こんにちは。日本工学院八王子専門学校の藤巻です。
今回は私が作ったレンダリングエンジンがU22プログラミングコンテスト2018で経済産業大臣賞を受賞しました!
プレゼンでも発表したのですが、周りから難しいとかよくわからないとか言われたので解説記事を書きました。
自慢はこの辺までにしてさっそく解説していきましょう。
↓クリックするとデモ動画が見れます

ざっくり概要
Lightn Renderer Engineはエンジンと書いていますがぶっちゃけフレームワークレベルです。誇張しすぎました。(本記事では混乱しないように名前の通りエンジンと呼ばせていただきます…)
- Direct3D11
- 物理ベースレンダリング
- GPU駆動レンダリング
主に上記3点において注力したのがこのレンダリングエンジンです。
モデルの読み込み、演算ライブラリまですべて自作しています。
今までUnityやUnrealEngineばかりを使っていたためグラフィックスAPIに関する知識がほぼ皆無でした。
一方でポストエフェクトやシェーダー、軽量化に関する知識は商用ゲームエンジンを使う上でいろいろと調べたり実際に使用したり知識としてはありました。
商用ゲームエンジンで実装されている機能を自前で実装するのが今回の目的でした。
Direct3D11
OpenGLはおろかDirect3D9すら使ったことがなかったのでどのグラフィックスAPIを使うか悩みましたが一番メジャーそうなDirect3D11を選びました。
学習目的なのでDirect3D12をやってみたかったのですが当時はすぐさじを投げました。
レンダリングエンジン自体はシングルスレッドで動作していてゲームUpdate→Renderのようなよくある残念な実装です。
コンピュートシェーダーやジオメトリシェーダー、DrawIndirectなどDirect3D11世代の命令を多く活用しています。
レンダリングパス
- GPU メッシュカリング
- Depth Pre Pass
- Gbuffer描画
- スカイライト
- ディレクショナルライト
- Tile Based Culling & ポイント・スポットライト
- ポストエフェクト
レンダリングにあたってはディファードレンダリングを使用しています。
GPU メッシュカリング(GPU駆動レンダリング)
本レンダリングエンジンの特徴の一つでもあるGPU駆動レンダリングの部分です。
これは従来のカリングから描画までの流れです。
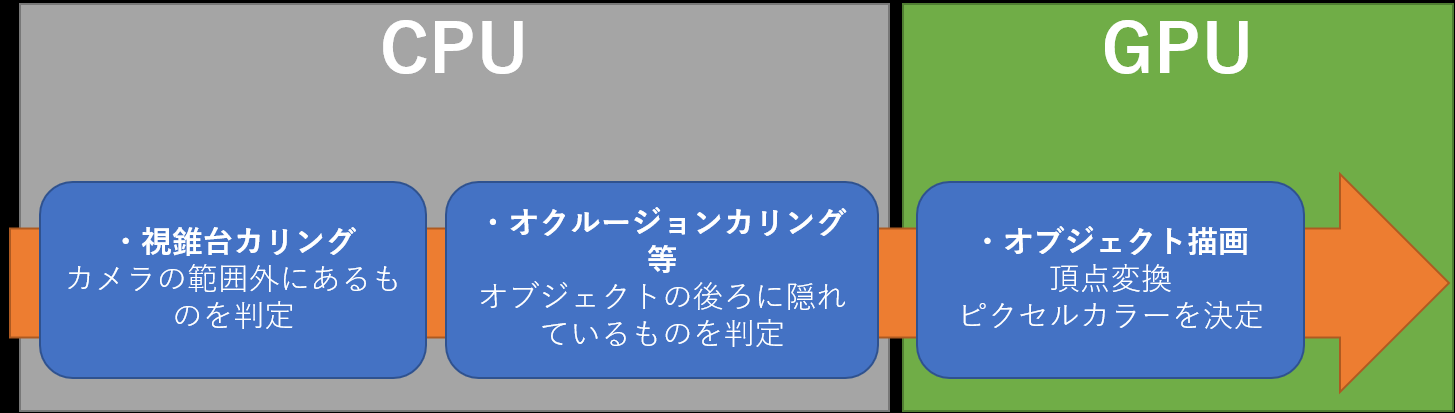
上記画像の処理をすべてGPUで行うのがGPU駆動レンダリングです。
一連の流れ
カリングの計算はコンピュートシェーダーで行います。
カリングした結果をAppendStructuredBufferとよばれるスタック可能な配列に描画対象のワールド行列を描画リストとしてため込んでいきます。
ついでにByteAddressBufferにドローコールごとに描画するメッシュの数やインデックスバッファのオフセットなどを記録します。
なぜワールド行列を描画リストとして扱っているかというと本当は頂点バッファとして扱ってインスタシングに流したかったからです。頂点キャッシュ効率の都合で定数バッファに長い描画リストを渡すよりも高速に動作します。
しかしAppendStructuredBufferはバッファフォーマットにDXGI_FORMAT_R32_UNKNOWNを指定する必要があるのですが、
頂点バッファを生成するのに必要なD3D11_BIND_VERTEX_BUFFERと共存できないため泣く泣くGPUバッファのシェーダーリソースビューとして渡しています。
最後にDrawindexedInstancedIndirect命令を使用して描画するメッシュの数などを記録したByteAddressBufferを引数に渡して描画します。
頂点シェーダーではシェーダーリソースビューとして渡された描画リストのワールド行列をSV_InstanceIDのインデックスで参照して頂点変換を行います。
これらの流れによってCPUがやる仕事はコンピュートシェーダーの起動とDrawindexedInstancedIndirect命令を呼ぶだけです。
For文でメッシュの数だけループする必要もないのでとても高速に動作します。
カリング処理
モデルのAABBと視錐台の6平面との判定を行い、カメラから見えているか見えていないかを判定しています。
U22プログラミングコンテストに応募した時点では実装されていませんが、のちにGPUオクルージョンカリングも実装しています。
実装方法としてはまず1フレーム前のデプステクスチャのミップマップを作成し、その深度値とAABBを比較して完全に隠れている場合は描画しないようにします。
UnrealEngineでも実装されているオクルージョンカリング法です。こちらに日本語で分かりやすい解説を発見しました。http://darakemonodarake.hatenablog.jp/entry/2014/12/17/000422
以下はどれだけ物量をさばけるかのデモで、100万オブジェクトをリアルタイムにカリングしています。(画像クリックでデモ動画が流れます)

Depth Pre Pass
ピクセルのオーバードローを防ぐ目的でよくDepthPrePassは使われていますが、GPU駆動レンダリングではまとめて多くのメッシュを描画するのとGPU上で描画順を制御できないのでオーバードローがより顕著に現れます。
一部の内製エンジンでは手前のある程度の部分までしかDepthを描画しないなどの工夫をしているようですが、今回のレンダリングエンジンではフルでDepthを描画しています。
GBuffer描画
Gbufferレイアウトは以下の通りです。

ベースカラーはBloom等に対応するためにHDR 64bitフォーマットに対応しています。
元からPCで行うデモの予定だったのでR11G11B10のフォーマットは試していません。
法線は本当はR16G16にして2軸圧縮したかったのですが、時間が(ry
スカイライト
IBLを用いたライティングを行っています。
実装はUnrealEngineのものを参考にしています。
ディレクショナルライト
The普通の平行光源ライティングです。
残念なシャドウマップ(USM)も実装しています。(トッテモジャギジャギ)
Tile Based Culling & ポイント・スポットライト
スカイライトとディレクショナルライトは画面全体に行っていましたが、ポイントライトとスポットライトはカリング処理を含めてライティングを行っています。
この一連のフローもGPU駆動になっていて、多くのライトを描画することができます。
まずはコンピュートシェーダーで16px X 16pxごとにタイルを生成してそのタイルに何個ライトが含まれるか計算します。
各タイルを囲う6つの平面を計算してからその平面とライトが交差するかどうかでカリングしています。
ポイントライトなら平面の法線と半径の内積がプラスなら交差しています。スポットライトならこれに角度の条件を足せば正しく処理できるのですが、今回はスポットライトもポイントライトも同じカリング処理です…
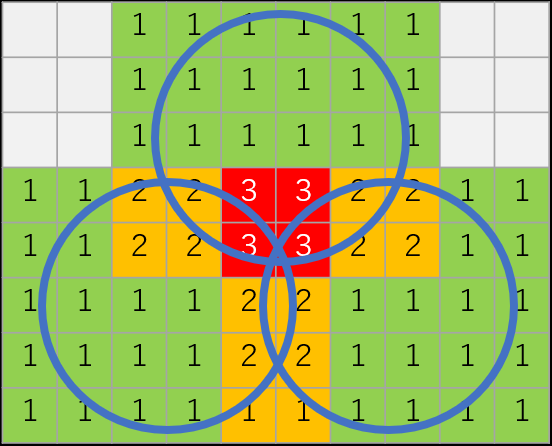
ちょっとイメージつきづらいのですが平面と半径の内積をとっているので実際には円状のタイルではなく、円を囲むような四角になります。
詳しくは下の動画を見てもらえればわかりやすいと思います。
一旦uint32bitの配列に16bitごとにビットシフトして、ライティング結果を格納しておいてのちにポストプロセスのステージでレンダーターゲットに描画します。
以下はライトを1000個ほど描画するデモです。(画像クリックでデモ動画が流れます)

ポストエフェクト
ポストエフェクトは以下を実装してみました。
- Bloom
- SSAO
- Vignette
- ToneMapping
Bloomは縮小バッファを生成して距離の2乗で減衰するBloomを実装しました。
SSAOはサンプルポイントと対象ピクセルとの高さの差分の平均を使用しています。
ToneMappingはアンチャーテッドでも使用されたアルゴリズムを使用しています。http://filmicworlds.com/blog/filmic-tonemapping-operators/
最終的なポストエフェクトは1パスで行っています。
その他
マップデータはUnityで配置してそのTransform情報をシーンデータとしてエクスポートしています。
モデルデータはFBXSDKを用いて独自のバイナリフォーマットに変換したうえで使用しています。
制作期間7か月くらいです。