はじめに
前回に引き続き、AzureMLのチュートリアルをしていきます。
今回もデザイナーを使っていきます。
チュートリアル概要
今回のチュートリアルは、Recommendation - Movie Rating Tweetsというものになります。
このサンプルでは、レコメンデーションモジュールを使って、映画のレコメンデーションエンジンを学習させる方法を紹介します。
これにより、ユーザーの評価または、好みを使い、そのユーザーがどのような評価をこの映画にするのかというモデルになります。
ブロックの説明
今回のデータ
今回のデータは映画のデータとユーザーの評価データを使います。
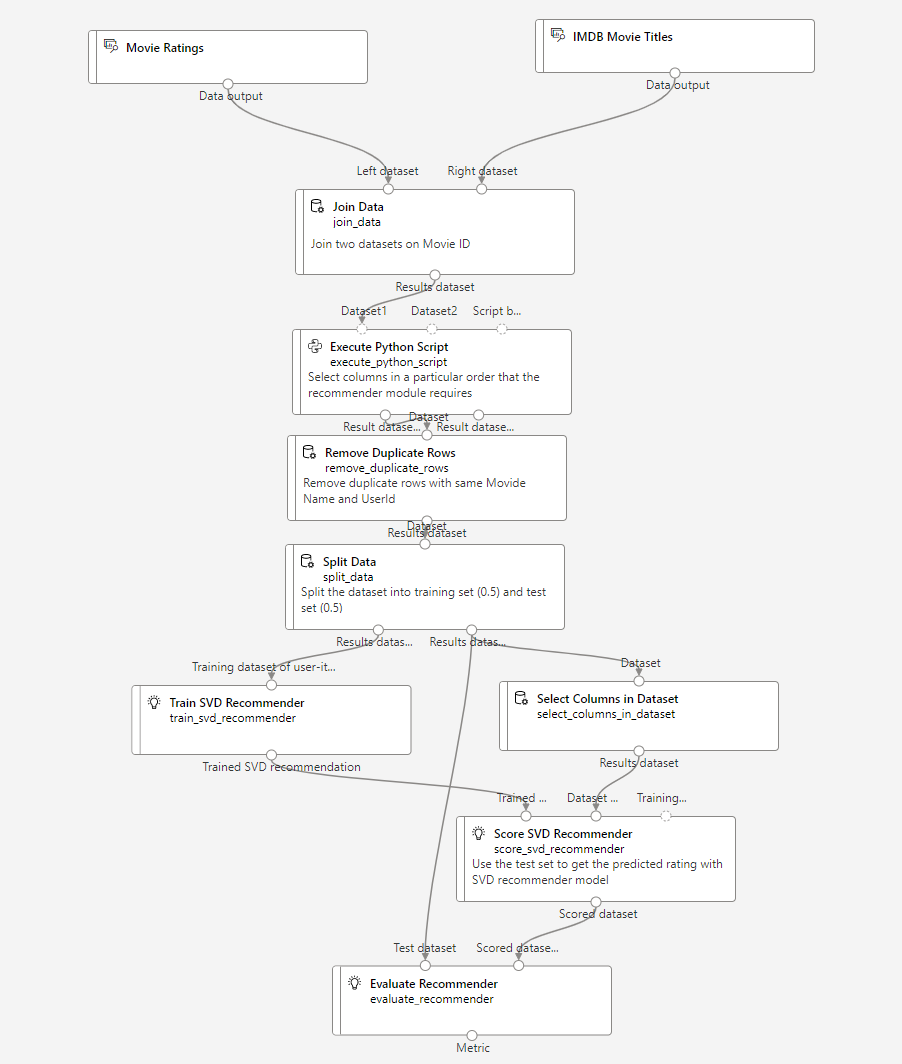
Movie Ratings
ユーザーの評価データ
ユーザーがどの映画に対して、評価をしたかのデータが入ってます
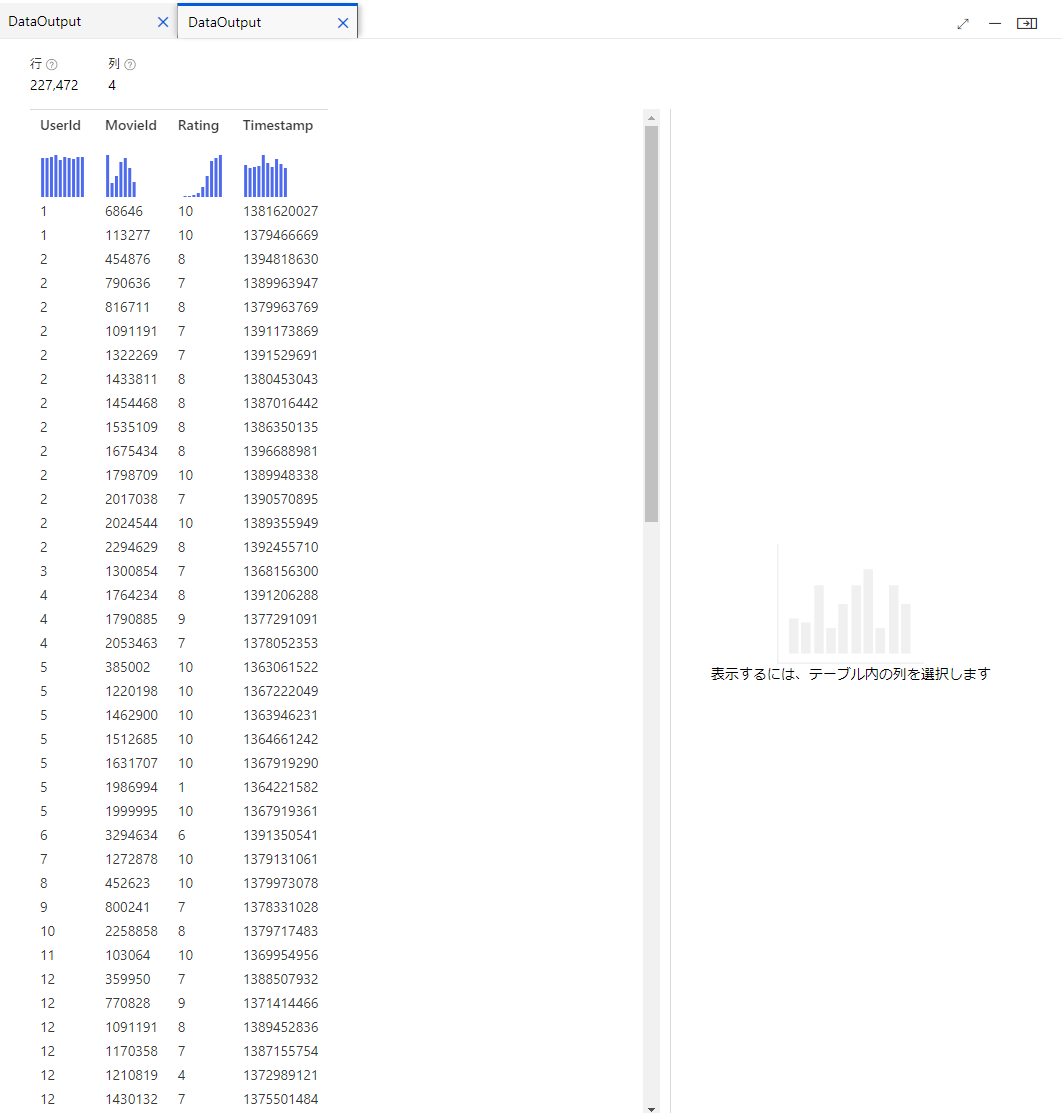
IMDB Movie Titles
映画のタイトルとID
IMDBの映画のデータが一覧で入ってます。
Join Data
二つのデータセットをMovie IDで結合するブロックになります。
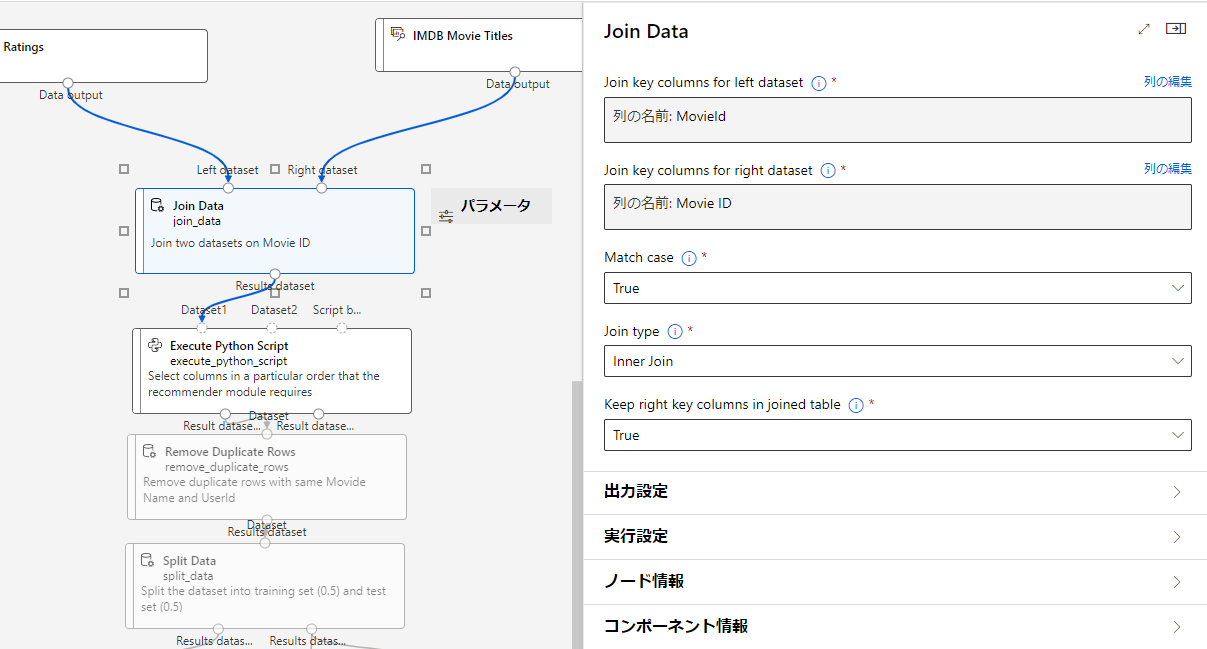
設定を上から解説します。
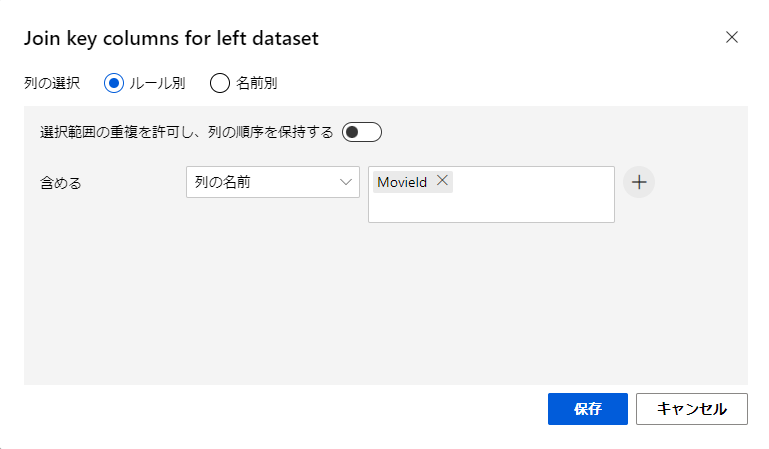
Join key columns for left dataset
左のデータセットの結合キーカラムを選択します。
今回はMovieIdになります。
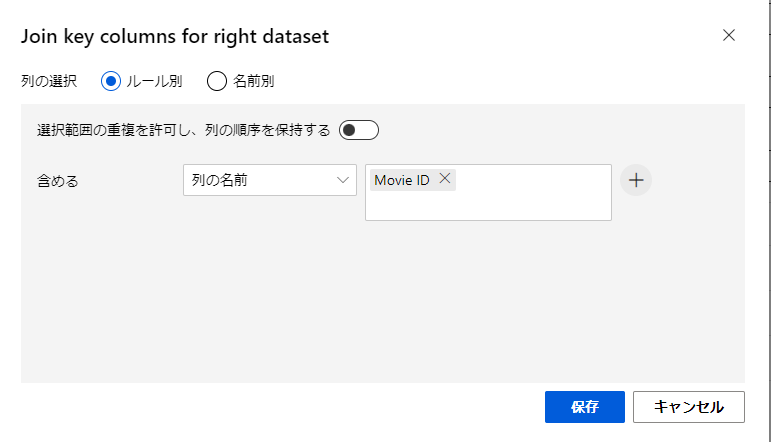
Join key columns for right dataset
右のデータセットの結合キーカラムを選択します。
今回はMovie IDになります。
Match case
キーカラムにおいて大文字小文字を区別した比較を行うかどうかを示す。

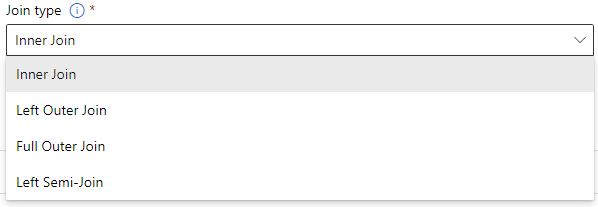
Join type
ジョインタイプの選択
- Inner Join:内部結合
- Left Outer Join:左外部結合
- Full Outer Join:完全外部結合
- Left Semi-Join:左セミ結合
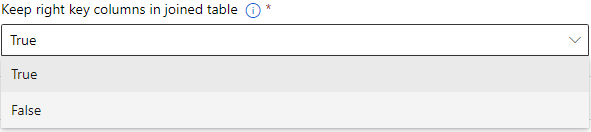
Keep right key columns in joined table
結合されたデータセットに、2つ目のデータセットのキーカラムを残すかどうかを指定する
Execute Python Script
今回のPythonの処理
レコメンダーモジュールが必要とする特定の順序でカラムを選択する。
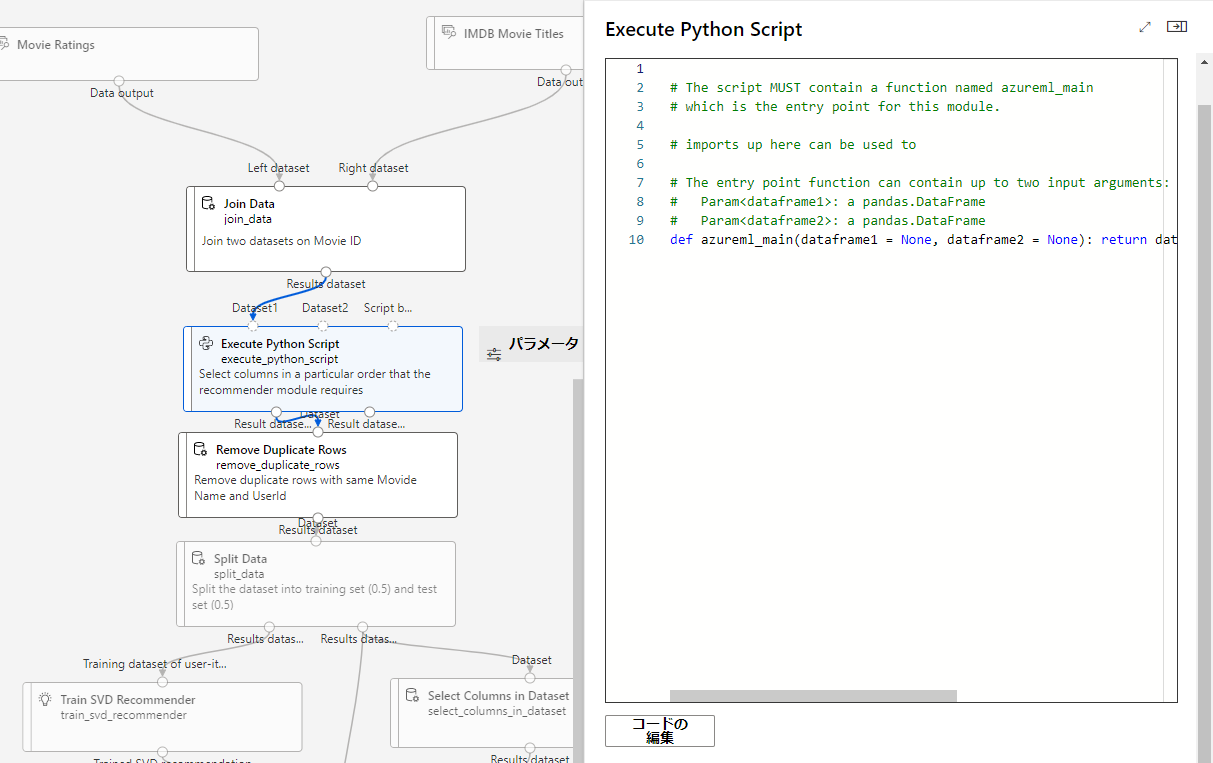
コードはこんな感じ
# The script MUST contain a function named azureml_main
# which is the entry point for this module.
# imports up here can be used to
# The entry point function can contain up to two input arguments:
# Param<dataframe1>: a pandas.DataFrame
# Param<dataframe2>: a pandas.DataFrame
def azureml_main(dataframe1 = None, dataframe2 = None): return dataframe1[['UserId','Movie Name','Rating']],
Remove Duplicate Rows
同じMovide NameとUserIdを持つ重複した行を削除するブロック。
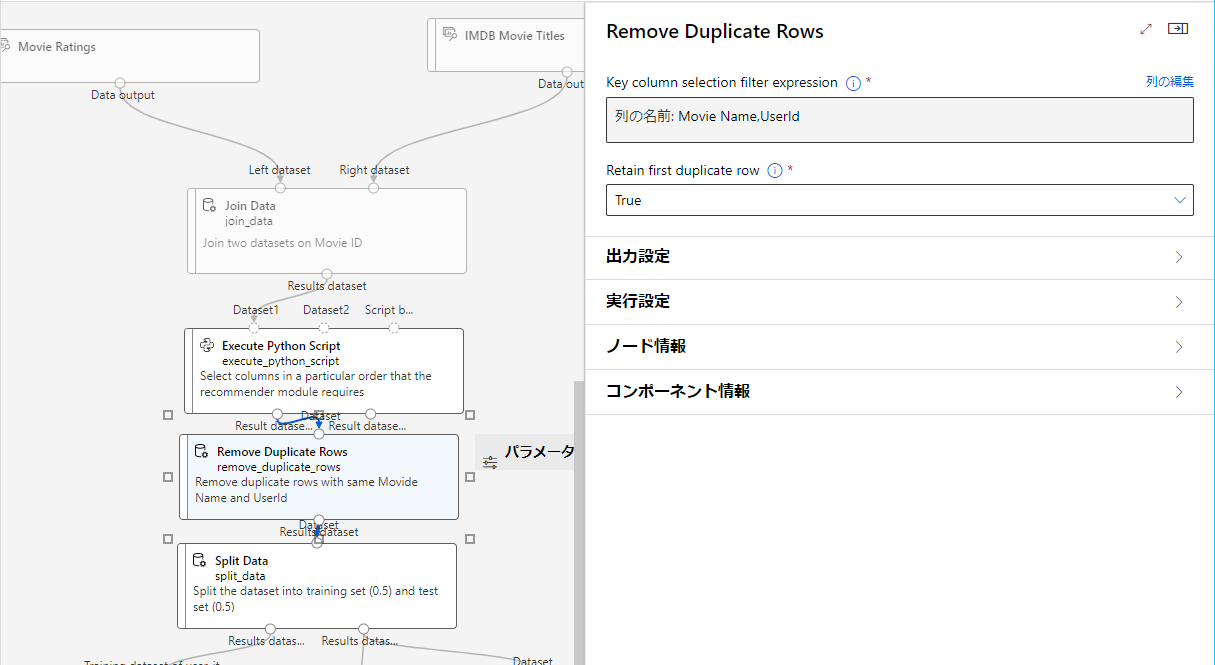
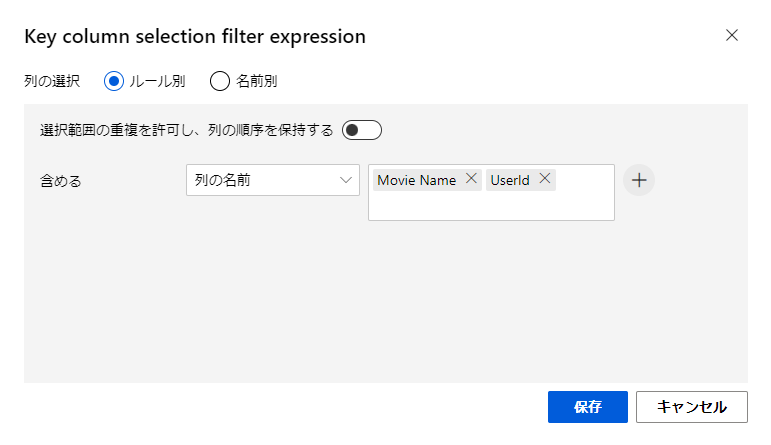
Key column selection filter expression
重複検索時に使用するキーカラムの選択
今回はMovie NameとUserIdを選択。
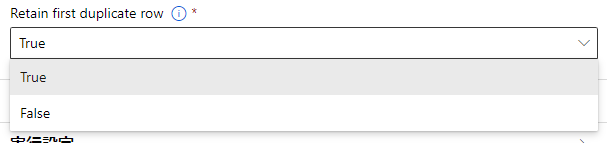
Retain first duplicate row
重複する行の集合の最初の行を残し,他の行を破棄するかどうかを示します。
Split Data
ここのブロックでは上記で作成した、トレーニングデータとテストデータを分けるブロックになります。
そのため、最後のoutputが二つになっており、それぞれに対して処理を行っていく形になります。
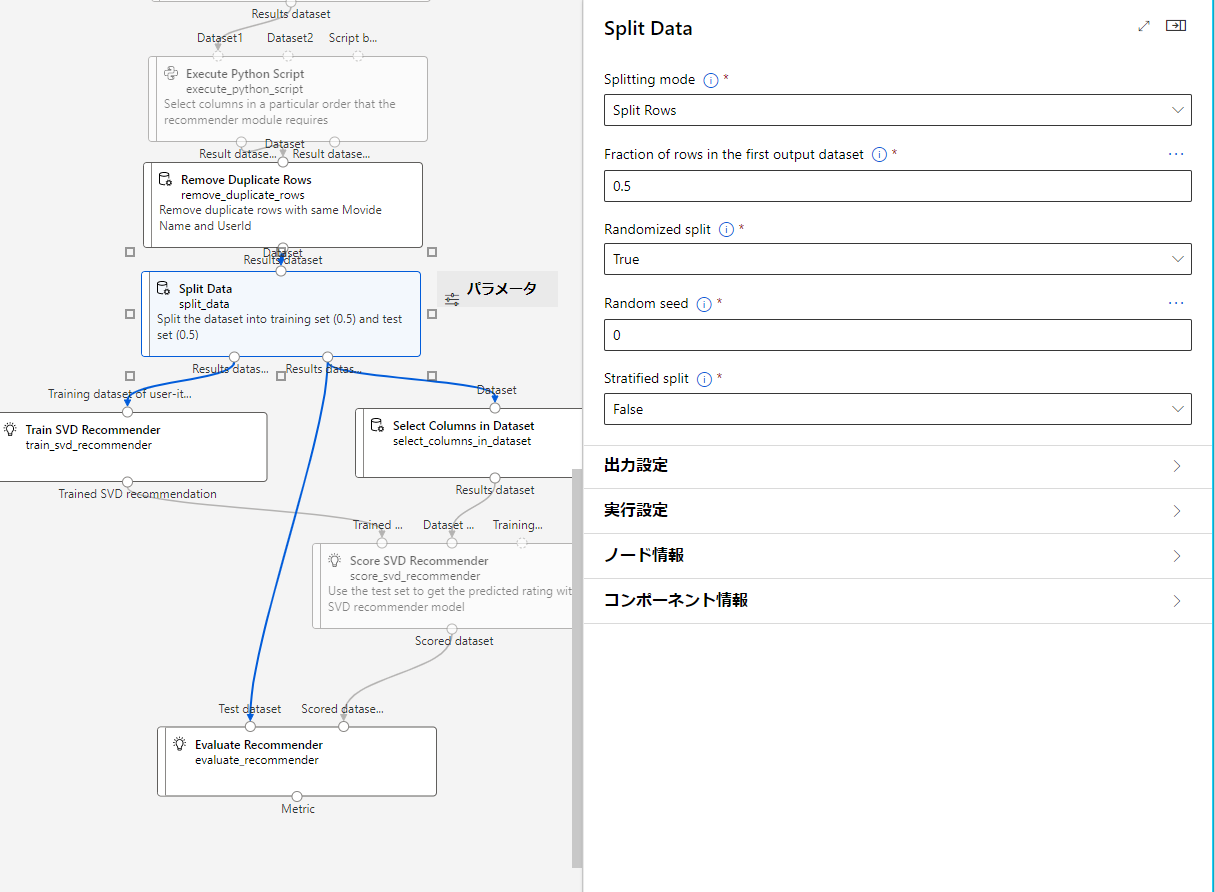
このブロックの機能を上から確認していきます。
Splitting mode
データセットの分割方法を選択する。

- 行の分割
- 正規表現
- 相対表現
Fraction of rows in the first output dataset
入力データセットの行数に対する、最初の出力データセットの行数を表す比率を指定する。

Randomized split
行をランダムに選択するかどうかを指定する

Random seed
乱数生成器のシードを確認するための値を設定する。

Stratified split
各分割の行を層別カラムでグループ化するかどうかを指定する。

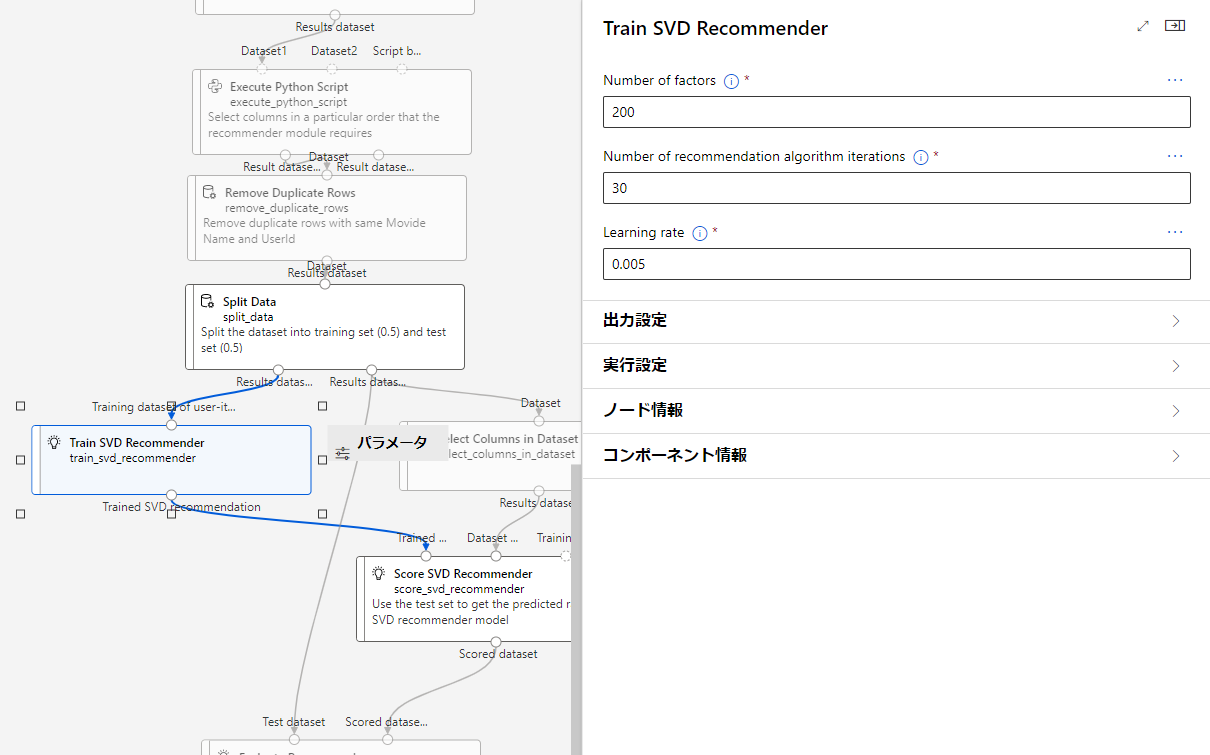
Train SVD Recommender
SVD Recommenderの検証データを作成します。
Select Columns in Dataset
データセット内のカラムを選択する
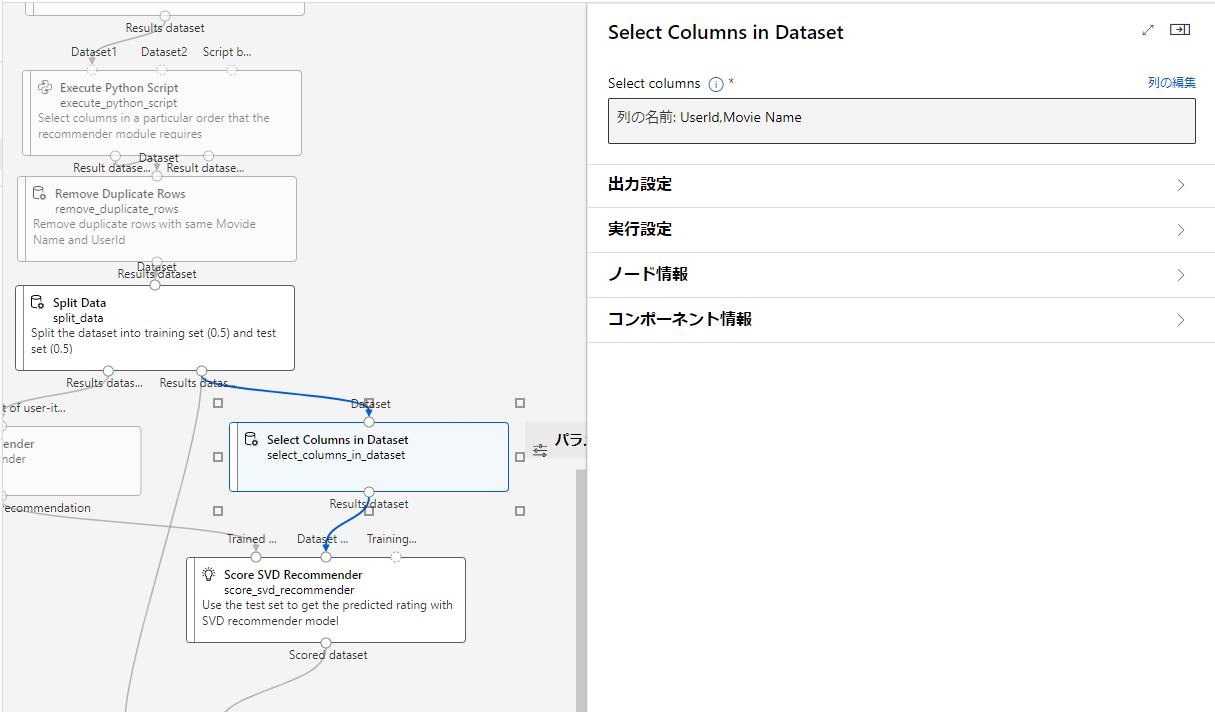
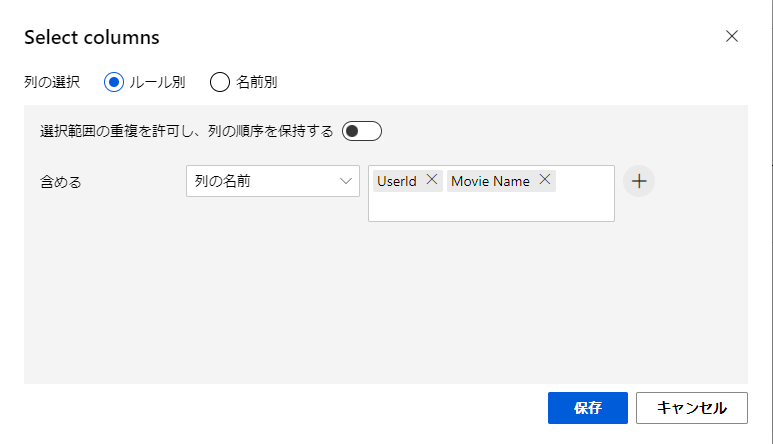
今回はMovide NameとUserIdを選択。
Score SVD Recommender
テストデータを使って、SVD Recommenderで予測される評価を取得する
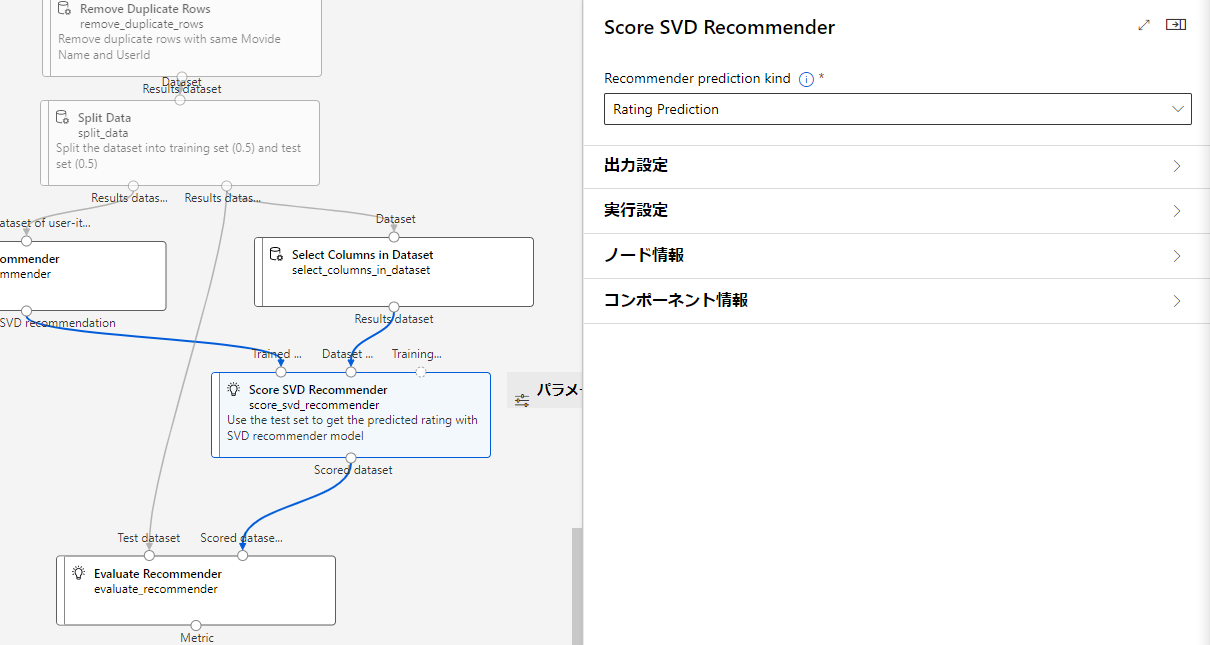
Recommender prediction kind
レコメンデーションが出力すべき予測の種類を指定する
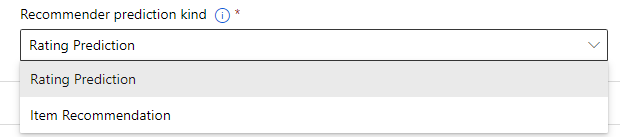
- Rating Prediction:評価の予測
- Item Recommendation:ユーザーへのおすすめ
今回は評価の予測をするのでRating Predictionで進めます。
Evaluate Recommender
Recommenderをモデルとして評価する。
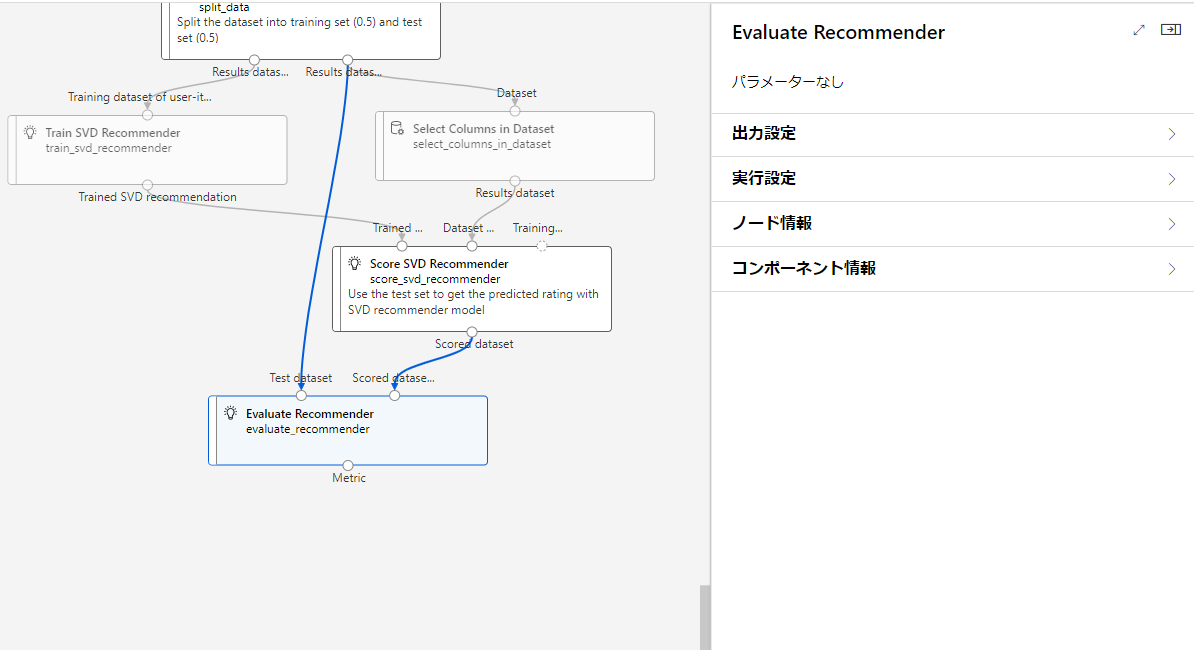
以上がブロックの説明になります。
前回に引き続き、こちらでリアルタイム推論パイプラインの作成をしていきます。
リアルタイム推論パイプライン
大枠は前回と同じ感じになっています。
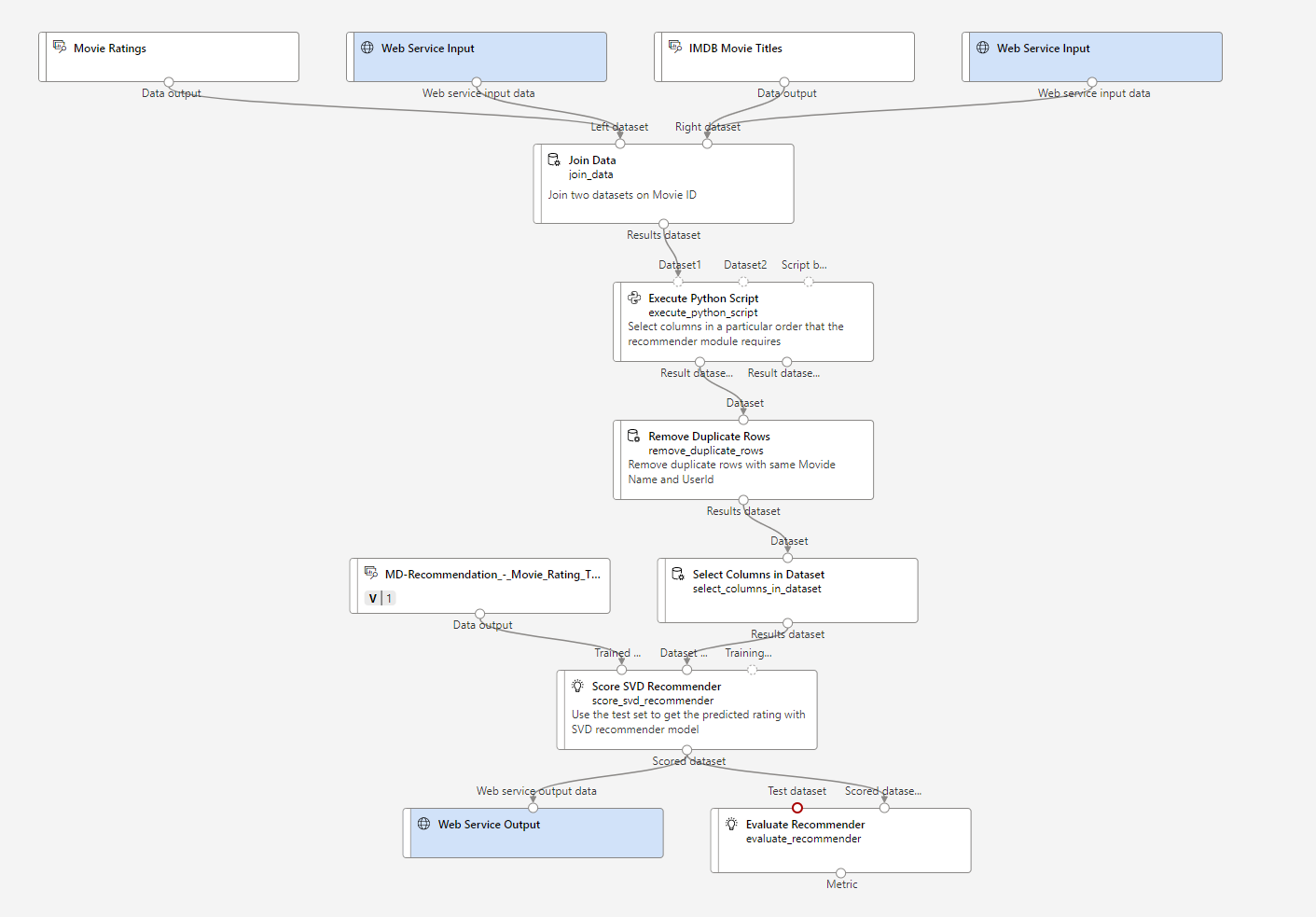
今回は作成するとエラーになってます。
エラーの内容としては、推論パイプラインにしたときに、Test datasetがどこからも参照されていないのエラーになります。
しかし、トレーニングの方はもともとのデータを分けてTest datasetにしていたので、今回はリアルタイム推論であり、Test datasetはリアルタイムで作成することになります。
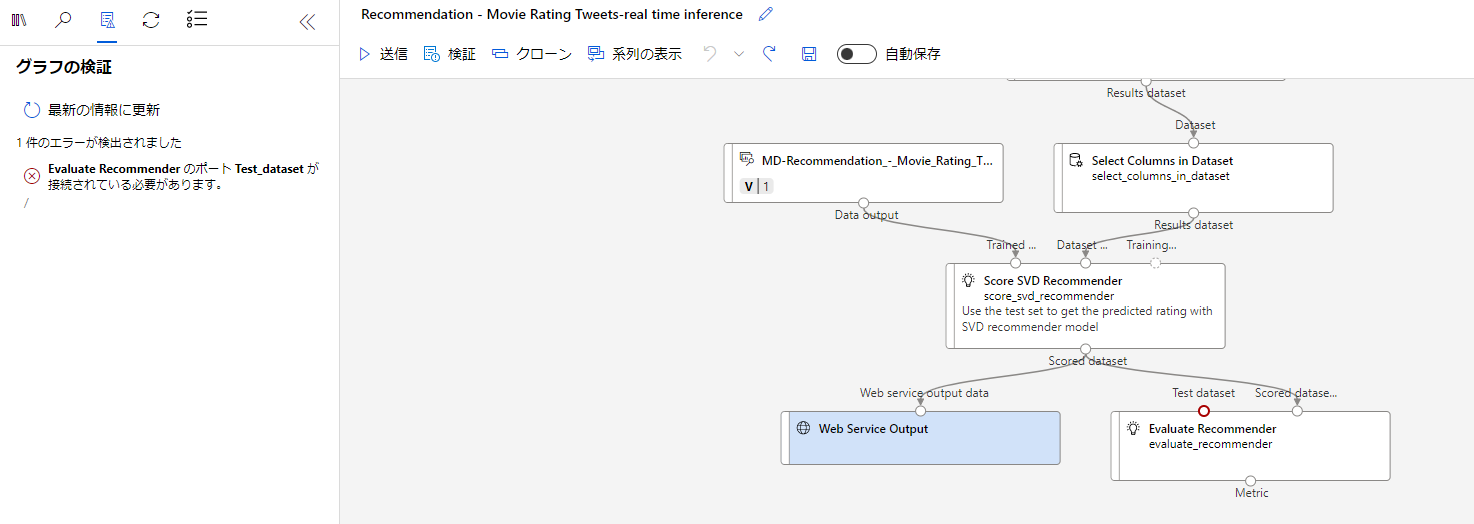
なので、Evaluate Recommenderは削除して、推論パイプラインを作成していきます。
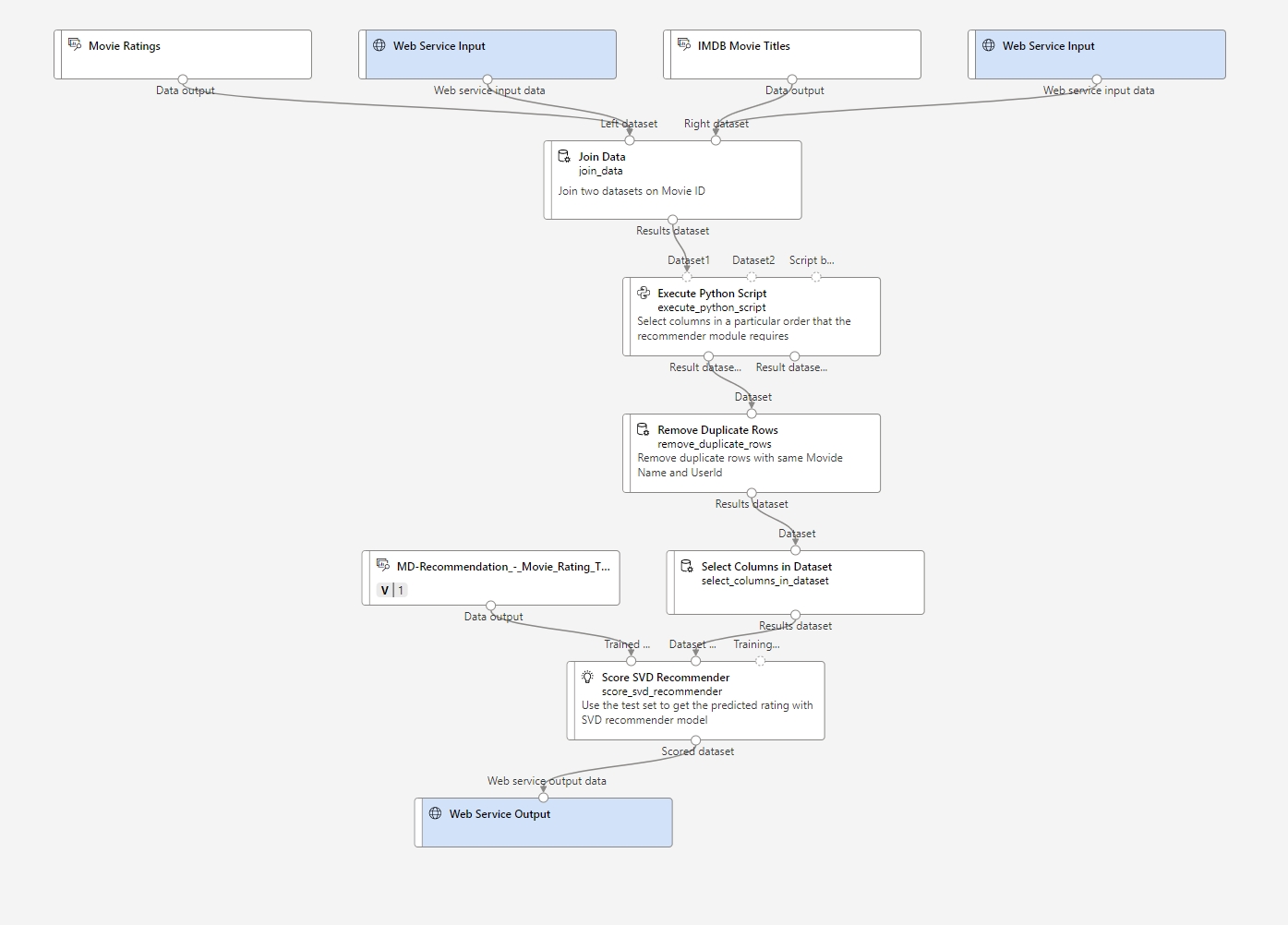
前回に引き続き、モデルが出来たらデプロイをして、テスト実行をしてみます。
テスト実行
そしたら、前回のようにテスト実行の画面まで行きます。
今回テストで使用するデータはこちらになります。
{
"Inputs": {
"WebServiceInput0": [
{
"UserId": 1,
"MovieId": 68646,
"Rating": 10,
"Timestamp": 1381620027
},
{
"UserId": 1,
"MovieId": 113277,
"Rating": 10,
"Timestamp": 1379466669
},
{
"UserId": 2,
"MovieId": 454876,
"Rating": 8,
"Timestamp": 1394818630
},
{
"UserId": 2,
"MovieId": 790636,
"Rating": 7,
"Timestamp": 1389963947
},
{
"UserId": 2,
"MovieId": 816711,
"Rating": 8,
"Timestamp": 1379963769
}
],
"WebServiceInput1": [
{
"Movie ID": 8,
"Movie Name": "Edison Kinetoscopic Record of a Sneeze (1894)"
},
{
"Movie ID": 91,
"Movie Name": "Le manoir du diable (1896)"
},
{
"Movie ID": 417,
"Movie Name": "Le voyage dans la lune (1902)"
},
{
"Movie ID": 628,
"Movie Name": "The s of Dollie (1908)"
},
{
"Movie ID": 833,
"Movie Name": "The Country Doctor (1909)"
}
]
},
"GlobalParameters": {}
}
このデータで一度テストボタンを押してみます。
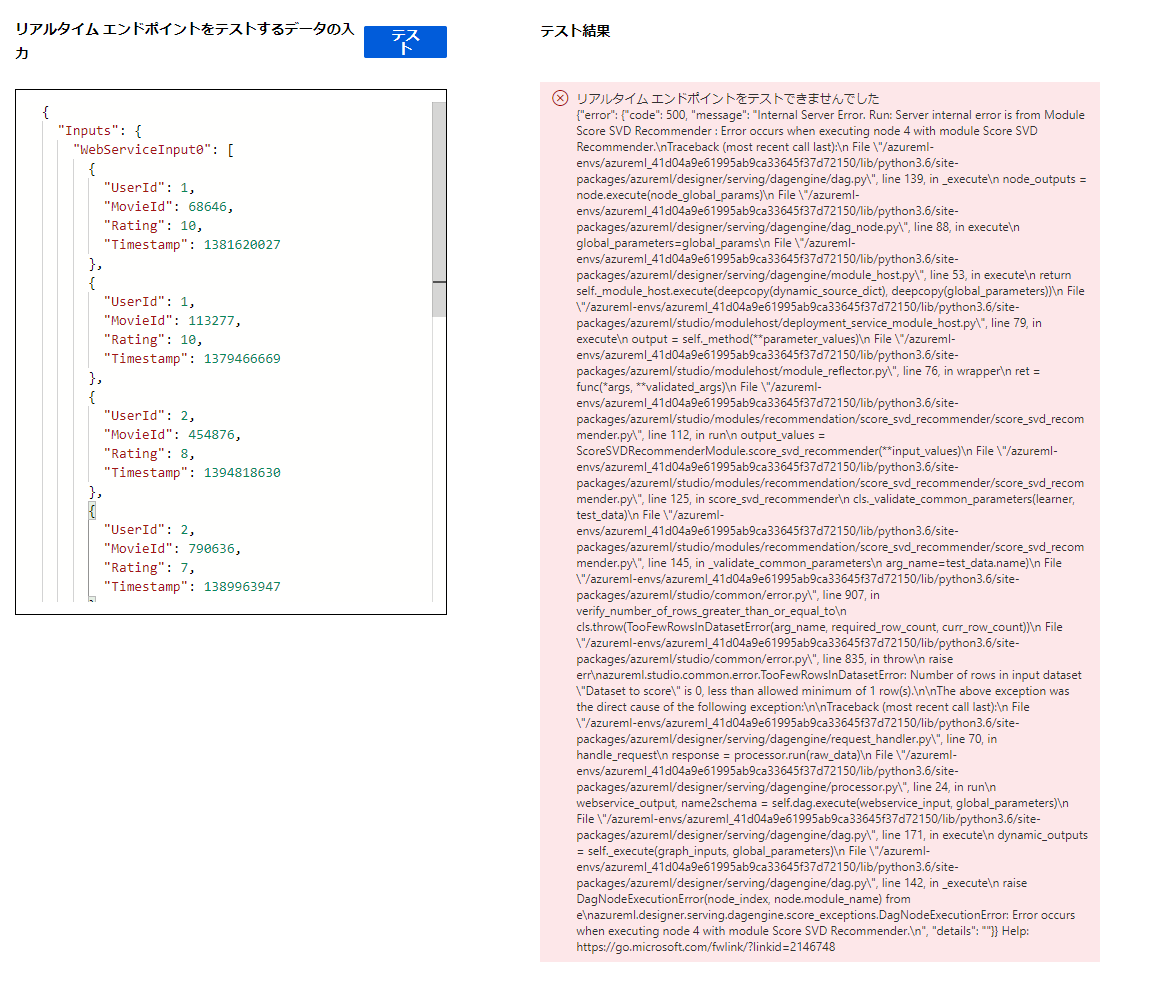
すると、エラーが出ます。
理由としては、上記のデータのWebServiceInput0のMovieIDと、WebServiceInput1のMovie IDが一致しないことによるエラーになります。
ブロックの時の処理でJoin Dataというのを行ってます。
そのため、MovieIDとMovie IDを一致させる必要があります。
今回は自分で分かりやすいように書き換えるだけにします。
{
"Inputs": {
"WebServiceInput0": [
{
"UserId": 1,
"MovieId": 1,
"Rating": 10,
"Timestamp": 1381620027
},
{
"UserId": 1,
"MovieId": 2,
"Rating": 10,
"Timestamp": 1379466669
},
{
"UserId": 2,
"MovieId": 3,
"Rating": 8,
"Timestamp": 1394818630
},
{
"UserId": 2,
"MovieId": 4,
"Rating": 7,
"Timestamp": 1389963947
},
{
"UserId": 2,
"MovieId": 5,
"Rating": 8,
"Timestamp": 1379963769
}
],
"WebServiceInput1": [
{
"Movie ID": 1,
"Movie Name": "Edison Kinetoscopic Record of a Sneeze (1894)"
},
{
"Movie ID": 2,
"Movie Name": "Le manoir du diable (1896)"
},
{
"Movie ID": 3,
"Movie Name": "Le voyage dans la lune (1902)"
},
{
"Movie ID": 4,
"Movie Name": "The s of Dollie (1908)"
},
{
"Movie ID": 5,
"Movie Name": "The Country Doctor (1909)"
}
]
},
"GlobalParameters": {}
}
そしたら、こちらのデータで実行してみます。
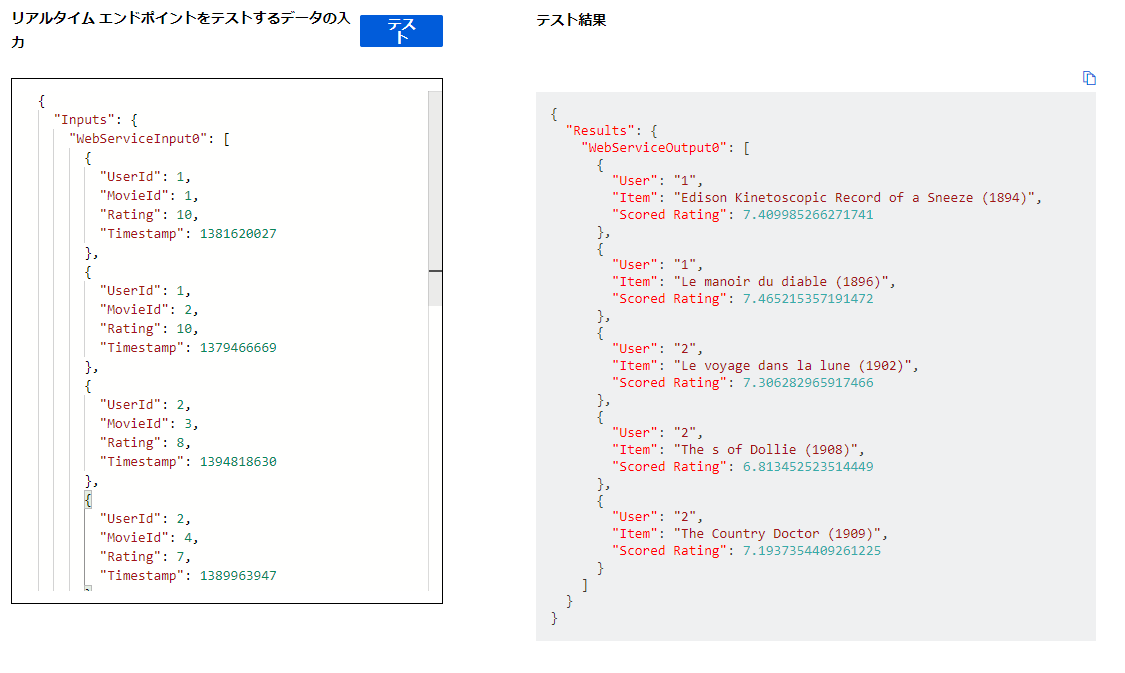
しっかり予測できました。
まとめ
今回は映画の評価の予測を行いました。
Recommender prediction kindを変更することで、おすすめの映画を出すことも可能なので、機会があればやりたいです。