『Retrieval-Augmented Generation for Large Language Models: A Survey(以下、RAG Survey論文と表記)』の内容について以下、取りまとめました。
https://arxiv.org/abs/2312.10997v5
概要
RAG研究のまとめ
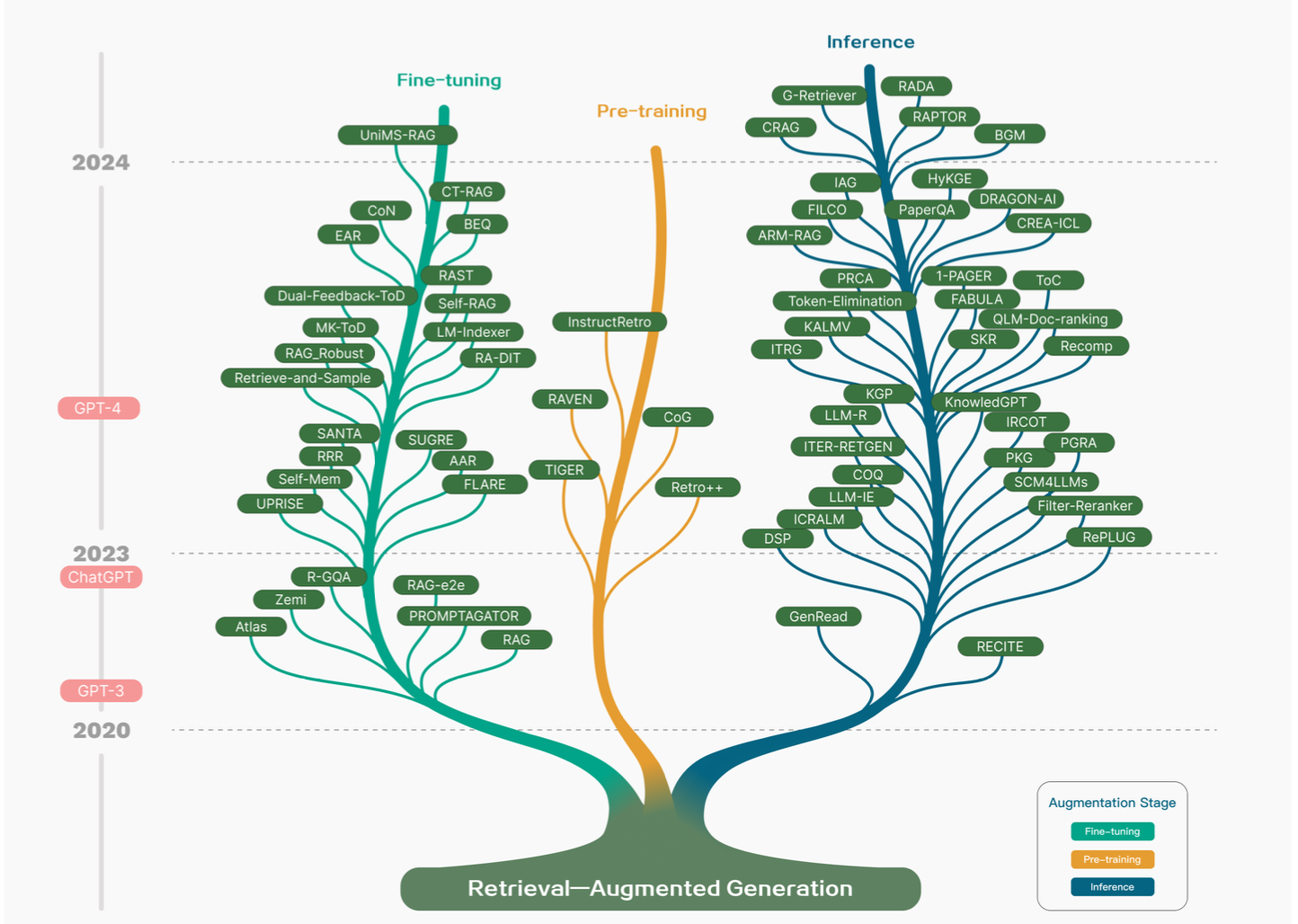
RAG Survey論文 Fig.1
上記では、RAGの研究が「Fine-tuning」・「Pre-training」・「Inference」の3種類に分類されます。
RAG Survey論文の構成
Survey論文の構成は『Ⅰ. Introduction』に概要が記載されているので、以下に簡単にまとめました。
Abstract
Ⅰ. Introduction
-> Surveyの概要について取りまとめ
Ⅱ. Overview of RAG
-> RAGのメインのコンセプトと現在の枠組み(current paradigms)
Ⅲ. Retrieval
-> Retrievalにおけるindexingやembeddingの最適化
Ⅳ. Generation
-> Generation時のpost-retrieval processやLLMのfine-tuningについて
Ⅴ. Augmentation process in RAG
-> 3つのAugmentationの過程についての分析
Ⅵ. Task and Evaluation
-> RAGのdownstream tasksと評価システムについて
Ⅶ. Discussion and Future Prospects
-> RAGの現在の課題と今後の研究の方向性について
『Ⅵ. Task and Evaluation』の『downstream tasks』はpre-trainingに対し、手元の小規模データセットに基づくタスクのことを大まかに指します。downstream tasksに取り組むにあたっては、fine-tuningやChatGPTのように入力を調整することが主流です。
RAGの概要(Ⅱ. Overview of RAG より)
RAGの大まかな処理の流れ
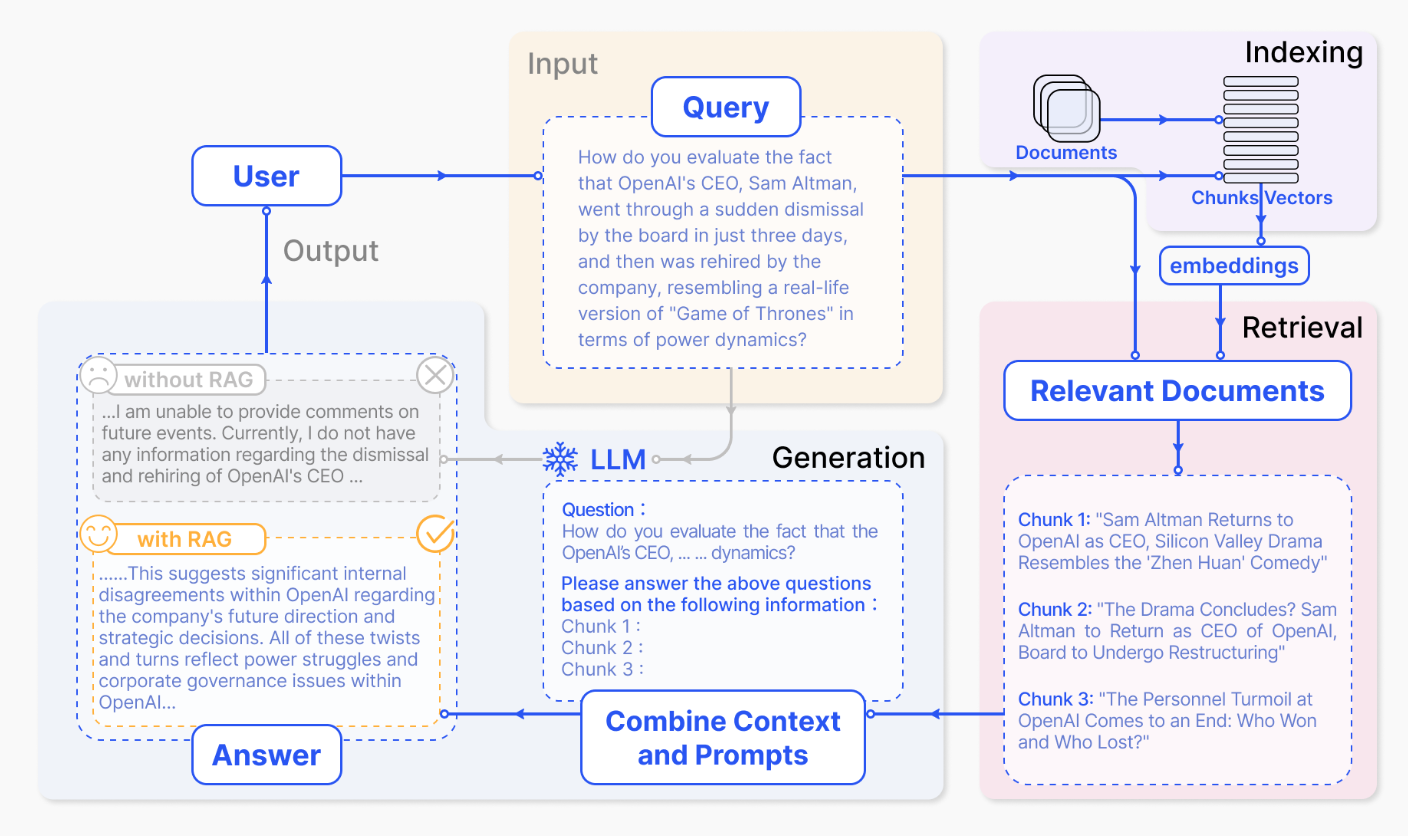
RAG Survey論文 Fig.2
RAGの大まかな処理の流れは上図のように表されます。以下、Indexing、Retrieval、Generationについて詳しく確認します。
Indexing
- PDF、HTML、Wordなどのフォーマットから統一的なプレーンテキストを作成し、digestible chunksに分割する。
- embedding modelを用いることでchunksをベクトル化し、ベクトルデータベース(vector database)に保存する。
Retrieval
- ユーザーからの入力(user query)に対し、Indexingで用いたのと同様なembedding modelを用いることでuser queryをベクトル表現(vector representation)に変換する。
- user queryに基づくベクトル表現とベクトルデータベースに格納した結果の類似度を計算し、類似度の高い上位K個のchunksを抽出する。
- 抽出したchunksをプロンプトの拡張コンテキスト(expanded context)に追加する。
Generation
- user queryとRetrievalによって選ばれた文書(selected documents)を合成する。
- LLMに入力し、生成を行う。
Naive RAGとその発展
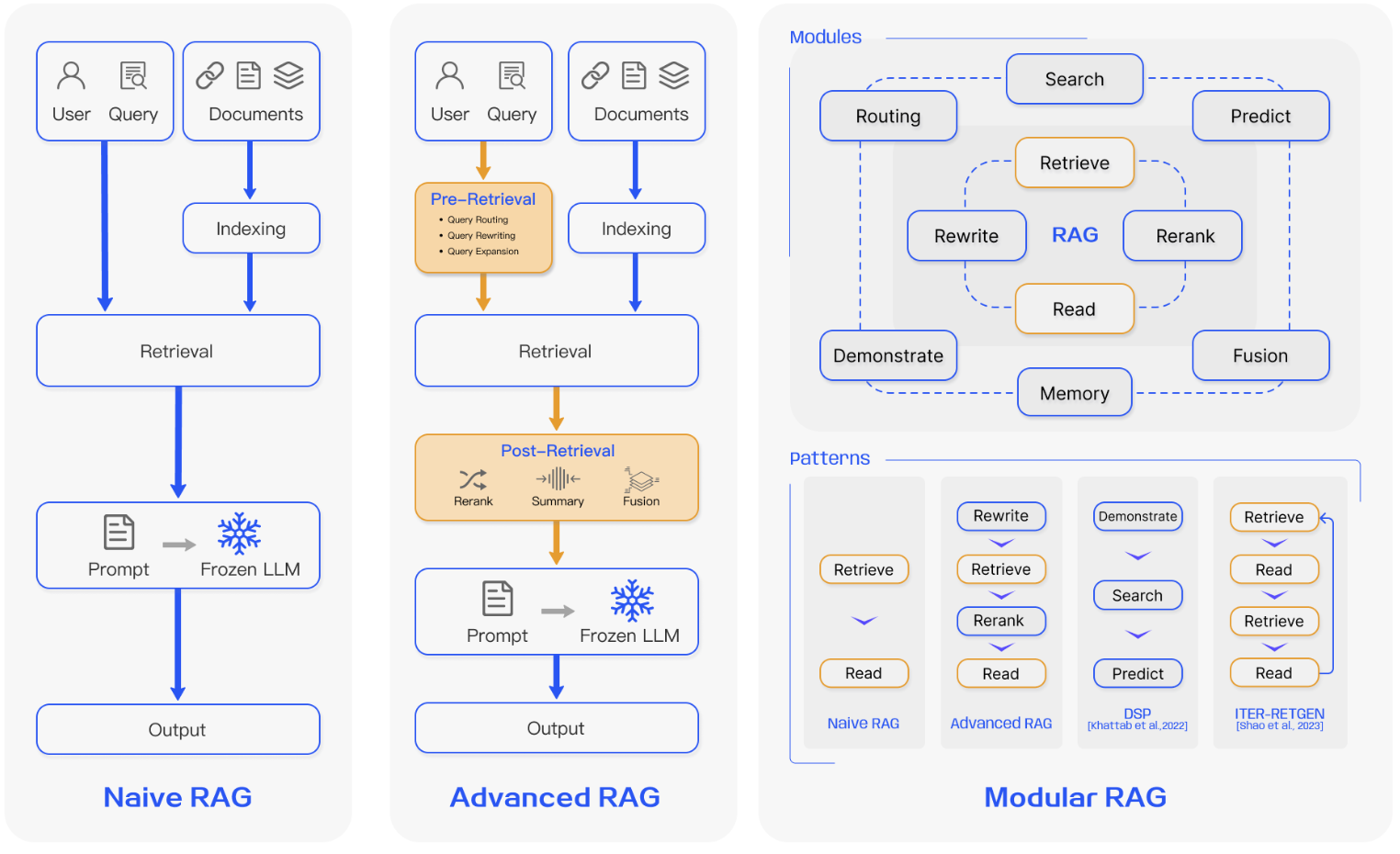
RAG Survey論文 Fig.3
当項では「RAGの大まかな処理の流れ」で確認したRAGの発展について確認します。以下、Naive RAG、Advanced RAG、Modular RAGについてそれぞれ確認します。
Naive RAG
「RAGの大まかな処理の流れ」で確認したRAGの基本的な処理構造をRAG Survey論文ではNaive RAGと呼んでいます。「RAGの大まかな処理の流れ」の内容と重複するので、ここでは省略します。
Advanced RAG
・Pre-Retrieval
Pre-retrieval processではindexの構造やuser queryの最適化を行います。
・Post-Retrieval
Post-Retrieval Processでは得られた検索結果をクエリに効率的に組み合わせを行います。基本的にはchunksに再度ランク付けを行ったり、文脈圧縮(context compressing)を行ったりします。RerankingはLlamaIndex・LangChain・HayStackなどにも用いられます。
Modular RAG
Modular RAGは適応的かつ多機能のRAGであり、Naive RAGやAdvanced RAGを発展させた枠組みです。
RAGとFine-tuning
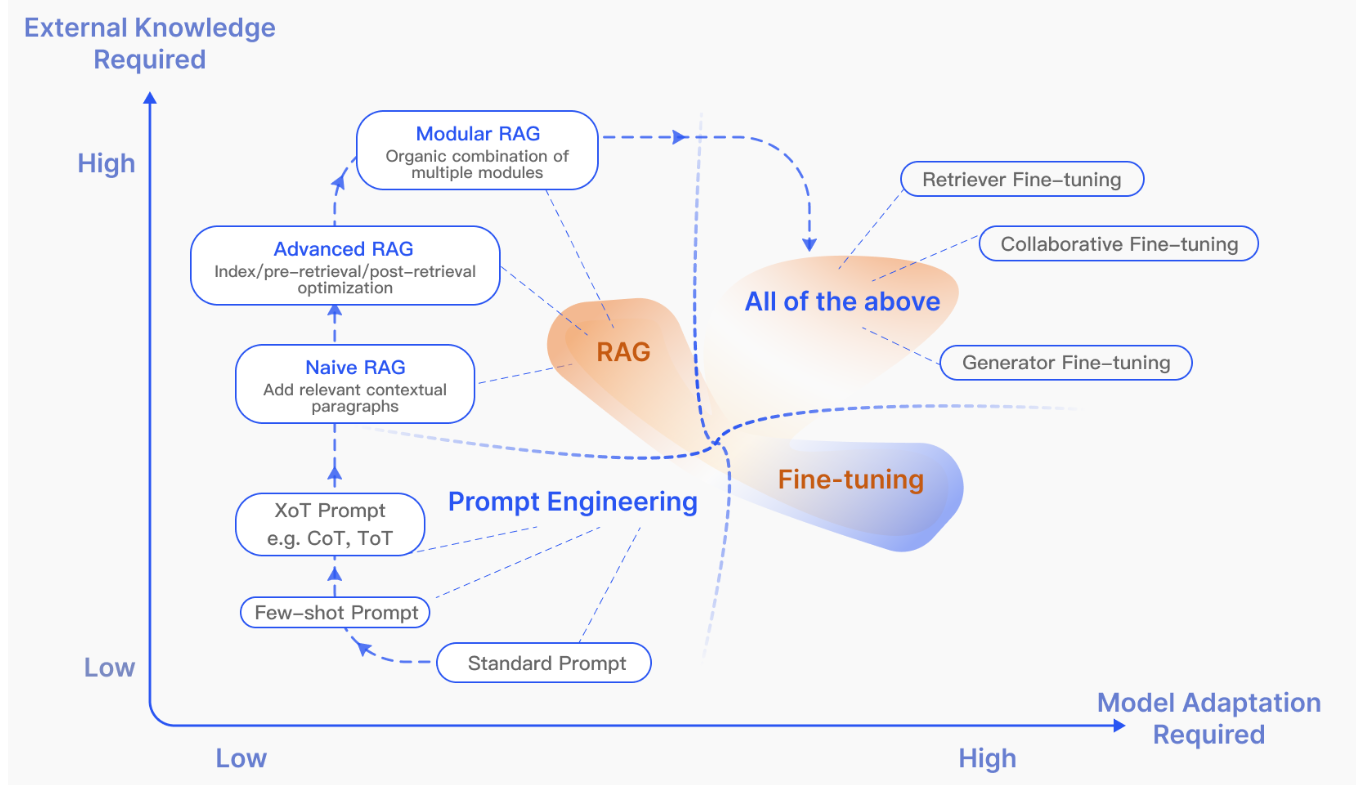
RAG Survey論文 Fig.4
上図はRAGと同時に議論されることが多いPrompt EngineeringやFine-tuningなどの関係を図式化したものです。「外部知識が必要か(External Knowledge Required)」と「Modelの再学習が必要か(Model Adaptation Required)」の2つの視点からRAG・Prompt Engineering・Fine-tuningの3つが整理されています。Prompt Engineeringは外部知識も再学習を用いない一方で、RAGは外部知識を用い、Fine-tuningでは再学習を行います。
Retrievalについて(Ⅲ. Retrievalより)
LLMの性能の向上にあたってRAGは外部知識(external knowledge)を用いますが、検索(Retrieval)を行う際にはいくつかの重要な要素があります。以下、それぞれについて確認します。
A. Retrieval Source
1) Data Structure
unstructured dataのテキスト形式が基本で、さらなる改善にあたってpdfのようなsemi-structured dataや、知識グラフ(Knowledge Graph)のようなstructured dataなどに拡張されます。
2) Retrieval Granularity
検索結果のデータの粒度も重要です。粒度が粗い場合は関連する情報を多く含む一方で冗長であり、結果が散漫なものになります。一方で、粒度がきめ細かい場合は計算負荷を増大させる一方で正しさを保証しないという点が課題です。このように粒度の調整は重要です。
B. Indexing Optimization
Indexingの際、文書は分割され、ベクトル表現に変換されます。この際のindexの質が、Retrievalにおける検索の正確さに反映されます。
1) Chunking Strategy
分割化された文書をchunkと言います。chunkの作成方法は主に2通りあり、文字数(100・200・512)で区切る方法と、Small2Bigのように文単位で区切る方法です。
2) Metadata Attachments
chunksをページ番号、ファイル名、著者などのメタ情報を元にリッチ化することで、検索の際にこのメタ情報に基づくフィルタリングを行うことが可能になります。また、timestampに基づいて重み付けを行うことで、新しい情報がより取得されやすくすることも可能です。
メタ情報はページ番号のように機械的に与えられるものに限らず、人工的に作成することも可能です。例えばパラグラフの要約などを与える場合があります。
3) Structural Index
情報検索の高度化にあたっては、ドキュメントの階層化を行うことも有用です。
・Hierarchical index structure
たとえば、chunksは対応するファイルと階層的な構造となります。
・Knowledge Graph index
ドキュメントの構造化を行うにあたって、知識グラフ(Knowledge Graph)を活用することは一貫性を保つ視点で有効です。
C. Query Optimization
Naive RAGでは基本的にはユーザーのクエリに基づく検索が試みられる一方で、正確かつ明確な問いの作成は難しいです。
1) Query Expansion
1つのクエリを複数に拡張することで、検索精度の向上や生成結果の最適化が可能です。
・Multi-Query
プロンプトエンジニアリングを用いることで、複数のクエリを作成するというのもQuery Expansionの一案です。
・Sub-Query
複雑なクエリをよりシンプルなsub-questionsの集合に分解することでクエリ拡張(Query Expansion)を行うことができます。
・Chain-of-Verification(CoVe)
ハルシネーション(hallucinations)を防ぐにあたって、拡張されたクエリをLLMを用いてチェックすることもあります。
2) Query Transformation
ユーザーのクエリを変換したクエリを用いることで検索を行うことも有用です。
・Query Rewrite
LLMを用いることでユーザーのクエリを書き直すことなども可能です。
3) Query Routing
D. Embedding
検索(Retrieval)は基本的にクエリとドキュメントに基づくchunksに基づいて行われます。したがって、Embeddingの質の向上によって検索の質を向上させることが可能です。
E. Adapter
Fine-tuningによって検索(Retrieval)の質を向上させるというのも一案です。UP-RISEやAAR(Augmentation-Adapted Retriver)などがその一案です。
LoRAのように少数のパラメータを導入してFine-tuningを行う枠組みをAdapterと言うようです。
Generationについて(Ⅳ. Generationより)
検索(Retrieval)後の結果をそのままLLMに入力するのはそれほど良い方法ではありません。以下、「検索結果のコンテンツ(Context Curation)」と「LLM(LLM Fine-tuning)」の二つの視点からの調整について確認します。
A. Context Curation
人間と同様にLLMも長文の前と後ろに着目し、真ん中はあまり重視しないので、生成時にはこれらについて気をつける必要があります。
1) Reranking
2) Context Selection/Compression
B. LLM Fine-tuning
LLMのFine-tuningを行うことでLLMの品質の向上や、Fine-tuning時に与える入力と出力に特化させた学習が可能になります。
Augmentationについて(Ⅴ. Augmentation process in RAGより)
Retrievalによって得た結果を活用してクエリを充実させることをAugmentationといいます。Augmentationの研究は下記のように大まかに分けることができます。
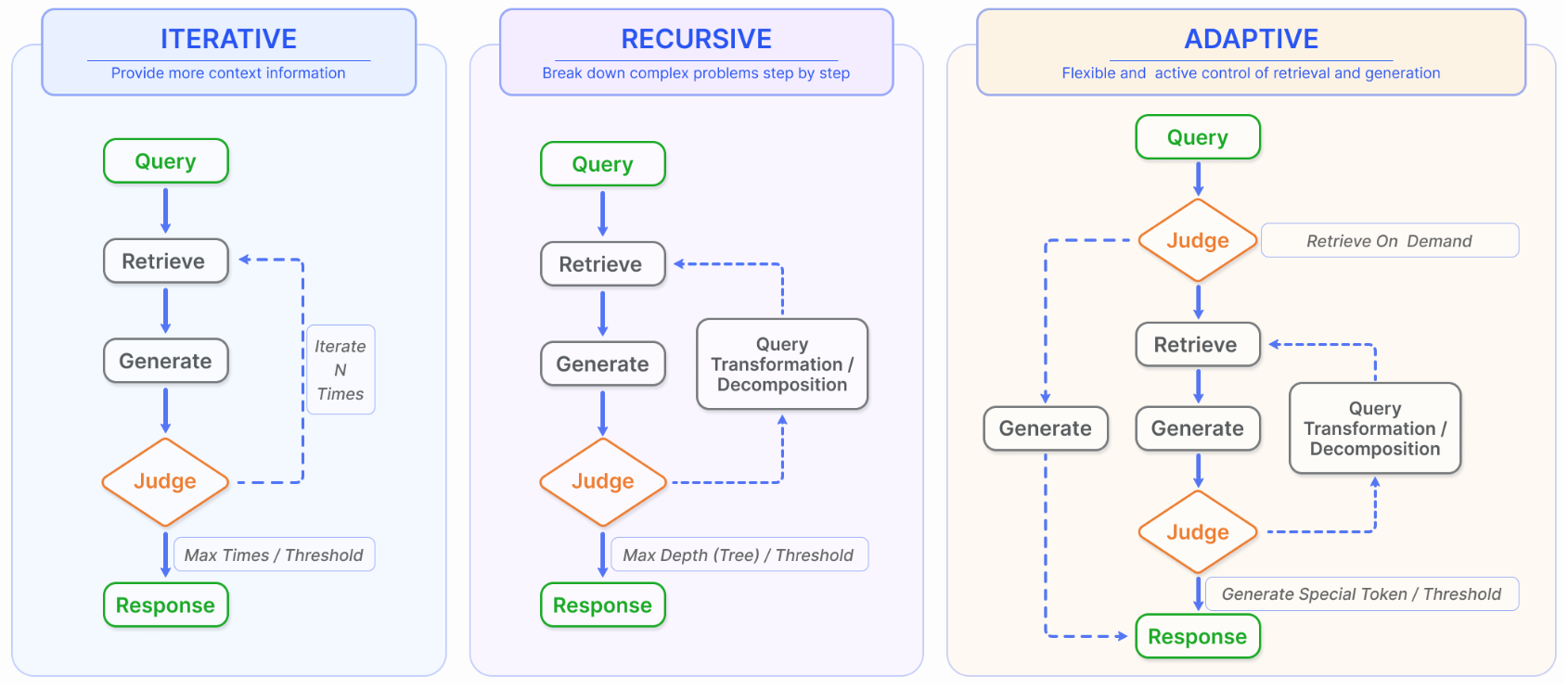
RAG Survey論文 Fig.5
A. Iterative Retrieval
初めに生成されたクエリを元に知識ベース(knowledge base)を複数回検索するのがIterative Retrievalです。Iterative Retrievalを行うことで回答生成をより頑健にすることができます。
B. Recursive Retrieval
Recursive Retrievalは探索した結果に基づいて次のクエリを生成する検索の方法です。情報を深く探索し、検索結果に相関性を持たせるにあたって用いられます。IRCoTのようにCoT(Chain-of-Thought)を発展させるにあたっても用いられることがあります。
C. Adaptive Retrieval
Adaptive RetrievalはRetrievalの規模をLLMが動的に判断するような処理プロセスです。
タスクと評価について(Ⅵ. Task and Evaluationより)
A. Downstream Task
B. Evaluation Target
C. Evaluation Aspects
D. Evaluation Benchmarks and Tools
RAGの課題と今後の研究トピックについて(Ⅶ. Discussion and Future Prospects)
A. RAG vs Long Context
近年ではLLMの取り扱う文脈は200,000単語を超えており、RAGが必要かどうかの議論が生じています。とはいえ、RAGは少なくとも現在は計算コストの点などから代用不可の役割を果たしています。長文向けのRAGが今後の研究トレンドの1つに挙げられます。
B. RAG Robustness
『Misinformation can be worse than no information at all.(誤答は何も回答しないよりも悪い)』という言葉があるように、Retrieval時のノイズや矛盾する情報はRAGの出力の品質に影響します。
このような誤答を防ぐにあたってCuconasuらが行った研究では、相関の低いドキュメントを含むことで正答率を30%以上向上させたとされます。
https://arxiv.org/abs/2401.14887
C. Hybrid Approaches
RAGとFine-tuningの組み合わせが有効だと考えられています。
D. Scaling laws of RAG
RAGを用いるにあたってのLLMのパラメータ数についてはまだ不確かのようです。
E. Production-Ready RAG
実際にRAGを用いるにあたっては「検索(Retrieval)の効率化」、「巨大な知識ベースを用いる際の正答率の向上」、「データセキュリティの向上」が課題とされます。
F. Multi-modal RAG
近年、RAGはテキストに限らず、画像・音声・動画・コードなど、Multi-modalに用いられるようになりました。以下、それぞれの研究例です。
Image: RA-CM3、BLIP-2
Audio&Video: Vid2Seq
Code: RBPS