内容
文章内にある各単語を抽出したり、whereをかけたりするときに、毎回正規表現書くのが面倒だったので、
抽出 or 除外したい単語をlist内にまとめておくと便利にできるやつを作った。
コード
sample.py
def regex_words(word_list):
w_list = []
forward_regex = "(^| )"
backward_regex = "($| )"
for w in word_list:
w = str(w).strip()
regex_word = f"{forward_regex}{w}{backward_regex}"
w_list.append(regex_word)
return "|".join(w_list)
t_words = ["test ", " test", " test ", "testterms"]
regex_sentence = ["test"]
r_words = regex_words(regex_sentence)
print("r_words: ", r_words)
for t in t_words:
print(t)
print(re.search(r"{}".format(r_words), t))
print("*" * 100)
まあとりあえず実行してみてちょ。
t_wordsに文章等を入れ、regex_sentenceに抽出(除外)したい単語を入れる。
そうすると下記のような感じで正規表現で引っ掛けられる単語を判定可能に。
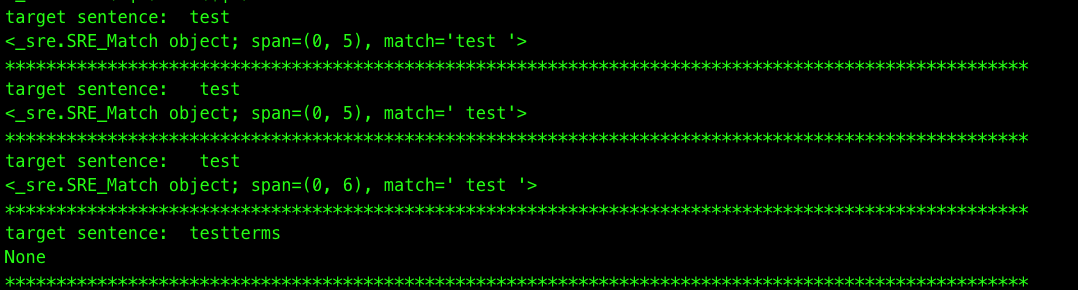
r_wordsを使うことによって、
df.str.replace(r_words, "")
とか
df[df.str.contains(r_words)]
とか超便利。