背景
ソフトウェアアーキテクチャハードパーツを読んだ流れで、メトリクスのことについても関心が強くなったので、メンバーを集めて少人数でアーキテクチャメトリクスのワークをやってきた。
この本は、機能面だけでなく、運用面の非機能系にてどの程度の定量指標なら今の設計やアーキテクチャが妥当か?といったことを定量評価するための適応度関数についてだけでなく、Findyさんで有名なFour Keysについても触れられている。
主張
個人的には10章から読んでみた方が楽しめると感じている。
理由はGQMアプローチに関する思考が、網羅された内容が書かれており、
この章だけ単体でも相当な学習になるだけでなく、メトリクスを採取するのに、
どのようなデータが必要か?などを構造化して考えるための思想が書かれているからだ。
GQM(+D)ワークショップ
書籍の最終章でこのGQMについて触れられている。
G=ゴール
Q=ゴール達成を計測するのにどんな質問に答えられていればいいか
M=質問に回答するにはこんなメトリクスの組み合わせ
D=メトリクス可視化のために必要なデータ
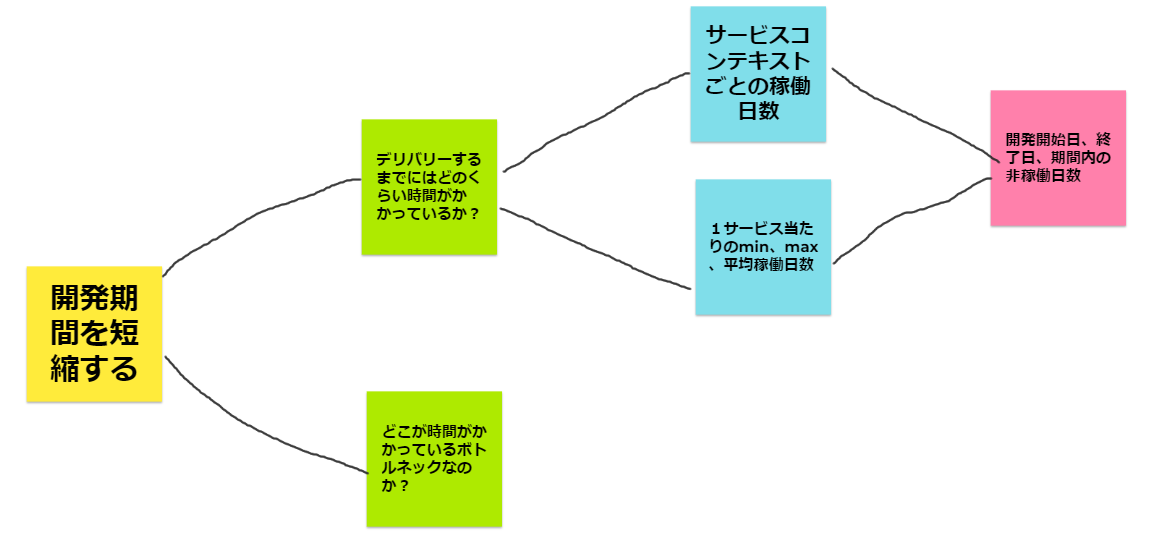
黄色付箋がゴールであり、緑が質問、ブルーがメトリクス、ピンクがデータ。
右に行くほど詳細になっており、左へ行くほど上位目的になっている。
関心の分離
この時、目的と手段という関心の分離を徹底し下位を気にしてはならないです。
どういうことかというと、ブルーのメトリクスのことを考えている際には、
それをどんなデータで実現できるか?を考えないということです。
上位目的に依存
さらにクリーンアーキテクチャなどにある、より安定した抽象概念に依存せよ
という思想にのっとり、CQM+D(データ)の依存関係の向きは、
G ← Q ← M ← D を守りましょう。
SLAP原則を意識
メトリクス1つとっても、粒度の揃っていない状態では、
あるQに紐づくメトリクスが具体的なものもあれば、曖昧なものもごちゃまぜになっていて
なんてことに繋がります。
曖昧なメトリクスということは、それだけ粒度の大きい可能性があります。
分解して他のメトリクスと粒度をそろえてあげましょう。
適切な粒度は、その後に出すデータのリストが明確になる程度です。
ループバックチェック
常にループバックチェックを以下のように行い続けましょう。
Gのために必要十分なQがそろっているか?
Qのために必要十分なMがそろっているか?
Mのために必要十分なDがそろっているか?
をチェックするのです。
ここをないがしろにすると、情報の【完全性】を考えたいときに路頭に迷いやすくなります。
上位から下位へのトップダウン
まず図でいうG(ゴール)である、
「開発期間を短縮する」をチェックするためには何が必要か?
から、
・「デリバリーするまでにどのくらいの時間がかかっているか」
・「どこが時間のかかるボトルネックなのか」
などなどをトップダウンで洗い出します。
図で描いているものは簡単のためにサンプルで描いたものなので、
実際にGをかなえるためのQが必要十分にそろってるか?といったことは考えていないです。
下位から上位へボトムアップ
・「デリバリーするまでにどのくらいの時間がかかっているか」
・「どこが時間のかかるボトルネックなのか」
これらのQがすべてそろっていれば、Gゴール達成したのかどうか
が十分に評価でするか?
注意事項
たまにこのGQMストラクチャーを更新することをさぼったがために、
完全性がどんどん低下するような案件を見かけました。
このGQMストラクチャーは一回定義して終わりではありません。
必ず、
・必要と思われていたデータを集めるのに非常にコスト(時間的なコスト含む)がかかり、
迅速な意思決定するためにはなかなか難しい。
または
・より安価に運用できるデータが見つかった。
ということが開発環境、もしくは運用環境にて判明したら、更新する必要があります。
これはMとDのところだけではなく、ほかの階層においても言えることです。
下位の実現可能性や制約を上位にフィードバック
たとえばピンクの付箋のデータ、これが仮に採取するのに
めちゃくちゃ恩恵よりもコストがかかってしまうと仮定しましょう。
そうしたら対象のメトリクスは価値よりもコストの方がかかるということだから、
妥当なメトリクスではないということになります。
そのメトリクスがかけることによって、そこと紐づく上位のQが十分なメトリクスではないとなり、
同時にそれに伴って、そのメトリクスの上位概念であるQも達成できたかの確認ができないということになります。
検証容易かどうかという観点
何度も更新の入るGQMストラクチャーであるからこそ、
最初に定義する際にも、更新する際にも、常に人が一貫性を検証しやすいか?
という観点をもってして描きましょう。
メトリクスに必要なデータを思い描くことができない
もしくは
ディスカッションに参加した人によってメトリクスを構成するデータの案がバラバラ
もしくは
メトリクスの優先順位についての議論で悩んでしまう
という状況に遭遇したら、
まだ対象のメトリクスがあいまいさを残している可能性が高いです。
明確なゴールからのストラクチャーが描けているのなら、
優先順位もどんなデータがあるべきか?も容易に思い描けるし、認識のずれも起こりにくいです。
では、そんな明確なゴールやメトリクスを定義するために心がけるにはどうしたらいいでしょうか?
ワタシから個人的に1つおすすめのある法則を紹介します。
SMART法則
SMART/スマートの法則は、ビジネスマネジメントの専門家であるジョージ・T・ドラン氏によって提唱された目標設定のためのフレームワークです。
SMARTは、
・Specific(具体的な)
・Measurable(測定可能な)
・Achievable(達成可能な)
・Relevant(関連性のある)
・Time-bound(期限が明確な)
の頭文字から来ています。
またこれを意識したKGIが定義されているからこそ、業務プロセスのそれぞれの達成目標であるKPIがデザインできます。
セットで使う理由
書籍では触れられていませんが、GQMストラクチャーはこのSMART法則と照らし合わせると
非常に相性のいいものになってます。
G(ゴール)をこのSMART法則に従って明確に定義しないと、
そのあとのQ以降があいまいな状態でしか浮かび上がりませんし、
そのゴールに対して、妥当なQなのか?や必要十分なQがすべて洗い出されてるか?
といった検証も容易にはできなくなります。
なのでセットで使うことを私はマストにしています。
もしもまだGQMワークショップを行った回数が少ないとかで、
データまでの一気通貫モデルを作成するのに時間がかかるとかであれば、
是非ともこのSMART法則を意識したゴールなどを定義することを意識してみてください。
かなりその効果を実感できると思います。
ではSMARTのそれぞれの項目内容に触れていきます。
それぞれ単独で使用するようなモノではなく、セットで組み合わせて使用します。
Specific(具体性)
目標設定は具体的に行う必要があります。
これはメトリクスの定義においても同様です。
明確さのないあいまいなメトリクスのままでは、それを実現するためのデータのリストは考えることができません。
なんとなくで「こんな感じのデータの集合じゃない?」とデザインされたものになってしまいます。
特にG(ゴール)を定義する際にはこの具体性が非常に求められます。
なんとなくでデザインされたGQMストラクチャーでは対して恩恵のないデータが定義されてしまいます汗
Measurable(計量性)
Measurableは「測定可能か」という意味で「目標の達成度が測れるか」という基準を表します。
あいまいな目標の場合、もうその時点でどの程度達成できたかがわからず、
方針の軌道修正をした方がいいのかどうなのかさえ判断がつきません。
私の中では、この計量性は特にQ(質問)で特に意識させられるものです。
ゴールをで明確に定義し、この達成度合いがわかるからこそ、
各スプリントレビューなどで小さいミクロなレベルでの軌道修正をした方がいいのか?
といったもろもろの判断が下せます。
Achievable(達成可能性)
Achievableは「実現可能な」という意味で、「達成可能な目標か」を基準にして目標を考えます。
これはデータのリストまで洗い出したうえで、下位からのフィードバックをかける際に
特に意識して考えるべきものになります。
もちろんデータまでのストラクチャーを考えなくても、
メトリクスのリストを洗い出した時点でおおよそのコストなどの制約がわかるのなら、
その内容をもとに上位概念へ反映させます。
要件定義においてもこの達成可能性を意識した定量指標の定義をしたか
どうなのかでその後の設計工程などの質が変わります。
どう考えてもチームで無理な目標を設定してしまうと、残業や目標に届いてない低品質状態で納品ということにもつながりかねません。
それは開発者たちが体験するプロジェクトというコトの品質劣化にもつながります。
またこの考え方は、顧客の期待値捜査の際にも意識して行う必要があります。
特に受託などの場合、現時点での自分たちでは達成できそうにないけれど、
そのプロジェクト期間中で自分たちが成長すれば十分届きそうな目標であれば、
顧客への期日までの納品も可能であるため信用の継続にもつながり、
かつ プロジェクトを通しての開発者たち自身が成長を実感できるという
わくわくした【開発者体験】、プロジェクトというコトの品質にも繋がってきます。
Relevant(関連性)
目標を達成することで、「何が生み出されるか」「自分にどのような利益があるのか」
という関連性がどの程度明確か?
ワクワクするような目標の設定がされていないと、
ステークホルダーたちはなかなか協力的にはなってくれないです。
そのためにも各ステークホルダーにとっての価値とゴールとの間に関係性があることを示さなくては、そのステークホルダーたちにいくら呼びかけても無駄です。
この目標を達成できると → あなたにとってこんな価値が実現できる
この要件指標を満たすと → あなたのこの要求を実現できる
といった関連性を描けないと、どのデータや 要件を優先度高く考えないといけないか?
といったことも考えようがないです。
また指標がMeasurable 計測できていることによって、
要件の指標を増加させた際に、要求を満たせている度合いが向上し、
対象のステークホルダーの喜びが増加しているか?を検証できる。
もしも増加していないのなら、その要件にコストを使う意味はないと証明できたことになる。
ここでは詳細な説明を端折りますが、価値駆動で考える匠メソッドの思考プロセスを用いて、ステークホルダーの価値と各メトリクスやデータとの繋がりを描いておくと、どのようなデータをどの程度の品質で保存しておかないといけないか?が明確になりやすいです。
補足事項
ちなみにこのRelevant(関連性)に関しては、
各事業がこのGQMストラクチャーを使ったゴール指標が明確に定義されており、
キャッシュフローの流れなどと絡めた実際のデータをもとに、
組織内の事業同士の内部力学関係を明らかにするということも含んでいいと思っています。
内部力学を把握することで、各事業同士のトレードオフ関係などをある程度類推することができ、「この事業をあまりにも伸ばしても他の事業へのマイナスのインパクトを与える」という、事業目標の上限値をおおよそ定義することができます。
Time-bound(期限)
Time-boundは「期限を定めた」という意味で、目標に期限があるかを確認する項目です。
目標達成には必ず時間的な期限があります。
たとえばあるメトリクス1つとっても、
そのメトリクスを集めるのにどのくらいの時間がかかったのか?ということ。
それ以外にもマイクロサービスアーキテクチャでのデータの結果整合性、
あれはタイムラグのある整合性という特性上、
ビジネス上の都合で「この時間内のラグなら許容できる」というもとで、
結果整合性でもいいのかどうなのか?を判断できるようになります。
もしも高確率で許容時間を超えてしまうようで、
かつ それがビジネスに大きなマイナスのインパクトを与えるのなら、
結果整合性ではない方がいいという判断ができるようになります。
また上記のAchievable(達成可能性)を考慮して、
G(ゴール)の期限設定は、「◯月◯日までにこの達成する」など、現実的且つ具体的な期限を設けるようにしましょう。
これらによってプロジェクトでの各スプリントでの活動内容や優先度。
それだけでなくGQMストラクチャーにおける優先度の定義付けが容易になります。
データマネジメントとの関係性
さんざんGQMストラクチャーに触れてきましたが、これがあるから
データにどんな特性が求められるのか?が浮き彫りになります。
ようはデータ品質のWhyになるってことです。
またデータの意味のあるまとまりである、データドメインを他のプロジェクトでも再利用できるのか?
それによりデメリットなどの考察の手助けにもなります。
是非ともこのGQMストラクチャーを使った定期的ワークショップによって、
価値あるデータを描きつづけることにつなげてみてください。