この記事はSnowflake Advent Calendar 2023の10日目の記事です!
はじめに
地理空間データを効率よくクエリしたいとき、空間インデックスを活用したくなることがあるので、今回、Snowflakeで空間インデックスを使う場合、どういったものが使えるか確認してみました。
空間インデックスって?
空間データベースに対する空間検索を最適化するものです。
OracleやPostgreSQL(PostGIS)などでは、地理空間データ型を扱える機能があり、地理空間データに対応した空間インデックスが内蔵されています。(大変お世話になってました。)また、そのような機能がないDB環境だと、空間インデックスをデータの属性として付与したり、別でインデックステーブル作ったりすることもあるかと思います。(メッシュリストテーブル等)
空間インデックスの種類
空間インデックスという言葉を使うとき、大きく2つわけられるかと思います。
地理空間データが属するバウンディングボックスを階層化的に持つRtreeを構築する方式のもの(実データ駆動型)と、空間充填曲線+Grid等の形状で事前に分割し番号やハッシュ値をつけておく方式のもの(グリッドベース型)です。PostgreSQL+PostGISの空間インデックスは前者、日本のデータでよく見る地域メッシュコードは後者です。
Snowflakeでは?
Snowflakeはそもそもインデックスというオブジェクト自体がないので、空間クエリ、集計操作を最適化するために、空間インデックスを活用するには工夫が必要そうです。現状選択肢としては以下が使えそうでした。
Search Optimization Service(Enterprise Editon以上)も検索性能の最適化に利用できそうですが今回はいったん棚上げします。(触ってみたい。。)
今回はSnowflakeネイティブ機能で、GA済みのgeohashにフォーカスします。
geohashとは?
グリッドベースの空間インデックスで、階層的に空間を格子状に区切った領域を文字列で表現するものです。文字列の桁数右に増えていくことによって、より細かい領域を表することができるため、Geohashの前方一致桁数によって、位置精度を見ることもできます。
例えば、池袋駅東口ですと、「xn7770r」あたりになります。
https://geohash.softeng.co/xn7770r
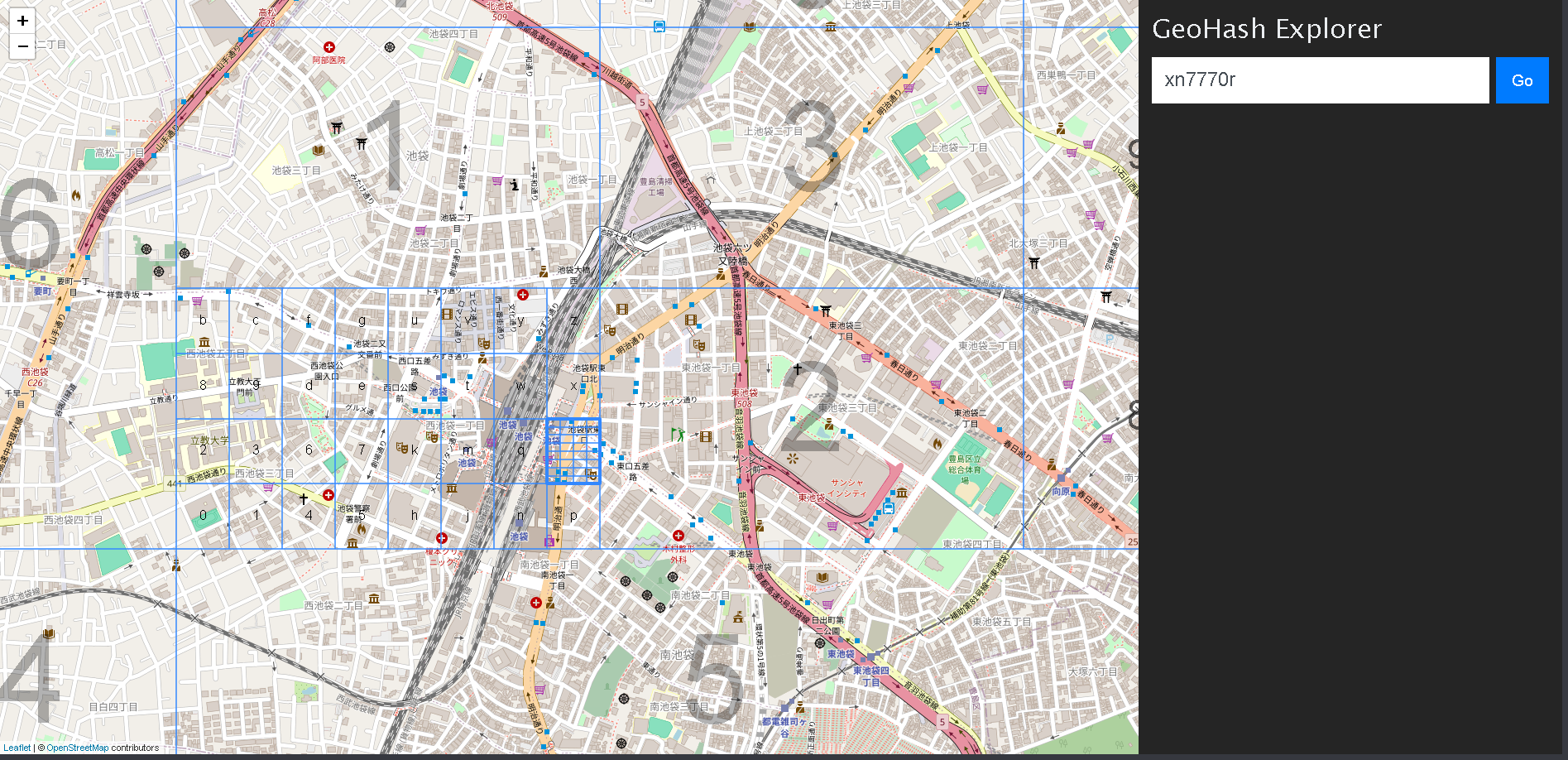
Snowflakeでgeohashを使いどころ
geohashが一般的に使われるケースがSnowflakeでもそのまま適用できると思います。
位置情報の圧縮
地理空間データは、緯度経度、Geojson、WKB(EWKB)、WKT(EWKT)といった形でデータを持つことになりますが、ある程度の精度で位置がわかるのであればよいということであれば、geohashに変換しておくことで、データサイズを圧縮することができます。特に大量の形状点で構成されるポリゴンデータの場合、サイズが大きくなりがちなので、有効です。
空間メッシュとしてグループ化、階層化
グリッドベースの空間インデックスに地理空間データを変換すれば、グリッド単位での集計、階層的なデータ解析に用いることができます。例:地域メッシュ統計データなど
空間検索の最適化やクラスタリング
空間関係関数を用いた検索処理にてGeohashを用いた枝刈りを事前に行うことができますが、
検索したい範囲と重なるgeohashを事前に求める必要があります。geohashの事前計算がでてきれば、
また、空間検索が重視されるテーブルでは、クラスタリングキーをgeohash値にすることで、空間的に近しいデータを近くに並べることができます。(geohashでソートした場合、Z階数曲線で並ぶので、微妙に近い位置情報が離れてしまう場所も存在してしまうのですが・・・ここは難しいところですね。)
試してみた
空間検索の最適化でgeohashを使ってみるケースを試してみます。
ダミーデータ準備
検索性能をみるために、ざっくり東京都付近に1億件のポイントデータ生成しました。(geohash列&ソート付)一億件のポイントデータなら、XSサイズのウェアハウスで空間検索すると数十秒かかるのでこのくらいにしてます。
set (xmin,xmax,ymin,ymax) = (
select
st_xmin(POLYGON_JP_PREF_2_LIGHT) as xmin,
st_xmax(POLYGON_JP_PREF_2_LIGHT) as xmax,
st_ymin(POLYGON_JP_PREF_2_LIGHT) as ymin,
st_ymax(POLYGON_JP_PREF_2_LIGHT) as ymax
from
-- 都道府県の基礎データ | 2020年 テーブル
PREPPER_OPEN_DATA_BANK__JAPANESE_PREFECTURE_DATA.E_PODB.E_PR_FD20
where
PREF_CODE= 13 -- 東京都
);
create or replace table dummy_tokyo_point as
with t as (
select
st_point(
uniform($xmin, $xmax, random()),
uniform($ymin, $ymax, random())
) AS geog
FROM
table(generator(rowCount => 100000000))
)
select
geog,
st_geohash(geog) as geohash_val
from t
order by 2
;
Geohash絞り込み無しで、空間検索
池袋駅より周囲200mのダミーデータを抽出してみます。
範囲検索だと、ST_Distancenもありですが、今回は、ST_Bufferでポリゴン化してみました。
(Bufferを使ってみたかっただけ。。厳密な200m範囲をとる場合は、距離条件でやったほうがいいです。POINTデータでST_Bufferするときれいな円ポリゴンでなく、多角形ポリゴンなので、結構誤差があります。)
select
count(*)
from
TESTSL.TEST001.DUMMY_TOKYO_POINT as dtp
inner join PREPPER_OPEN_DATA_BANK__JAPANESE_STATION_AND_RAILWAY_DATA.E_PODB.E_SR_PS20_1 as s201 -- PODB 日本の駅
on
s201.railway_line_name = '山手線'
and s201.station_name = '池袋'
and st_intersects(ANALYTICS_TOOLBOX.CARTO.ST_BUFFER(s201.POINT_STATION_CENTROID,200), dtp.geog)
;
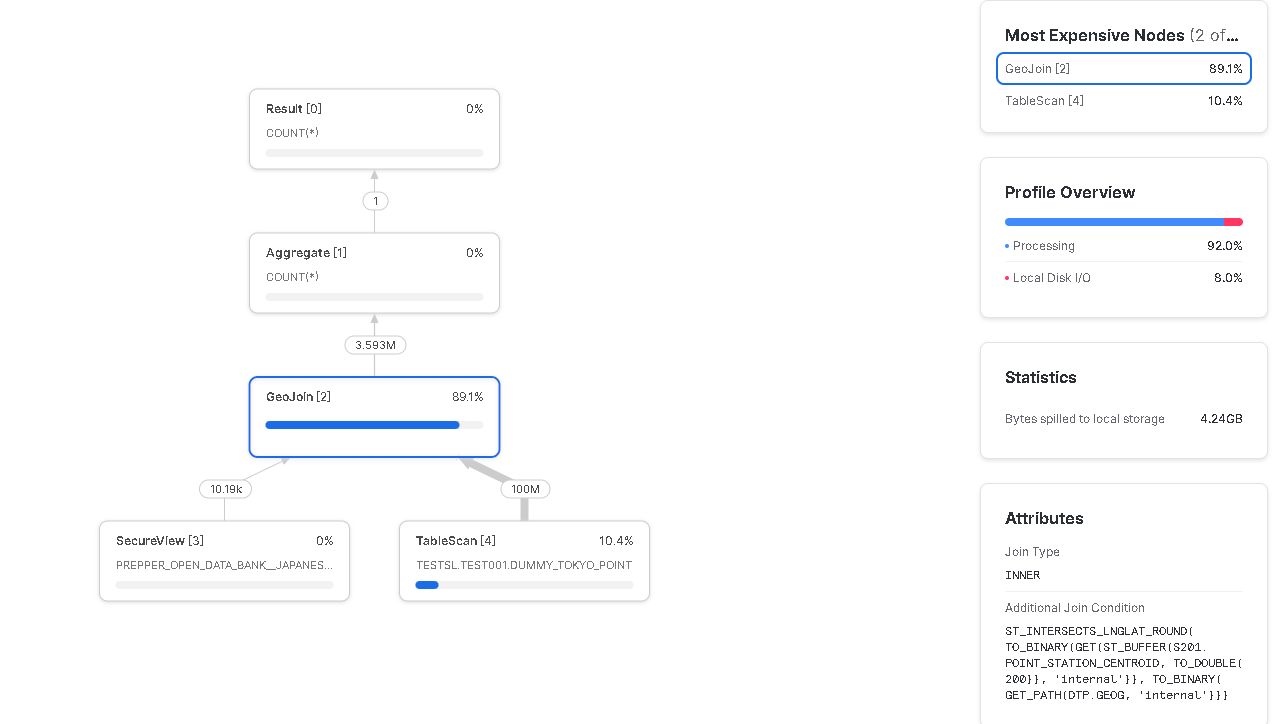
結果は以下の通り、30秒近くかかっており、ダミーデータ全体を読みにいっています。
実行時間 29s
Bytes spilled to local storage 4.24GB
Query Profileは以下
そこで、geohash値でソートしている強みを生かし、
池袋駅周辺を含むGeohash「xn777」での絞り込みを挟んでみます。
select
count(*)
from
TESTSL.TEST001.DUMMY_TOKYO_POINT as dtp
inner join PREPPER_OPEN_DATA_BANK__JAPANESE_STATION_AND_RAILWAY_DATA.E_PODB.E_SR_PS20_1 as s201 -- PODB 日本の駅
on
s201.railway_line_name = '山手線'
and s201.station_name = '池袋'
and dtp.geohash_val like 'xn777%'
and st_intersects(ANALYTICS_TOOLBOX.CARTO.ST_BUFFER(s201.POINT_STATION_CENTROID,200), dtp.geog)
;
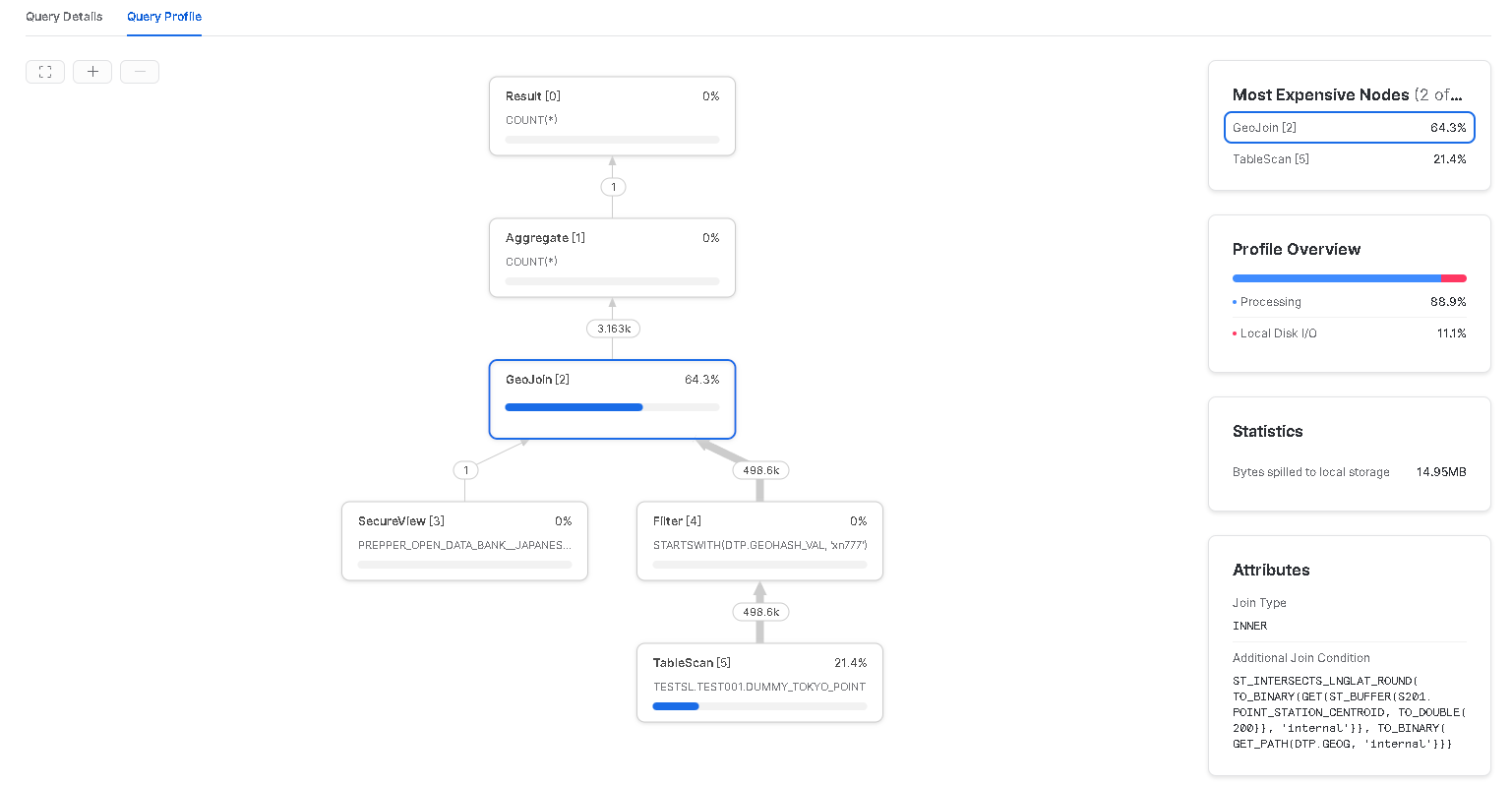
geohashによる枝刈りが効いて、実行時間が1.3秒とかなり短縮されました。
実行時間 1.3s
Bytes spilled to local storage 14.95MB
Query Profile
まとめ
Snowflakeで空間インデックスの活用について、主にGeohash機能を中心に掘り下げてみました。
グリッドベースの空間インデックスでは、日本国内だと地域メッシュコードを使うことが多く似たようなことはできるがSnowflakeだとGeohashが気軽に使える場所にあるので適材適所で活用できるとよさそうです。
Snowflakeの地理空間機能は、プレビューだったり、GeometryとGeographyのカバー範囲が結構ちがったりと、まだ過渡期なところも感じます。今後のアップデートに期待しています。