はじめに
若干釣りっぽいタイトルで恐縮です🙇♂️
画像についてあまり詳しくない現職データエンジニアが、単騎で画像コンペに突っ込んでいき、どのようなプロセスでメダルを獲得するに至ったの?を共有する記事となっております。
画像コンペの進め方がわからない人間がどのようにして進めていったのかを共有することで、これからコンペに参加してみたいな〜と思っている方へのモチベーション向上・後押しになれば良いなと考えております。
細かいアーキテクチャや使った手法、ツールについてはあまり言及できていないと思います!ライトに読んでいただくことを目的としたいので予めご了承くださいまし。
書いている人間のステータスについて
- 現職データエンジニア(BigQueryが友達)
- 統計検定2級を取っているため、数式を見てもアレルギーは出ない
- 仕事で画像をはじめとした非構造データを扱うことは少ない
- 最近文章系はちょっと増えた
- AIについては若干の知識があり、自然言語処理系はなんとなくわかっている(つもり)
- Embeddingの理解はとっかかりなくできたレベル
- 画像処理については、チュートリアルでよくある手書き数字の分類をしたことがあります!程度
- 登竜門に到達した?してない?くらいのレベル
- ちゃんとコンペ参加したことがなかった
- とりあえず他人のコードを真似して1回だけ投稿した実績は多数あり(ドヤ)
- 英語はちょっとだけ読める
- 読んだことがあった画像系AIの本
- ゼロから始めるディープラーニング(1と2)
- PythonとKerasによるディープラーニング
- サーーっと読んだだけで何も覚えてない
- 肝臓が弱すぎて日本酒は飲めません...
どんなコンペに参加したの?結果は?
Nishikaで2023年6月〜2023年9月15日まで開催していた「日本酒銘柄画像検索」というコンペティションに参加しました。
内容としては、日本酒に絞った画像検索です。
例えば、下記の図のように「獺祭」の写真を検索クエリとしての画像としたときに、日本酒のデータベースから「獺祭」の写真を引っ張ってくる、みたいなタスクを行えるようなモデルの開発をするのが目的で、引っ張ってきた画像がちゃんと獺祭の写真撮ってこれてるの?や「獺祭」以外の画像はちゃんと弾いてる?という観点から評価が行われ、モデルの優劣をつけるコンペティションになっています。
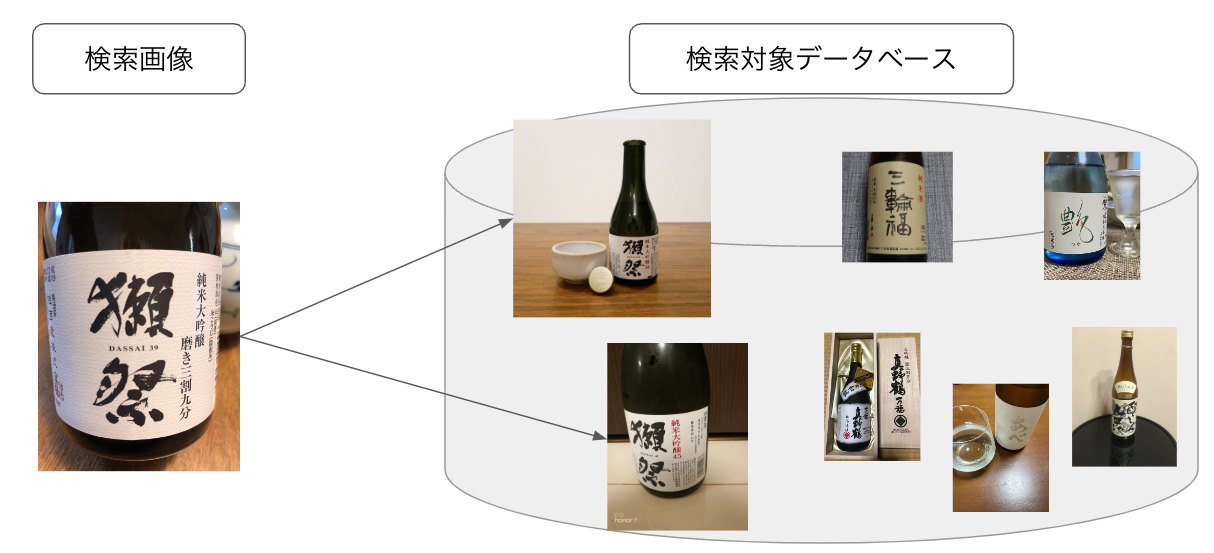
評価指標にはMean Reciprocal Rank@20というもので評価されています。
なんぞ?って感じですが、『引っ張ってきた画像がちゃんと獺祭の写真撮ってこれてるの?「獺祭」以外の画像はちゃんと弾いてる?』の観点から評価が行える指標で、検索をする上で自分が目的としている対象が上位に来ることはどの検索エンジンでも望まれることで、それを反映でき、定量的に評価できるようなものになっています。(実は評価指標について途中で運営側のミスが発覚し修正されていますが、後述します。)
結果としてはタイトルの通り、銀メダルを取得でき、順位としては12位/120人中で上位10%には入れているという結果でした。
後述しますが、個人的には「もーちょっと頑張れたのでは?」と思っている結果でもあります。

取り組んだ流れ
コンペ開始直後(6月)
このタイミングでは「また面白そうだけどむずそうなコンペ始まったなぁ...とりあえず参加だけしとくか」と考え、参加ボタンを押しました。
運営から提供されているサンプルコードをGoogle Colabに丸ごとコピペし、実行して投稿。
「何もわからん」の感想だけが残り、Switchを手に取りゼルダをプレイし始めた覚えがあります...
7月上旬
参加者の方が有志でベースラインを投稿してくださったのをみて、また丸コピして実行しました。
画像系のコードの書き方に慣れていない部分が大半で、「DataLoaderって結局なんぞ?」「albumentationsって初めて聞いたぞおい...」「学習率にスケジュールかけるなんてあるんか」など新しい発見と自分の未熟さを痛感しながら一行づつわからないなりに丁寧に読み進めました。
この時からChatGPTなどを使ってコードの解説を行わせながら知識を深めていきました。
読み終わった際に「何だかいけそうな気がする」というどこから来たかもわからない自信を元手にやる気を出してここから進めていくことと相成りました。
7月中旬
7月初旬に参考にした他の方のベースラインを改修していく形で、自分自身のベースラインを作成する形にしました。
いつ「後で読む」フォルダに突っ込んだか覚えてもいないPytorchでpretrainモデルを用いた画像向けSiameseNetworkのメモという記事がどうやら使えそうということがわかり、早速組んでみてワクワクしていたところ惨敗。後から分かったことで問題設定とあってなかったというわけですが、その当時はそれすらわからず、「できんから不採用」という形で、他の角度系アルゴリズムを用いて進めました。
よくわかる角度系深層距離学習~前編がとてもわかりやすくここから急速に理解が進み始めました。
またこの時期は同時並行して過去の似たようなコンペで上位解法を物色し始めていました。
主に参考になったのはNishikaの過去コンペのAI×商標:イメージサーチコンペティション(類似商標画像の検出)の1位解法です。
PCAについてはほぼ丸パクリしてるくらいです。
8月上旬
QiitaやZennを読み漁りながら何とか自分自身のベースラインを提出。ロスの下がり具合がかなり良かったので期待しながら提出するとスコアは手元のものと比べ、約2分の1程度でした。普通手元のスコアと投稿後のスコア(LB)がここまで乖離することはほとんどないイメージだったため、原因も追及せずに「おお...センスないな俺...」とかなりショックを受けてここで一度やめてしまいました。
ゲームと同じで、自分が考えた攻略方法がまるで太刀打ちできなくクソゲー認定してしまった時と同じような感情をここで抱きました。

8月中旬
この時期は順位を上げるというより、単純な知的好奇心が芽生え、「角度系のアーキテクチャってもっと具体的にどういう仕組みで動いてるんやろか?」を明瞭にしたくお勉強の期間として頑張っていました。
実際に学んだ内容が日本語で解説されている記事がほぼないことに気づいて、備忘録としてCosFace・ArcFaceとElasticFaceへの拡張という形で記事に残したりしていました。
以前からChatGPTを活用しながらコード生成させたり、エラーを解析させたりしていましたが、論文を要約させたり、中身について質問するという使い方をするようになり始めました。
これがかなり有効でわからないところは「猿でもわかるように説明しろ!」と命令して、中学生が理解できるレベルまで噛み砕いて説明させていました。
また自分の理解が正しいかどうかも聞けるのが「すげぇなぁOpenAI」と感心しながら利用していました。

8月下旬
この時期に事件が起きました。
運営側で投稿時に使っていた評価指標が実は間違えていたということが参加者の提言から発覚し、評価指標の見直し、正しい評価指標を使ったランキングのし直しが実施され、まさかの上位に躍り出てしまいます。

実は自分がやっていたことが間違いではなく、地味にスコアを上げる行動だった!ということがこの時にわかり、再度やる気が出てきて色々やり始めます。
またこの時期にいろんなアーキテクチャの実験があらかた完了したフェーズだったので、さらに大きなモデルの構築に進むためにGoogle ColabをPro+にして気合いを入れながら学習を進めていました。
外にいる間も寝る直前もwandbという学習経過を見れるサービスを使って「今どんな感じかなぁ」と観察しながら楽しんでいました。
↓なんかそれっぽいダッシュボード

9月
この時期は学習などはあらかた終了し、「後処理」と呼ばれる検索の精度を既存のモデルを使って細かく調整していくフェーズに入りました。
Google Landmark Retrieval(Kaggleの画像検索系の大きなコンペ。解法のお手本になることが多いです。)をはじめとする過去の画像コンペの上位解法を真似したり、改変しながら効きそうな手法を色々試していました。
が、かなり頭打ちの状態だったので何しても精度が良くならずに悶々としながら作業を進めていました。最終的には諦めてしまい(ここがダメ)、お祈りで「ShakeUpしないかなぁ....」と祈りながら最終週を過ごしていました。

コンペ終了(9月15日)
細かい解法についてはコンペのトピックで共有しているため割愛しますが、最終的に2モデルのアンサンブルで12位でした。お祈りShakeUpは叶わず、むしろShakeDownしてしまう始末に...
12位解法
反省点
色々ありすぎて全部は上げられません!が、いくつかピックアップしてみます。
データを見なさすぎた
AIコンペを進める上で壊滅的なことですが、検索対象・検索用画像、トレーニング画像を1%程度しか見ずにコンペを進めていました。
他の上位者の解法を見ると、「ラベルづけの間違いがあった」「複数の銘柄が写っている写真があった」など、精度にクリティカルに影響しそうな内容に言及されている方がいらっしゃって、「やっちまった」とその場でもう猛省しました。
AIコンペ全体に言えることだと思いますが、「人間が単純に理解しやすいことはAIにも理解しやすい」と考えております。というのも、人間にとって判断が難しいことってAIにとっても難しいことが多いです。例えばラベル付が間違えている場合、「え、この写真って〇〇って名前の銘柄じゃないん...?」となるようにAIも同じです。
なのでデータをしっかり見た上で、データのクレンジングやモデル作成の方針決めを行うのは、よく言われていることだけどなぜよく言われているのかが今回で身をもって経験できたと思います。
なので、データは絶対にみましょう!
検証の多様化がなかった
最初に他の方のベースラインを見て進めていった、と前述しましたが、他の方の解法を見ると物体検出系のモデルを使って、瓶を大きくするように加工していたり、複数の瓶がある場合はそもそもトレーニング画像からは削除する、のような工夫をされている方がいらっしゃいました。これも「データを見ろ!」に通ずるところですが、考えてみればノイズになりそうだなぁというのは直感的にわかりますよね。
私も「抜本的に効果的な前処理とか必要だよなぁ〜」と思いつつも目の前の学習の精度を上げることにしか興味がなくなっていた時期がありました。
なので、いろんな観点から検証をしてみましょう!失敗は成功の元です!
検証のサイクルが遅すぎた
特に使用するモデルのbackbone(EfficientNetやSwin Transformer, ResNetなど)の検証でより良いものを選んだ方がいいよなと考えていましたが、それを検証するのに全てFoldに分けてループ実行する、のような無駄時間を使って全て検証をしていました。
よくよく考えれば最初は適当にtrain, validに分けて数epochやればいいものの、5Fold30epochを全部やって「あ、ダメやん」という判断を繰り返すことを10回程度やっていました。
時間の無駄でしたし、Google Colabのクレジットを大量に消費するだけの行為でしかなかったです。
なので、検証はステップに分けて細かくやろう!見切りをつけるのは早めに!
やって良かったこと
ChatGPTの活用
もはやこれの恩恵でしかないと思っていますが、今回のコンペではフル活用しました。前述した通り、コードの生成、エラーの解析、論文の要約など、専門的なことでわからないことはとりあえずChatGPTさんに聞いてました。
記事の公開
1つしか公開していないですが、細かいアーキテクチャの内容を理解するのに記事を公開することを目標にするのはいいことだなと痛感しました。やはりアウトプット最強説は間違いないと思います!
コンペに参加しきったこと
なんだかんだこれが大きいかなと思います。私自身も参加ボタンだけ押して1subするかしないかみたいなコンペは10じゃきかないです。ですが、参加し続けてみていろんな知見を得て最終的にメダルを取れたことは自分にとっての自信にもなりますし、今後のコンペ参加へのハードルを大きく下げてくれる要因にもなるなと思いました。
論文読み込むなんて大学以来することないと思っていたことも「楽しく感じられるようになるんだ...」と成長にもつながったと思います。
データエンジニアのキャリアとしての影響
そんなにないかな?とも思いますが、昨今のLLMの台頭によって「とりあえずAI!」みたいな風潮は少なからず増えてきた中で、実際にAI開発するならどんなプロセスを踏むの?という部分で具体的な内容を経験として得られたことは、顧客と話す中で「なんとな〜くぼやっと話す」からある程度説得力を持たせるための材料になったと思います。
なので、「自分はAIエンジニアじゃないから...」「AIなんか難しそうだし...」とならずに、どんな職種の方でもとりあえず参加してみるのはとてもいいことじゃないかなと思っています!
もしかしたら共感してくださる方がいるかもですが、特にAIコンペは作業興奮めっちゃあるように感じます笑
おわりに
画像コンペにソロで初参加したデータエンジニアがもがいていた体験談をつらつらを共有させていただきました!
正直しんどいなぁ〜〜と思う時期もありましたが、結果的には成績も残せて良い経験に繋げられたので、やり続けることが結局大事なんだなと感じました。
Nishikaはトピックでの意見交換がそこまで盛んではないため、あまり初心者には優しくない環境かもしれませんでしたが、逆に自分で考えることが増やせるな!とプラスに捉えていたので、あまり問題ではなかったように思います。
今後は他の方の解法の実施や、Kaggleへの参加、チームでの参加もしてみたいなと考えています。