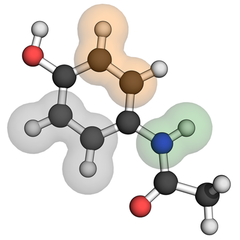
本日分子コンペがついに終わりましたので、自分の頭の整理を目的にツラツラと書いていきます。
そもそもKaggleとは?
機械学習分野のコンペサイトです。ざっくり言うとデータセットと評価指標が与えられ、期間内に誰が最も優れたモデルを作成できるかを競うものです。
※コンペによっては期間がないものもあります。
色々な人がKernel(要はソースコード)を公開してくれているので、Kernelを読むだけでも勉強になります。
また他の人のコードをForkして自分なりに改良して結果を提出できるので、「全然何したらいいかわからない!」という人でも簡単にコンペに参加できます。
Kaggleをはじめた時は、そもそも機械学習分野を全く分からなかったので、とりあえずコンペに参加してみてKernelをForkして、
自分で実行しながら何やってるの?をずっと勉強していまいした。
結果を送ると直ぐにPublic Leaderboardにスコアと順位がでます。自分が実施した改良がどのくらい影響があったのかなどもすぐにフィードバックを得ることができます。
何よりこの順位がすぐ出るという点が私は好きで、結構モチベーション維持に役立ってくれています。
コンペの概要
本コンペは、分子内にある原子間の相互作用を予測することが目標でした。
すでに化学分野ではこの計算する技術はあるものの、とにかく時間がかかる。PDCAを回すのがきついということもあり、より高速で信頼性の高い方法はないか?ということで本コンペが開催されています。
コンペには最終的に2755チームが参加しました。
最終的な結果
過去最高の37位で終えることができました。
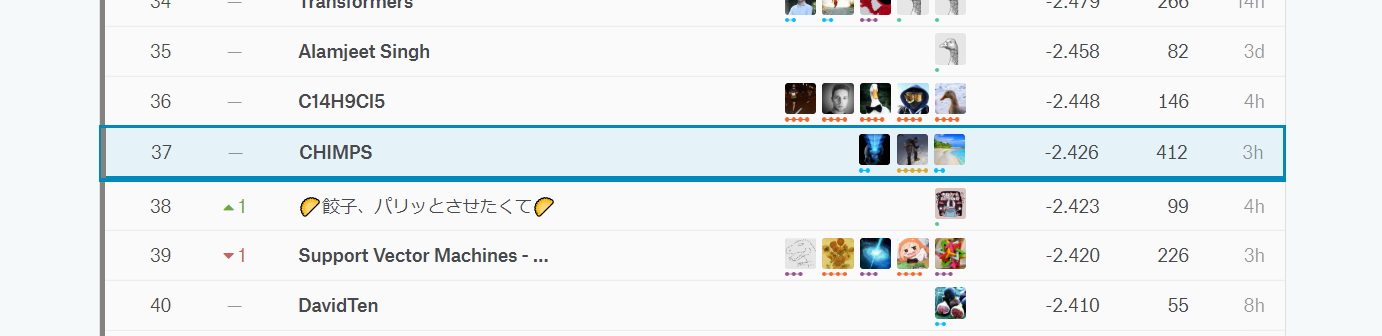
初めてチームを組みました。
異なるアプローチで出した結果のアンサンブルの有効性や、情報交換は有用だなと感じました。
チームメンバーからアドバイスをもらい、私が作成したLightGBMのモデルのスコアも-2.100(100位くらい)になりました。
もしもチームを組んでなかったら、ギリブロンズメダルに入るか?くらいの順位だったと思います。
コンペ参加から終わりまでにやったこと
以下は基本時系列にトピックを記載しましたが、厳密にはいくつかの工程を行ったり、戻ったりしながら進めていきました。
ドメイン知識取得
- 量子科学を専攻していた後輩に「これ何?」を教えてもらう
- とりあえず量子科学の本を買って軽く読んでみる
- Kaggle内のKernelでデータを色々と見てみる
特徴量を探索 - LightGBMのKernelをForkして、特徴量を追加してみる
- 毎日出てくるKernelとDiscussionを毎日眺めて、追加できない特徴量がないか探す
- 特徴量の重要度を出し、上位の200件の特徴量でモデルを作成・結果を出力する
環境構築 - 特徴量が増え、データサイズが大きくなりKaggle環境のメモリに入りきらなくなるので、GCPで環境を作る
チームを組む - 最後の3weekごろに、Matiasからダイレクトメッセージが来てチームを組むことになる
メンバーとの情報交換 - matiasが使っている特徴量を追加して再度学習する
Meta featuresの作成 - どうやらFCを予測したものを追加するとモデルの精度が上がることが分かったので、色々な特徴量の組み合わせでFCを作る
パラメータチューニング - BayesSearchCVでパラメータチューニングする
新メンバーがチームに加入 - Annaが新しくチームに追加する
アンサンブル - メンバー個々人の結果を重みづけも含め色々と試行してアンサンブルする
自分が作成したモデル
基本Public Kernelに書いてある流れとあまり変わりはないです。
データをKFoldで5に分けて、typeごとにモデルを作成するというもの。
以下に利用した特徴量を記載します。基本的にはPublic KernelやDiscussionにあった特徴量を追加。個人的なEDAで追加したのは原子間の距離とmulliken_chargeの積くらいなと。
特徴量(実際はもっとあると思いますが、覚えている限り)
- x,y,zから作成した2原子間の距離
- bond
- 2原子間の距離とmulliken_charge(Open Babelの結果)の積
- 各原子の近傍に存在する原子の情報(距離が最も近い正の原子上位5件、負の原子上位5件)
- meta feature(FC)
- Public Kernelで利用している特徴量(Giba等)
- ポイントとなる特徴量のAggregate
- QM9
- etc...
最終的なソリューション
ベースとしては、LightGBM、GNN(Graph Neural Network)、NN(Neural Network)の3つのモデルの結果をアンサンブルしています。
アンサンブルした結果のスコアは-2.426くらいとなっており、単体のモデルで最も強かったのはGNNで-2.3ありました。
最後に参加したAnnnaがGNNはコードを作成しており、このDiscussionを参考にして作ったとのこと。コードを見ましたが全然分からず…
ちなみに私の作成したLightGBMは-2.1くらいでした。
3つのモデルの結果だけでなく最後は結構泥臭い感じでアンサンブルした結果が伸びないかやっていました。
例えば、過去のちょっとスコアが低いものや、random_seedを変えた結果、あとはPublicに出ているKernelの結果など…
ソリューションとしては結構泥臭く、綺麗ではないです。
反省と今後
やっぱりGNNが強かったなと。
LightGBMが途中で伸び悩んだ時にGNNにも着手しようかと思ったのですが、「んーわからん!サンプル少ないし…」と思いやめてしまったんですよね。
まだまだ他のKagglerに依存した形でしか動けていないのが現状です。
この1年Kaggleを通して大体何をしなくてはいけないのか?はわかってきました。
現状の依存した状況から脱却するためにも、もっと自分で論文等の1次ソースを読み、実装に反映させていくことに今後取り組みたいと思っています。