はじめに
大量のパワーポイントファイルからテキスト抽出を行う必要があり、当初はpython-pptxを使う予定でしたが、ファイルがパワーポイント2003までのもの(拡張子ppt)だったため断念しました。 そこでJavaの外部ライブラリのApache POIを使いテキスト抽出を行うことにします。Apache POIとは
 Apache POIとは、Microsoft Office形式のファイルを読み書きできる100% Javaライブラリです。 この記事で扱うパワーポイントだけでなくエクセルやワードの操作も行えます。Apache POIのダウンロード
Apache POIのダウンロードはこちらから行なってください。プログラム
以下のpptファイルの1ページ目のスライドのテキストを取得します。 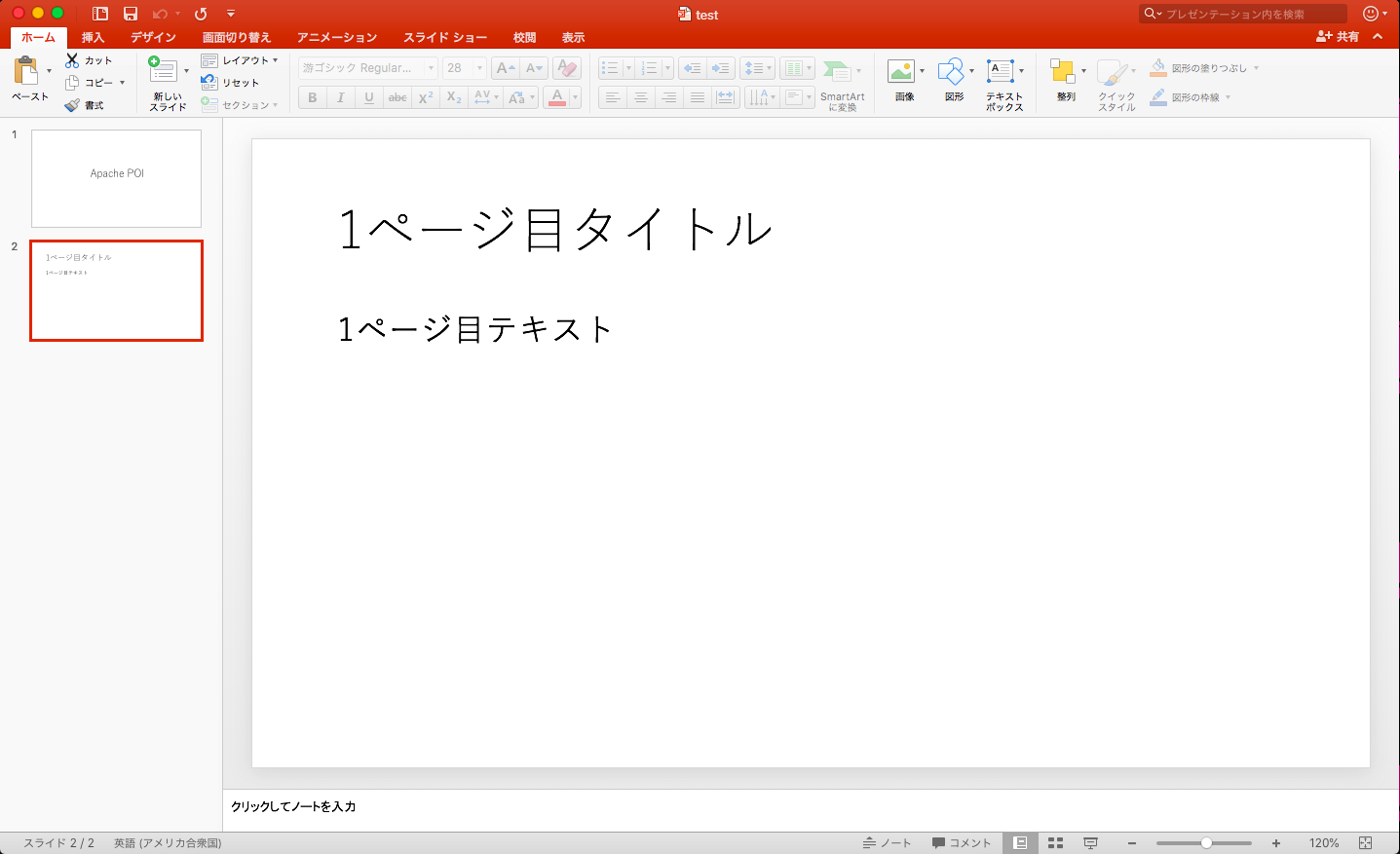以下のプログラムで動かします
PPT2txt.java
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.List;
import org.apache.poi.hslf.usermodel.HSLFSlide;
import org.apache.poi.hslf.usermodel.HSLFSlideShow;
import org.apache.poi.util.IOUtils;
public class PPT2txt {
public static void main(String[] args) throws IOException {
File file = new File("./data/test.ppt");
FileInputStream inputStream = new FileInputStream(file);
// 読み込むファイルのサイズが大きい場合は最大値を増やす
// IOUtils.setByteArrayMaxOverride(10000000);
HSLFSlideShow ppt = new HSLFSlideShow(inputStream);
// プレゼンテーション内のすべてのスライドの配列を取得
List<HSLFSlide> slides = ppt.getSlides();
int page = 1;
int paragraph = 1;
System.out.println(slides.get(page).getTextParagraphs().get(paragraph));
ppt.close();
}
}
結果
プログラムを実行すると1ページ目のテキストが取得できます。[1ページ目テキスト]
おわりに
この記事ではパワーポイント2003までのもの(拡張子ppt)のテキスト抽出の方法を紹介しましたが、もちろんパワーポイント2007以降のファイル形式(拡張子pptx)でも可能です。 その際は、org.apache.poi.hslfではなくorg.apache.poi.xslfを使用します。 また、テキスト抽出だけでなく画像取得やスライド作成などの行えますので、その場合はドキュメント見て頑張りましょう。最後までお読み頂きありがとうございました。