概要
LLaVAとは
LLaVAは「Large Language and Vision Assistant」の略であり、入力された画像に関するやり取りが可能なマルチモーダルなLLMです。同様な目的でGPT-4が用いられますが、LLaVAはGPT-4とそれほど遜色ない結果が得られることから注目を集めています。
Ollama Python Libraryを用いたLLaVAの実行例
LLaVAは公開されたLLMであり、Ollamaなどを用いることでローカルで動かすことができます。
上記などに基づいてOllamaをインストールしたのちにCLIで下記を実行することでLLaVAのインストールかつLLaVAを用いた処理を行うことができます。
$ ollama run llava
以下、上記を参考とするOllama Python Libraryを用いた実行例について簡単に確認します。

Ollamaロゴ
たとえば上図のOllamaロゴと"Describe this image:"を入力すると下記のような結果が出力されます。
The image displays a white and black icon of an alpaca with a simple
design. The alpaca is depicted from the front, with its head positioned centrally within the circle. It has a round body and two oval ears, each adorned with a small circular detail. Its eyes are represented by dots, and it features two short horns on top of its head. The image is presented in a flat graphic style, characteristic of emojis or icons commonly used to represent different categories or products.
Ollama Python Libraryの詳しい用法については下記で詳しく取り扱いましたので、合わせてご確認ください。
LLaVAの構成
大まかな構成
LLaVAの大まかな構成は下図などを元に確認することができます。
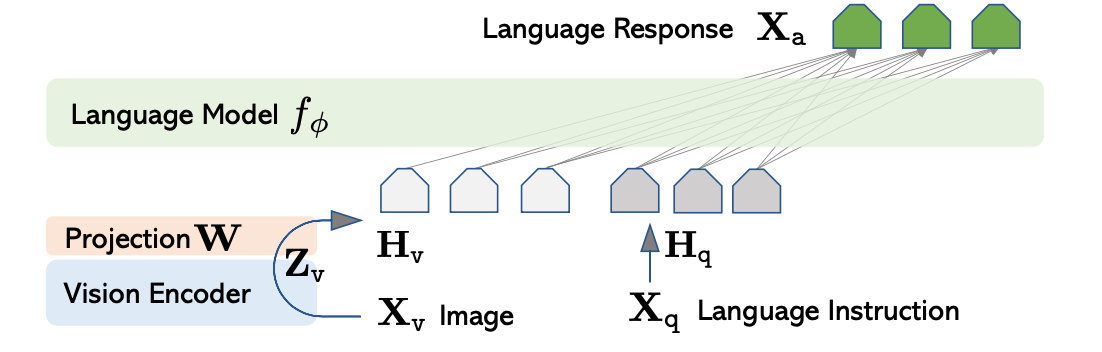
LLaVA論文 Figure 1
基本的にはVision Encoderを用いて抽出した画像の特徴量ベクトルに対し、射影行列(projection matrix)の$\mathbf{W}$をかけることで画像のEmbeddingを取得し、LLMに反映させると理解すれば良いです。
LLaVAではLLMにはVicuna、Vision EncoderはViT-L/14を用いたとされます。VicunaとViT-L/14については次項と次々項で詳しく確認します。
LLM(Vicuna)

「Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality」より
上記より、VicunaはLLaMAをFineTuningすることによって得られたことが確認できます。よってVicuna-13BはLLaMA-13Bに対応すると考えることができます。
LLaMA-13B
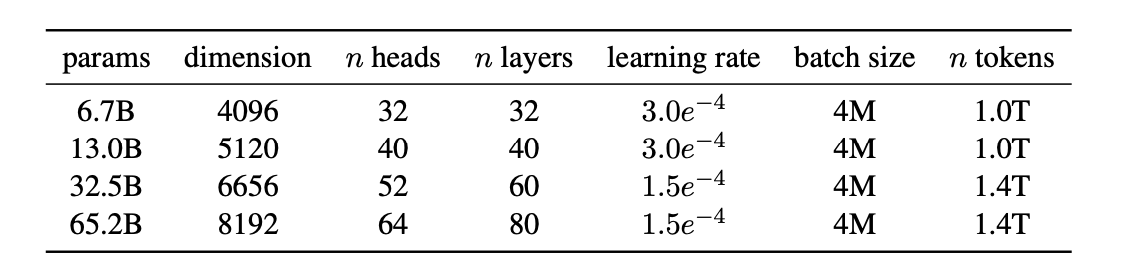
LLaMA論文 Table 2
上記より、LLaMA-13B1のハイパーパラメータについて確認することができます。
Image Encoder(ViT-L/14)
ViT-L/14はViT(Vision Transformer)のLargeに対応します。

ViT論文 Table 1
ViT-B(ViT-Base)、ViT-L(ViT-Large)、ViT-H(ViT-Huge)はそれぞれ上記のように構成されます。ViT-BとViT-LはBERTのBASEとLARGEに対応していることが下記のBERTの論文からも確認できます。

BERT論文 Section.3 本文より
ViTで画像を取り扱うにあたっては、画像をパッチ単位で分割し、それぞれをトークンと見なす処理が実行されます。ViTのオリジナルの論文では$16 \times 16$の256ピクセルを1つのトークンと見なす処理が基本となります。このパッチ作成の際の区切りが16かつViT-Lを用いる場合、ViT-L/16のように表すことは抑えておくと良いです。LLaVAではViT-L/14なので、「ViT-Largeを用いるかつ、$14 \times 14$のパッチを用いる」と理解すれば良いです。
ViT-L/14がViTを表す一方で、LLaVA論文ではViT論文を直接参照していないことに注意が必要です。LLaVAで用いられるViTは分類ではなく「特徴量抽出(embedding)」が目的なので、対照学習(Contrastive Learning)という考え方に基づきます。
よって、この対照学習にViTを用いた取り組みであるCLIPの論文がLLaVA論文の本文中で参照されています。
CLIP
CLIPは「Contrastive Language-Image Pre-Training」の略であり、対照学習の枠組みでマルチモーダルな事前学習を行った研究です。

CLIPついては下記で詳しく取りまとめましたので、合わせて確認してみると良いかもしれません。
参考
・LLaVA論文
・Vicuna
・LLaMA論文
・ViT論文
・BERT論文
・CLIP論文
-
Bは10億(Billion)に対応するので、LLaMA-13Bは約130億のパラメータを保持するLLMであることが読み取れます。 ↩