背景
ある程度変更頻度が落ち着いてきた頃に、既存のコンポーネントを再利用したいようなフェーズがやってくる。
その際に考えられるいくつかのパターンについてここではまとめていく。
主な主軸は共有ライブラリなのか、共有サービスなのかのトレードオフ考察になる。
その前にそれぞれのパターンの個々の特性について触れていく。
注意事項
これは単に共有コードをソフトウェア上でどうするか?
という設計パターンに留まらず、再利用コードを担当するチームをどう配置するか?
その際に再利用コードを担当できるようなヒト系のリソーススキルは充分足りているか?
少しスキルアップすれば充分到達可能か?
といった今の組織構造という制約も込みで考えなくてはならない。
複数の非機能面の比較軸(組織的に実現可能なのか?も込み)において定性評価した上で、
最終的にどのパターンを適用するか?を考える。
前提知見
コンポーネントの凝集原則をそもそも前提知見として持っておかないといけない。
また
コンポーネントの凝集原則などを用いて、意味のある単位でまとめる。
さらにそれを
以下の3つのパターンのどれで再利用させるのか?
この大きく分けて2つのフェーズを考えられるようになることが、
今回紹介する3つのパターンを使いこなしている状態であると言える。
コードレプリケーション
これは非常にシンプルな設計パターンである。
単に再利用したいコードの塊を各サービスにコピーさせて持たせるだけである。
よって各サービスで再利用コードを共有していないことになる。
それによるメリットとデメリットを考えていこう。
メリット
各サービスがコードを共有しない
コピーして持たせているだけなので、まずサービスAの再利用コードに変更が入っても、他のサービスには影響しない。
独立性が担保されていることはメリットと言える。
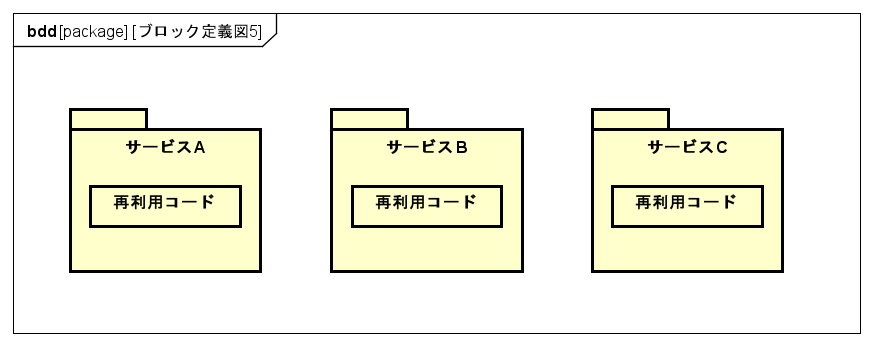
境界付けられたコンテキストを維持できる
独立性が担保されているので、各サービスは勿論コンテキストの境界を維持しやすい。
それによってチームトポロジーのインタラクションモードのような、
コラボレーションとXaaSを状況に応じて使い分けたりといった煩わしさから解放される。
この反面のデメリットは後述します。
デメリット
変更の適用の困難さ
サービスが2つ程度ならまだいいが、仮に再利用コードに変更が起きた際に、
その変更をすべてのサービスに適用しないといけないといった際には、サービスの量などに応じて困難になってくる。
概念そのものが重複しているのか? それとも別々に変更したいのか?
完全に別々に運用されてしまっている状況下では、再利用コードの名前すらも変えられてしまっているかもしれない。
すると、次の整合性の取りにくさにも繋がってくる。
整合性
下図において、サービスAの共有コードを変更し、仮にVer1.0→Ver1.1にしたとする。
そしてサービスBに関しては、Ver1.0→Ver1.2にしたとする。
こんな感じで独立して運用されてしまいやすいため、コンテキストの境界が明確に区切りやすいその代償として、再利用コードの整合性が合わなくなりやすい。
境界付けられたコンテキストの維持の代償ですね。
バージョニング管理の面倒さ
それぞれを独立性を持たせて運用する分にはいいが、
あとから各サービスの共有コードに整合性を持たせたいなどといった際には、
サービスの数が増えれば増えるほどバージョニングの管理などの面でめんどくさくなる。
どんな時に適しているか
書かれたらそれっきりで変更されないようなものであったり、
不具合や仕様変更リスクが非常に低いコードの塊である際には、
後述の共有ライブラリパターンよりもこちらの方が適している可能性が高い。
極論ではあるが、
再利用コードが絶対に変更されない安定したモジュールであり
かつ
再利用コードを使っているサービス内のコンポーネントがごく少数
であれば、私なら迷わずにこのコードレプリケーションパターンを適用する。
もちろん、各チームには不用意にその共有コードを使うコンポーネント数を増やさないように統制をはかった上で。
補足事項
チートポ的なお話をするとすれば、各種サービスに配置させる再利用を担当するチームが、
それぞれ別々に重複する形で配属される形がこのパターンの組織配置。
境界付けられたコンテキストを維持できる反面、途中で整合性を取りたくなった時などを想定し、横ぐしを指した横断的活動が再利用コンポーネントを担当するチームに求められる。
共有ライブラリ
概要説明
コンパイル時に、各サービスにバインドされるという特性上、
動かした後に障害が起きるという共有サービスパターンにはある問題がコチラにはない。
ただし、不必要なテストコストやデプロイ時のコストといったデメリットなどもある。
こちらの共有ライブラリは、コンパイル時にバインドされ、
共有サービスはランタイム時に結合させるため、
わたしは前者を静的な結合、後者を動的な結合と呼んでしまっている。
前提条件
共有ライブラリでは必ずバージョニング管理を行うこと。
後方Verとの互換性を担保したり、環境変化に素早く対応するためである。
理由はバージョニング管理されていなかったとしたらという状況を考えればいい。
ただし、バージョニング管理をすると今度は別の問題が出てくる。
メリット
ランタイムエラーを減らせる
ライブラリ技術では、共有コードはコンパイル時に統合されているので、
共有サービスのように実行時にエラーが起きるといった心配はない。
バージョンを変更できる
以下の図のように大きな粒度感でライブラリが凝集されてしまっていたとしたらどうでしょうか?
※共有ライブラリ内のC1~C5のコンポーネントは別々の理由で変更されると仮定します。
サービスAはC1、C2、C3を。
サービスBはC1~C5のすべてを。
サービスCはC1、C4、C5を使いたいとします。
また、C2とC3は同じタイミングで変更され、
C4とC5も同じタイミングで変更されると仮定します。
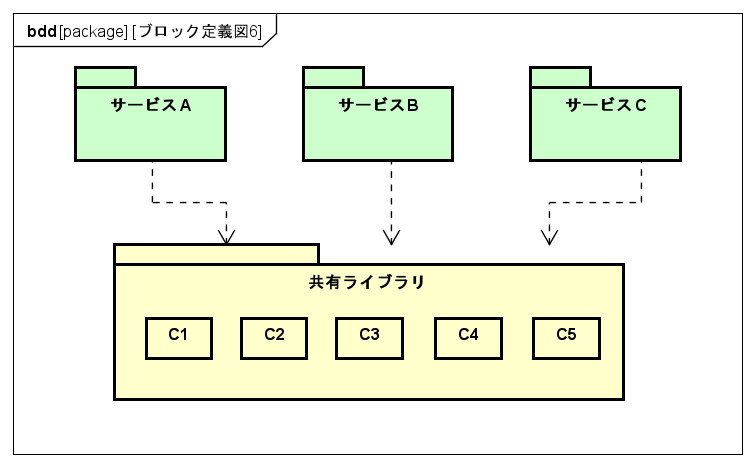
上図のように大きい粒度でまとめられていると、依存関係はシンプルでいいですが、
その一方で、C4やC5コンポーネント内のクラスファイルとかに変更が入った状況を考えるとどうでしょう?
あまりにも大きい粒度でまとめられているがために、共有ライブラリ全体のバージョンが古くなってしまい、共有ライブラリを使用する3つすべてのサービスが不要な再テストやデプロイを行わないといけません。
たとえば、サービスAやCは使っていないコンポーネントに変更が入った場合にも、
余計なテストとデプロイコストが発生してしまうのです。
これは共有ライブラリが、コンポーネントの凝集原則である、全再利用原則CRPに反した纏められ方であるがゆえに起こってしまうとも言えますね。
サービスAはC4、C5を使っていません。
サービスCはC2、C3を使っていません。
だからCRPに素直に準拠するなら、1つにまとめるべきではないです。
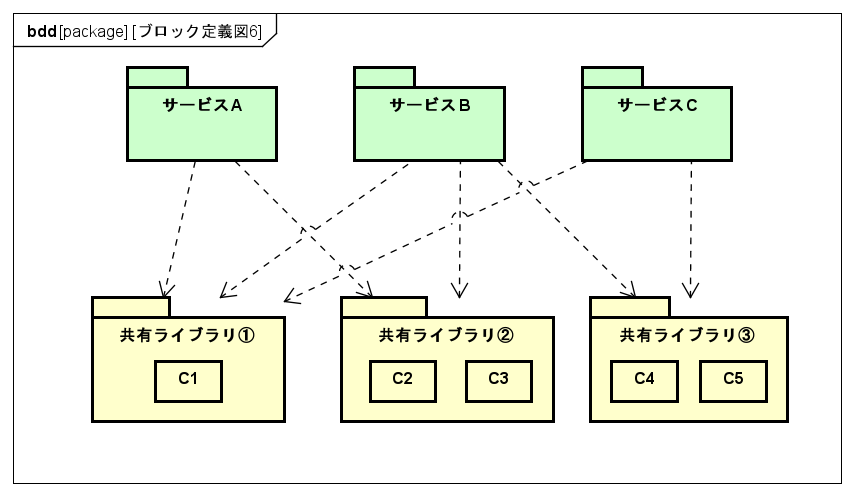
上図のように細かく分けてバージョン管理することで、不要なテストコストやデプロイコストを削減できます。
ただし別の問題点が浮上します。それについてはデメリットで触れます。
共有コードの変更に対する素早さ
これはバージョニング管理されているからこそである。
上図のように細かく分けて、変更点をバージョン管理することで、
不要なテストコストやデプロイコストを削減でき、その分の時間も浮くので、結果的に高いアジリティを維持しやすい。
デメリット
粒度調整による依存関係の管理
REP原則に則り、共有ライブラリの粒度を細かく分けることで、
共有コード部分に変更があった際に、アジリティを高められる一方で、
今度はそれによって下図のようにサービスと共有ライブラリ群との間の依存関係が煩雑になってしまう。
バージョニング番号と一貫させて細かく分割しているケース
細かく分割していないケース
上図の2つを比較すれば、依存関係の煩雑さの違いが自明であろう。
この図解では、まだサービスの個数や共有ライブラリ内のコンポーネント個数が少ないので
まだシンプルに感じるであろうが、
実際にはもっと個数が多く、細かくわけることでより煩雑になってしまう。
バージョンに廃止がめんどう
共有ライブラリの古いバージョンをサポートを打ち切る非推奨計画をたてるのが面倒であること。
すべての共有ライブラリを一律で適用する戦術的なバージョン廃止計画を立ててもいいけども、分けられたライブラリは基本的にそれぞれ異なる変更理由、変更速度で変更される。
なので、REP原則の考え方のように各ライブラリごとに非推奨計画を戦略的に考える方が妥当である。
ただし、そうすると今度は共有ライブラリごとの非推奨マネジメントするめんどうさがある。
バージョン変更時のコミュニケーションコスト
マイクロサービスは高度な物理的に分散型であるので、共有ライブラリのバージョンが変更された際に、変更を担当したチーム以外のチームに対して変更したことを伝えなくてはならない。
組織構造的な話
共有ライブラリパターンでは、ライブラリをメンテするチームを各種サービスを担当するチームに静的に混ぜるような感じで一体となっている感じ。
各共有ライブラリは自分を参照しているのが、どのサービスなのか?を認知負荷はかかるかもしれないが、把握しておける工夫が必要と感じる。
また物理的に近い距離にいる配置にしなくては、アーキテクチャとチーム間の距離に乖離が起きる。
通信を必要としないアーキテクチャなんだから、たとえばリモートでもoviceで常に近い距離感にいるようにするなど。
どんな時に適しているか
書かれたらそれっきりなどのように、ほぼ皆無に近いほど変更が入らない場合には、
上記のコードレプリケーションパターンが適していた。
この変更リスクポイントの評価はリスクマトリクス図で定性評価をすればいい。
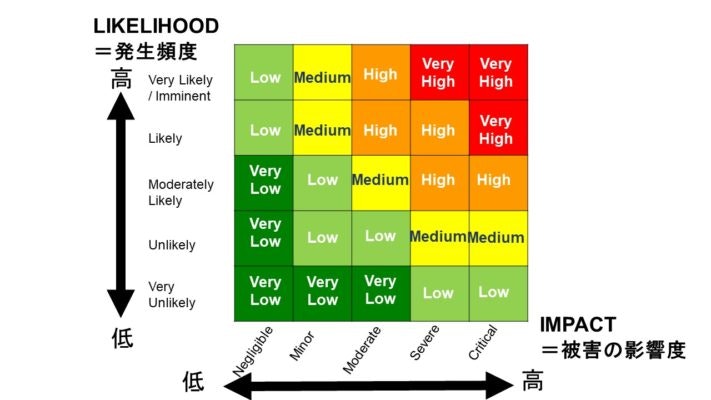
でも変更リスクポイントが極めて少なくはない~中程度(LowやMedium)であれば、
このパターンは適している場面が多い。
また
デプロイコストは気にしないが、パフォーマンスやスケーラビリティ、耐障害性に関して不確実さを無くしたい
といった際にもこのパターンは適している。
共有サービス
概要説明
共有コードのまとまりを意味のあるかたまりにして、別サービスとして配置する手法。
共有ライブラリは継承的な結合であるのに対して、コチラは委譲的な結合で共有する。
コチラは変更時のデプロイコストを削減できる一方で、共有ライブラリにはなかった様々な問題がある。
メリット
境界づけられたコンテキストの維持
静的なコード共有がない
共有部分を変更した際、共有サービス境界内に閉じること。
また動的なコード共有なので、変更時に
共有サービスを使用する他のサービスを再テストしたり、再デプロイしなくていい。
コードの重複が起きない
デメリット
バージョン変更が難しい
異なるコンテキスト境界として共有サービスが切り離されているので、
共有サービスを使う側のサービスからすれば、共有サービスに変更が入る度に、
そのAPIエンドポイントのバージョンが動的にコロコロと変えられてしまう。
そのため共有ライブラリに比べてバージョン管理は非常に面倒。
ランタイム変更による障害
共有ライブラリがコンパイルベースの変更なのに対して、コチラはランタイムの変更。
確かに共有サービスを変更しやすいものの、共有サービスへのちょっとした変更が
共有サービスを使用する全サービスをダウンさせてしまう可能性がある。

共有ライブラリでは実行前にエラーとか出てくれるが、コチラは実行するまでダウンするのかどうかが読めない。
パフォーマンス
共有サービスの場合には、サービス間通信があるため、ネットワークレイテンシーが全体のパフォーマンスに影響する。
また安全性を担保するためにセキュリティチェックを行うことで、そのレイテンシーも出てくる。
しかもそこがパフォーマンス面でのボトルネックにもなりやすい。
厳格なコントラクトのgRPCを使用することで、ネットワークレイテンシーは削減できるものの、今度はサービス間のコントラクトが厳格になってしまい、使い勝手悪くなるという問題点が出てくる。
セキュリティ
共有コードがサービスとして分離されている特性上、ネットワーク通信を行う部分で
脆弱性分析をしておく必要性がある。
コンパイル時にすでに統合しているわけでない、通信を介した動的結合ではここは気を付けないといけない。
コントラクトの設計をどうしようか?
厳格なものにするのか? それともいろんな利用者がアクセスしやすいように厳格でないコントラクトにするのか?ってことを考えないといけない。
スケーラビリティ
共有サービスパターンでは、それを使用する側のサービスのスケール感に合わせて共有サービス側もスケールしないといけない。
1つ2つのサービスから使われている場合くらいならまだいいけども、
いくつものサービスから共有サービスが利用される場合に関しては、スケール管理は非常にややこしいことになる。
耐障害性、可用性上の問題点
共有サービスがダウンしてしまった場合などには、それを使う他のサービスも動作を止めてしまう。
それに共有サービス自体に問題がなくても、ネットワーク通信が切れてしまうなどの問題がある。
あらかじめリスクポイントの高いカオス環境下を想定した状況での実験で、回復性をチェックしておくなどのことも考慮しないといけない。
組織構造的な話
共有サービスは、完全に違う部門として切り離されている所と連携するような物理配置。
ネットワーク通信を必須とするアーキテクチャなので、
この共有サービスパターンを使った場合には、サービス側(ストリームアイランドチーム側)は物理出社で、共有サービス側はリモートワークとか。
または違う階にいるとかっていうような配置にすることは可能である。
ただしそれは、事前に仮にネットワーク通信が切れるとか、
共有サービスチーム側に何らかの不具合(チームメンバーが全員欠勤したとか)
ていう最悪を想定した状況を事前に考慮した上で、代替案をいくつか担保した上で
やっても許される配置設計であると感じている。
ボトルネックになりやすい承認プロセス
部門の壁をまたいだ際に発生する【承認プロセス】。
共有サービスパターンでは、コンテキスト境界を超えた先との連携となるので、
当然セキュリティ上のリスク緩和のために、承認プロセスを行うことが多々ある。
しかし、LeanとDevOpsの科学などでも触れられているように、
この承認プロセスは全体の中でパフォーマンスを落とすボトルネックとなりやすい。
これは上記のパフォーマンスでも触れたことである。
もしも承認プロセスを走らせなくても、リスクポイントは低いようであれば、
いっそのこと承認プロセスを無くしてしまった方が良い。
↑ ECRS原則のEを適用
もしも承認プロセスを走らせないと危険というのであれば、共有ライブラリパターンに変えることを前向きに検討した方が良い。
どんな時に適しているか
複数言語や複数のプラットフォームを使うような環境や、
共有部分に頻繁な変更が入るような時に適しているパターンである。
ただしランタイム時の障害などのリスクポイントが不確実でないとか、低いといった場合と思っておいた方がいい。
両者の比較
トータルで見ると、共有サービスの方が考えるべきことは多々あり、
組織の設計スキルが成熟していないのであれば、共有ライブラリの方が無難であると感じている。一方そうすると依存関係の複雑さなどの様々な代償を伴う。
変更リスクという観点
共有ライブラリの場合には、共有コードに変更が入ると、それを使うすべてのサービスに対する変更の影響として、再テストや再デプロイのコストが起きてしまう。
細かく分けると上記で触れたように、今度は依存関係の管理が非常に面倒になってしまう傾向が高い。
対して共有サービスでは、変更が起きたとしてもその影響はそのサービス内に閉じているため、再テストや再デプロイのコストは削減できるし、依存関係もシンプルにしやすい。
ランタイム時の障害
ただし共有サービスにした場合には、ランタイム時に変更が反映されていることによって、
サービスダウンする可能性がある。
共有ライブラリではそのような心配はない。
テスト観点
共有サービスの場合にも、ランタイム時のダウンが不確実性高く、
それによるビジネスインパクトが読めないのならテストをする必要がある。
このテストコストといった観点も踏まえた上で、変更時のコストを考えた方がいい。
パフォーマンス
共有サービスではネットワーク通信と、セキュリティチェックレイテンシーが伴う。
共有ライブラリではコンパイル時に結合させるから、そもそもレイテンシーは存在しない。
スケーラビリティ
共有ライブラリでは、コンパイル時に使う側のサービスにバインドされる特性上、
スケーラビリティの面で懸念点を考える必要性はない。
しかしながら、共有サービスパターンでは、管理が面倒になりやすい。
学習コスト
上記を見てもらえれば分かると思うが、コードレプリケーションパターンと共有ライブラリの場合とは違い、共有サービスパターンの場合には、いろいろな運用特性の問題がある。
そのため、現在チームがそれらを必要十分に考えられるか?という組織能力的な制約を考慮した上で適用するものを選ぶ必要がある。