はじめに
今回使うのがAzureMLのデザイナーという機能になります。
デザイナーはブロックをドラッグアンドドロップすることで、MLの処理を作ることが出来ます。
ブロックは色んな種類があり、データのカラムを編集できるブロックや、Pythonの処理を書き込めるブロックなど、様々なものがあります。
チュートリアル概要
今回は二項分類のチュートリアルを行っていきたいと思います。
データの内容は働いている大人の年収が50K$以上か以下かというデータになります。
色々な人の年収のデータを使い、未知のデータを予測していこうと思います。
ブロックについて
まず、ブロックそれぞれの機能と処理を確認していきます。

全体図はこんな感じです。
そしたら上から見ていきます。
Adult Census Income Binary Classification dataset

ここには今回の予測に使うデータセットが格納されています。
それぞれのカラム毎のデータがグラフでも確認できます。

今回予測する箇所は一番右のカラムのincomeという欄になります。
それぞれの年収が50K以上か以下か記した行になります。
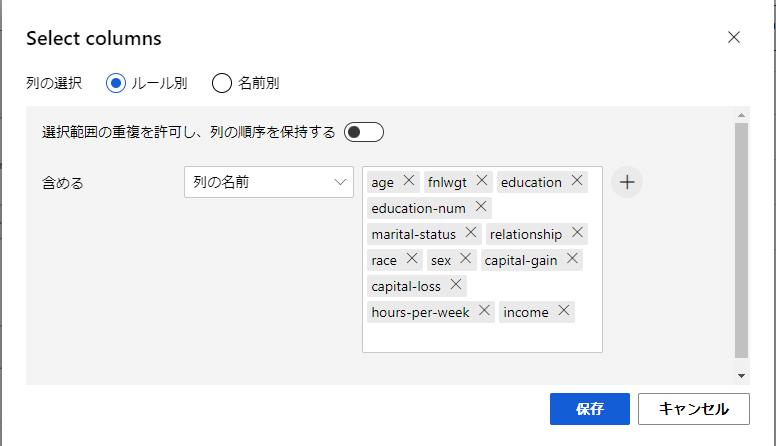
Select Columns in Dataset

ここのブロックでは、上記のデータセットをつかい、カラムを選択するブロックになります。
今現在は、age,fnlwgt,education,education-num,marital-status,relationship,race,sex,capital-gain,capital-loss,hours-per-week,incomeが選択されてます。
右側の列の編集を押すことで、選択するカラムが変更できます。
今回は選択済みなので、このまま進めます。
Execute Python Script
一番初めのPythonの処理になります。

ここに記入されており、コードの編集から編集ができます。
下記がコードになります。
# The script MUST contain a function named azureml_main
# which is the entry point for this module.
# imports up here can be used to
import pandas as pd
from pandas.api.types import is_numeric_dtype
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None):
label_col = 'income'
true_label = '>50K'
output = convertDataFrameToVWFormat(dataframe1, label_col, true_label)
return output,
def convertDataFrameToVWFormat(dataframe, label_col, true_label):
# remove '|' and ':' that are special characters in VW
def clean(s):
return "".join(s.split()).replace("|", "").replace(":", "")
def parse_row(row):
line = []
# convert labels to 1s and -1s and add to the beginning of the line
line.append(f"{1 if row[label_col] == true_label else -1} |")
for col in feature_cols:
if col in numeric_cols:
# format numeric features
line.append(f"{col}:{row[col]}")
else:
# format string features
line.append(clean(str(row[col])))
vw_line = " ".join(line)
return vw_line
# get feature columns and numeric columns
feature_cols = [col for col in dataframe.columns if col != label_col]
numeric_cols = [col for col in dataframe.columns if is_numeric_dtype(col)]
# parse each row
output = dataframe.apply(parse_row, axis=1).to_frame()
return output
ここのPythonの処理は、データセットをVW形式に変換する処理になります。
Adult Income データセットを Vowpal Wabbit 形式に変換し、トレーニングデータとテストデータに分割して、Azure BLOB に書き込みます。
Split Data

ここのブロックでは上記で作成した、トレーニングデータとテストデータを分けるブロックになります。
そのため、最後のoutputが二つになっており、それぞれに対して処理を行っていく形になります。
このブロックの機能を上から確認していきます。
Splitting mode
データセットの分割方法を選択する。

- 行の分割
- 正規表現
- 相対表現
Fraction of rows in the first output dataset
入力データセットの行数に対する、最初の出力データセットの行数を表す比率を指定する。

Randomized split
行をランダムに選択するかどうかを指定する

Random seed
乱数生成器のシードを確認するための値を設定する。

Stratified split
各分割の行を層別カラムでグループ化するかどうかを指定する。

Train Vowpal Wabbit Model
ここのブロックでは、コマンドラインインタフェースを用いてVowpal Wabbitモデルを学習させるブロックになっています。
ここでモデルの作成を行います。
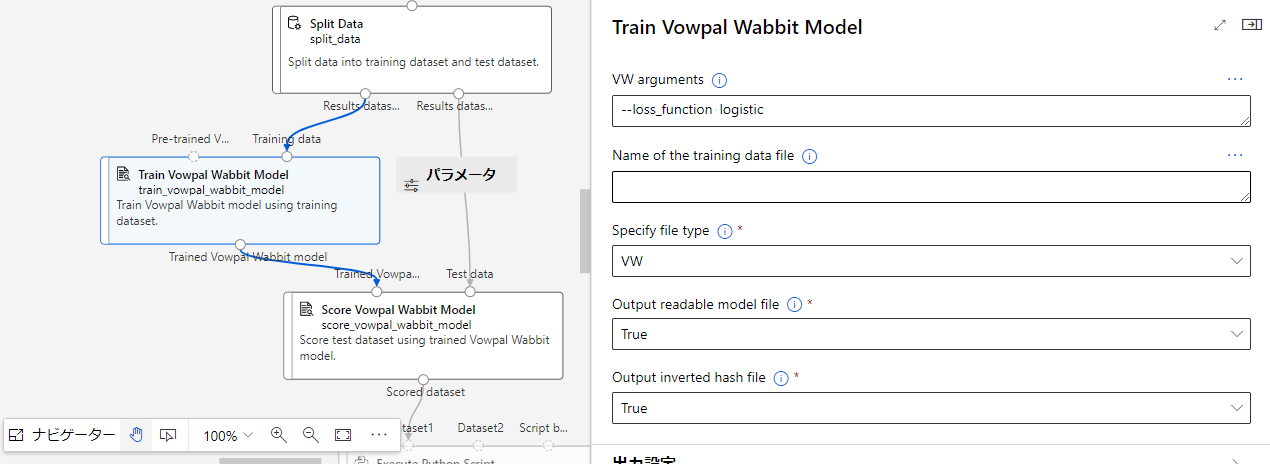
先ほど上記でトレーニングデータとテストデータを分けたので、それのトレーニングデータのみ使います。
VW arguments
vowpal wabbitのコマンドライン引数を入力する。
--loss_function logistic(使用する損失関数を指定する。デフォルトでは2乗を使用する)

公式記事の説明

Name of the training data file
学習用データファイルの名前を入力する場所
今回は入力せず行きます。

Specify file type
ファイルの種類を指定します。
今回はVWになります。

※SVMLightはC言語で書かれた SVM ( Support Vector Machine ) プログラムになります
Output readable model file
読みやすいモデル (--readable_model) ファイルを出力するかどうか。
--readable_modelは人間が読める最終リグレッサを数値特徴量として出力するコマンドになります。

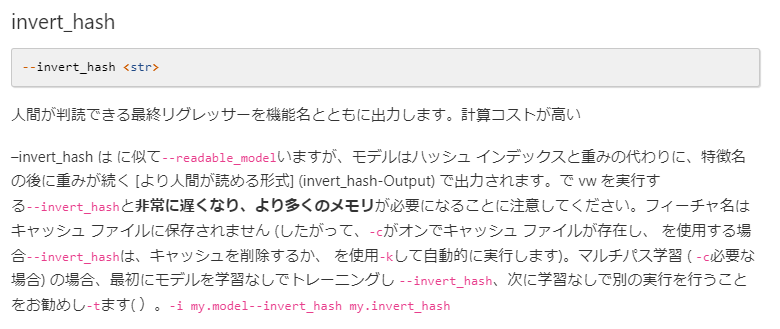
Output inverted hash file
inverted hash(--invert_hash)ファイルを出力する。
--invert_hashは人間が判読できる最終リグレッサーを機能名とともに出力するコマンド

公式記事の説明
Score Vowpal Wabbit Model
ここのブロックでは、コマンドラインインターフェースからVowpal Wabbitを使用してデータをスコアリングするブロックになってます。

このブロックには、Train Vowpal Wabbit ModelでVowpal Wabbitモデルの学習を行ったモデルと、Split Dataで分けたテストデータを使います。
VW arguments
vowpal wabbitのコマンドライン引数を入力する。
--link logistic(リンク機能を指定するコマンド)

Name of the test data file
検証用データファイルの名前を入力する場所
今回は入力せず行きます。

Specify file type
ファイルの種類を指定します。
今回はここもVWになります。

Include an extra column containing labels
ラベルを含む余分なカラムを scored データセットに含めるかどうかを選択します。

Include an extra column containing raw scores
scored データセットに、raw scoresを含む追加のカラムを含めるかどうか。

Execute Python Script
評価用の採点結果カラムを追加する。ブロックになります。
上記でスコアリングしたデータセットに、Binary Class Scored Labelsのカラムを追加していく処理。

下記がコードになります。
# The script MUST contain a function named azureml_main
# which is the entry point for this module.
# imports up here can be used to
import pandas as pd
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be None.
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1=None, dataframe2=None):
threshold = 0.5
binary_class_scored_col_name = "Binary Class Scored Labels"
binary_class_scored_prob_col_name = "Binary Class Scored Probabilities"
# result is the probability when "--link logistic" is on. Rename it to "Binary Class Scored Probabilities"
output = dataframe1.rename(columns={"Results": binary_class_scored_prob_col_name})
# set scored labels according to the probabilities
output[binary_class_scored_col_name] = output[binary_class_scored_prob_col_name].apply(
lambda x: 1 if x >= threshold else -1)
return output
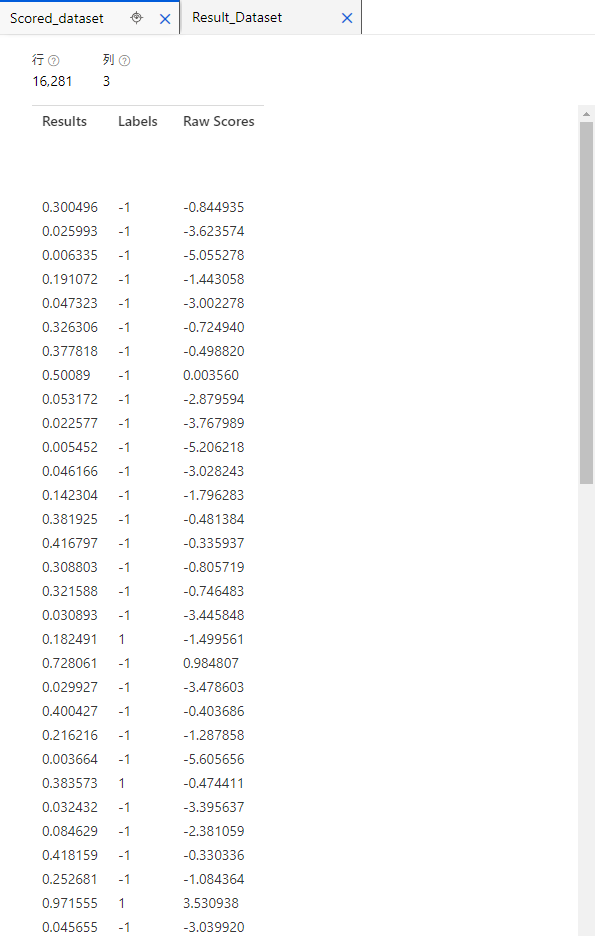
処理としては、Scored datasetのResultのカラムのデータを使います。
それをPythonの処理を使います。
def azureml_main(dataframe1=None, dataframe2=None):
threshold = 0.5
binary_class_scored_col_name = "Binary Class Scored Labels"
binary_class_scored_prob_col_name = "Binary Class Scored Probabilities"
output = dataframe1.rename(columns={"Results": binary_class_scored_prob_col_name})
output[binary_class_scored_col_name] = output[binary_class_scored_prob_col_name].apply(
lambda x: 1 if x >= threshold else -1)
ここの処理を使うことで、threshold以上を1、以下をー1にするという処理と、
新しいカラムBinary Class Scored Labelsに記述していくという処理になります。

上記のBinary Class Scored Labelsがtestデータの結果になります。
Edit Metadata
Labelsの列をEvaluate ModelのLabelsフィールドに変更する、ブロックになります。
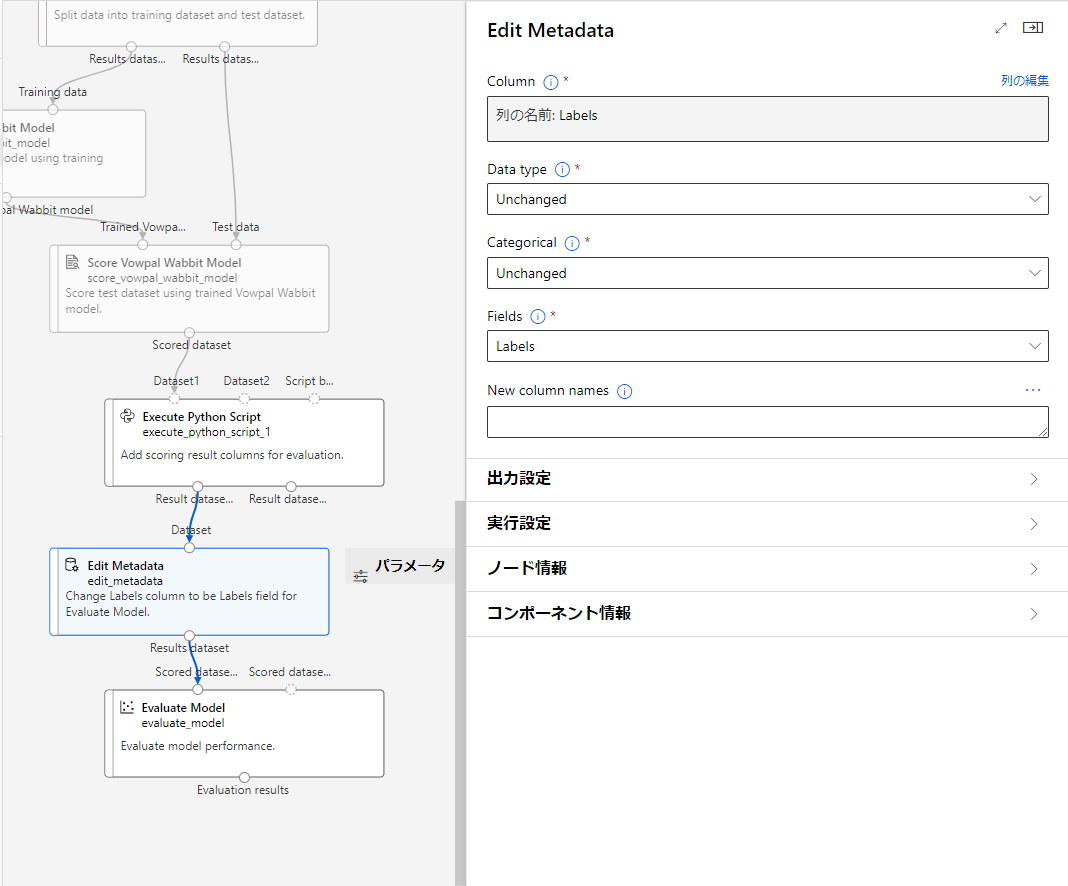
上から説明していきます。
Column
変更を適用するカラムを選択します。
今回はLabelsを選択します。

Data type
カラムの新しいデータ型を指定します

- Unchanged:変更なし
- String:文字型
- Integer:整数型
- Double:浮動小数点数型
- Boolean:論理型
- DateTime:日付時刻
に変更可能です。今回は変更しません
Categorical
カラムにカテゴリフラグを付けるかどうかを指定する。
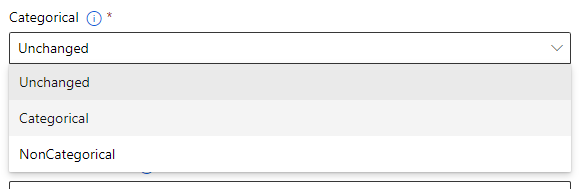
今回は変更なしで進めます。
Fields
学習アルゴリズムにおいて、カラムを特徴とみなすか、ラベルとみなすかを指定する。
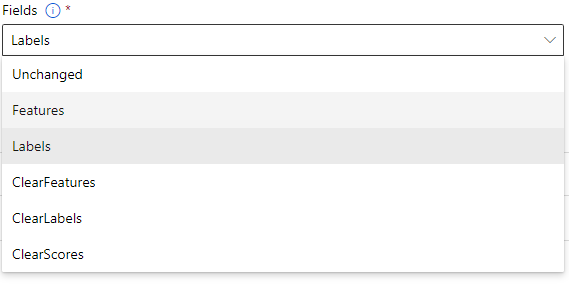
- Unchanged:変更なし
- Features:特徴
- Labels:ラベル
- ClearFeatures:特徴をクリアする
- ClearLabels:ラベルをクリアする
- ClearScores:スコアをクリアする
今回はLabelsを選択します。
New column names
カラムの新しい名前を入力する

今回は記入なしで進みます。
Evaluate Model
ここのブロックでは、モデルの性能を評価します。
実行した後に、このようなデータを確認することができます。
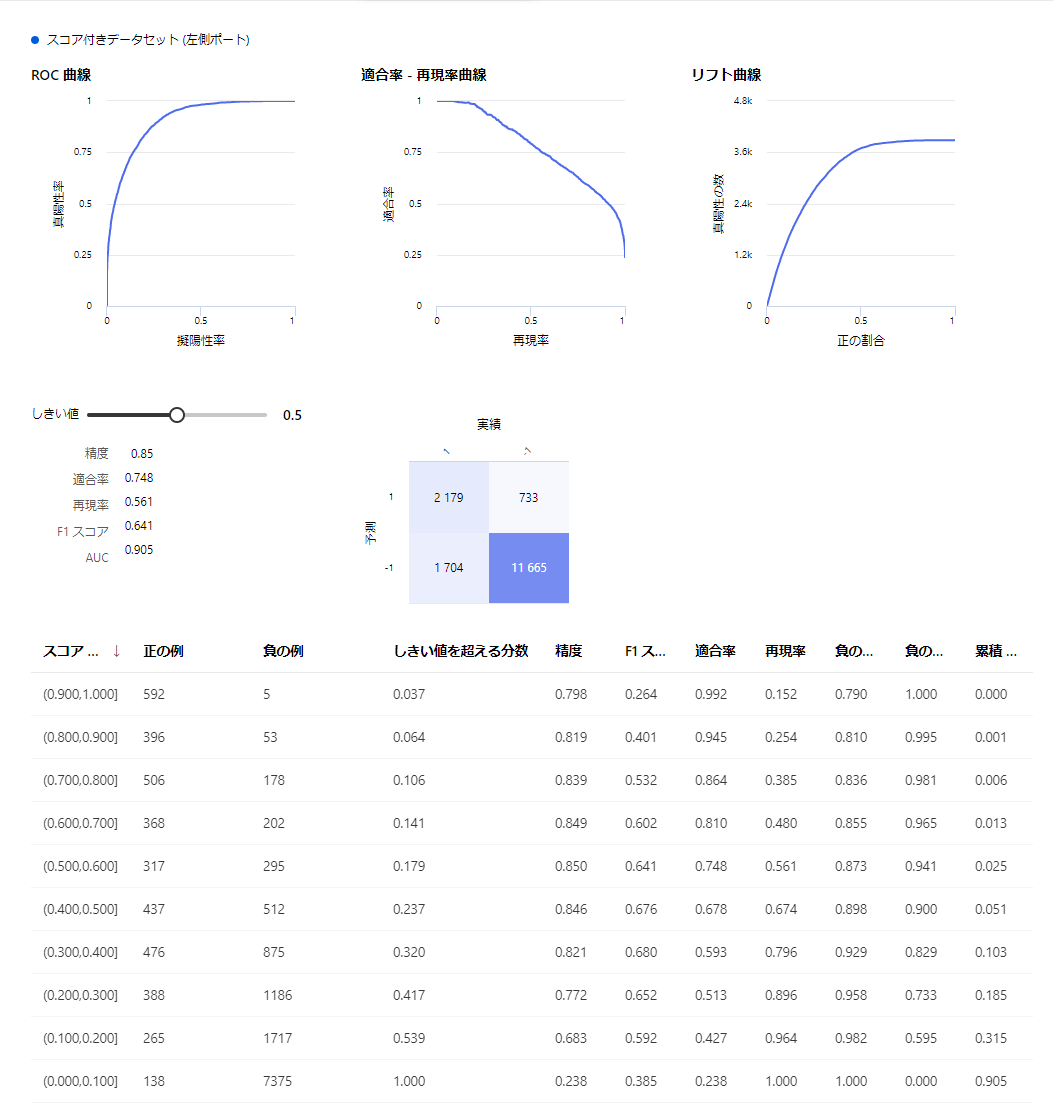
ROC曲線
カットオフ値を連続的に変化させた際の真陽性率と偽陽性率の値をプロットした曲線です。
適合率 - 再現率曲線(PR曲線)
縦軸に適合率(Precision)を、横軸に再現率(感度, Recall,true positive rate,TPR)をとる曲線です。

リフト曲線
モデルの精度を図る曲線

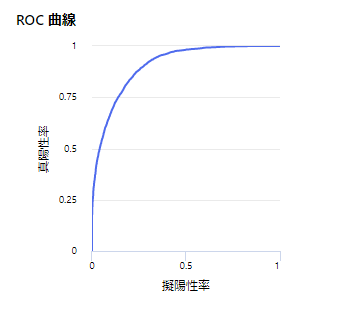
しきい値の変更
変更することで別の結果を見ることができる
しきい値を変えることで、右の混同行列も変わる

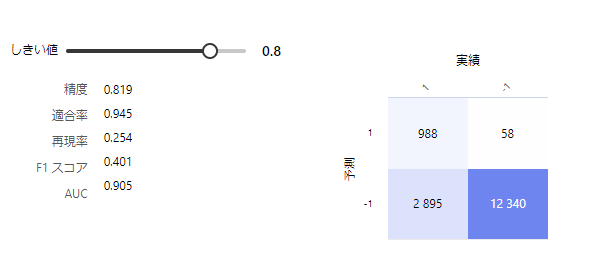
※混合行列とは
二値分類(2クラス分類)においては実際のクラスと予測したクラスの組み合わせによって、結果を以下の4種類に分けることができる。
- 真陽性(TP: True Positive): 実際のクラスが陽性で予測も陽性(正解)
- 真陰性(TN: True Negative): 実際のクラスが陰性で予測も陰性(正解)
- 偽陽性(FP: False Positive): 実際のクラスは陰性で予測が陽性(不正解)
- 偽陰性(FN: False Negative): 実際のクラスは陽性で予測が陰性(不正解)
これを行列にしたものが混合行列。
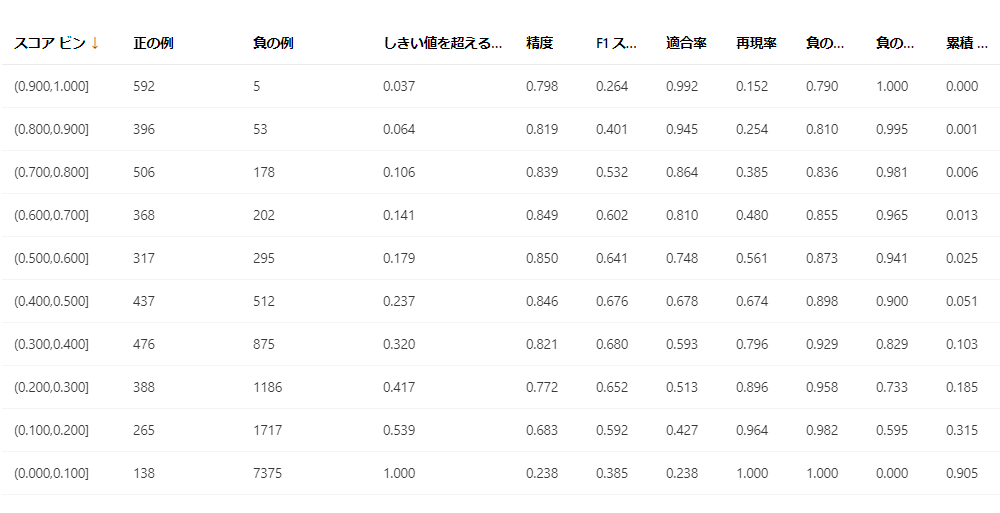
スコア範囲ごとのデータ
一定の範囲ごとに分けられたデータになります。
作ったモデルを使ってテスト実行してみる
上記で作ったモデルを使ってテスト実行してみたいと思います。
トレーニングの処理
まずは、デザイナーで作ったモデルの処理を送信します。
左上の送信ボタンを押すと、下記の画像のようなものが出てきます。

今まで作ったことがある場合は、既存のものを選択で前回の設定を使える且つ、一つのファイルのような感じで、実験名によって振り分けることができるようになります。
今回は初めてなのでtestという実験名を付けて送信します。
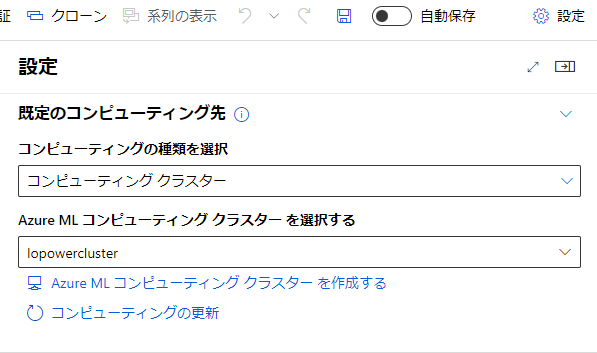
※右上の設定から、コンピューティングを作成して設定しておかないとエラーが起こるので注意。
このような感じで送信済みジョブになるので、青文字のジョブの詳細をクリックして、ジョブの詳細に飛びます。

そうするとこのような画面に飛びます。
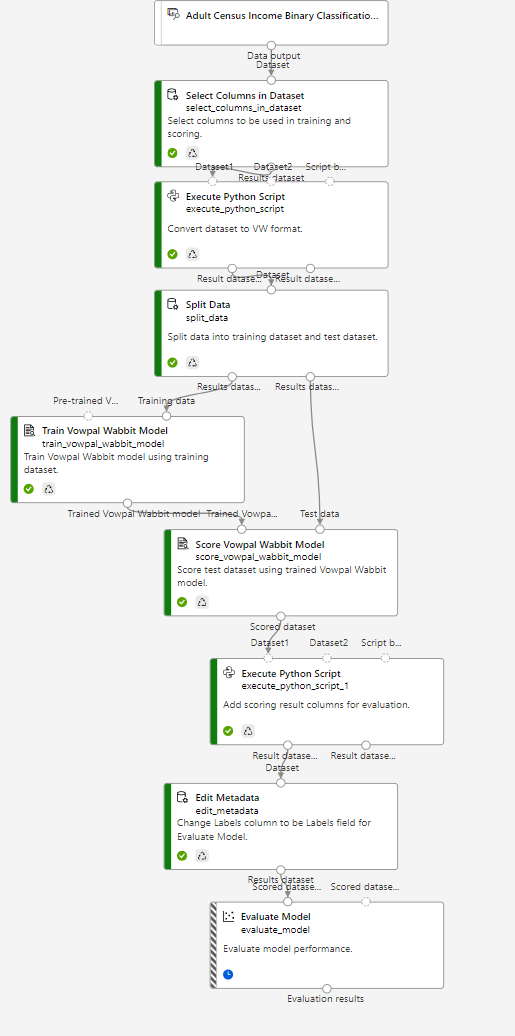
左側が緑色になっているのが、処理が終わったブロック。
縞々になっているのが、現在処理を行っているブロックになります。
※下記画像のように、赤色になることがありますが、エラーです。

エラーの詳細は右上のジョブの概要から確認できます。


今回のエラーはUserErrorというのが確認できます。
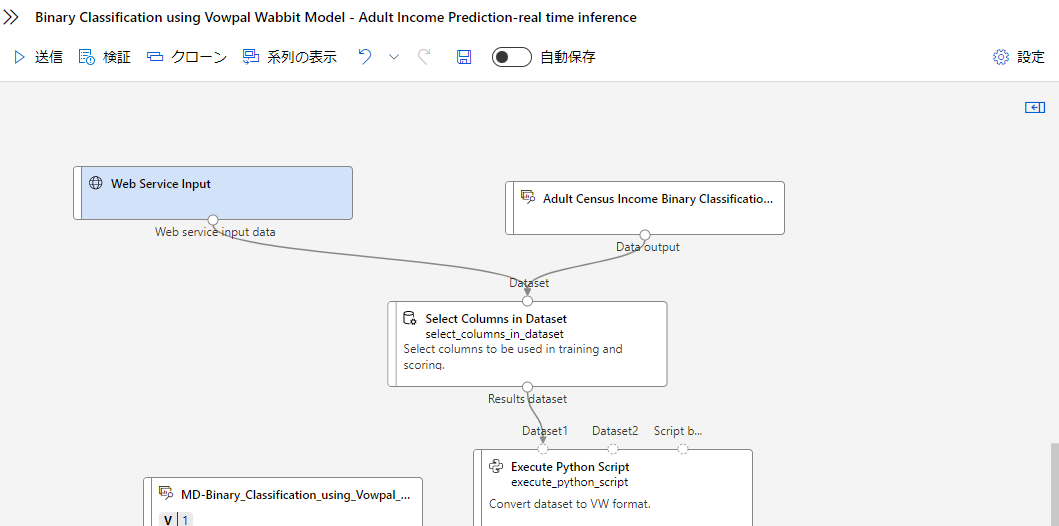
リアルタイム推論パイプラインの作成
完了したら、リアルタイム推論パイプラインを作成して、未知のデータを予測するモデルを作ります。

※最新の情報に更新を押さないと出てこない場合があります。
押すとこのような画面に飛びます。

これは、デザイナー上で新しくトレーニングとは別にリアルタイム推論というパイプラインが作成されます。

Web Service InputとWeb Service Outputについて
Web サービスの入力コンポーネントでは、ユーザー データがパイプラインに入る場所が指示されます。 Web サービスの出力コンポーネントでは、リアルタイム推論パイプライン内でユーザー データが返される場所が指示されます。
要件を満たすために、Web サービスの入力および Web サービスの出力コンポーネントを手動で追加または削除することができます。 リアルタイム推論パイプラインには、少なくとも 1 つの Web サービスの入力コンポーネントと 1 つの Web サービスの出力コンポーネントがあるようにしてください。 Web サービスの入力コンポーネントまたは Web サービスの出力コンポーネントが複数ある場合は、それらの名前が一意であることを確認してください。 コンポーネントの右パネルに名前を入力できます。
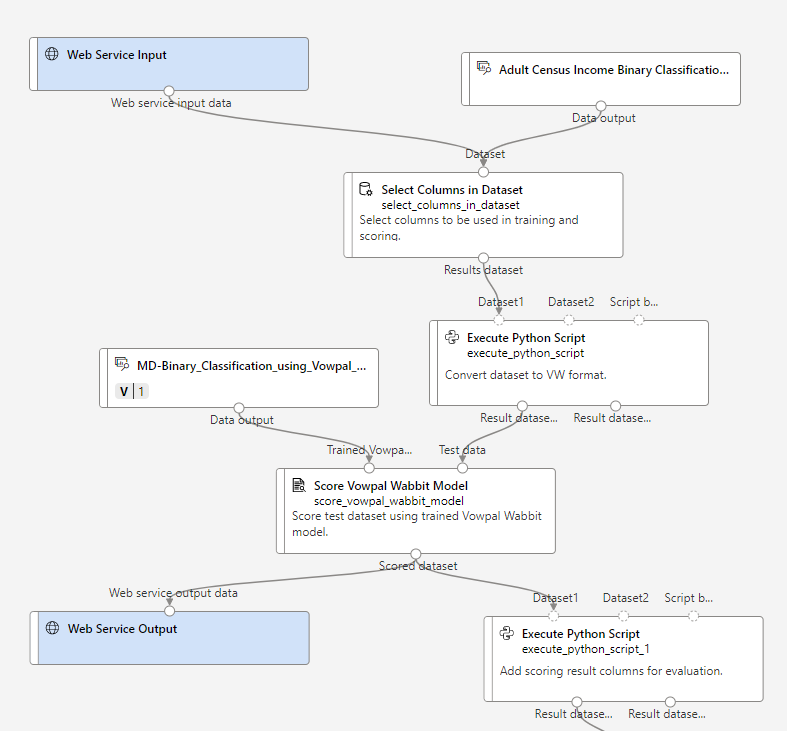
MD-Binary_Classification_using_Vowpal_...
トレーニングで作成したモデルが、ファイルとして格納されているブロックになります。
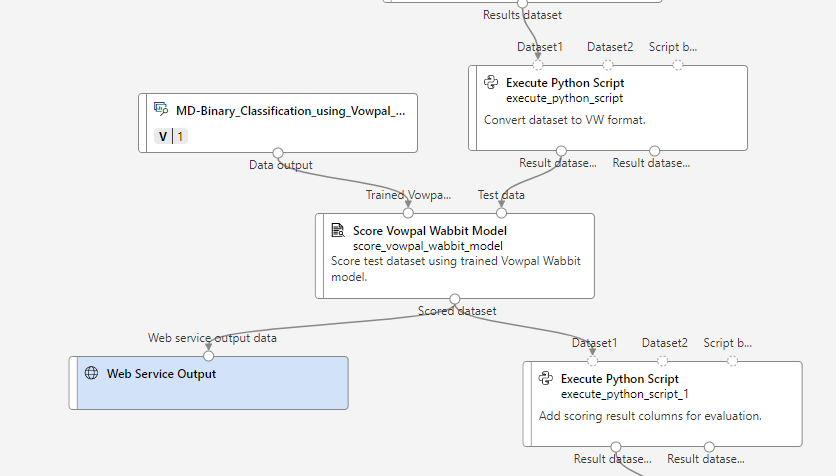
中身はこんな感じのファイルがはいってます。

推論パイプラインの実行
実行してみる。
同じように左上の送信を押すと、トレーニングと同じ設定の画面が出てきます。
今回は、トレーニングの時設定した、testの設定を使ってみたいと思います。

同じようにジョブとして登録されます。
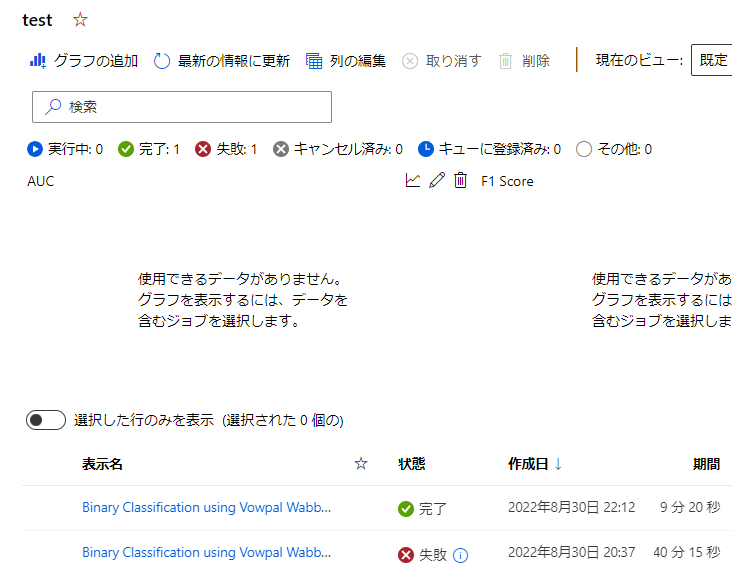
※ジョブの確認方法
左のタブからジョブを選んで選択

このような感じで先ほどの設定毎で、見れるようになってます。
今回はtestなのでそれをクリックします。

そうすると、このtestの設定のジョブを一覧で見れます。
推論パイプラインのデプロイ方法
これで、全部の処理が完了したので、次にデプロイをします。
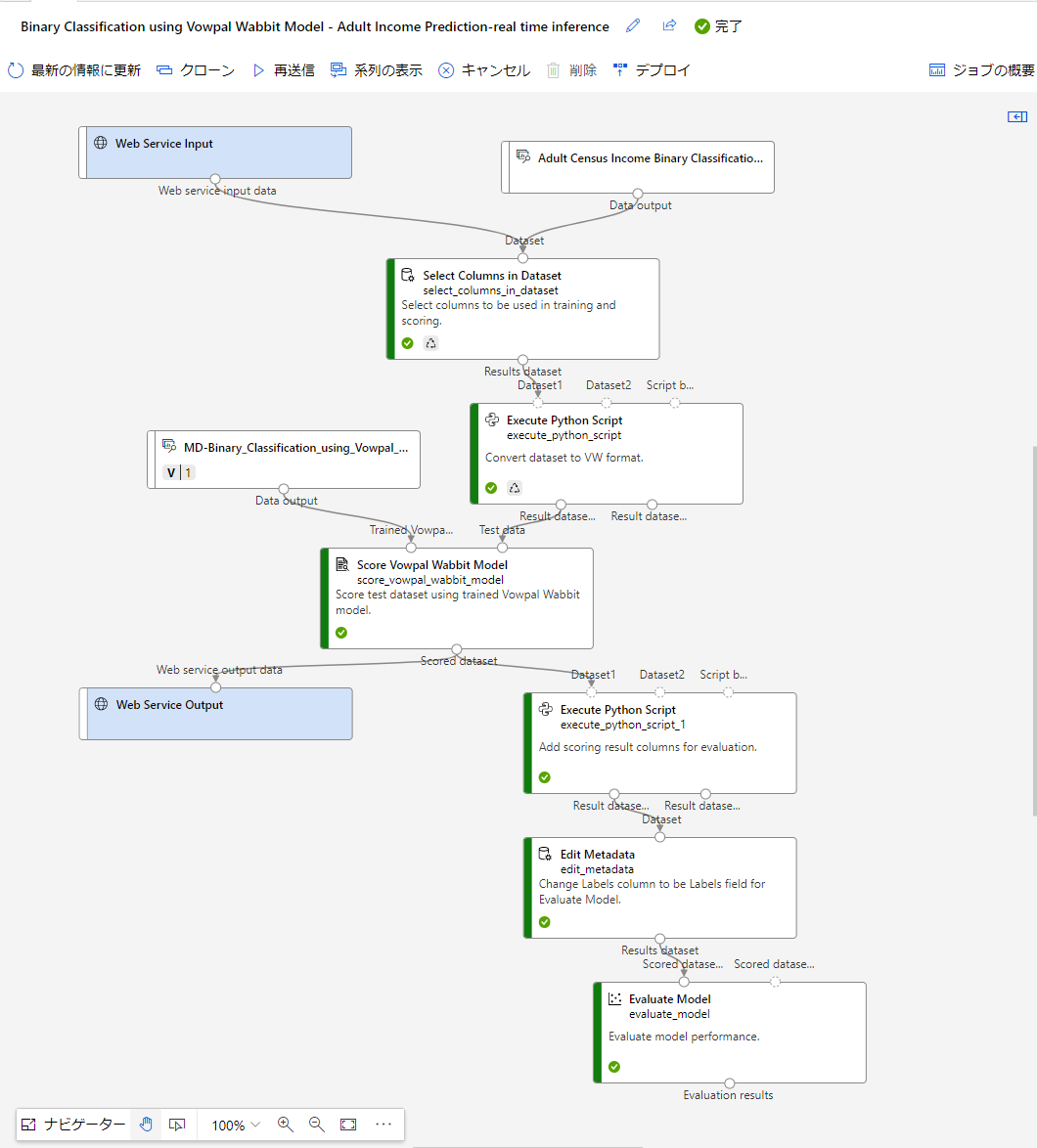
こちらのデプロイを押します。

押すとエンドポイントの設定に入ります。
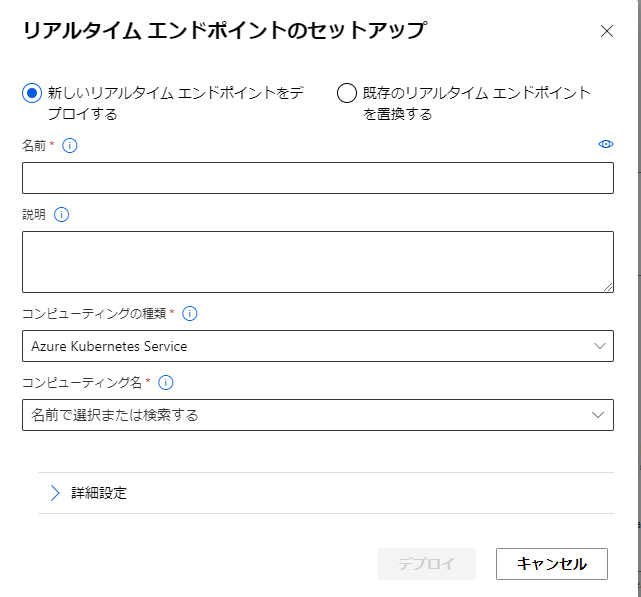
まだ、推論クラスターを作ってないので、コンピューティングを指定できません。
なので、まず推論クラスターを作ります。
推論クラスターの作成
左のメニューから、コンピューティングを選びます。

推論クラスターを選択し、新規をクリック
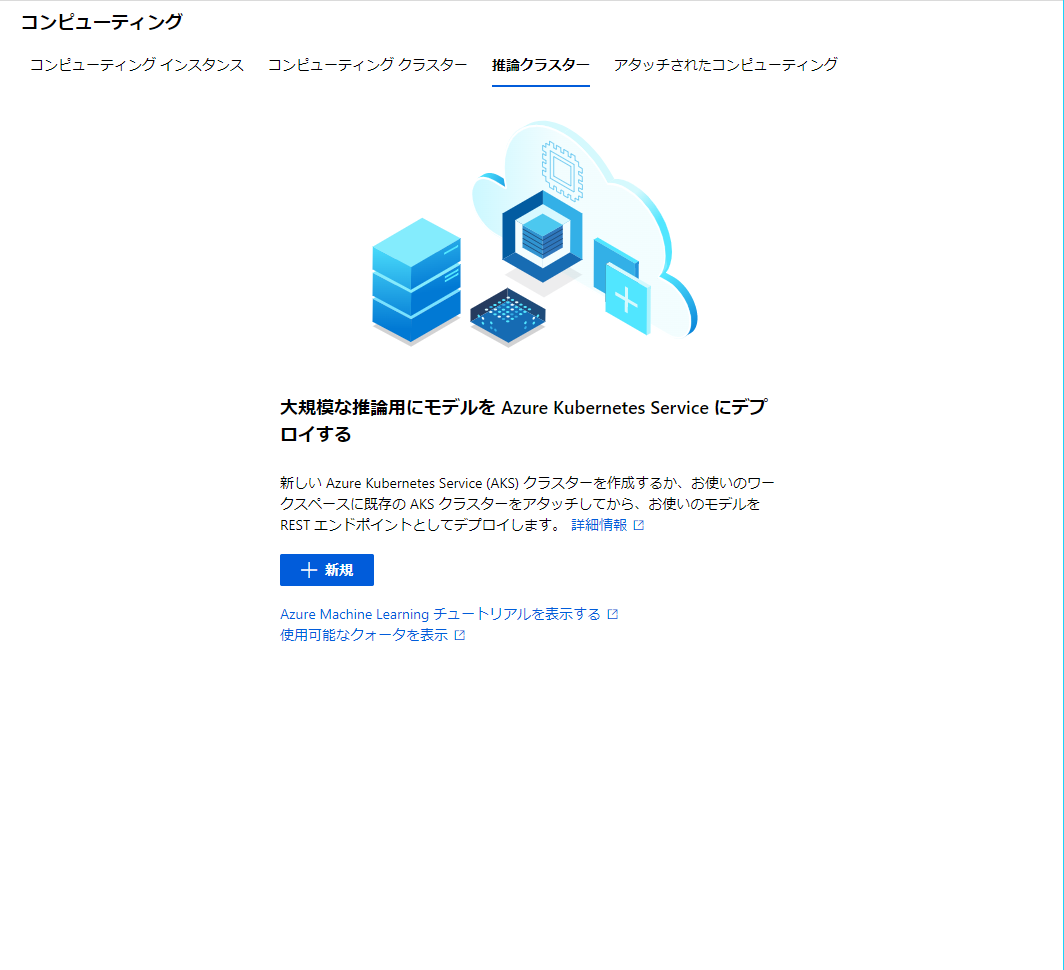
今回は新規作成なので、リージョン(場所)の選択から。

選択した後、VMのサイズを選択

次に、このコンピューティングの名前を決めます。
自分の好きな名前で大丈夫です。
[名前は必須です。名前の長さは 2 から 16 文字の間でなければなりません。有効な文字は英字、数字、- 文字です]
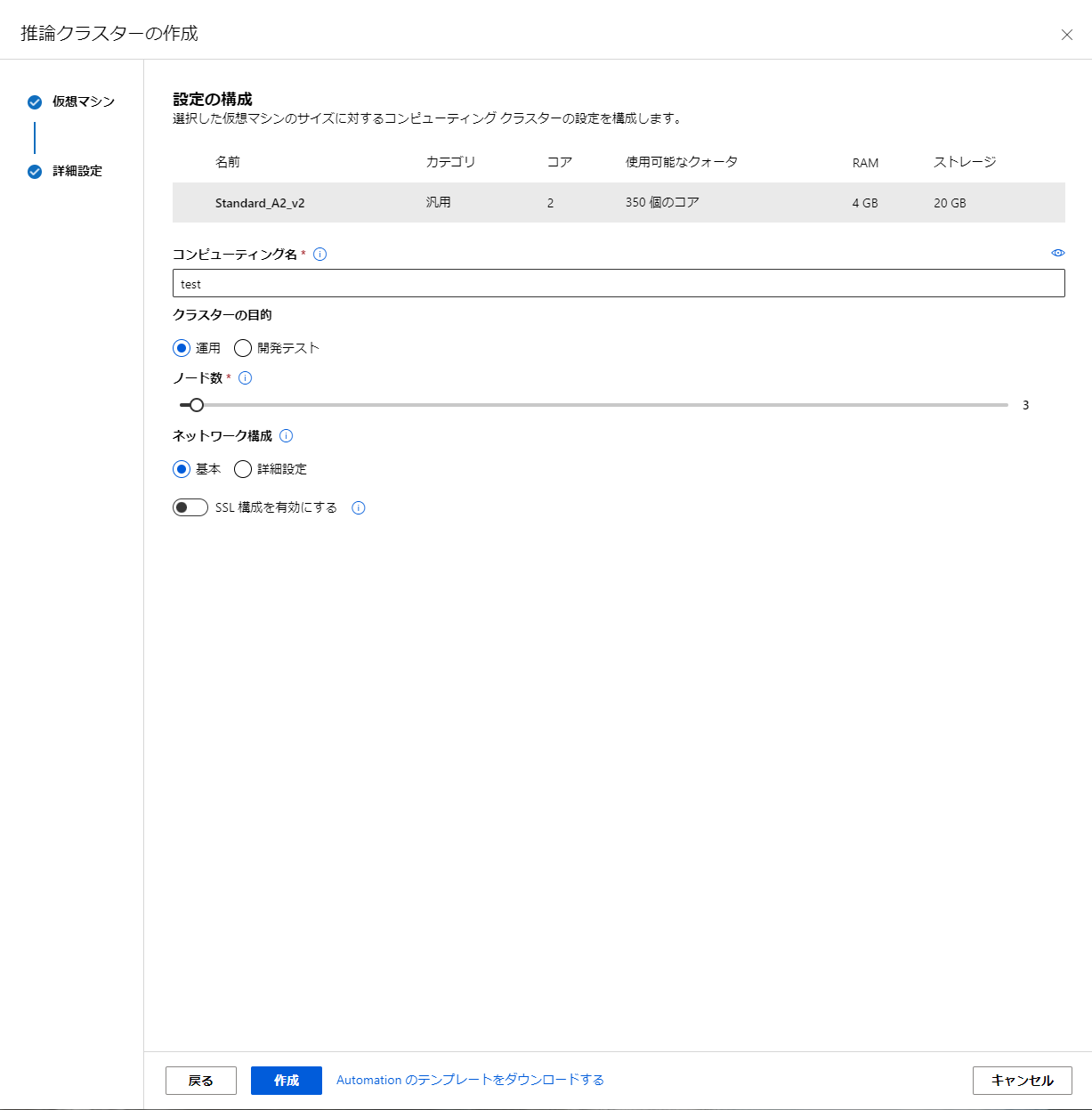
今回はこのままで作成します。
※その他の設定
ノード数:ノードのサイズによって、CPU コアの数、メモリ容量、およびノードに割り当てられるローカル ファイル システムのサイズが決まります。
[運用クラスターのノード数は、3 つ以上である必要があります。]
ネットワーク構成:詳細設定でIPアドレスなどを、変えれます。
[既存の仮想ネットワーク内にコンピューティングを作成するときにこれを使用します。]
SSL構成を有効にする:これを使用して、コンピューティングの SSL 証明書を構成します。
デプロイ方法
こちらで推論クラスターが完成したので、先ほどのデプロイに戻ります。

エンドポイントの設定をします。

名前はわかりやすいもので。
[これは、お客様のモデルがデプロイされた後に [エンドポイント] タブに表示されます。]
コンピューティングの種類は、Azure Kubernetes ServiceとAzure コンテナーインスタンスの二種類から。
Azure Kubernetes Service:運用上のオーバーヘッドが Azure にオフロードされるため、Azure でのマネージド Kubernetes クラスターのデプロイが簡素化されます。 ホストされた Kubernetes サービスとして、Azure によって正常性監視やメンテナンスなどの重要なタスクが処理されます。Kubernetes クラスターを Azure に短時間でデプロイすることができます。
Azure コンテナーインスタンス:コンテナーは、クラウド アプリケーションのパッケージ化、デプロイ、管理を行う優れた方法としてしだいに普及しつつあります。 Azure Container Instances には、仮想マシンを管理したり、より高度なサービスを採用したりせずに、Azure で最も高速かつ簡単にコンテナーを実行する方法が用意されています。
といったものになってます。
今回はAzure Kubernetes Serviceの方を使います。
コンピューティング名は先ほど推論クラスターで作った名前になります。
今回は詳細設定はいじらず、このままデプロイします。
詳細設定では、レプリカ数や、CPU、メモリの予約容量などVMの設定を幅広く変更できます。
エンドポイントの確認
デプロイを行うと、左のエンドポイントに今回のものが追加されます。
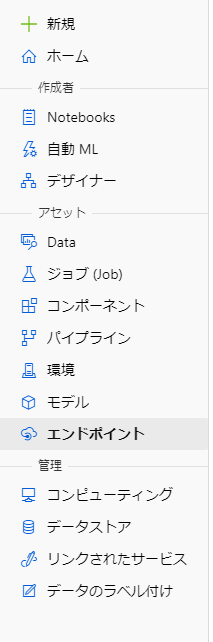
このような感じで、一覧で表示されます。

今回のデプロイしたエンドポイントに入ると、現在のデプロイ状態がわかります。
デプロイ状態がまだ、Transitioningなので移行中で、サービスがデプロイ処理中であることを示します。

デプロイ状態がHealthyになったので、テスト実行ができるようになりました。
上のタブのテストのところからできます。

テストに入ると、エンドポイントをテストするデータの入力ができます。
データの入力はjson型になっており、ここで予測したいデータに書き換えることができます。

テストボタンを押すと、予測結果が表示されます。

以上で一通りの流れと説明は以上になります。
まとめ
今回は二項分類についてやってみました。
初めてAzureMLを触ってみたのでとても難しくわからないことだらけでした。
今後、AzureMLを触る人がいたら、参考にしてみてください。
次回もチュートリアルをやってみます。