この記事はSpark Advent Calendar 16日目の記事です。
SparkのUser Interface
Sparkに対して通常ジョブを実行する際には以下のような選択肢があると思います。
-
spark-submit: スケジュールされたジョブ、すでに固定化されたproductionのジョブなど -
spark-shell: interactiveに処理を実行させたい場合 -
spark-sql: SQLをinteractiveに書きたい場合 -
pyspark: PythonでSparkのジョブを書きたい場合
これらはすべてSparkのパッケージに同包されていますが、全部CLIです。ブラウザなどからGUIとして使えるツールとしては
などがあります。Jupyterは元々Pythonの分析用GUIツールとして作られたみたいですが、今はSparkもサポートしているようです。Zeppelinは元々Spark上で動くようなツールとして作られたみたいです。
今回はこういったツールの一つとして使えそうなspark-jobserverについて書きたいと思います。
spark-jobserverとは
spark-jobserverはTupleJumpという会社が作っているRESTfulなAPIを通してジョブのsubmitや管理をできるライブラリです。今年のSpark Summit EUで初お目見得したものだと思います。
おそらく社内でのinternalなSpark利用をもっと簡単に管理できるようにするため("Share Spark across the enterprise"とあるので)に元々は作られたのではないかと思いますが、すでにSpark SQLやSpark Streamingも使えるみたいで機能としてはすでに揃っている形でした。AuthenticationやHTTPSはまあ必須という感じかもしれないです。
Launching spark-jobserver
何はともあれ立ち上げてみましょう。spark-jobserverにはすでにSparkが含まれているので改めてSparkをインストールする必要はありません。もちろん独自に立ち上げたクラスタがあったりバージョンを指定して使いたかったりした場合はそちらを向けることもできます。
試すようとしてはdockerのimageが用意されていますのでそちらを使うのがべんりです。
dockerが利用可能な環境であれば以下のコマンドを打つだけでspark-jobserverを立ち上げてくれます。
$ docker run -d -p 8090:8090 \
velvia/spark-jobserver:0.5.2-SNAPSHOT
細かくはここでは省きますが、spark-jobserverのimageをdownloadしてきて8090ポートで立ち上げてくれます。ここにREST APIやUIが立つのでホストマシンの方にexportしています。
http://localhost:8090 にアクセスすると以下のようなUIが見られるはずです。
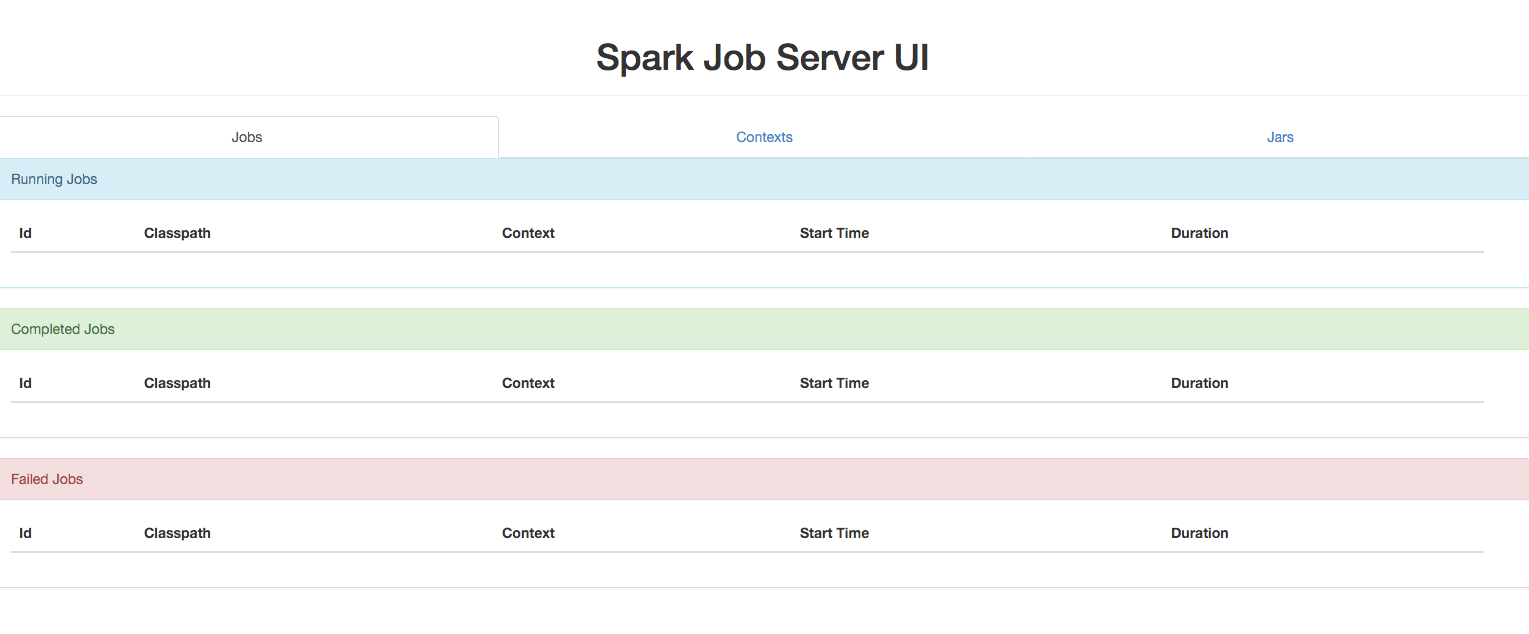
注意:OSX上でdocker-machineを使っている場合はdocker-machineのIPに繋がないと行けないので以下のコマンドで参照してください。
$ open http://$(docker-machine ip your-docker-machine-name):8090
Submit job to spark-jobserver
Hadoop界隈でのHello World, WordCountのジョブを走らせてみようと思います。そのためにはjobのjarをビルドしておく必要があります。test用のパッケージはjob-server-testsというディレクトリ以下にあるので下記のコマンドでビルドができます。
$ sbt job-server-tests/package
job-server-tests/target以下にjarファイルができますのでまずはこれをuploadします。
$ curl --data-binary @job-server-tests/target/scala-2.10/job-server-tests_2.10-0.6.2-SNAPSHOT.jar \
$(docker-machine ip your-docker-machine-name):8090/jars/your-test
OK
このjarがjobserverに正しくuploadされていればOKと返ってきます。UI上のJarsというタグからも確認できます。

ではこのjarに含まれているWordCount用のアプリケーションを動かしてみます。これもREST APIを叩けばいいただけです。とりあえずお試しで叩く場合のためもそうですが、おそらくREST APIでデータも突っ込んで分析した場合も想定していると思いますがjobserverにAPIから入力データを入れることもできます。
$ curl -d "input.string = a b c a b see" \
"$(docker-machine ip your-docker-machine-name):8090/jobs?appName=your-test&classPath=spark.jobserver.WordCountExample"
{
"status": "STARTED",
"result": {
"jobId": "edb6805c-5ce5-406b-a944-8b372fcc6905",
"context": "be8cf199-spark.jobserver.WordCountExample"
}
}
これでjobが動き始めました。結果もこれまたAPIで取得ができます。今回はブラウザからアクセスしてみましょう。URLはhttp://$(docker-machine ip your-docker-machine-name):8090/jobs/edb6805c-5ce5-406b-a944-8b372fcc6905です。jobIdは適宜かえてください。
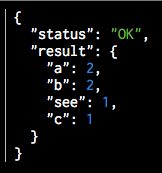
wordがcountできています。
今のでなんとなくわかったかもしれませんが、jobserverのトップページにはJobs, Contexts, Jarsというタブがあると思います。これらの情報が欲しければ基本的に
# Jobのリスト
http://<Job Server IP>:8090/jobs
# Contextのリスト
http://<Job Server IP>:8090/contexts
# Jarのリスト
http://<Job Server IP>:8090/jars
から得られます。そこで得られた識別子idとかnameとかを使って掘っていけば詳細が得られたり、結果が得られたりします。非常にシンプルですが、十分わかりやすくあまり使い方に悩むことはなさそうです。
Persisten Context
Sparkのjobを作成する場合は通常SparkContextというクラスを作る必要があります。spark-jobserverに投げた場合はこのcontextの作成を代わりにjobserverがやってくれます。この場合にはSparkJobというクラスを継承したクラスを作成して以下のメソッドを実装します。
object SampleJob extends SparkJob {
override def runJob(sc:SparkContext, jobConfig: Config): Any = ???
override def validate(sc:SparkContext, config: Config): SparkJobValidation = ???
}
SparkContextにはjobserverが作成してくれたSparkContextが渡ってくるのでそれを使い回すことができます。SparkContextにはDriver, Executorのメモリサイズ、CPUのcore数など設定できるのでjobのメインとなるコードを書き換えることなくチューニングすることができます。
新しくContextを書き換えて保存する場合は下記のようにします。
$ curl -d "" "$(docker-machine ip your-docker-machine-name):8090/contexts/test-context?num-cpu-cores=4&memory-per-node=512m"
このcontextを使いたい場合は下記のようにcontextパラメタを付与してリクエストをします。
curl -d "input.string = a b c a b see" "$(docker-machine ip your-docker-machine name):8090/jobs?appName=your-test&classPath=spark.jobserver.WordCountExample&context=test-context&sync=true"
{
"result": {
"a": 2,
"b": 2,
"c": 1,
"see": 1
}
}⏎
SparkContextはSparkのジョブを実行する上で大事な情報を多く保持している部分なのでこれをpersistできたり、変更できるということはチューニングや設定値の再利用が簡単になるのでこれだけとってもspark-jobserverはinternalなenterprise利用に非常に向いていると思いました。