はじめに
先日、Geoffrey Hinton教授 1がSIGIR 2020 でオンライン講演したときの録画をみて、そういえばこの辺りの話を全然知らないなと思い、改めて autoencoder とはなにか?ということについて調べてみました。
誰のための記事か
- 基本的に、覚えられなくて何回も調べてしまう私のための記事です。
- もし私のような人がいれば助かるかもしれません。
- autoencoder についての初歩的な話が読みたい人にはもしかしたら有益かもしれません。
誰のための記事でないか
- 機械学習のプロフェッショナルで高度な内容をお求めの人にはレベルが初歩過ぎて合わないかもしれません。
- そもそも機械学習の手法に興味がない人も合わないかもしれません。
- サンプルを探しているひとにもあまりおすすめできないです。サンプルをお探しの方は GitHub2 を漁るといいと思います。
TL;DR
- autoencoder とは、NN (Neural Network) を用いて実現される次元圧縮・特徴抽出に使われる機械学習アルゴリズムです。
- 2006 年に Geoffrey Hinton 教授が提案しました。
- 基本の autoencoder は入力層と出力層が同じになるように学習をすすめます。
- 入力層と出力層の差分を取ることで異常検知などに使えるアルゴリズムです。
Autoencoder とは
まずは Wikipedia の定義をおさらいしましょう。
オートエンコーダ(自己符号化器、英: autoencoder)とは、機械学習において、ニューラルネットワークを使用した次元圧縮のためのアルゴリズム。
なるほど、なるほど。ところで、面白いことに、日本語の Wikipedia のこの項の概要では
オートエンコーダは3層ニューラルネットにおいて、入力層と出力層に同じデータを用いて教師あり学習させたものである。
と書いてあって 教師あり学習 とカテゴライズされているのですが、英語の Wikipedia の定義では、
An autoencoder is a type of artificial neural network used to learn efficient data codings in an unsupervised manner.
in an unsupervised manner とあり、なぜか違う雰囲気を醸し出しています。どちらが正しいんでしょうね?
ちなみに、MathWorksのサイトでは、
オートエンコーダ(自己符号化器, autoencoder)とは、ニューラルネットワークを利用した教師なし機械学習の手法の一つです。
と書いてありますから、とりあえず教師なし学習と考えることにしておきましょう。
何が教師ありなのか、というところの捉え方で違うのかもしれませんが、そこは初心者らしく突っ込まないで華麗にスルーすることにします3。
図で説明
超単純な autoencoder を図にあらわしてみましょう。
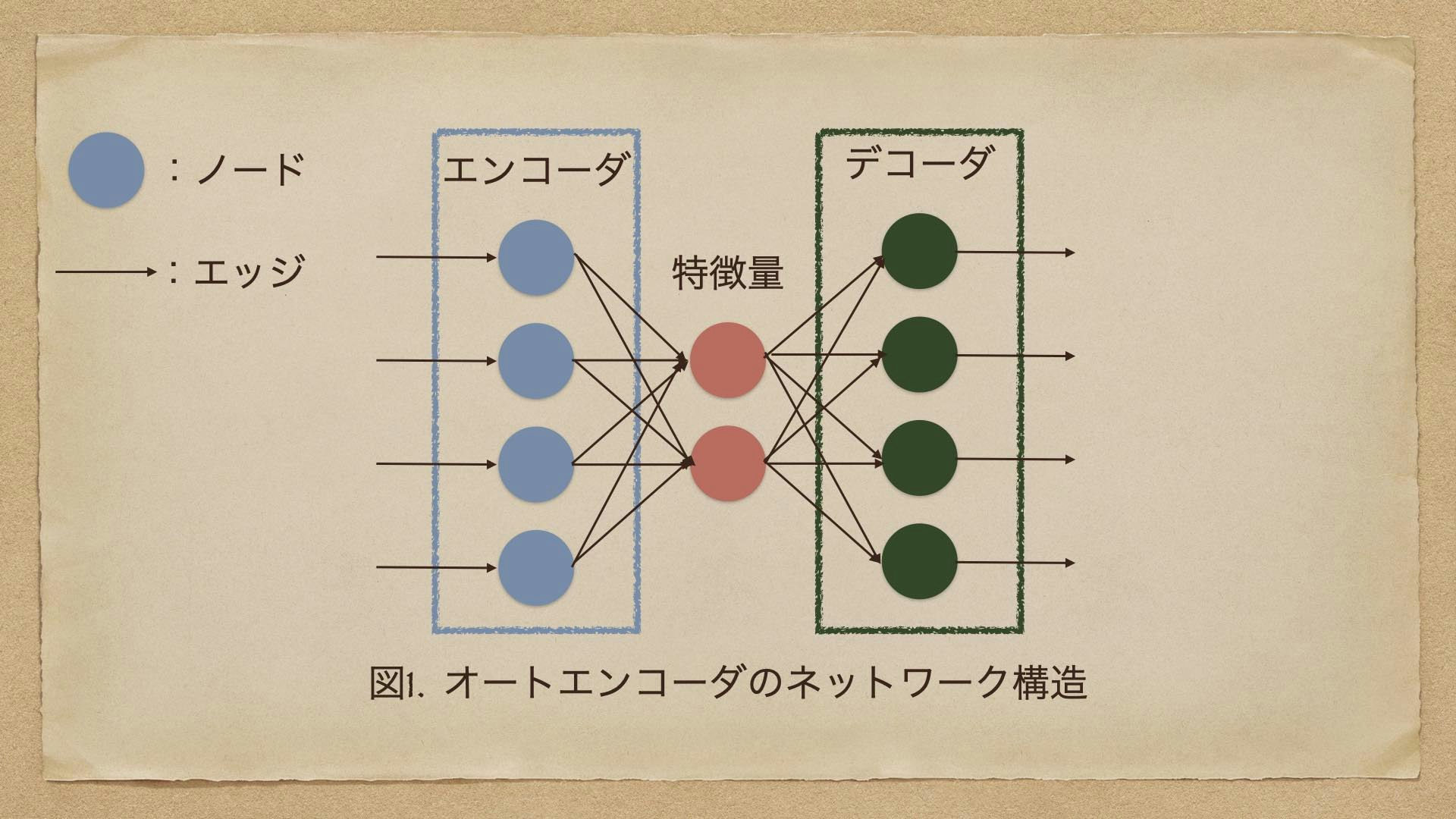
円がノード、矢印がエッジをあらわすのですが、ノードが何か計算をするところ、矢印はデータ入出力の方向を表すと考えると良いと思います。
この図でわかるとおり、エンコーダとデコーダのノードの数が同じで、真ん中の特徴量と書かれたノードはエンコーダとデコーダよりも数が少なくなっています。この場合は、エンコーダとデコーダがそれぞれ4つのノードをもち、特徴量は2つのノードを持っています。
つまりエンコーダから見た場合、ノードが4つから2つに減っているわけで、これが「次元削減」というものにあたります。次元削減というとなんのこっちゃと思う向きもあると思いますが、ノードが減っている=計算量が減る、というのと同じ意味と思っていれば、なんとなく感覚はわかると思います。この次元削減されたノードからエンコーダと同等のノードを持つデコーダにデータが展開されたときに、エンコーダと同じようになるように特徴量を学習させるのが autoencoder です。
機械学習やデータサイエンスの分野で何が面倒かというと、次元の呪い(curse of dimention) というやつですね。1次元なら一個ずつ計算すればよいけど、n次元になるとリア充、ではなく、計算量が爆発するのでとても嫌われ者です4。Hinton 教授の原論文のタイトルReducing the Dimensionality of Data with Neural Networksにもあるとおり、そもそもニューラルネットワークでデータの次元を削減するにはどうすればいいか、というところがテーマのようです。
コードを書こうと思ったが ...
Keras のページにめっちゃ丁寧に書いてありました。ここんところ眠くて仕方がないので、この紹介で許してください。
m(__)m
ちなみに、CoLab に Keras のコードをコピペして計算をしてみたところ、次のようになりました。使用されているのは MNIST のデータですね。MNIST は白黒の数字の手描き文字画像のデータセットです。元のコードと同じく Epoch = 50 でやってみました。
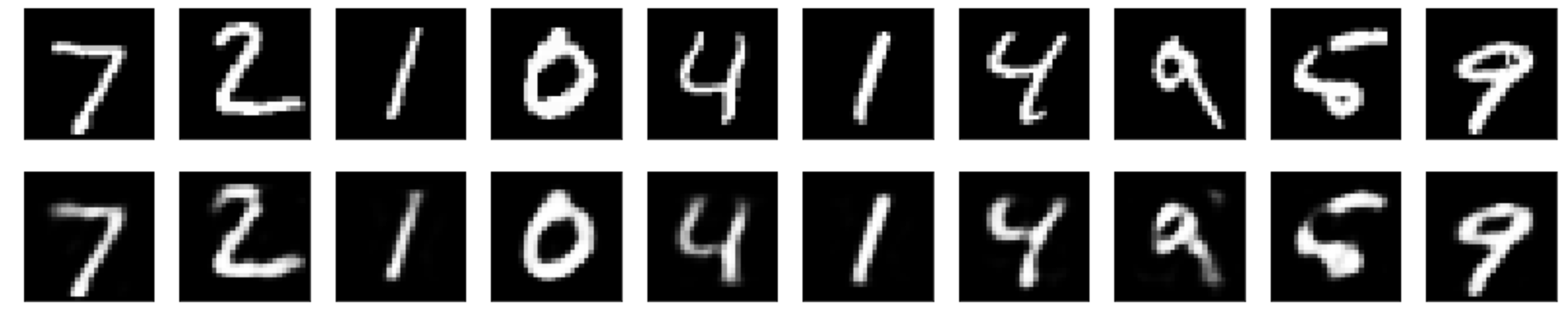
上が入力画像、下が出力画像です。端が薄かったり小さい丸が潰れてたりするのはご愛嬌ですかね。このくらいまで形が真似できていれば(10年以上前の)次元削減の効果としては良かったのではないかと。
(今回は追及しませんが、いまはもっと精度の良いものがあるようですね。)
autoencoder は何に使われるか?
autoencoder は、エンコードして同じものにデコードするという性質上、あらかじめ正常なデータでざっくり訓練しておいた学習器に、本番データを食わせて、入力と出力の差分をとって異常検知に使われたりするそうです。
あるいは、変分オートエンコーダなる手法でデータ生成をしてみたり、データの分類やクラスタリングに利用されるそうです。Apple Watch で人の活動を検知したりしていますが、あーゆーのに、単純な autoencoder よりもっと進んだアルゴリズムが使われているのかもしれませんね。
あと、あらかじめ正しい画像データを先に学習することで、ノイズ除去にも使われたりします。単純なノイズが入った画像だと、Webで人間認定するための画像コードがあっさり破られそうな気配です。
おわりに
なんというか、autoencoder は恒等写像みたいな言葉でいわれると、分かったようなわからないようなという気がしますが、結局、入力と出力をできるだけ同じになるように学習するのが autoencoder の面白いところなのではないかと。
入力と同じものを出力するというタスクを考えると、似たような作用をするものとして GAN が思い浮かびますが、GAN の方が精度良く元の入力を再現できるようです。autoencoder と GAN の比較の記事があったので、興味のある方は読んでみると楽しいかもしれません5。
拙い記事をここまで読んでくださり、どうもありがとうございました。
おまけ
そもそも、なんで autoencoder とか言い出したかというと、自然言語処理で一世を風靡したというか今も風靡している Google BERT とかを調べていてたどりついたわけで ... なんというか、構文解析でゴリゴリ翻訳するのが日本の英語学習なら、BERT は「どんどん話すための瞬間英作文トレーニング」 っぽいなーと思うのでありました。
この本のメソッドは、同じような構文の英文をどんどん単語を入れ替えたり、平叙文を疑問文にしたりということを高速に繰り返し学習するというのが味噌だったりするようなので、なんとなくそういう手法に似てるところはありそうだなと思ったりします。
BERT はあまり autoencoder と関係なさそうに見えるんですが、BERT で使う Transformer というのが関係があるっぽかったので、まず autoencoder を調べてみようと思った次第6。
あと、人間は学習する生き物である、というふうに言われていたりしますよね。師匠のやり方をみて弟子が見様見真似で道具を作ってみるとか、そういうのは autoencoder っぽいですね。そう考えると、autoencoder というアルゴリズムは、発想が認知心理学の先生ならではなのかも7、と思ったりしました。■