はじめに
この記事では、Compute Shaderで並列化したソートアルゴリズム3種の要素数に対する処理時間を比較していきます。
比較するソートアルゴリズムは
- 奇偶転置ソート
- バッチャー奇偶マージソート
- バイトニックソート
の3種類です。また、発行するスレッド数、並列化処理の実装方法に一貫性がないため、正確な結果を提示するものではありません。その点を踏まえてご覧ください。
実際に計測に使ったプロジェクトはこちらになります。
https://github.com/Kuyuri-Iroha/gpgpu_sort_test
各ソートアルゴリズムについて
奇偶転置ソート (Odd–even sort)
奇偶転置ソートアルゴリズムは、バブルソートを改良したもので、下図のように繰り返し回数が偶数回か奇数回かで、比較入れ替えする要素のペアを1つ飛ばしに変えることで並び替えると言うものです。
今回実装したアルゴリズムは、るっちょさんに教えてもらった下図リンクのアルゴリズムを参考にして作成しました。
 引用:
引用:
ScriptとCompute Shaderの実際にソートを行っている部分のみを抜き出していますが、実装は以下の通りです。
C# Script
int count = 0;
for(int i = 0; i < pixelSize; i++)
{
sorterKernel.SetFloat("iteration", (float)i);
sorterKernel.SetTexture(kernelIndex, "src", buffers[count % 2]);
sorterKernel.SetTexture(kernelIndex, "dest", buffers[(count + 1) % 2]);
sorterKernel.Dispatch(kernelIndex, 32, 32, 1);
count++;
}
sorterKernelはComputeShader型のオブジェクトで、buffersはRenderTextureの要素数2の配列です。この2つのRenderTextureを使って値の入れ替えを行います。また、kernelIndexには予めComputeShader.FindKernel関数でインデックスを割り当てています。
Compute Shader
RWTexture2D<float4> src;
RWTexture2D<float4> dest;
float iteration;
bool IsEven(float x)
{
return fmod(x, 2) == 0;
}
float Rgb2Gray( float3 color )
{
return 0.299f * color.r + 0.587f * color.g + 0.114f * color.b;
}
uint2 IndexToCoord(uint inx)
{
return uint2(fmod(inx, 1024u), inx / 1024u);
}
[numthreads(32, 32, 1)]
void OddEvenKernel (uint3 id : SV_DispatchThreadID)
{
uint index = (id.x + id.y * 1024u);
float3 cCol = src[id.xy].rgb;
float c = Rgb2Gray(cCol);
int s = 1;
bool isLeft = (IsEven(iteration) && IsEven(index)) || (!IsEven(iteration) && !IsEven(index));
float3 lCol = src[min(uint2(1024u, 1024u), IndexToCoord(index + s))].rgb;
float l = Rgb2Gray(lCol);
float3 leftC = (index + s) < 1024u*1024u ? c < l ? cCol : lCol : cCol;
float3 rCol = src[max(uint2(0u, 0u), IndexToCoord(index - s))].rgb;
float r = Rgb2Gray(rCol);
float3 rightC = 0 < (index - s) ? r < c ? cCol : rCol : cCol;
dest[id.xy] = float4(isLeft ? leftC : rightC, 1.0);
}
isLeftで現在のピクセルが比較する側かされる側かを調べ、それに応じて比較を行っています。また、定数sで隣接ピクセルを抽出する際に範囲外に出てしまうことを防ぐための処理を挟んでいるため、少々煩雑になっています。
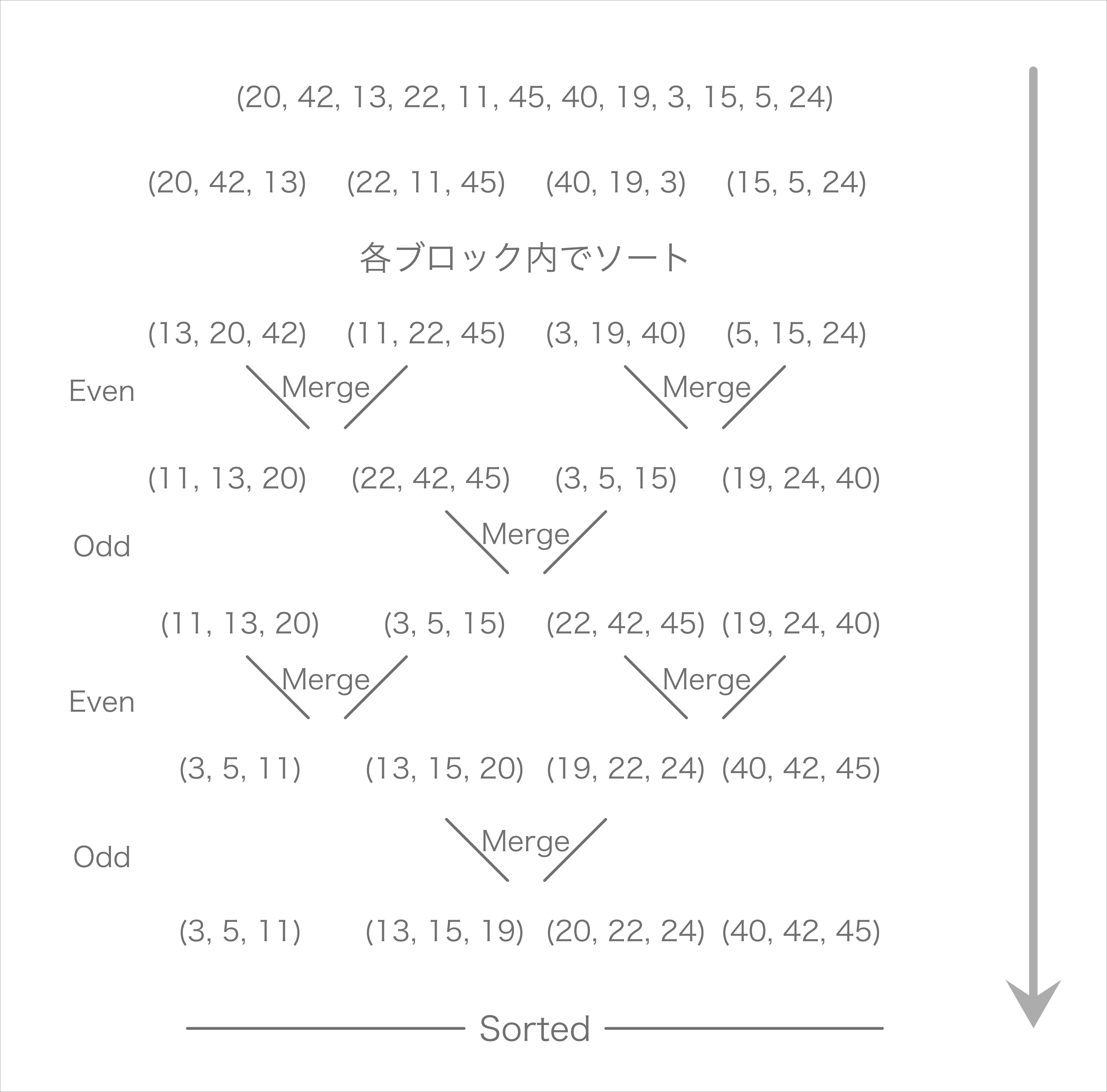
バッチャー奇偶マージソート (Batcher odd–even mergesort)
バッチャー奇偶マージソートはマージソートの並列可能版、と言う認識でいます。実際このアルゴリズムに関してはあまりちゃんとした理解をできていません。
処理手順としては下図のように行うと認識しています。ただ、ソーティングネットワークというものをこのソートを調べるときに初めて知り、未だにちゃんと読めていないのでなんとも言えないです…。
実装は今回、Compute Shaderをこの方のリポジトリから拝借して実装しています。
https://github.com/ref2401/oems
このコード内では、最初のブロック分割の部分を4つずつのブロックに分割して、各スレッドに均等に分配して計算しているみたいです。(そこまでしか追えていません…。)
C# Script
pixelBuffer.SetData(src.GetPixels());
sorterKernel.SetBuffer(kernelIndex, "g_buffer", pixelBuffer);
sorterKernel.Dispatch(kernelIndex, 1, 1, 1);
Color[] sortedPixels = new Color[pixelSize];
pixelBuffer.GetData(sortedPixels);
dest.SetPixels(sortedPixels);
dest.Apply();
sorterKernel奇偶転置ソートの時と同じです。お借りしたこのCompute Shaderは1次元配列としてデータを扱うので、そのための変換処理が入っています。pixelBufferはComputeBuffer型のオブジェクトで、pixelSizeがソートする総ピクセル数です。
Compute Shader
人からお借りしたものなのでここでの紹介は行いません。編集箇所として、ピクセルの輝度でソートするためにg_bufferの型をfloat4に変更。比較関数には奇偶転置ソートで使用したRgb2Gray関数を使用しています。
バイトニックソート (Bitonic sort)
このアルゴリズムは比較、入れ替えを行う組をビットシフトによって決定するものだと認識しています。正直このソートもあまり詳しくわかっていません。ただ、ソーティングネットワークは直感的にわかるくらい単純です。ただ、繰り返すごとに、2の累乗回で比較の方向が入れ替わるのがだいぶわかりにくいです。
正直、実装はわかるけどなぜそれでソートできるのかがわからない。という、バッチャー奇偶マージソートと逆の状況となってしまいました。
実装はhttps://qiita.com/aa_debdeb/items/e04aa08bcb9ff9be8e32を参考にさせていただきました。
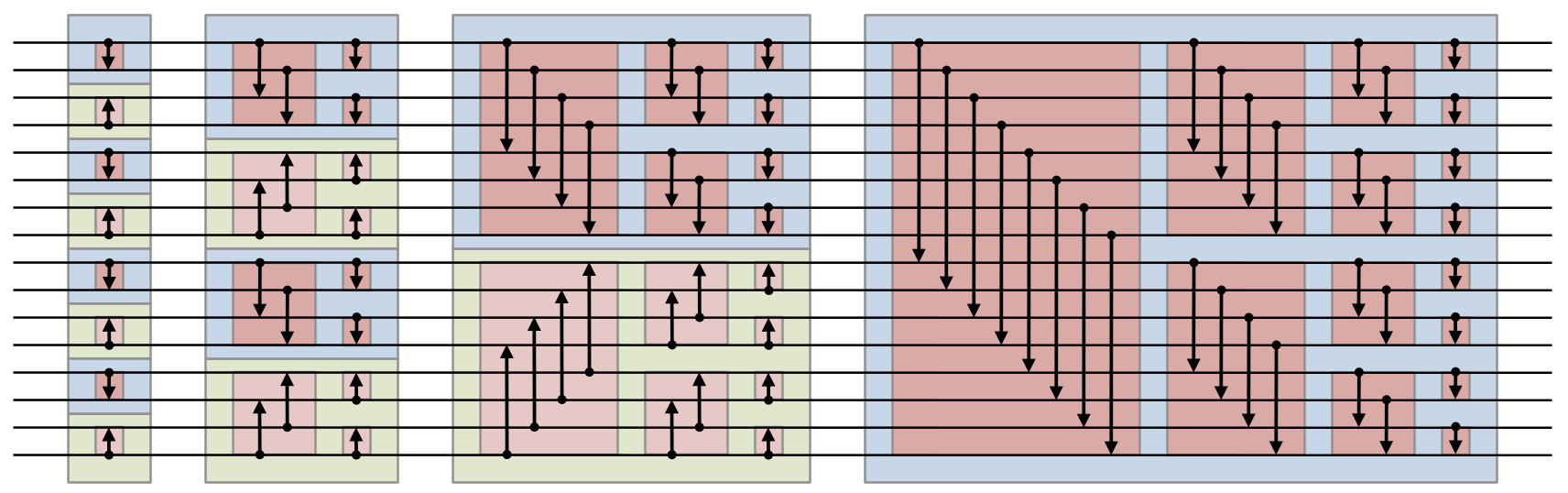
引用:https://en.wikipedia.org/wiki/Bitonic_sorter
C# Script
int count 0;
for(int blockStep = 0; blockStep < Mathf.CeilToInt(Mathf.Log(pixelSize, 2)); blockStep++)
{
for(int subBlockStep = 0; subBlockStep <= blockStep; subBlockStep++)
{
sorterKernel.SetInt("uBlockStep", blockStep);
sorterKernel.SetInt("uSubBlockStep", subBlockStep);
sorterKernel.SetTexture(kernelIndex, "src", buffers[count % 2]);
sorterKernel.SetTexture(kernelIndex, "dist", buffers[(count + 1) % 2]);
sorterKernel.Dispatch(kernelIndex, 32, 32, 1);
count++;
}
}
sorterKernelは他のソートと同様、ComputeShader型です。このコードのblockStepが先ほどの図の背景色が塗られたブロックと対応しています。CPU側でブロックとサブブロックを分ける処理を行い、GPU側で比較と入れ替えを行うという仕組みです。また、値の入れ替え方法は奇偶転置ソートの時と同じダブルバッファで行っています。
Compute Shader
RWTexture2D<float4> src;
RWTexture2D<float4> dist;
uint uBlockStep;
uint uSubBlockStep;
float Rgb2Gray( float3 color )
{
return 0.299f * color.r + 0.587f * color.g + 0.114f * color.b;
}
[numthreads(32, 32, 1)]
void BionicKernel(uint3 id : SV_DispatchThreadID)
{
uint index = id.x + id.y * 1024u;
uint d = 1u << (uBlockStep - uSubBlockStep);
bool up = ((index >> uBlockStep) & 2u) == 0u;
uint targetIndex = 0u;
if ((index & d) == 0u)
{
targetIndex = index | d;
}
else
{
targetIndex = index & ~d;
up = !up;
}
float a = Rgb2Gray(src[id.xy].rgb);
float b = Rgb2Gray(src[uint2(targetIndex % 1024u, targetIndex / 1024u)].rgb);
if ((a > b) == up || a == b)
{
dist[id.xy] = src[uint2(targetIndex % 1024u, targetIndex / 1024u)];
}
else
{
dist[id.xy] = src[id.xy];
}
}
コードの説明はhttps://qiita.com/aa_debdeb/items/e04aa08bcb9ff9be8e32に詳しく書かれていますので省きます。
比較実験
比較は簡単に行うために、UnityのEditor上で行いました。
実行環境は以下の様になっています。
OS: Windows 10
CPU: Intel Core i9 9900K
GPU: NVIDIA Geforce RTX 2070
Memory: 16 GB
この環境で各200回ソートを実行して、最初の50回分を除いた100回分の測定の平均を測定値とします。処理時間はUnityのTime.deltaTimeに1000をかけることでmsとしました。
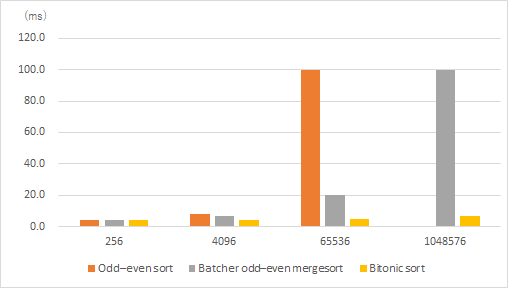
結果はこのようになりました。
| 256 | 4096 | 65536 | 1048576 | |
|---|---|---|---|---|
| Odd–even sort | 4.199 | 8.248 | 100.000 | |
| Batcher odd–even mergesort | 4.153 | 6.381 | 20.183 | 100.000 |
| Bitonic sort | 4.317 | 4.144 | 4.521 | 6.464 |
 |
||||
| 表の列がソートする要素数、列がソートの種類となっています。単位はmsです。また、Odd–even sortの要素数1048576はあまりにも処理時間が長かったため省きました。 | ||||
| 圧倒的にバイトニックソートが速いです。ですが、バッチャー奇偶マージソートだけだいぶオーバーヘッドが大きいので、それがかなり響いているかもしれません。 |
まとめ
- バイトニックソート
- バッチャー奇偶マージソート
- 奇偶転置ソート
この順番で処理時間が短いと言う結果となりました。しかし、要素数256の時は僅差ではありますが奇偶転置ソートが一番早かったので、要素数が極端に少ない時は奇偶転置ソートの方が高速なのかもしれません。
ケースバイケースの可能性を感じて素敵です。