1. Transformerの概要
Transformerは、ニューラルネットワークをベースとしたディープラーニングのモデルで、特に自然言語処理(NLP)の分野で広く使われています。このモデルは、従来のRNN(リカレントニューラルネットワーク)やLSTM(Long Short-Term Memory)といった時系列データを扱うモデルの限界を克服するために開発されたモデルになります。RNNLSTMについても下記の記事を参照ください。
Amazonの参考書籍はこちらから。
2. RNNの限界とTransformerの革新
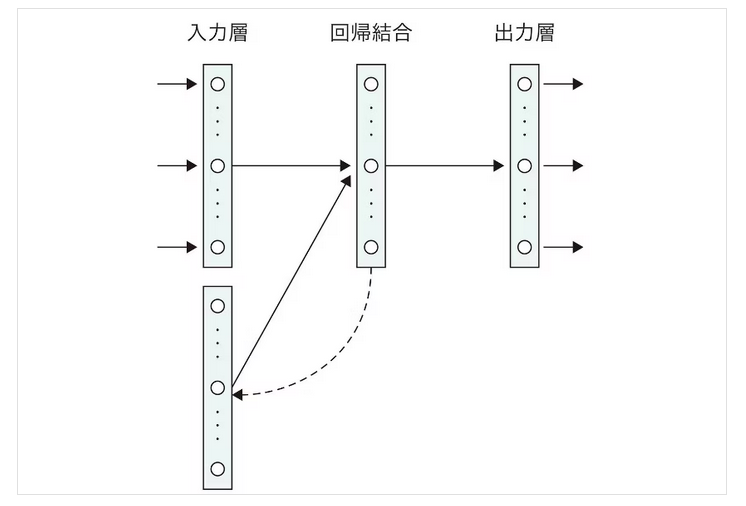
RNNは過去の情報を保持して、次のステップにフィードバックするという機構(下図の回帰結合層)を持っていますが、長いシーケンスにおける情報の依存関係を十分に学習することが困難で、「長期依存関係」の問題を抱えています。これに対処するためにLSTMやGRUなどが開発されましたが、計算リソースが膨大になるという問題がありました。
TransformerはRNNのような逐次処理を排除し、代わりに全ての入力単語に対して一度に注意を向ける「Attention機構」を取り入れたモデルです。このため、並列処理が可能で、RNNよりも高速かつ効率的に長い依存関係を学習できるようになっています。
3. Encoder-Decoderモデル
Transformerは、エンコーダー・デコーダーモデルの構造を持っています。エンコーダーが入力を処理して、デコーダーがその出力から目的の結果を生成します。特に、注意すべきは「Self-Attention」と呼ばれる機構で、これは入力データ全体の中でどの部分に注意を払うべきかを学習します。このSelf-Attentionが、長距離の依存関係を効率的に捉えるための鍵となっています。
4. Attention機構
Attention機構は、「時間の重み」をネットワークに組み込んだもので回帰結合層の重み付き和を採用することで、時間の重みを考慮したモデルを実現する。
Attention機構は、ある単語が他の単語とどれくらい関連しているかを計算する手法で、文全体を考慮しながら、特定の単語に重み付けを与えて処理します。これにより、Transformerは文中のどの単語に対しても双方向的に注目しながら情報を効率的に処理できるのです。
トランスフォーマーはエンコーダとデコーダからRNNを排除し、代わりにSelf-Attention(自己注意機構)と呼ばれるネットワーク構造を採用している点が最大の特徴になります。
5. BERTとの関係
BERTは、このTransformerのエンコーダー部分を利用して、双方向から文脈を理解できるように設計されたモデルです。BERTの革新は、文脈を左右両方向から同時に捉える「双方向性」にあり、これが従来のモデルよりも精度を向上させる大きな要因となっています。
修正版の説明
Transformerは機械学習におけるディープラーニングモデルで、特にRNNが抱えていた長期依存関係の問題を解決するために開発されました。RNNでは逐次処理が必要で、過去の情報をフィードバックする機構がある一方で、長いシーケンスに対する学習が困難でした。
Transformerではこの逐次処理を排除し、Attention機構を組み込んだエンコーダー・デコーダーモデルとして設計されています。このAttention機構により、入力データ全体を一度に処理し、文の各部分がどのように相互に関連しているかを効率的に学習します。
特に、Self-Attentionという仕組みによって、文中の単語同士の依存関係を双方向に捉えることが可能となり、従来のRNNベースのモデルよりも高精度かつ高速な処理が可能になりました。