CQRS(コマンド・クエリ責務分離)の原則
書き込み(コマンド)と読み取り(クエリ)では、データに求められる品質特性
(パフォーマンス、一貫性、可用性など)が全然異なるため、両者を物理的に分離することは、ビジネス機会損失を避けるための戦略的な投資と言えます。

しかし、1つの物理的なDBで論理スキーマで明確に分けてってことも一応できます。
今回は、
論理的にスキーマで分けた場合
物理的に分けた場合
の2つのメリットとデメリット両方をじっくり見て見ましょう。
1. 論理スキーマで分離する場合(同一データベース)
書き込みモデルと読み取りモデルが、同じ物理データベースインスタンス内に、[
異なるテーブル群(あるいはスキーマ)として存在する構成です。(下図参照)
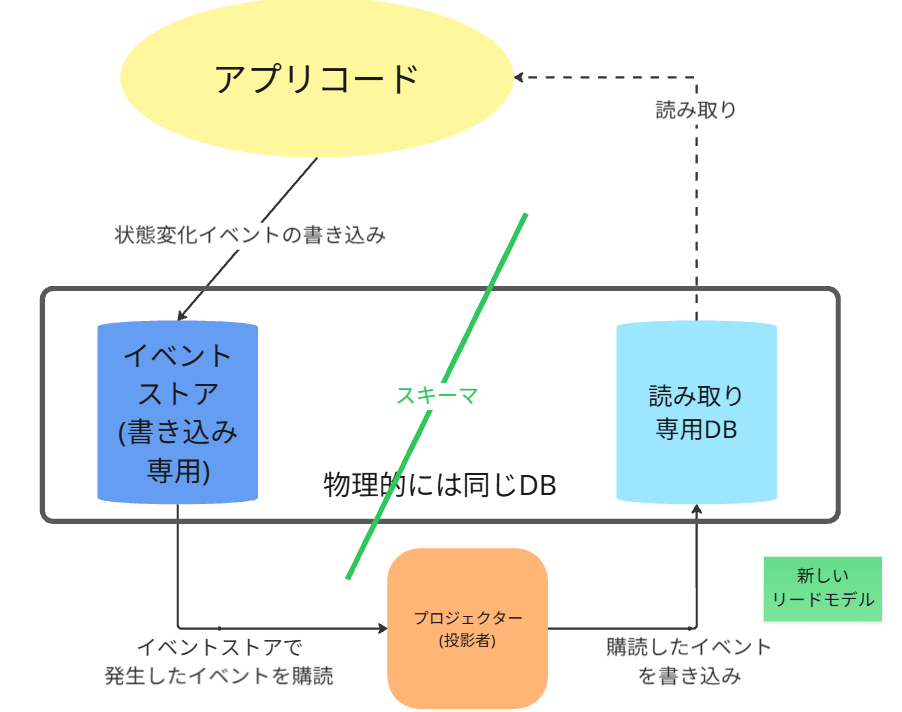
メリット
運用がシンプル
バックアップ、障害復旧、パッチ適用、監視、アクセス管理といった、データベースの運用ライフサイクル全体を、単一のポイントで管理できます。
これにより、運用チームの認知的な負荷と作業コストが大幅に低減されます。
強い整合性の維持が容易
同じデータベース内であるため、ACIDトランザクションの仕組みを利用できます。
単一のトランザクション内で、
・書き込みモデルのテーブルへのINSERT
・読み取りモデルのテーブルへのUPDATE
を同時に実行し、アトミックにコミットすることが可能です。
これにより、データのコマンド側とクエリ側の不整合が発生するリスクが低くなります。
低コスト
データベースのライセンス費用(該当する場合)や、サーバーインスタンス費用が一つで済みます。
また、コンポーネント間の通信がプロセス内で完結するため、ネットワーク転送コストも発生しません。
デメリット
パフォーマンスの競合
大量の書き込みが、読み取りのパフォーマンスを低下させたり、その逆が起きたりする可能性があります。
クエリ側はハイパフォーマンスで意思決定に必要な分析データが欲しいのに、
なかなか手元に来ないっていう事態になりやすい。
書き込み処理(コマンド)が多発すると、テーブルや行のロックが発生し、
読み取り処理(クエリ)が待たされる可能性があります。
逆に、分析系の重いクエリが実行されると、データベースのCPUやI/Oを占有し、
即時性が求められる書き込み処理のレイテンシーを悪化させるなど、互いのワークロードが干渉し合います。
スケーラビリティの限界
読み取りと書き込みを個別にスケールさせることができません。
もしシステムが読み取りヘビーな場合でも、書き込み側も含めたデータベース全体をスケールアップする必要があり、とても非効率。
スケールさせる方法は、より高価なサーバーに乗り換える垂直スケール に限られます。
システムの負荷割合が「読み取り9割、書き込み1割」といった場合でも、読み取りのためだけに安価なサーバーを複数追加する水平スケールといった、効率的な拡張戦略を取ることができません。
技術選択の制約
書き込みと読み取りの両方に、同じデータベース技術を使わなければなりません。
書き込みにはRDB、読み取りには検索エンジン、といったような特性に応じた使い分けができません。
書き込みと読み込みの求める品質のバランスのいい所のDBにするってことができたらいいけど、、、と思って調べたらヒットしたので、それも下で触れます。
2. 物理的に分離する場合(異なるデータベース)
書き込みモデルと読み取りモデルが、完全に別の物理データベースインスタンスとして存在する構成です。
メリット
独立したスケーラビリティ
これが最大のメリットです。
読み取り負荷が高い場合は、リードモデルのDBだけを安価なレプリカで何台もスケールアウトさせることができます。
書き込みと読み取りのワークロードの特性に合わせて、それぞれ独立かつ最適なコスト効率でスケーリングが可能です。
技術の最適化
書き込みと読み取り、それぞれの用途に最適なデータベース技術を選択できます。
例えば、
・書き込み側はイベントストアとしてApache Kafkaを
・読み取り側はリレーショナルなクエリ用にPostgreSQLを
・そして検索用にはElasticsearchを
というように、複数の異なるリードモデルを構築することも可能です。
パフォーマンスの分離
書き込みと読み取りのワークロードが物理的に分離されているため、互いにパフォーマンスの影響を与えません。そのため、性能が安定します。
耐障害性の向上
両者は異なる障害ドメインに属します。
リードモデルの検索インデックスが破損しても、
システムは新しい注文を受け付け続ける(書き込みは継続できる)など、障害が起きた際の影響範囲が限定されます。
ただし、同じネットワークセグメンテーションに配置した場合、
ネットワーク自体に障害が起きたら、異なる障害ドメインとは言えません。
離れた安定したネットワークセグメンテーションに配置したら、
それは今度は結果整合のレイテンシーを大きくさせてしまいます。
デメリット
運用が複雑
管理すべきデータベースの数が増えるだけでなく、両者を同期させるためのメッセージブローカー(Kafkaなど)や投影者(プロジェクター)といった、新たなコンポーネントの運用も必要になります。
これにより、システム全体の構成が複雑化し、運用チームにはより高いスキルが求められます。
結果整合性
これが最大のトレードオフです。
書き込みが行われてから、それがリードモデルに反映されるまでに必ず遅延が生じます。
これにより、「Read-Your-Writes問題」が発生する可能性があります。
アプリケーションやUI/UXは、このデータの非同期性を許容するように設計されている必要があります。
高コスト
複数のデータベースインスタンスや、メッセージブローカー等の追加コンポーネントが必要になるため、インフラコストは一般的に高くなります。
両者のバランスの良いどころ
書き込み(OLTP)と読み取り(OLAP)の両方のワークロードを、
単一のデータベースで効率的に処理しようとするアーキテクチャや製品群を、
HTAP(Hybrid Transactional/Analytical Processing) と呼びます。
HTAPとは
これは、CQRSのように書き込みと読み取りのデータベースを物理的に分離するのではなく、
一つのデータベース内で両方のワークロードを共存させることを目指す技術です。
仕組み
多くは、高速な書き込みを得意とする行ストアと、高速な集計・分析を得意とするカラムストアの両方のエンジンを、一つのデータベース内に実装しています。
トランザクションデータが書き込まれると、それがリアルタイムで分析用のカラムストア形式にも複製・変換される、といった内部的な仕組みを持っています。
代表的なHTAPデータベース
・SingleStore (旧MemSQL)
・TiDB
・SAP HANA
・CockroachDB
また、PostgreSQLやMySQLといった従来のRDBも、拡張機能によってHTAP的な能力を高めています。
ただし、トレードオフは存在する
HTAPは多くのケースで有効ですが、CQRSによる物理分離が持つメリットを全て代替できるわけではありません。
これは 「シンプルさ」と「完全な最適化」のトレードオフ です。
HTAPが優れる点:シンプルさと即時性
管理するデータベースが一つで済むため、運用は圧倒的にシンプルになります。
結果整合遅延がない
書き込まれた最新のデータに対して、即座に複雑な分析クエリを実行できるという大きな利点があります。CQRSで問題になる「結果整合性の遅延」は発生しません。
CQRS(物理分離)が優れる点:完全な最適化と分離
HTAPは、あくまで一つの製品内で両立を目指したものです。
書き込みの性能だけを極限まで追求したイベントストアや、
検索性能だけを追求したElasticsearchのような、それぞれの用途に特化した最高のツールには、個別の性能で劣る可能性があります。
物理的に分離されていないため、リソースの競合が起きる可能性は残ります。
また、書き込み側と読み取り側を独立してスケールさせるといった、柔軟なスケーリング戦略も取りにくいです。
HTAPの結論
HTAPは
「ある程度の規模までシンプルさを維持しつつ、リアルタイム分析も実現したい」
というデータへの要求に対する、非常に強力でバランスのいい解決策です。
しかし、極端な性能やスケーラビリティが求められる場合は、CQRSによる物理分離の方が、より最適な選択となることがあります。
ようは、求められるデータの品質がすべてを決める
データメッシュ化の準備段階となる
最後にもう1つ、コマンドとクエリを物理分割する他の視点での恩恵について。
コマンドクエリモデルを物理的に分離しているマイクロサービスは、その特性からデータメッシュ化する際に、他のアーキテクチャに比べて、以下のような絶大な恩恵を受けます。
わたしが、物理分割をすすめるのは、ぶっちゃけこれが最大要因です
1. 「ドメインオーナーシップ」の素地が形成されている
CQRSの時点
書き込みモデル(コマンド)と読み取りモデル(クエリ)の両方に責任を持つチームは、
事実上、そのビジネスドメインのデータのライフサイクル全体を管理しています。
データメッシュへの恩恵
これは、データメッシュの第一原則である 「ドメインによるデータオーナーシップ」 の考え方を、すでに実践していることに他なりません。
そのチームが、そのままデータプロダクトのオーナーとしての役割を担うことができます。
2. 「リードモデル」が「データプロダクト」のプロトタイプになる
CQRSの時点
リードモデルは、特定の参照(クエリ)用途のために、消費者が使いやすいように最適化・設計されたデータストアです。
データメッシュへの恩恵
このリードモデルは、まさにデータメッシュが定義する 「Data as a Product」 の考え方を具現化したものです。
すでに消費者(他のサービスやBIツール)を意識して設計されているため、このリードモデルをより公式な「データプロダクト」として公開・提供するまでのステップが非常にスムーズです。
3. 「非同期連携」「結果整合」の経験が活きる
CQRSの時点
書き込みモデルから読み取りモデルへのデータ同期は、多くの場合、
イベントを介した非同期プロセス(プロジェクター責務) によって実現されています。
データメッシュへの恩恵
この非同期連携の経験は、データプロダクトをイベントストリームとして公開したり、他のデータプロダクトを購読したりといった、データメッシュで中心となる技術パターンに直接活かすことができるはずです。
結果整合性に伴う課題についても、チームはすでに対応策を経験済みです。
結論
CQRSで物理分離を実践している組織は、データメッシュが求める技術的・組織的な思考様式の大部分をすでに獲得しています。(スキル的にも)
そのため、そうでない組織に比べて、データメッシュへの移行を、遥かに低リスクかつスムーズに進めることができます。
まとめ
とまあ、長々と書き綴ってきたんですが、私個人としては、物理分割をお勧めします。
ただ、求められるデータ品質がそもそも、バランスなのであれば、HTAPでもいいでしょう。
その代わり、早期に大事なデータ品質が何なのか?を特定に努めてください。(下の記事参照)
顧客の求めるデータ品質の中でも、変わりにくい部分はあるはずです。
そこを早急に探し当てて、そのデータ品質を満たすには、上記のどれがもっとも妥当なのか?を複数のデータ品質評価軸で多角的に評価してみてください。
次回は、物理的に分かれている前提で、
コマンド・リードモデルを同期連携する場合と非同期連携する場合の両方を見ていきます。