使用書籍
Python実践データ分析100本ノックの最適化問題をRで解きます。
データ加工や機械学習のセクションはtidyverseや各種libraryを用いて比較的容易にRで代替できると感じたのですが、最適化問題にはネットワークグラフの描写や数理最適化においてR特有の方法を知らないとできないなと感じたので勉強がてらやってみました。
今回は第3部第6章「物流最適ルートをコンサルティングする10本ノック」です。
使用データは手元にあると仮定するので適切な経路で入手お願いいたします。
ノック51「データ読み込み」
library(tidyverse) #お好みで
library(igraph)
factory <- read_csv("tbl_factory.csv")
warehouses <- read_csv("tbl_warehouse.csv")
cost <- read_csv("rel_cost.csv")
trans <- read_csv("tbl_transaction.csv")
4つのデータを結合していきます。データによって結合カラム名が異なるので気を付けます。
join_data <- left_join(trans, cost, by = c("ToFC" = "FCID", "FromWH" = "WHID"))
join_data <- left_join(join_data, factory, by = c("ToFC" = "FCID"))
join_data <- left_join(join_data, warehouses, by = c("FromWH" = "WHID"))
join_data <- join_data[,c("TransactionDate","Quantity","Cost","ToFC","FCName","FCDemand",
"FromWH","WHName","WHSupply","WHRegion")]
> head(join_data)
# A tibble: 6 x 10
TransactionDate Quantity Cost ToFC FCName FCDemand FromWH WHName WHSupply WHRegion
<dttm> <dbl> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr>
1 2019-01-01 02:11:10 33 1.1 FC00004 横須賀工場 25 WH00003 豊洲倉庫 42 関東
2 2019-01-01 06:12:42 19 1.3 FC00007 那須工場 25 WH00006 山形倉庫 65 東北
3 2019-01-01 06:32:32 31 0.9 FC00006 山形工場 30 WH00004 郡山倉庫 60 東北
4 2019-01-01 07:17:06 18 1.6 FC00002 木更津工場 29 WH00003 豊洲倉庫 42 関東
5 2019-01-01 07:52:18 30 0.8 FC00001 東京工場 28 WH00002 品川倉庫 41 関東
6 2019-01-01 08:56:09 31 0.3 FC00005 仙台工場 21 WH00005 仙台倉庫 72 東北
関東支社と東北支社のデータ確認です。
kanto <- join_data[join_data$WHRegion=="関東",]
> head(kanto)
# A tibble: 6 x 10
TransactionDate Quantity Cost ToFC FCName FCDemand FromWH WHName WHSupply WHRegion
<dttm> <dbl> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr>
1 2019-01-01 02:11:10 33 1.1 FC00004 横須賀工場 25 WH00003 豊洲倉庫 42 関東
2 2019-01-01 07:17:06 18 1.6 FC00002 木更津工場 29 WH00003 豊洲倉庫 42 関東
3 2019-01-01 07:52:18 30 0.8 FC00001 東京工場 28 WH00002 品川倉庫 41 関東
4 2019-01-01 09:09:30 12 1.5 FC00001 東京工場 28 WH00003 豊洲倉庫 42 関東
5 2019-01-01 10:52:55 27 1.5 FC00003 多摩工場 31 WH00003 豊洲倉庫 42 関東
6 2019-01-01 19:16:11 21 1.3 FC00003 多摩工場 31 WH00002 品川倉庫 41 関東
tohoku <- join_data[join_data$WHRegion=="東北",]
head(tohoku)
> head(tohoku)
# A tibble: 6 x 10
TransactionDate Quantity Cost ToFC FCName FCDemand FromWH WHName WHSupply WHRegion
<dttm> <dbl> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr>
1 2019-01-01 06:12:42 19 1.3 FC00007 那須工場 25 WH00006 山形倉庫 65 東北
2 2019-01-01 06:32:32 31 0.9 FC00006 山形工場 30 WH00004 郡山倉庫 60 東北
3 2019-01-01 08:56:09 31 0.3 FC00005 仙台工場 21 WH00005 仙台倉庫 72 東北
4 2019-01-01 09:00:15 33 0.7 FC00006 山形工場 30 WH00006 山形倉庫 65 東北
5 2019-01-01 14:12:51 21 0.7 FC00006 山形工場 30 WH00006 山形倉庫 65 東北
6 2019-01-01 17:14:43 36 0.7 FC00006 山形工場 30 WH00006 山形倉庫 65 東北
ノック52「現状の輸送量、コスト確認」
各種カラムの集計のため、割愛します。
ノック53「ネットワークを可視化してみよう」
PythonではNetworkXを使っていますが、今回は先ほど読み込んだigraphを使います。
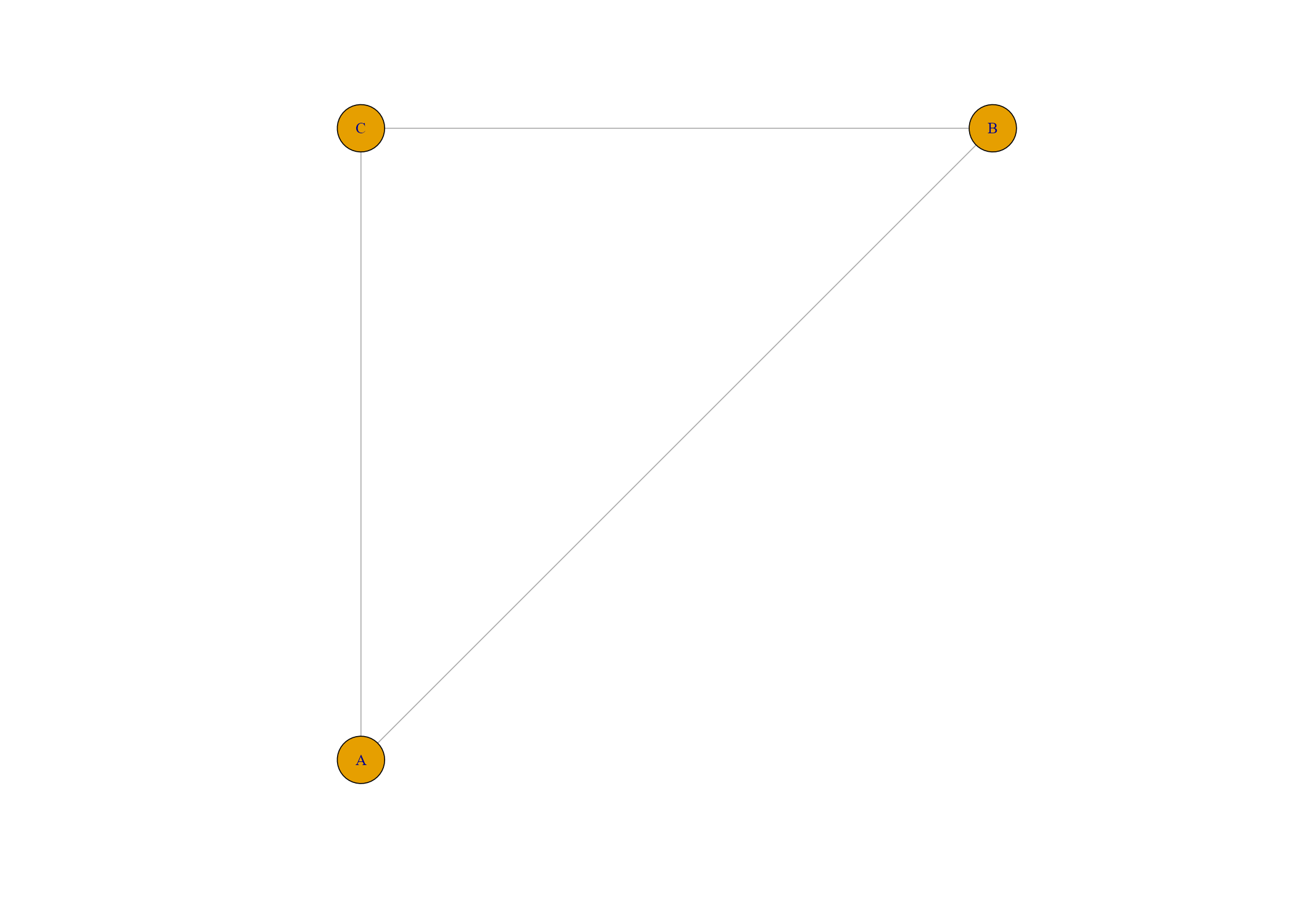
座標付きの3つのノードを結ぶネットワークグラフを作ります。
#各ノードの座標を設定
nodeA <- c(0,0)
nodeB <- c(1,1)
nodeC <- c(0,1)
#matrix形式でノードと座標を格納
pos <- rbind(nodeA, nodeB, nodeC)
# [,1] [,2]
# nodeA 0 0
# nodeB 1 1
# nodeC 0 1
#グラフ描写。結合ノード、label文字を付与。
G <- make_empty_graph(n = 3, directed=FALSE) %>%
add_edges(c(1,2, 2,3, 3,1)) %>%
set_vertex_attr("label", value = c("A","B","C"))
plot(G, layout = pos)
make_empty_graph(n = 3, directed=F)でノード数、ラインの有向無向を指定します(今回は無向なのでFALSE)
add_edges(c(1,2, 2,3, 3,1))で結ぶノードを指定します。この場合は1 -> nodeA, 2 -> nodeB, 3 -> nodeCと対応しています。
set_vertex_attr("label", value = c("A","B","C"))でグラフ上のノード文字を指定します。
ノック54「ネットワークにノードを追加してみよう」
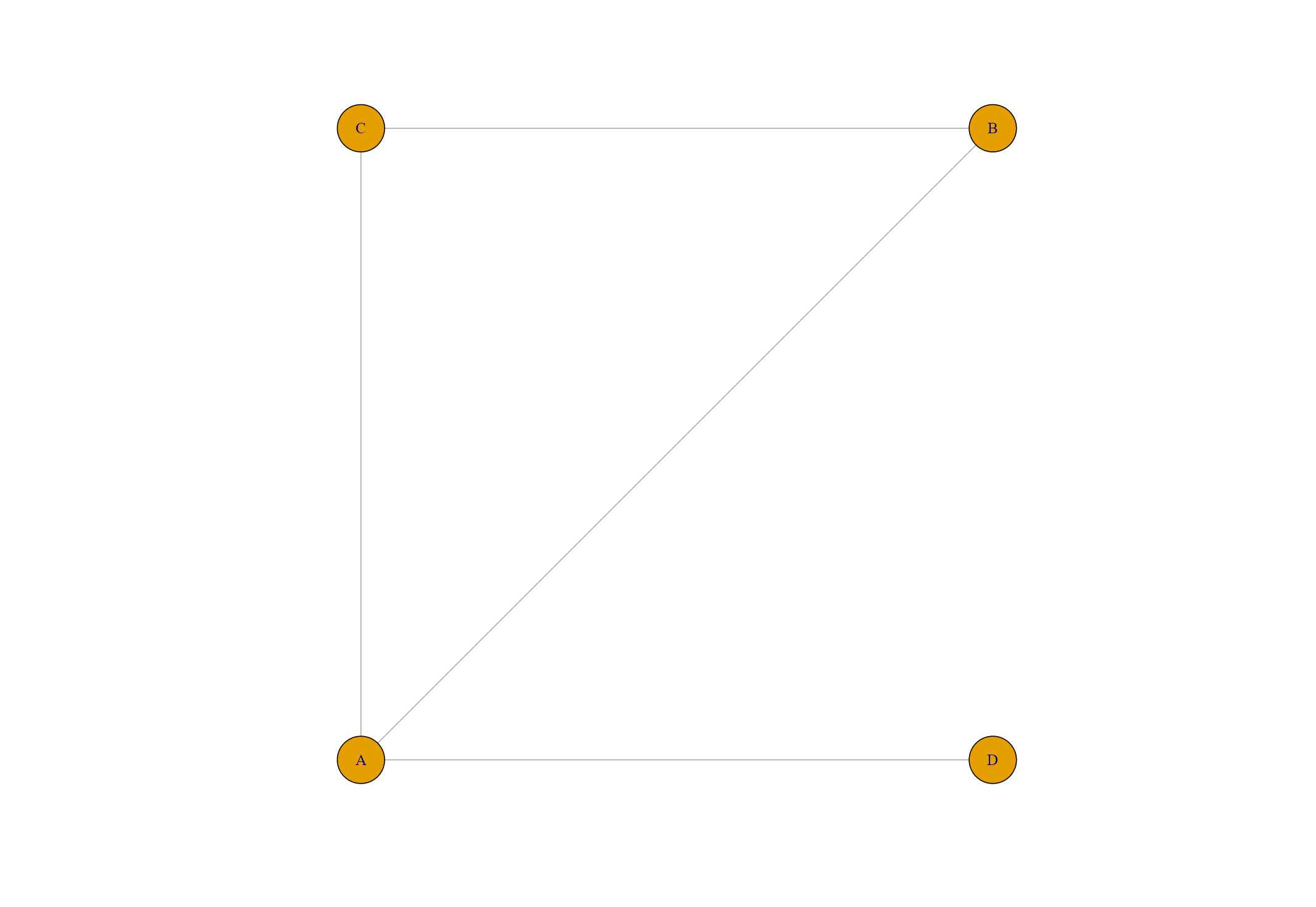
上のグラフにnodeD(1,0)を追加します。
nodeD <- c(1,0)
G2 <- add_vertices(G, 1, label = "D") %>%
add_edges(c(1,4))
pos2 <- rbind(pos, nodeD)
plot(G2, layout = pos2)
先ほどのグラフGに新しいノードを一つ、ラベル名をDとして付与します。
今回はAとDだけをadd_edgesでつなぎます。
座標matrixもnodeDの情報を最下行に追加して更新しましょう。
ノック55「ルートの重みづけをしよう」
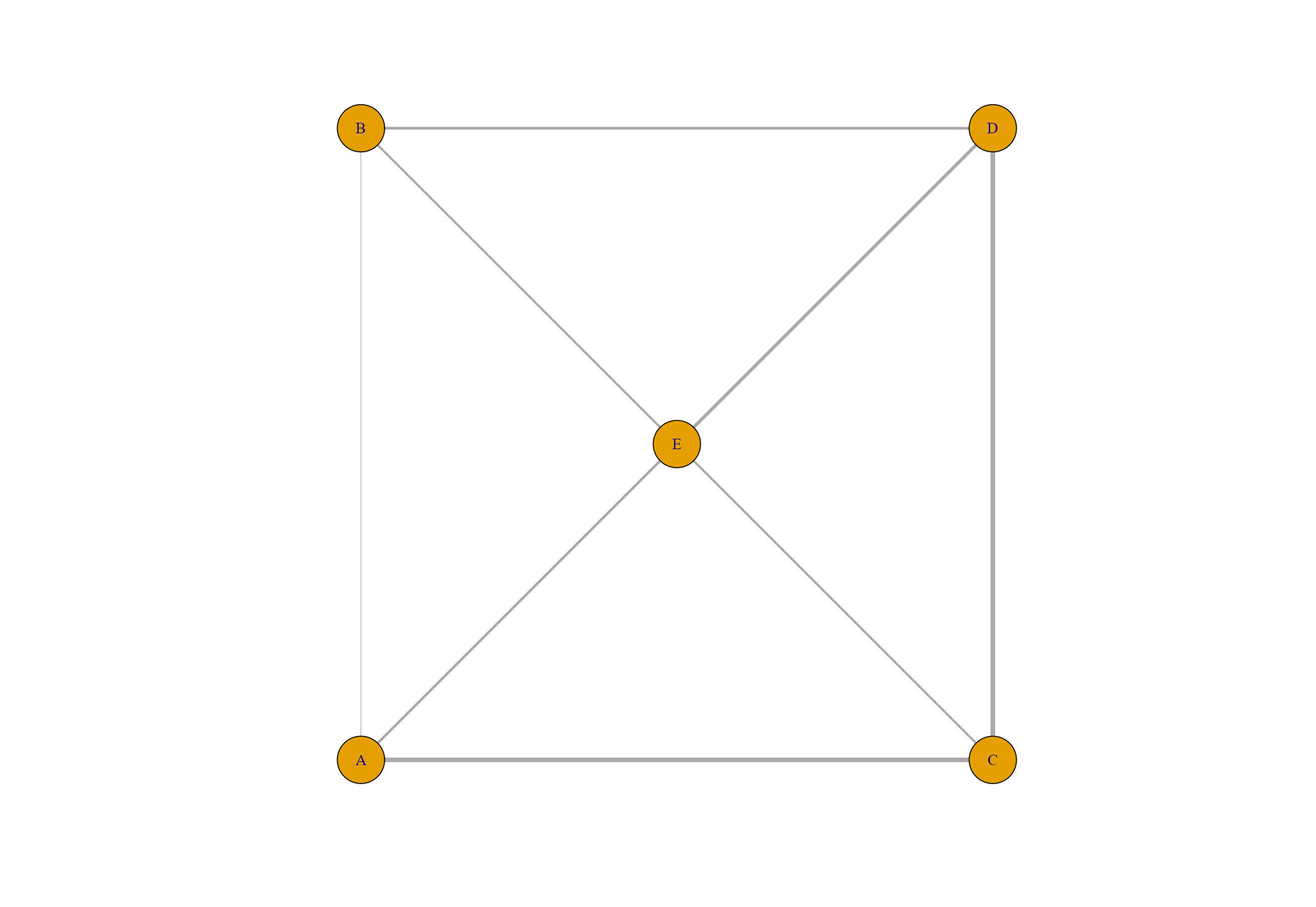
5つのノードについて、各ノード間の重み情報と位置情報を読み込みます。
df_w <- read_csv("network_weight.csv")
# A tibble: 5 x 5
A B C D E
<dbl> <dbl> <dbl> <dbl> <dbl>
1 0.640 0.143 0.945 0.522 0
2 0.265 0 0.456 0.568 0
3 0.618 0.612 0.617 0.944 0
4 0 0 0.698 0.0602 0.667
5 0.671 0.210 0 0.315 0
df_p <- read_csv("network_pos.csv")
# A tibble: 2 x 5
A B C D E
<dbl> <dbl> <dbl> <dbl> <dbl>
1 0 0 2 2 1
2 0 2 0 2 1
重みの設定、辺の設定、位置情報の整理、グラフ作成の順で行います。
#辺の重み設定
size <- 5 #見やすい値で調整可能
edge_weight <- c()
for(i in 1:nrow(df_w)){
for (j in 1:ncol(df_w)) {
if(i < j){
edge_weight <- append(edge_weight, as.numeric(df_w[i,j]*size)) #重みを可視化しやすいように調整
}
}
}
node <- names(df_p) #node名格納
edge <- c()
for(i in 1:ncol(df_p)){
for(j in 1:ncol(df_p)){
if(i < j){
edge <- append(edge, c(i, j)) #node間組み合わせを格納
}
}
}
pos <- t(df_p) #座標matrix作成
[,1] [,2]
A 0 0
B 0 2
C 2 0
D 2 2
E 1 1
Gx <- make_empty_graph(n = length(node), directed=F) %>%
add_edges(edge) %>%
set_vertex_attr("label", value = node) %>%
set_edge_attr("width", value = edge_weight) #重み追加
plot(Gx, layout = pos)
set_edge_attr("width", value = edge_weight)で重みを辺の太さ"width"として属性を追加しました。
ノック56「輸送ルート情報を読み込んでみよう」
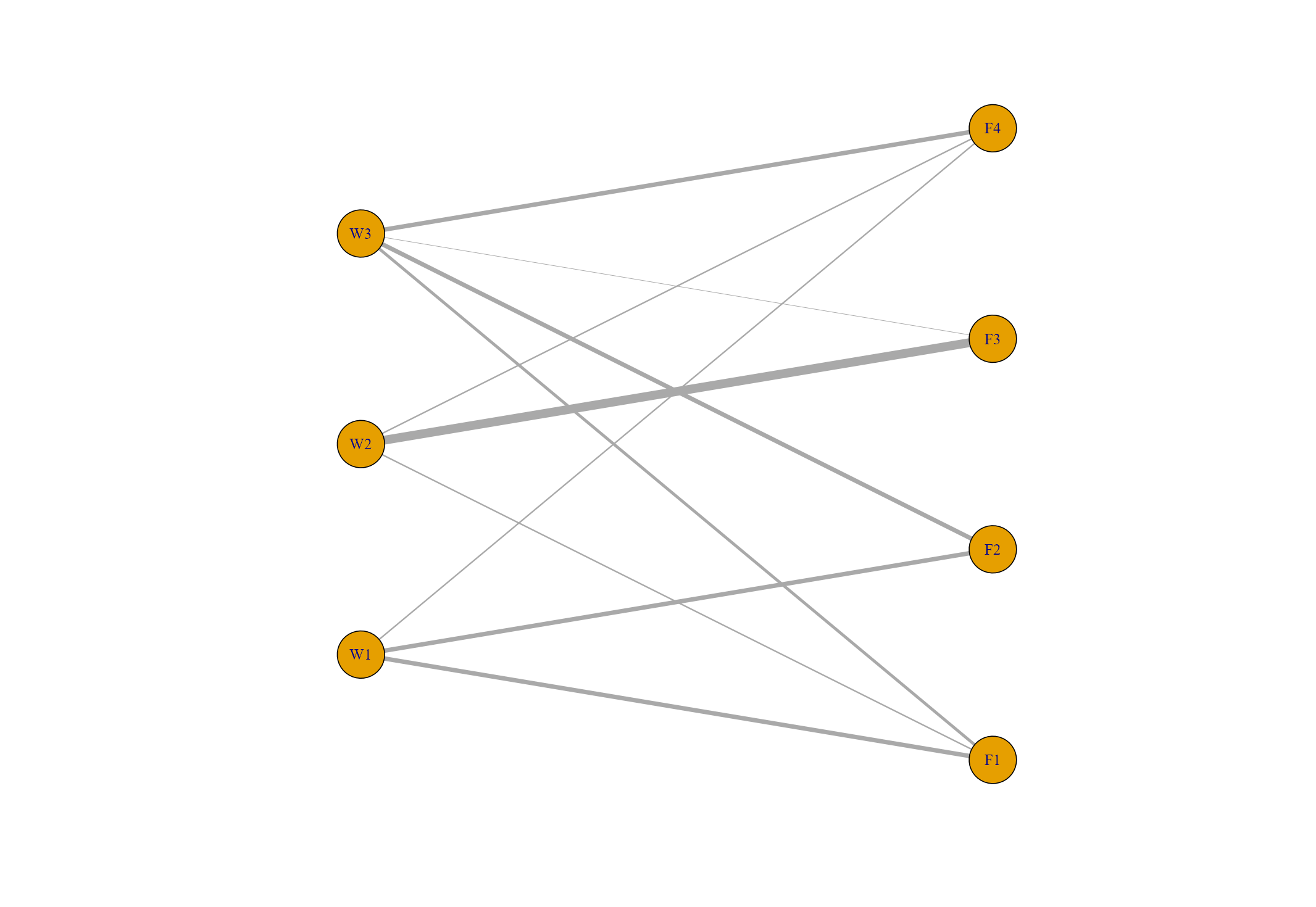
df_tr <- data.frame(read_csv("trans_route.csv"))
rownames(df_tr) <- df_tr$工場
df_tr <- df_tr[,-1] #扱いやすいように工場名の列を削除してindex名とします。
F1 F2 F3 F4
W1 15 15 0 5
W2 5 0 30 5
W3 10 15 2 15
ノック57「輸送ルート情報からネットワークを可視化してみよう」
読み込んだdf_trの倉庫・工場間の物流量をネットワークで可視化します。
使っている関数はノック55とすべて同じです。
df_pos <- read_csv("trans_route_pos.csv") #座標情報
# A tibble: 2 x 7
W1 W2 W3 F1 F2 F3 F4
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0 0 0 4 4 4 4
2 1 2 3 0.5 1.5 2.5 3.5
node <- names(df_pos)
pos <- t(df_pos)
edge <- c()
for(i in 1:nrow(df_tr)){
for(j in 1:ncol(df_tr)){
edge <- append(edge, c(i, j + nrow(df_tr)))
}
}
size <- .1 #見やすい値で調整
edge_weight <- c()
for(i in 1:nrow(df_tr)){
for(j in 1:ncol(df_tr)){
edge_weight <- append(edge_weight, as.numeric(df_tr[i,j]*size))
}
}
Gx <- make_empty_graph(n = length(node), directed=F) %>%
add_edges(edge) %>%
set_vertex_attr("label", value = node) %>%
set_edge_attr("width", value = edge_weight)
plot(Gx, layout = pos)
ノック58「輸送コスト関数を作成しよう」
#データ読み込み
df_tr <- data.frame(read_csv("trans_route.csv")) #輸送ルート情報
rownames(df_tr) <- df_tr$工場
df_tr <- df_tr[,-1]
df_tc <- data.frame(read_csv("trans_cost.csv")) #輸送コスト情報
rownames(df_tc) <- df_tc$工場
df_tc <- df_tc[,-1]
#輸送コスト関数
trans_cost <- function(df_tr, df_tc){
cost = 0
for(i in 1:nrow(df_tc)){
for(j in 1:ncol(df_tr)){
cost <- cost + df_tr[i,j] * df_tc[i,j]
}
}
return(cost)
}
#輸送コスト
trans_cost_1 <- trans_cost(df_tr, df_tc)
[1] 1493 #総輸送コスト1493万円
データ読み込み後の加工はコスト関数を作る時に扱いやすくするためです。
コスト関数では輸送ルートの輸送量とコストを立仕上げて総輸送コストを算出します。
この関数は後でまた使用します。
ノック59「制約条件を作ってみよう」
ノック58の結果「総輸送コスト1493万円」を削減するために最適化します。
需要、供給の各値が格納されたデータを使って制約条件を設定・確認します。
df_demand <- read_csv("demand.csv")
df_supply <- read_csv("supply.csv")
#需要側の制約
for(i in 1:ncol(df_demand)){
temp_sum <- sum(df_tr[,i])
if(temp_sum>=df_demand[1,i]){
print("OK")
}else{
print("需要を満たしていません")
}
}
[1] "OK"
[1] "OK"
[1] "OK"
[1] "OK"
#供給側の制約
for(i in 1:ncol(df_supply)){
temp_sum <- sum(df_tr[,i])
if(temp_sum<=df_supply[1,i]){
print("OK")
}else{
print("供給限界を超えています")
}
}
[1] "OK"
[1] "OK"
[1] "OK"
現状は制約条件を満たしているようです。
輸送ルートを変更しても同様に確認ができます。
ノック60「輸送ルートを変更して、輸送コスト関数の変化を確認しよう」
変更ルートが制約条件を満たすかどうか、どの程度コスト改善できるのかをこれまで作成した関数を使ってシミュレーションします。
df_tr_new <- data.frame(read_csv("trans_route_new.csv")) #新ルート
rownames(df_tr_new) <- df_tr_new$工場;
df_tr_new <- df_tr_new[,-1]
trans_cost_new <-trans_cost(df_tr_new, df_tc) #コスト計算
[1] 1428
#制約条件計算関数:需要
condition_demand <- function(df_tr, df_demand){
flag <- rep(0,ncol(df_demand))
for(i in 1:ncol(df_demand)){
temp_sum <- sum(df_tr[,i])
if(temp_sum>=df_demand[1,i]){
flag[i] <- 1
}
}
return(flag) #制約条件を満たすとフラグ1を付与
}
#制約条件計算関数:供給
condition_supply <- function(df_tr, df_supply){
flag <- rep(0,ncol(df_supply))
for(i in 1:ncol(df_supply)){
temp_sum <- sum(df_tr[i,])
if(temp_sum<=df_supply[1,i]){
flag[i] <- 1
}
}
return(flag) #制約条件を満たすとフラグ1を付与
}
res_demand <- condition_demand(df_tr_new, df_demand) #需要制約結果
[1] 1 1 1 1
res_supply <- condition_supply(df_tr_new, df_supply) #供給制約結果
[1] 1 0 1
輸送コストはノック58の1493万円から1428万円まで削減できましたが、供給側二番目の条件を満たせませんでした。
次は第7章「ロジスティックネットワーク最適設計」をRでやります。