CQRS
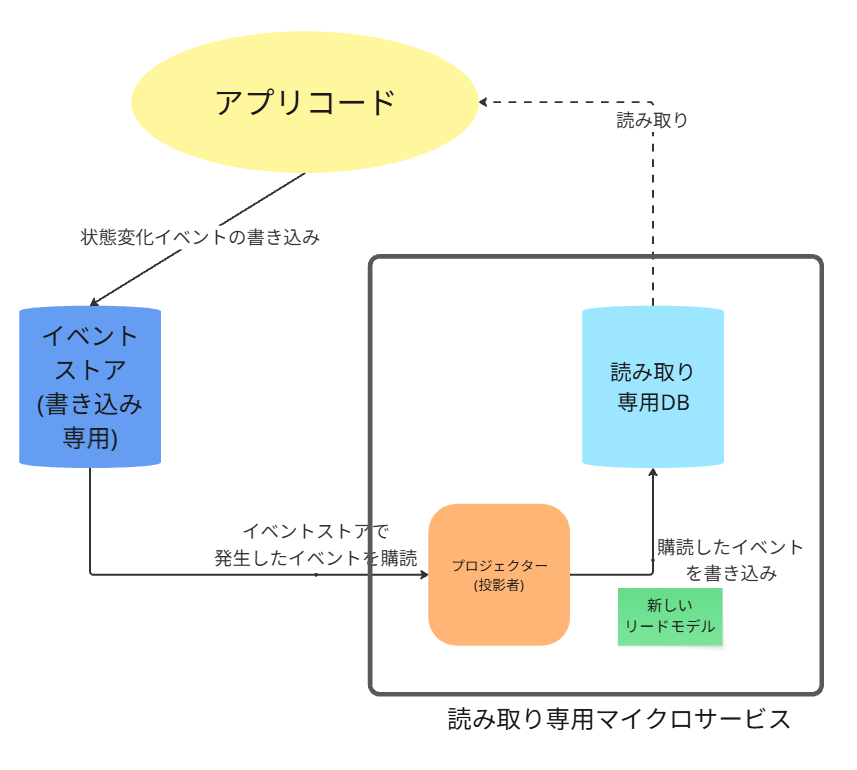
イベントストアが「書き込み」の唯一のデータベースとなり、これまで使っていたRDBは「読み取り専用」のデータベース(リードモデル)として再構築される、というものです。
これは、CQRS(コマンド・クエリ責務分離)という設計原則に基づいています。
役割の分離:書き込み(Write)と読み取り(Read)
イベントソーシングを導入すると、データの流れが書き込み用と読み取り用で明確に分離されます。
1. イベントストア(書き込みの唯一の真実)
役割
全ての状態変更(書き込み)は、イベントとしてこのイベントストアにのみ追記されます。
注文が作成された、住所が変更されたといった全ての「事実」が記録される、信頼できる唯一の情報源です。
特徴
従来のRDBがこの役割を担うことも可能ですが、多くの場合、イベントストリーミングプラットフォームや、専用のイベントストアデータベースが使われたりするそうです。
ここに、マイクロサービスの業務系データベースとしての責務が集約されます。
2. リードモデル(読み取り専用の最新状態)
役割
「現在の注文状況は?」「登録されている住所は?」といった
最新状態に関するクエリ(読み取り) に、高速に答えるためだけのデータベースです。
上記のイベントストアとは、データに求められる特性が全く違います。
特徴
イベントストアを流れるイベントを購読し、イベントの内容を反映して、自身のテーブルを更新していきます。
構成は、イベントソーシングを取り入れる前のRDBと非常によく似ていますが、
決定的に違うのは、このデータベースがアプリケーションから直接書き込まれることはなく、いつでもイベントストアから再構築できる「使い捨て可能」なキャッシュであるという点です。
データフローのイメージ
データフローなので、通常の構造モデルとは違うことにご注意ください
書き込みパス
コマンドが実行されると ⇒ マイクロサービスが処理を開始し ⇒ イベントストアにイベントを書き込む

読み取りパス
書き込まれた事実は、イベントストア自身が、リードモデルに対して通知して、
最終的にリードモデルを同期させる。それをクエリで分析する。

このように、これまで一つのRDBが担っていた「書き込み」と「読み取り」の責務を、
それぞれに最適化されたイベントストアとリードモデルという2つのコンポーネントに分離するのが、イベントソーシングにおける一般的な実装パターンです。
段階的な移行プロセス
前提として、ビジネスの動機として、対象の業務に対するモデリング手法が、
「あとからデータ分析とかしたいからイベント履歴式のドメインモデルにしたい」
というものがあった上で、この移行をしてください。
いきなり全てをイベントストアに切り替えるのではなく、以下のような段階的なステップを踏んでください。
この段階的なアプローチにより、リスクを管理可能なステップに分割し、
稼働中のシステムのダウンタイムを回避しながら、安全にアーキテクチャをイベントソーシングへ進化させることができます。
ステップ1:イベントストアの導入と「二重書き込み」
このステップでのアクション
まず、書き込み用のイベントストアを新規に構築します。
次に、既存のアプリケーションの書き込みロジックを修正し、これまで通り従来のRDBに最新状態を書き込む処理に加えて、その状態変化を表すイベントを新しいイベントストアにも書き込むようにします。
この時点では、読み取り処理はこれまで通り、全て既存のRDBから行います。

この段階の状態
書き込み:従来のRDBと、新しいイベントストアの両方に行われます(二重書き込み)。
読み取り:これまで通り、全ての読み取りは従来のRDBから行われます。
目的:既存システムへの影響を最小限に抑えながら、イベントの履歴を安全に蓄積し始めること
ステップ2:リードモデルの構築と検証
このステップでのアクション
ステップ1で蓄積され始めたイベントストリームを元に、読み取り専用の「新しいリードモデル」を構築します。
この時、従来のRDBを、そのままこの新しいリードモデルの器として再利用します。
ここでさらに、イベントストアに来たイベントをリードモデルに反映させるための専用プロセス(プロジェクター)を開発する必要があります。
また、従来のRDBの提供する読み取りモデルと、リードモデルの提供する読み取りモデルが
完全に一致しているのか?の検証も必要です。
個人的にこのステップ2が一番だるい時期だと感じます。

この段階の状態
書き込み:引き続き、RDBとイベントストアへの二重書き込みが行われます。
読み取り: 従来のRDBからの読み取りと、新しく構築したリードモデルからの読み取りを並行して行い、両者のデータが一致することを検証します。(図のピンクの部分)
目的:新しいデータフロー(イベントストア→リードモデル)が、従来の仕組みと等価な状態を正しく構築できることを安全に確認すること。
プロジェクターや、この検証部分はわかりにくいと思うので、下で詳しく触れます。
ステップ3:書き込みの切り替えとRDBの役割確定
このステップでのアクション
リードモデルのデータが信頼できるものであると検証できたら、アプリケーションからの従来のRDBへの直接の書き込み処理を停止します。
これ以降、書き込みはイベントストアのみに対して行われ、
既存のRDBは、イベントストアからのデータを反映する
完全な「リードモデル(読み取り専用DB)」 としての役割を担うことになります。

この段階の状態
書き込み:イベントストアのみが、信頼できる唯一の情報源となります。
読み取り:全ての読み取りは、イベントストアからのデータを反映するリードモデル(旧RDB)から行われます。
目的:アーキテクチャの切り替えを完了させること。
この時点で、システムはイベントソーシング+CQRSのアーキテクチャに移行したことになります。
ここで、まだピンクの検証ロジックが残ってることは重要です。
下記で触れます。
プロジェクター(投影者)の概要と責務
プロジェクターは、イベントソーシング+CQRSアーキテクチャにおいて、
書き込み側(イベントストア)と読み取り側(リードモデル)を繋ぐ、非常に重要な役割を担うコンポーネントです。(図のオレンジ部分)

責務内容:イベントを「状態」に翻訳する
プロジェクターの唯一の責務は、
「イベントストアで発生したイベントを購読し、その内容を読み取り専用のリードモデル(RDBなど)に反映させる」
ことです。
具体的な動作
①. イベントストアに新しいイベントが追加されるのを待ち受けます(Listen)。
例えばOrderConfirmedイベント を受け取ると、
そのイベントのデータ(注文ID、顧客名、金額など)を解釈します。
②. 解釈したデータを使って、リードモデルのordersテーブルに新しい行をINSERTします。
③. 次に同じ注文IDでOrderShippedイベント を受け取ると、ordersテーブルの該当行のステータスをSHIPPEDにUPDATEします。
このように、プロジェクターは一連の「起きたイベント(出来事)」を、
人間や他のシステムが理解しやすい「最新の状態」へと投影(Project) する、翻訳家のような役割を果たします。
責務の配置場所(どこに置くか)
プロジェクターのロジックをどこに実装するかは、アーキテクチャ上の選択ですが、主に以下の2つのパターンが一般的です。
パターンA:独立したマイクロサービスとして
イベントを購読し、リードモデルを更新するだけの責務を持つ、専用のマイクロサービスとして構築します。

メリット
単一責務原則に従ってるのでプロジェクターコンポーネントの責務がわかりやすい
単一責任の原則に従っており、コンポーネントの責務が明確です。
リードモデルの更新ロジックと、リードモデルを公開するAPIのロジックを、独立して開発・デプロイ・スケールさせることができます。
デメリット
①. 運用オーバーヘッドの増大
管理・監視すべきコンポーネントの数が増えます。
CI/CDパイプラインや監視ダッシュボードなども、このプロジェクターサービスのために別途用意する必要があり、インフラ全体の複雑性が増します。
②. ネットワークのオーバーヘッド
イベントの受信やリードモデルへの書き込みが、全てネットワーク越しの通信となります。
これにより、レイテンシーが増加しネットワークが新たな障害点となる可能性があります。
パターンB:リードモデルを提供するサービス内部に
リードモデルのデータを外部に公開するAPIを持つ読み取り専用マイクロサービスの、
内部的なコンポーネント としてプロジェクターを実装します。
メリット
高い凝集度とシンプルな構成
データを更新するロジック(プロジェクター)と、そのデータを読み取るロジック(API)が同じコンポーネントにまとまっているため、凝集度が高くなります。
管理すべきデプロイ対象が一つで済み、構成がパターンBに比べてシンプルです。
デメリット
デプロイ時の結合
リードモデルの更新ロジック(プロジェクター)の小さな修正であっても、APIを提供するサービス全体を再デプロイする必要があります。
これにより、APIの可用性に影響を与えるリスクが生まれます。
リソースの競合問題
大量のイベントを処理するプロジェクターのバックグラウンド処理と、低レイテンシーが求められるAPIのリクエスト処理が、同じコンポーネントのリソース(CPU、メモリ、DBコネクションプール)を奪い合う可能性があります。
データ検証ロジック
次に、図のピンクの部分のデータの検証ロジック について深ぼっていきましょう。

ここはツールてよりも、移行戦略の一部として自分たちで作ることが一般的です。
主な検証アプローチには、以下の2つがあります。
1. アプリケーション内でのリアルタイム比較
ピンクの処理を既存の黄色のアプリケーションコードに持たせる方法です。
仕組み
①. アプリケーションが読み取りリクエストを受け取ると、まず従来のRDB(正解データ)
からデータを取得します。
②. 次に、新しく構築したリードモデルからも同じデータを取得します。
③. コード内で両方のデータを一致しているか比較します。
④. もしデータが一致しない場合は、その差分を詳細なログやメトリクスとして記録します。
⑤. そして、ユーザーには、常に正解である従来のRDBのデータを返します。
メリット
本番環境のリアルなトラフィックを使って、リアルタイムでデータの不整合を検知できます。
デメリット
読み取り処理のたびに2つのデータソースにアクセスするため、僅かながらシステムの応答時間が長くなります。
2. オフラインでのバッチ比較
仕組み
①. 本番のアプリケーションとは別に、定期的に実行されるバッチプログラムを用意します。
②. このプログラムが、例えば「直近1時間に更新された全レコード」を、従来のRDBと新しいリードモデルの両方から取得します。
③. 両者のデータを突き合わせ、差分があればレポートとして出力します。
メリット
本番アプリケーションのパフォーマンスに一切影響を与えません。
デメリット
リアルタイムではないため、データ不整合の発見が遅れる可能性があります。
共通目的
上記のどちらのアプローチであっても、その目的は
「プロジェクターがイベントを正しくリードモデルに反映できているか」を検証し、新しいデータフローへの信頼性を確立すること
です。
この検証ロジックによって不整合が検出されなくなり、
チームが「新しいリードモデルは信頼できる」という自信を持てた時点で、
初めて次のステップ(ステップ3:書き込みの切り替え)へ進むことができます。
検証ロジックの役目とライフサイクル
ちなみに、CQRSへの移行が完了した後も、この「データ検証ロジック」は残すのか?
それとも消すのか? 気になった方もいると思います。
結論から言うと、すぐには消しません。
むしろ、アプリケーションからRDBへの直接書き込みを停止した直後こそが、その検証ロジックが最も重要な役割を果たすタイミングです。
書き込み切り替え時における、検証ロジックの役割
ステップ3で書き込み方法を切り替えた後も、この検証ロジックを稼働させ続けることには、
以下の重要な2つの目的があります。
セーフティネットとしての最終検証
ステップ2までは、従来の直接書き込みと、イベント経由の反映が「同じ結果になるか」を検証していました。
ステップ3で直接書き込みを停止した後は、
「イベント経由の反映だけが、本当に正しく、漏れなくデータを最新に保ち続けられるか」
という、新しい書き込みシステムの最終的な正しさを検証するセーフティネットとして、
このロジックが機能しつづけます。
迅速な問題検知とロールバック判断
もし、書き込みを切り替えた直後に、この検証ロジックが大量の不整合を検知し始めたら、
それは新しいイベントソーシングの書き込みパスに何らかのバグや考慮漏れがあることを示しています。
これにより、問題が大きくなる前に即座に検知し、必要であれば迅速に直接書き込みを復活させる(ロールバックする)という判断が可能になります。
検証ロジックのライフサイクル
この検証ロジックは、移行期間中のみに存在する一時的なコードです。
いずれ削除しないと、負債コードとして残り続け、複雑性を増価させてしまいます。
そこで、以下の大きく分けて3つのフェーズで分類し、
最終的な3つ目の削除フェーズになったら、なる早で削除しましょう。
導入(ステップ2)
リードモデルの構築と、従来の仕組みとの等価性を検証するために導入します。
稼働(ステップ3)
書き込みを切り替えた後も、セーフティネットとして一定期間(例:1週間、あるいは一つの業務サイクルが完了するまで)稼働させ続けます。
削除(ステップ3完了後)
不整合が一切検出されず、新しいアーキテクチャが安定稼働しているという確信が得られたら、この検証ロジックは役目を終えます。
これ以降は、【使われないコード(役目を終えたコード)】なので、この時点で、技術的負債としてコードから安全に削除します。
データオブザーバビリティツールでさらにさらに安全に
上記の検証ロジックは、データオブザーバビリティツールを併用することで、
その検証プロセスは比較にならないほど安全かつ迅速になります。
あくまでも、上記の検証ロジックは、
「答えが分かっている既知の異常に対するテスト」
に近く、データオブザーバビリティツールは「予期せぬ問題を発見してくれる健康診断」に近いと言えます。
①. データオブザーバビリティがない場合(自前の検証ロジックのみ)
検証方法
開発チームが手動で実装する、特定のデータ項目を比較する検証ロジックに依存します。
例えば、「注文IDをキーにして、従来のRDBとリードモデルの注文ステータスが一致するか」といったコードを書き、定期的に実行します。
効果の差分(限界点)
検知の遅延
検証がバッチ処理で実行される場合、不整合の発生から発見までに数時間以上のタイムラグが生まれる可能性があります。
限定的な網羅性
検証ロジックのみでは、開発者が想定した、プログラムに記述された特定の項目しか検証できません。
例えば、
「注文ステータスは一致していても、更新タイムスタンプが微妙にずれている」
「あるカラムのNULL値の割合が急増している」
といった想定外のデータ不整合を発見することができません。
原因分析の困難さ
不整合が検知されても、「なぜ」それが起きたのかを突き止めるには、
結局、開発者が複数のシステムのログを手動で横断的に調査する必要があります。
コミュニケーションパスとアーキテクチャの不調和
複数のシステムのログを手動で横断的に調査する際に、
他のコンテキストを担当するチームとのコミュニケーションコスト増大になり、
その不整合問題が起きるたびに、チーム間はピリつきだしてしまいやすいです。
責任のなすりつけ合い問題
そのハレーションが組織内の意図しないコミュニケーション断絶を生みやすくなります。
結果的にその断絶が、エンタープライズアーキテクチャのあるべき形と一致したらラッキーなんですが、まあそんなうまい話はないわな💦
②. データオブザーバビリティツールと併用する場合
検証方法
データオブザーバビリティツールが、従来のRDBと新しいリードモデルの両方のデータストアに接続し、データの統計的なプロファイルを自動的かつ網羅的に常時監視してくれます。
レコード単位の比較だけでなく、データの統計的なプロファイル(鮮度、量、分布など)を常時比較します。
効果の差分(得られる価値)
迅速な検知
ツールはほぼリアルタイムでデータのプロファイルを比較するため、不整合が発生してから数分以内に問題を検知し、アラートを発報します。
これにより、問題が大きくなる前に迅速に対応できます。
網羅的な安全性
レコードの値の一致だけでなく、
「リードモデルの更新が、従来のDBより30分遅延している(鮮度の問題)」
「イベント経由で反映したレコードの量が10%少ない(完全性の問題)」といった、
データの鮮度、量、分布、スキーマといった、データ品質のあらゆる側面を自動で監視します。
これにより、手動のロジックでは見逃しがちな、より広範なデータの品質問題を自動で検知してくれます。
容易な原因分析
多くのツールはデータリネージュ(血統)機能を備えています。
これにより、リードモデルでの不整合が検知された際に、
「この不整合は、上流のAというデータソースのスキーマ変更が原因である」
「上流のどのパイプラインやソースデータの変更に起因するのか」といったことを視覚的に示してくれるため、原因究明の時間が劇的に短縮されます。
結論
移行という不確実性の高いプロセスにおいては、予期せぬことだって当然起こりえます。
それに気づかずに、見かけだけデータが一致しているということだけで、
「安全だ」と判断し、並行検証ロジックを削除してしまったら、もう大変です💦
データオブザーバビリティツールは、この移行の検証プロセスを、
「特定の項目を、時々チェックする」 という限定的な活動から、
「あらゆる側面を、常に自動で見守る」
という、遥かに安全で効率的な活動へと進化させるのです。
よって、コストはかかるものの、データオブザーバビリティツールを併用することで、
安全性は飛躍的に向上します。
補足 -アナロジーメカニズム-
この並行検証ロジックとデータオブザーバビリティツールを併用した関係性、
どこかで似たようなもの見たことがあるなって思いました。
適応度関数とカオス実験でのオブザーバビリティとの関係性です
並行検証ロジック = 適応度関数みたないもの
この関係は適応度関数に非常に似ています。
役割
適応度関数は、「アーキテクチャが既知のルール(例:循環依存がない)を守っているか」
を継続的に検証します。
同様に、並行検証ロジックは、「リードモデルのデータが、既知の正解(従来のRDB)と一致しているか」という、明確なルールを検証します。
性質
どちらも、
合否が明確な、決定論的なテスト
です。システムの「既知のリスク側面」に対するガードレールとして機能します。
データオブザーバビリティ = カオス実験での観測者みたいなもの
そして、データオブザーバビリティの役割は、カオス実験での観測者の役割と一致します。
役割
カオス実験では、
「障害を注入した際に、予期せぬ副作用や、未知の連鎖的な障害が起きないか」をシステム全体を俯瞰して観測します。
同様に、データオブザーバビリティは、
「データの値は一致しているが、予期せず更新が2時間遅延している」とか
「未知のNULL値が急増している」といった、単純な比較ロジックでは見つけられない、
システムの異常な振る舞いを観測・検知します。
性質
どちらも、未知の問題(Unknown Unknowns)を発見するための、探索的な活動です。
結論
このアナロジーで考えると、移行検証における2つのアプローチの重要性がより明確になるかと思います。
並行検証ロジック(適応度関数)で、移行が最低限の品質基準(既知のルール)
を満たしていることを保証しつつ、
データオブザーバビリティ(観測者)で、その裏で想定外の問題(未知の異常)
が起きていないかを監視する。
この両輪があって初めて、安全な移行が実現できるのです。
是非とも、CQRSへの移行の際には、データオブザーバビリティの導入を前向きな投資として、考えてみてください。