自作フレームワークにMesh Shaderを組み込み、従来の頂点シェーダーと比較してどのくらいパフォーマンスが変化するか検証しました。

- CADデータをポリゴン化したモデル、3DスキャンやZBrushでスカルプトしたような超ハイポリゴンモデルの場合 Mesh Shaderが圧倒的優位である。
- しかし低ポリゴン数のモデルが配置されたシーンではVertex Shaderの方が優位になる。
- 低ポリゴン数のモデルをAmplification Shaderと併用して描画するとMesh Shaderのみの場合と比べて速度が低下する。
- 超ハイポリゴンモデルの場合、Amplification Shaderを併用するとより高速になる。
自作フレームワーク
せっかくなので今回検証に使用した自作フレームワークをちょっとだけ紹介させてください。
| API | 開発環境 | CPU | RAM | GPU |
|---|---|---|---|---|
| D3D12 | Visual Studio 2019 | Ryzen 3950X (16C/32T) | 64GB | RTX2060 |
ライティングは何も実装していないのでテクスチャカラーをシンプルに出しています。
Mesh Shaderのパフォーマンスを比較するにあたってデバッグ機能を充実させました。
| デフォルト | Lod Level | Meshlet | Texcoords | Wireframe |
|---|---|---|---|---|
 |
 |
 |
 |
 |
| LODは赤~緑~青で詳細レベルから荒いレベルまでを表しています。LODがないメッシュは赤固定になっています。 |
| メッシュインスタンス バウンディング | メッシュレット バウンディング |
|---|---|
 |
 |
| 共にバウンディングはAABBを利用しています。メッシュレットの方は数が多いのでちょっと見づらいですね。 |
カリングについて
カリングとしてフラスタムカリング・バックフェースカリング・微小面積カリング・オクルージョンカリングを実装してあります。
微小面積カリングはMeshletが小さすぎてラスタライズがされないことを事前にバウンディングボックスの投影面積から判定してカリングしています。
オクルージョンカリングには縮小デプスを用いたHi-Zを採用しています。
縮小デプスはDepth Pre Passで生成されたデプステクスチャを元に作っています。


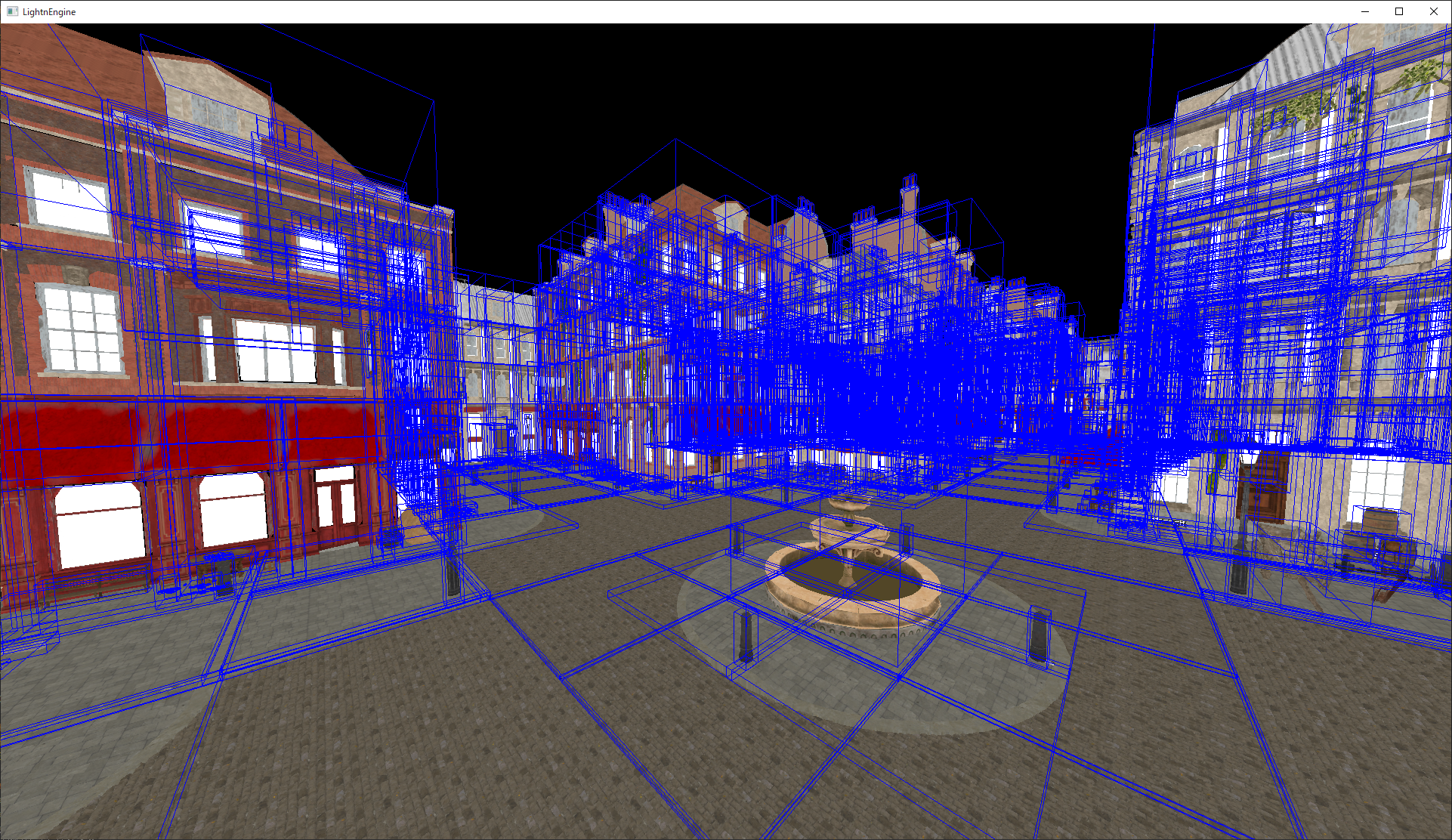
黄色い線がカリングで使用しているフラスタムの境界線です。
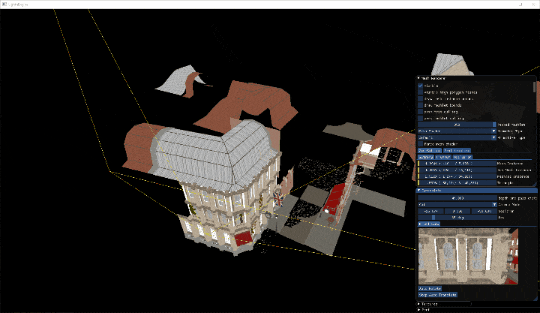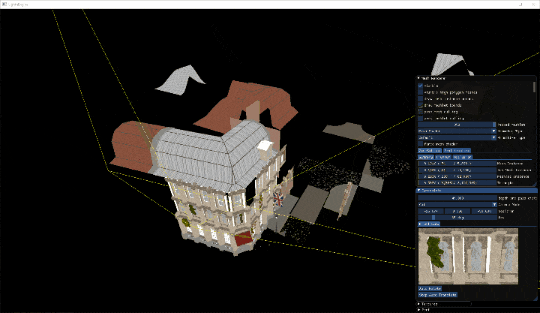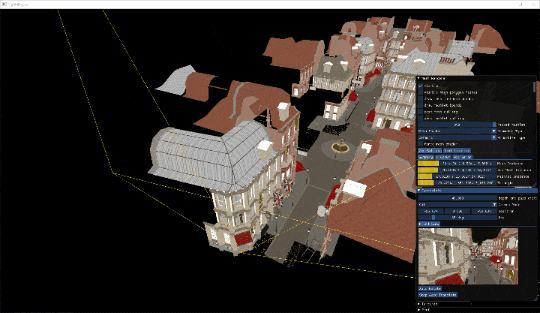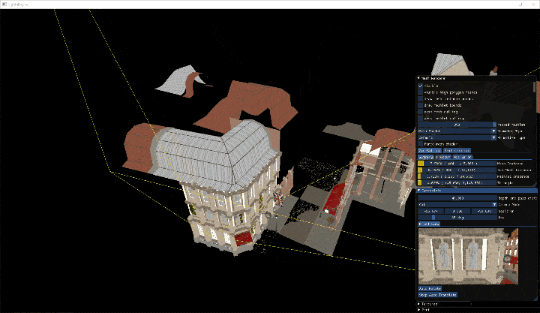
オクルージョンカリングの様子です。建物の目の前に来た時は後ろのものは遮蔽されてほとんど描画されていない様子が分かります。
実際のシーンで検証
Unityで3Dモデルを配置して独自バイナリにして吐き出しています。
冒頭でも述べましたが、メッシュシェーダーに有利なハイポリゴンメッシュを追加したバリエーションも用意しました。
本当はSponzaやSanMiguelなどの3DCG定番シーンを使うべきですが、巨大な一つのメッシュになってしまっているため別のものを用意しました。
| 標準シーン | ハイポリゴンシーン | 超ハイポリゴンシーン |
|---|---|---|
 |
 |
 |
| ハイポリゴンシーンには標準シーンに加えてハイポリゴンメッシュの像が多数配置されています。 | ||
| こちらのビューで負荷計測を行います。より正確に計測するためにNVIDIA Nsight Graphics Gpu Taceを使用しました。 |
| 標準シーン | ハイポリゴンシーン | 超ハイポリゴンシーン | |
|---|---|---|---|
| メッシュ数 | 189 | 194 | 194 |
| メッシュ配置数 | 5,808 | 5,836 | 6,084 |
| LODメッシュ数 | 668 | 673 | 673 |
| LODメッシュ配置数 | 18,709 | 18,737 | 18,958 |
| サブメッシュ数 | 1,328 | 1,333 | 1,333 |
| サブメッシュ配置数 | 50,736 | 50,784 | 51,032 |
| メッシュレット数 | 55,345 | 84,207 | 84,207 |
| メッシュレット配置数 | 1,103,909 | 1,314,417 | 2,943,696 |
| 頂点数 | 3,095,755 | 4,587,724 | 4,587,724 |
| 頂点配置数 | 61,272,954 | 70,390,953 | 149,413,035 |
| ポリゴン数 | 1,054,311 | 5,246,721 | 5,246,721 |
| ポリゴン配置数 | 52,333,776 | 67,994,167 | 202,373,227 |
| シェーダー数 | 3 | 3 | 3 |
| マテリアル数 | 136 | 136 | 136 |
比較用描画方式について
3つの描画方式を実装し、リアルタイムで切り替えられるようにしました。
| 描画タイプ | 説明 |
|---|---|
| Mesh Shader | GPUメッシュカリング+メッシュシェーダー |
| Multi Draw | GPUメッシュカリング+頂点シェーダー |
| Vertex Shader | CPUメッシュカリング+頂点シェーダー |
| ※Multi DrawはOpenGLやコンソール機APIの名称ですが、D3D12ではExecute IndirectというDispatchもできる機能なので利便上Multi Drawと呼びます。 | |
| 主にMesh ShaderとMulti Drawについて比較を行います。Vertex ShaderモードはGPUカリングパスがなかったりして厳密な比較ができないため対象にしていません。 |
各シーンでの測定結果は以下の通りです。
時間はすべてGPU負荷のみでCPUの負荷は入っていません。
メインパス
| GPUメッシュカリング | 増幅シェーダーカリング | |
|---|---|---|
| フラスタムカリング | 〇 | 〇 |
| オクルージョンカリング | 〇 | 〇 |
| バックフェースカリング | × | 〇 |
| 微小面積カリング | × | 〇 |
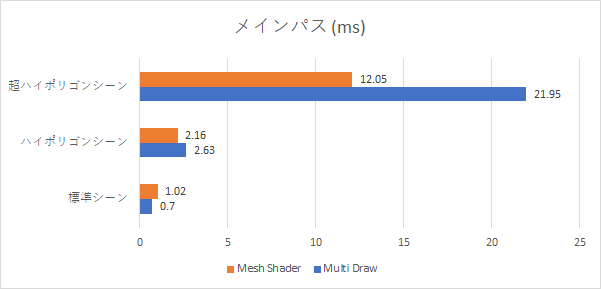
| 標準シーン | ハイポリゴンシーン | 超ハイポリゴンシーン | |
|---|---|---|---|
| Multi Draw | 0.7 ms | 2.63 ms | 21.95 ms |
| Mesh Shader | 1.02 ms | 2.16 ms | 12.05 ms |
それぞれ頂点シェーダー・メッシュシェーダーは異なりますがピクセルシェーダーはすべて同一のものを使用しています。
続いてDepth Pre Passの方も見てみます。こちらはFarClipが短めに設定されていてピクセルシェーダーはバインドされていません。
デプスプリパス
| GPUメッシュカリング | 増幅シェーダーカリング | |
|---|---|---|
| フラスタムカリング | 〇 | 〇 |
| オクルージョンカリング | × | × |
| バックフェースカリング | × | 〇 |
| 微小面積カリング | × | 〇 |
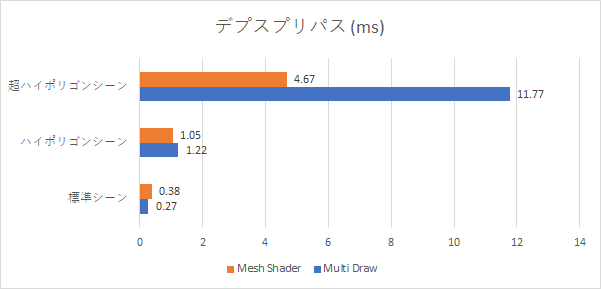
| 標準シーン | ハイポリゴンシーン | 超ハイポリゴンシーン | |
|---|---|---|---|
| Multi Draw | 0.27 ms | 1.22 ms | 11.77 ms |
| Mesh Shader | 0.38 ms | 1.05 ms | 4.67 ms |
| デプスプリパスで作成したデプステクスチャを元に階層デプスを作成し、オクルージョンカリングしているのでデプスプリパスはオクルージョンカリングされていません。 |
これらの結果からハイポリゴンなモデルが少ないシーンでは従来の頂点シェーダーのほうが優位となりました。
Githubのリポジトリにキャプチャデータも置いておきますので詳しく見たい方は是非ご覧ください。
Mesh Shaderの最適化
なるべく全てのケースでVertex Shaderより高速にならないかと思い、いくつか最適化を試しました。
究極的には詰められていないですが、やれることはやった感じです。
上記のパフォーマンスはこれらの最適化を行った後の結果となります...
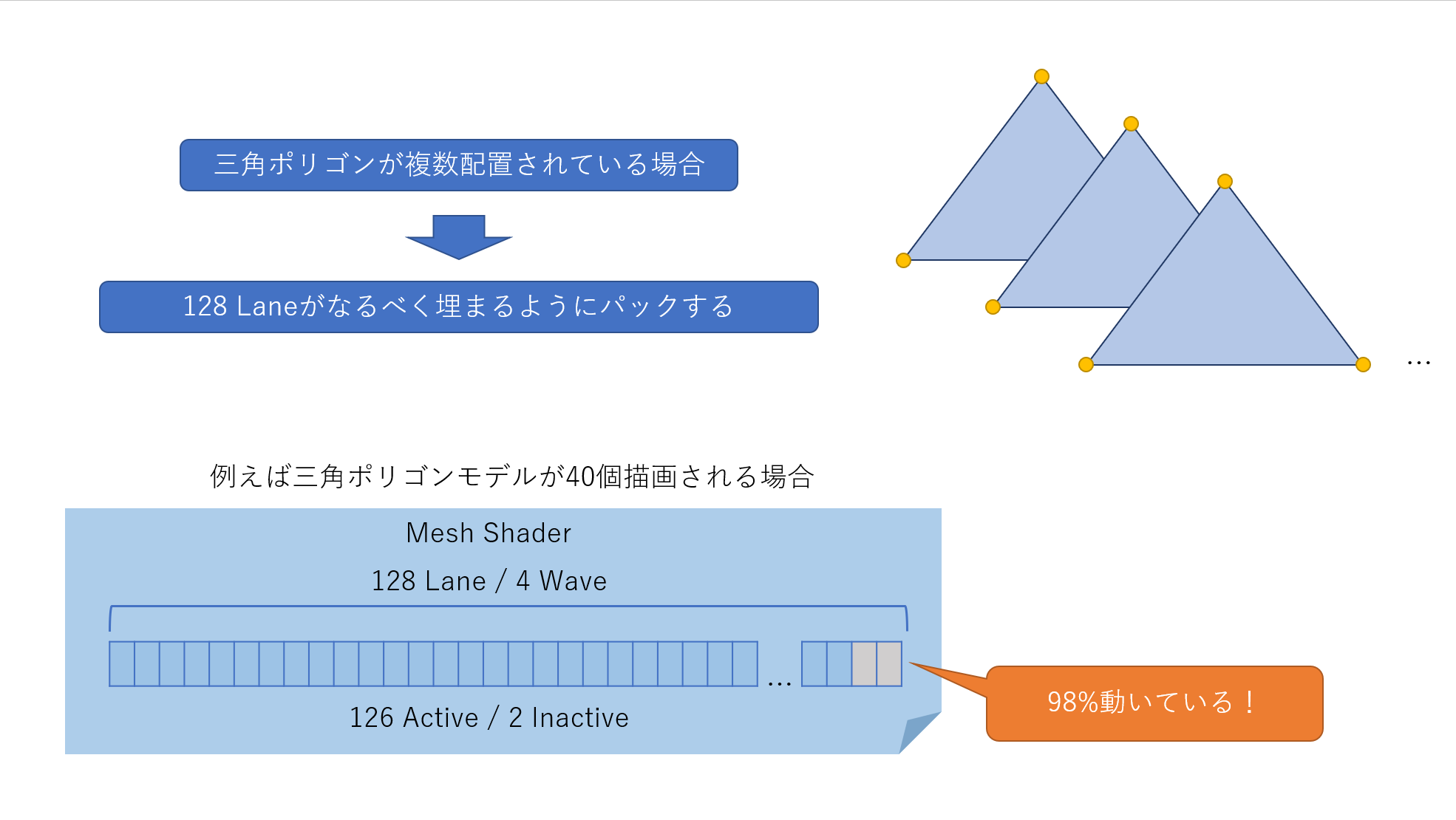
シンプルに実装するとGPUスレッド(Lane)の占有率が下がる
DirectX12のメッシュシェーダーサンプルやドキュメントの例などを参考にしてそのまま組み込むと速度で問題が出るケースがあります。
特に複数モデルやローポリゴン・ハイポリゴンが多種多様に含まれるシーンでは大きなロスが発生してメッシュシェーダーのパフォーマンスを最大限発揮できません。
この問題を解決するために増幅シェーダーやメッシュシェーダー内でパッキングを行い占有率を最大化します。
パッキングには2ケースあります。一つは増幅シェーダーでもう一つはメッシュシェーダーです。
増幅シェーダーはメッシュレットごとに1Wave/32Laneに詰められるだけ詰めます。
メッシュシェーダーでは4Wave/128Laneにメッシュレットに含まれる頂点とポリゴンを詰めます。
パックしない場合のワーストケースです。ほとんどのスレッドが使われません。
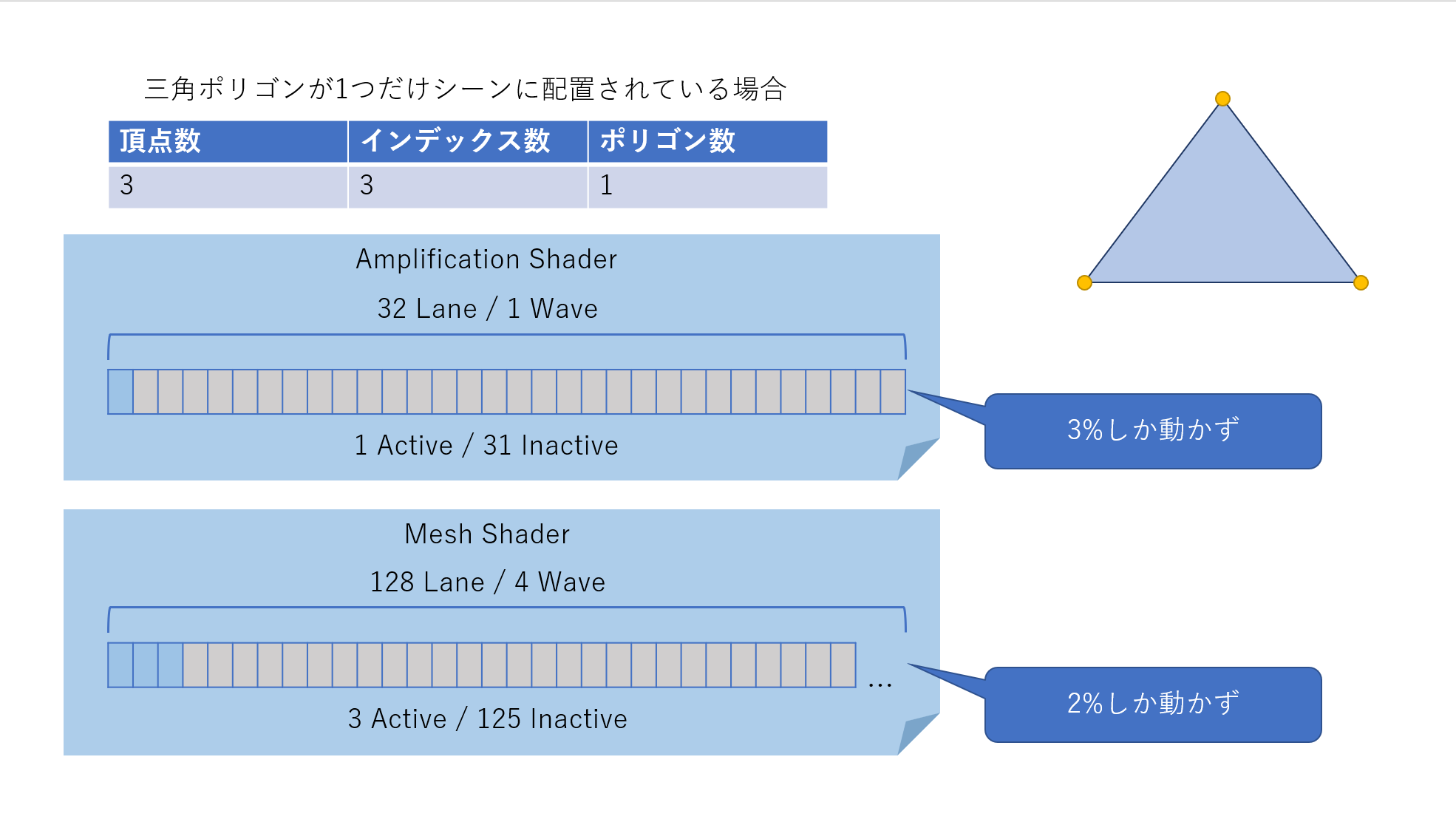
パックしてスレッドの使用率を上げました。ベストケースではありますが、無駄なスレッドが削減できました。
メッシュレットのインスタンシング描画
ドローコールを抑えるためにも同一モデルはインスタンシング描画を行います。
条件はいたってシンプルで、同一モデルかつ同じシェーダーであればインスタンシング描画されます。
マテリアルは違ってもまとめて描画されます。バインドレスリソースを活用しています。
メッシュシェーダーには従来のDrawInstancedのようなAPIは存在しない為、自前でインスタンシング処理を実装する必要があります。
メモリアクセス改善
インスタンシング描画とパッキングを行ってもやはりローポリなシーンでは頂点シェーダーの方が高速です。
次にメッシュシェーダー内のメモリアクセスを改善します。
従来の頂点シェーダーでは入力頂点キャッシュやプリミティブドライバー(各GPUスレッドに頂点データを割り振る)があり、パイプラインに最適化されています。
メッシュシェーダーでは入力頂点などはStructuredBufferで渡すため、気を付けてあげないとすぐボトルネックになります。
今回は8bit UINTを UINT32にパックしたり、StructuredBufferの要素サイズをキャッシュラインサイズの16byteにアラインしたりしました。
まとめ
標準的なシーンでは頂点シェーダーでもメッシュシェーダーでも変わらないくらいです。
ハイポリゴンシーンになるとメッシュシェーダーの恩恵が大きく表れている結果が確認できました。
可能であればどちらかのパイプラインに置き換えたい気持ちではありますが、しばらくは併用もしは頂点シェーダーのみでも問題ないでしょう。
個人でやる分にはまだよいですが商用的に採用するとなると実装・メンテにもコストがかかるので難しいですね。
余談 UE5のNaniteと比較
今回は単純にメッシュシェーダーを実装しただけなのでUE5のNaniteには逆立ちしてもかないません。
メッシュシェーダーの導入で頂点処理は高速化しましたが微細ポリゴンでピクセルシェーダー負荷が高くなってしまいました。
次回はVisiblity Bufferと頂点量子化(Naniteの自動Lod作成機能)をやってみたいと思います。
GPUソフトウェアラスタライザはまだ知識不足で厳しい気がするのでもう少し勉強してから出直します。
コードについて
こちらでコードを公開しています。
LightnEngine【Github】
参照
Introduction to Turing Mesh Shaders【NVIDIA Developer Blog】
Optimizing the Graphics Pipeline with Compute【GDC 2016】
Direct3D 12 mesh shader samples【Github】
Meshlete【Github】
NVIDIA Nsight Graphics【NVIDIA】
MeshOptimizer【Github】