やったこと
デシル分析の際にSQLでよく使っていたntile関数が検索しても、
出てこなかったので、関数を作成した。
SQLで「ntile最高。 で、なんでPythonにねーんだよ..」と感じた諸兄達に捧げる。
ntile関数 (ちょい編集した)
まあ、使い方としては、
df=pandas dataframeを入れてもらい、
col=デシル分析したい対象のカラム名を入れるべし。
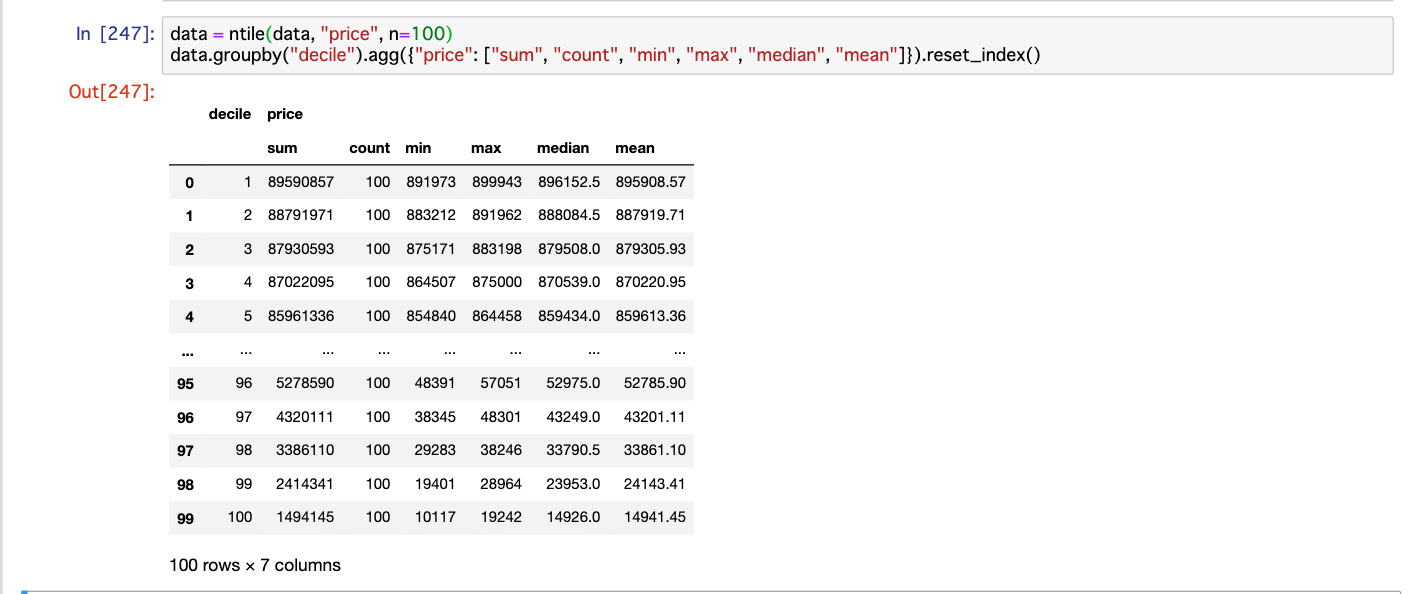
n=10としているが、100グループにしたい場合はn=100等にしてちょ。
n_tile=Trueとすると、decile数だけカラムとして付与するdataframeを返す、
Falseにすると各種集約関数付きdataframeを返す
agg=上記n_tile Falseにした場合の使いたい集約関数、
「sumだけでええわ」という方は、引数にagg=["sum"]として使う。
※コメントを英語にしてるのは英語の勉強中だから。
def ntile(df, col, n=10, n_tile=True, ascending=False, aggs=["sum", "count", "min", "max", "median", "mean", "std"]):
# check pandas dataframe type
if type(df) == pd.core.frame.DataFrame:
# check int or float
if type(df[f"{col}"].max()) == np.int64 or type(df[f"{col}"].max()) == np.float64:
ntile_df = pd.DataFrame()
length = len(df)
df = df.sort_values(col, ascending=ascending).reset_index(drop=True)
div_n = math.ceil(len(df) / n)
# mark N group
for idx, num in enumerate(range(0, length, div_n)):
n_df = df[num: num+div_n]
n_df["decile"] = idx + 1
ntile_df = ntile_df.append(n_df)
# return ntile_df if need only decile data
if n_tile:
return ntile_df
# otherwise aggregate col
agg_df = ntile_df.groupby("decile").agg({f"{col}": aggs}).reset_index()
# clean columns
agg_df.columns = ["".join(c) for c in agg_df.columns]
# merge two data
ntile_df = ntile_df.merge(agg_df, on="decile").copy()
return ntile_df
raise TypeError(f"`{col}` must be int or float type")
raise TypeError(f"`{type(df)}` must be pandas.core.frame.DataFrame type")
サンプルデータを作成
import pandas as pd
import random
# random price的なやつを作成
price = random.sample(range(10000, 900000), k=10000)
# 上記を用いてdataframeを作成する
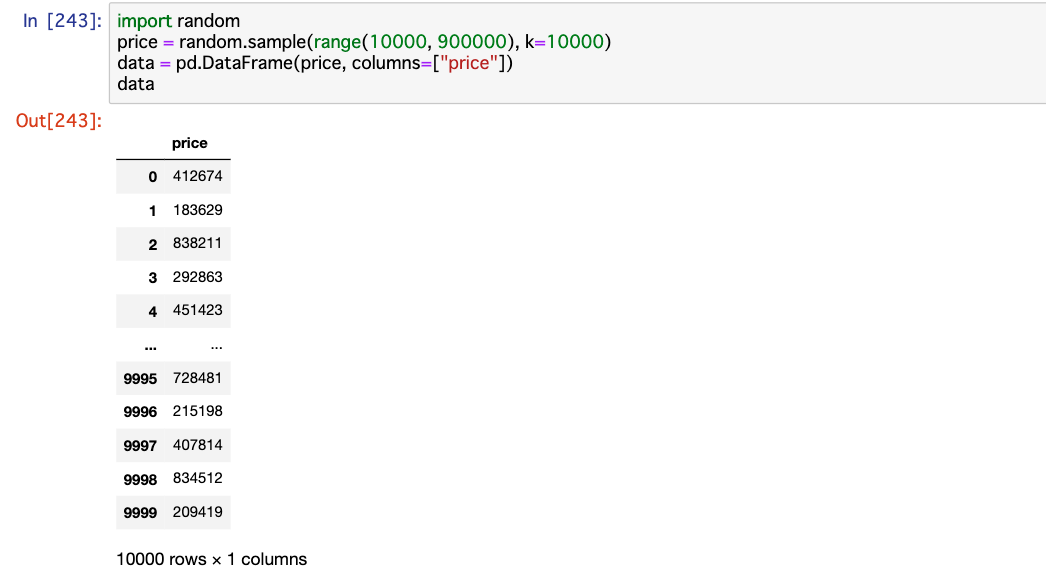
data = pd.DataFrame(price, columns=["price"])
中身はこんな感じ。
こんな感じに使う
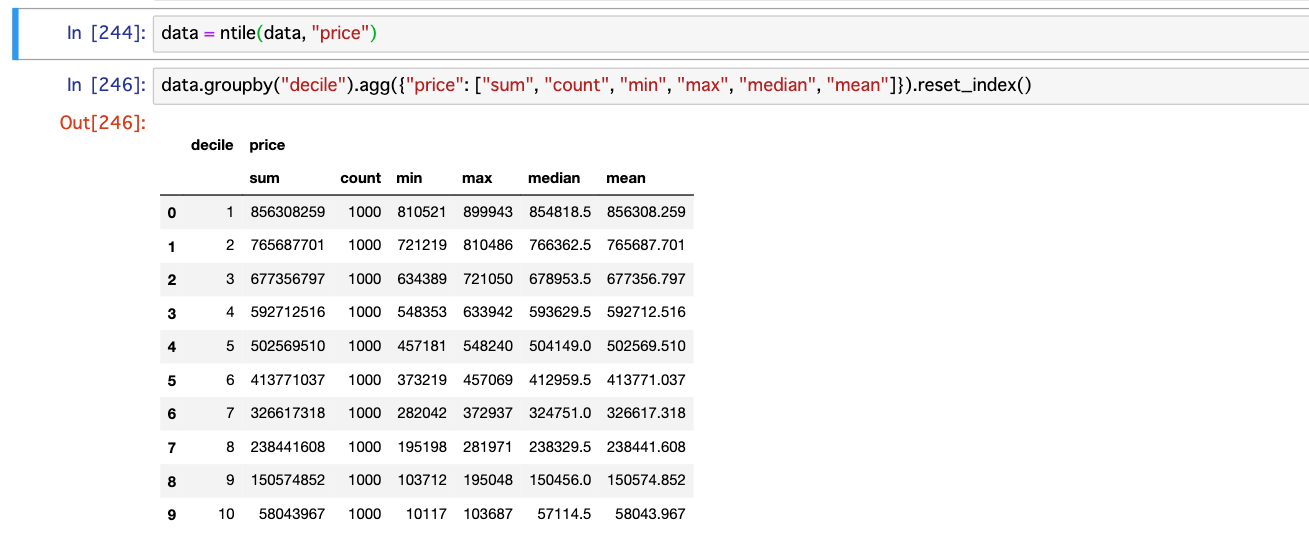
# dataを関数に入れちゃう。 n=10のデフォルトのまま
data = ntile(data, "price")
# decileでgroupbyして、各種集約関数を適用してみる。
data.groupby("decile").agg({"price": ["sum", "count", "min", "max", "median", "mean"]}).reset_index()
n=10
n=100
n_tile=Falseの場合は
data = ntile(data, "price", n=5 , n_tile=False)
data.pricemin.value_counts().sort_index().reset_index().rename(columns={"index": "price_segment", "pricemin": "count"})
そしてこれを見て欲しい。
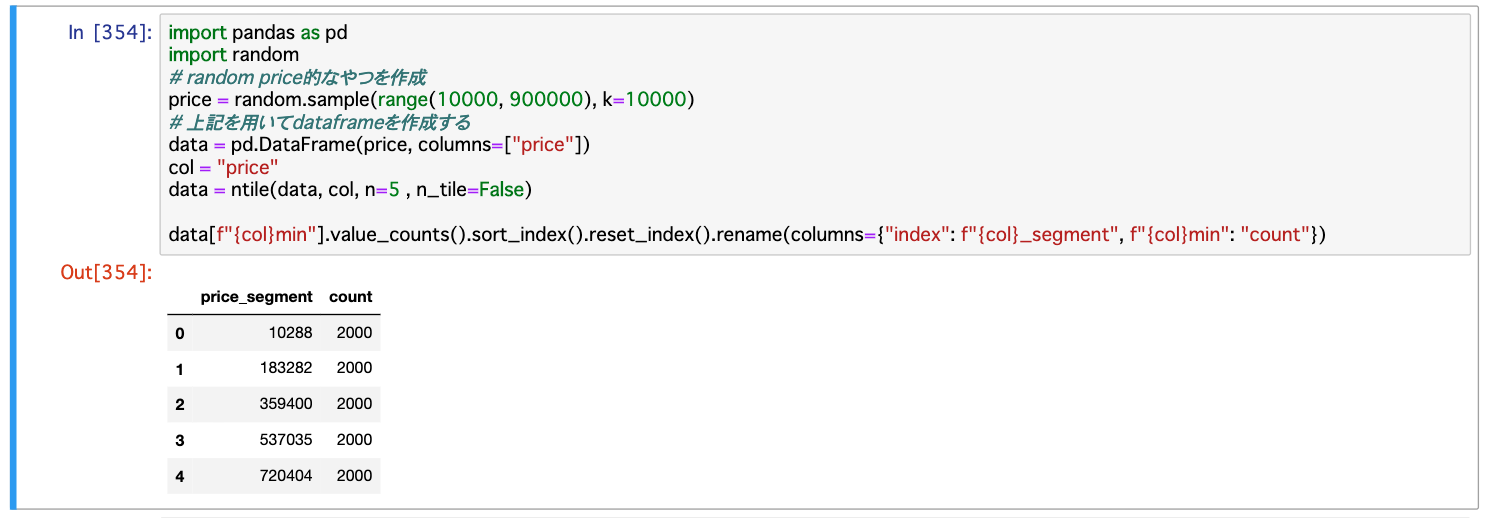
下記のようなことをやったことはないだろうか?
そして「対象のカラムに階級数を全部n%ずつの階級を作ってくれる関数ってないのかね??」
と感じたことはないだろうか?
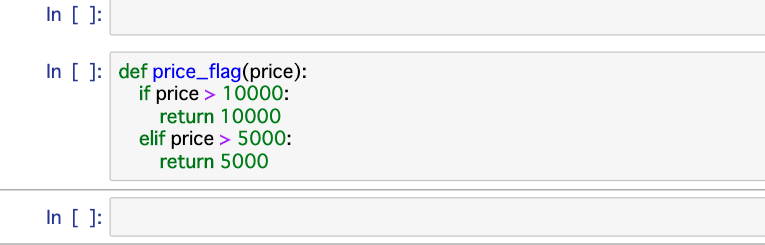
私は初心者なので上記を何度か思ったことがある。
毎回ntileを見て、手で修正していたが、今後はn=10の部分を変えるだけで変更が可能になった。
やっぱSQLよりpythonのが小回りが利く。
終わりに
検索不足か知らんけど、SQLでのntile関数がpython様に無いのが不思議だが、
まあ色々練習も兼ねて作ってみたから、SQLerからpythonerに転職した方はぜひ使ってみて欲しい。