KubernetesのVPA1のREADMEでは、現在CPU/memoryによるHPAとVPAの併用を禁止している。これを回避するカスタムメトリクスの導入などをしていしたが、HPA/VPAの干渉理由を求められたときにパッと明確な説明ができなかったので書き起こしておく。
Vertical Pod Autoscaler should not be used with the Horizontal Pod Autoscaler (HPA) on CPU or memory at this moment. However, you can use VPA with HPA on custom and external metrics.
HPAはPodのResourceRequestを用いてスケール値をどう算出しているのか?
VPAのWebhookは、PodのResource Request(.spec.template.spec.containers[].resource.requests)をCPUとメモリの消費量に合わせて動的に書き換える。つまりVPAの有無による違いは、このResource Requestが可変だということだ。では、可変なResource RequestはHPAにどのような影響を与えるのだろうか?
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
HPAのスケール値の算出方法は1のように、現在のレプリカ数に実測値と期待値の比を掛けたものだ。 () の部分の実装は指定するメトリクスオプションによって実装は異なるが、PodのResource Requestを利用するのはmetrics.typeが Resource かつtarget.typeが Utilization の場合のみだ。では、実際に()の部分を求めるコードを見てみる2
for podName, metric := range metrics {
request, hasRequest := requests[podName]
if !hasRequest {
// we check for missing requests elsewhere, so assuming missing requests == extraneous metrics
continue
}
metricsTotal += metric.Value
requestsTotal += request
numEntries++
}
currentUtilization = int32((metricsTotal * 100) / requestsTotal)
return float64(currentUtilization) / float64(targetUtilization), currentUtilization, metricsTotal / int64(numEntries), nil
このコードから、ResourceUtilizationRatioは、実測値の合計とリクエスト値の合計値の比を指定したターゲットで割ったものということが分かった。この値に現在のレプリカ数を掛けたものがスケール値となるが、コントローラが削除/追加するレプリカのResource Requestがこの平均値から外れていると期待した状態にならない。
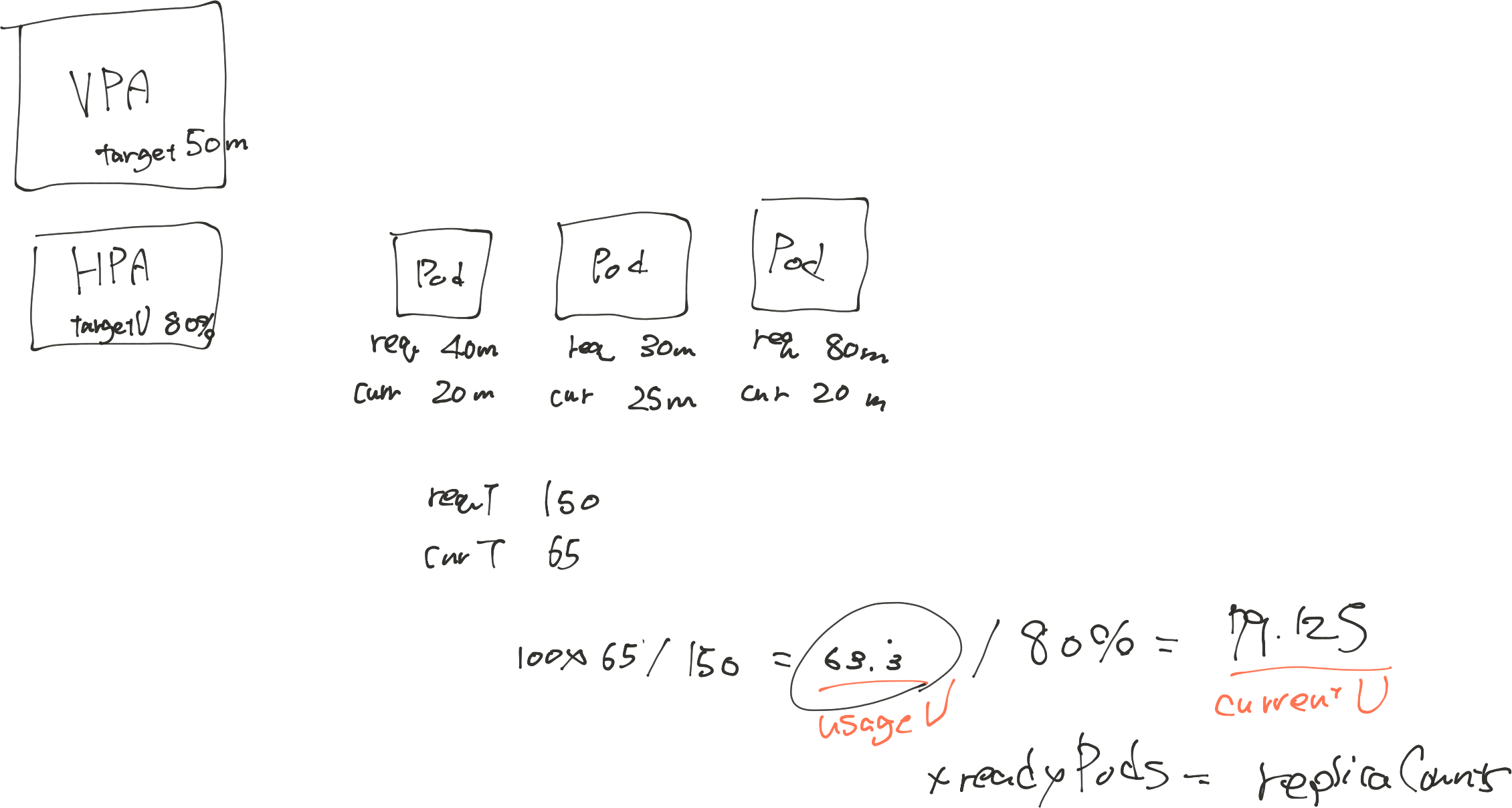
具体例を考えてみる。VPAのPodのResource Requestの更新方法もいくつかあるが、Creation方式にするとdesiredMetricvalueがPodによって変わってしまう。それ以外の場合でも、現在の値と次に作成される値が変わるので、予期するリソースを確保できない(or 確保しすぎる)パターンがある。
結論
CPU/memoryのUtilizationによるHPAでは、メトリクス実装値とResource Requestの割合からスケール値を計算してPodの追加や削除を行う。しかし、VPAによってスケール対象のDeployement(をOwnerに持つ)PodのResource Request値が変動すると、外れ値を持ったPodが操作されたときなどに予期したリソース量が確保できない。そのため、現在では併用を禁止しているのだと思う。
つまり、カスタムメトリクスなどを使っていたとしても、CPU/memoryをメトリクスとして同じように計算していると同じ問題を引く。なのでアプリケーションのタイプにもよるが、基本に則ってCPU/memoryでVPAしてRPSやp95latencyでHPAをやっている。