックが様々な箇所に格納される。
その時点でテーブルスペースのどのくらいの位置にセグメントが存在するのか確認する方法としては以下となる。
set lin 10000
col segment format a60
select tablespace_name tablespace,file_id,block_id,blocks,owner||'.'||segment_name segment
from dba_extents where tablespace_name='TBLSP01'
union
select tablespace_name tablespace,file_id,block_id,blocks,' '
from dba_free_space where tablespace_name='TBLSP01'
order by 1,2,3;
この確認方法が有効な例としては、テーブルスペースの縮小が挙げられるだろう。
上記で確認した列 BLOCK_IDxブロックサイズ程度の位置にそのセグメントが存在すると考えて良い。
表領域が縮小できるのは、その表領域の一番後ろのセグメントが存在する位置までなのでどの程度の位置まで縮小できるかどうか確認可能。
また、セグメントをその表領域内で再構成(つまり配置変え)する方法としては以下の方法が有効。
- テーブル再編成
- インデックス再編成
監査
Oracle データベースでは、ユーザーがデータベースをいつどのように操作したかを履歴として残すための監査機能がある。
要件によっては監査情報を取得することが必要だったりする。
いくつか監査に種類があるのでまとめていく。
11g以前
必須監査
Oracleで絶対的に取得される監査。特に設定で無効化することはできず、常に自動的に取得される。
監査ログは audit_file_dest に OS ファイルとして出力される。audit_trail がxml、xml,extendedの場合は、[SID]ora[pid][タイムスタンプ].xml、それ以外(NONEも含む)の場合は、[SID]_ora[pid]_[タイムスタンプ].aud
[監査対象]
- データベースの起動、及び、停止。
- インスタンスを起動したオペレーティング・システム・ユーザー、そのユーザーの端末識別子、日時のタイム・スタンプを記述した監査レコードが生成される。
- データベース監査証跡は起動処理が正常に完了するまで使用できないため、この監査レコードはオペレーティング・システム監査証跡に格納されます。
- SYSDBAおよびSYSOPERログイン。すべてのSYSDBAおよびSYSOPER接続が記録される
DBA 監査
DBA権限をもったユーザー操作を記録するための監査。有効にする場合は、audit_sys_operationをTRUEにする必要がある。
監査ログは audit_file_dest に OS ファイルとして出力される。audit_trail がxml、xml,extendedの場合は、[SID]ora[pid][タイムスタンプ].xml、それ以外(NONEも含む)の場合は、[SID]_ora[pid]_[タイムスタンプ].aud
[監査対象]
- SYSDBA、及び、SYSOPERとしてログインしたユーザーで実施した操作を全て記録するための監査。(必須監査では接続だけだが、操作も加えて操作も取得してくれる。)
- SYSユーザーによる操作は標準監査やファイングレイン監査の監査証跡には残らない。そのため、SYSユーザーを監査するためにはこのDBA監査が必須となる。
標準監査
標準監査は事前にaudit文で監査対象のユーザーや操作を定義し、その操作が実行された際に証跡を出力する。
表へのアクセスの他にも、データベースへのログイン、表などのオブジェクトの構成変更、権限管理の実施など様々なデータベース操作に対して監査を設定することが諸々可能。
audit_trailの設定をNONE以外にすることで、OSディレクトリ上や SYS.AUD$ 表に監査証跡を出力。
audit session by MARIO by access;
audit all statements by MARIO by access;
column user_name format a12
column proxy_name format a12
column audit_option format a20
column success format a12
column failure format a12
select * from DBA_STMT_AUDIT_OPTS;
column owner format a13
column object_name format a13
column object_type format a13
select * from DBA_OBJ_AUDIT_OPTS;