Developers.IO 2019 Tokyoに初参戦
表題のとおり、Developers.IO 2019 Tokyoに参加して参りました!
今年で5回目の開催を迎えるクラスメソッド主催のカンファレンスイベント Developers.IO 2019
とありますが恥ずかしながら今まで知らずにおりました。。
普段からブログには散々お世話になっておりますが、色々と勉強になったのでよかったです!
参加したセッションは以下です。
- Developers.IO CAFEのこれまでとこれから 〜顧客体験へのフォーカスから考える技術選択〜(横田聡)
- ハイブリッド/マルチVPC環境を構成するAWSネットワークの完全理解(菊池修治)
- サーバーレスの基本とCI/CD構築 & 運用 〜システムは動いてからが本番だ〜(藤井元貴)
- Amazon CultureとAWSの設計思想 ~マイクロサービスアーキテクチャとアジャイル開発~(アマゾン ウェブ サービス ジャパン亀田治伸氏)
- AWS CDKの基本と実例(加藤諒)
- 最近のAuroraのアップデート使いこなし術 〜 ServerlessやMulti-Masterどんな時に利用する? 〜(大栗宗)
- Well-Architected Framework Security Pillar DeepDive~セキュリティからはじめるより良い設計の考え方~(中山順博)
- AWSのすべてをコードで管理する方法〜その理想と現実〜(濱田孝治(@hamako9999))
会場到着
会場はベルサール東京日本橋でした。
駅から直結で最寄からも1本で来れたので良かったです。
A〜Hの全8トラックがあり、セッション内容も豊富だったのでなかなか選ぶのは大変でした。
人気のセッションはすぐに埋まってしまうので、来年以降は早めに抑えておこうと思いました。
※セッションは事前予約制ですが、当日でも空き席や立ち見で参加が可能でした。
Developers.IO CAFEのこれまでとこれから 〜顧客体験へのフォーカスから考える技術選択〜
元記事 : https://dev.classmethod.jp/event/report-developers-io-2019-tokyo-yokota-developersiocafe/
クラスメソッド株式会社の代表取締役である横田聡さんのセッションからスタートしました。
AWS Summitなどのイベントでも登壇されることも多くご存知の方も多いと思いますが、Developers.IO CAFEのスタートから今後の計画までお話し頂きました。
ちなみに文中登場するシーズンnは横田代表が海外ドラマ好きなので、そこに由来しているそうです。(笑)
Developers.IO CAFE開発前夜
昨今、IT企業が自ら事業を開始し事業会社化が世界的に進んでいるが自社はどうだろうか?と考えた際に、お客様目線に立ったサービスが提供できていないのではないか?と感じ、IT企業の事業会社化はもはや止められない流れになってきていると危機感を覚えていた。
特に昨年自身でAmazon Goを体験した際に大きな衝撃を受け、これを日本で実現したいと考えたことからDevelopers.IO CAFEの着想に至った。
しかし、Amazon Goに関する技術情報は公開されておらず全て手探りの中、一体どうやったら日本でAmazon Goを実現できるだろう?と考えた。
Amazonのカルチャーをハックしたらできるのでは?と仮説を立て、Amazonのカルチャーをハックすることを実践した。
Our culture
Amazon Goを実現するために下記を大事にして開発を進めていった。
- 大事なのは体験なので有りもので体験を実現する
- スピード重視(フィードバックを高速に反映して改善を繰り返す)のため
- 要件定義は動画で共有
- 実際のユーザー体験を再現した動画をあげてゴールのイメージをチームで共有する為
- 一連の体験を分割して単独で開発を進めていく
- 要件が実際にユーザー体験として実感できるかが重要なため
前述したとおり、技術情報がわからないため常に妄想 -> 技術検証を繰り返した結果以下のような技術を利用してみた
- Amazon Rekongnition Video
- AWS IoT Core
- 3D LiDAR ToFセンサー
- ESP32
- ひずみセンサー(ロードセル)
シーズン1
8人のエンジニアでスタートしたが、それぞれ場所別々だしタイムゾーンも別さらに全員兼業でやっていた。
そのためユーザー体験をベースに各々が単独で開発を進めていかなければ完成は見えなかった。
その結果要件定義と成果物が動画で共有されるようになった。
ほんの一例だが、開発の初期段階では以下のように開発が進んでいった。
- 極力お客様のアクションを減らす -> IoT(センサー)が必要だな -> とりあえずセンサー集める -> センサーでデータを取得 -> クラウドに送る
- レジ無くすために商品の増減を管理する -> 商品棚の重さをマイコンで管理すればいいんじゃないか -> 重量データをクラウドに逐一データを送る -> クラウド側で過去データを元に増減を検知する
といった感じで開発を進めていった。
シーズン1では下記のようなハードウェアや技術を利用していた。
- ESP32
- ひずみセンサー(ロードセル)
- Stripe(決済サービス)
- 顔認証(Rekognition)
企画からプロトタイプを1週間でセンサーからモバイルの決済までを3週間で実現した。
シースン1を経ての気付きは以下の点
- ユーザー体験をより良くするために成果物を動画で共有するのはすごく大事
- 収集データを基に分析した結果によって実店舗に影響を与えることが実現できるのではないか?
シーズン2
シーズン1に加えオペレーション側での改善を進めた。
- サーバーサイドの処理においてはStep functionsを利用して行動ステータスを管理した。
- エッジ処理にGPUで使って商品画像の学習を進めた結果、画像認識の時間を短縮することに成功した。(30分ほどの学習で認識制度は高くなった。)
- 測距センサーを商品棚に導入したことで、お客様が商品棚に手を入れたら検知できるようになった。
- これらのデータを利用してお店でリアルタイムで起こっていることを表示するWebアプリ作成し、モニタリングできるようになった
MQTTの利用し、これらの膨大なデータの送受信を実現した。
シーズン3
実店舗での運営を検討し、現テナントの契約を結んだ。
ToFセンサーでの動体検知を実現し、店舗内のお客様の動きをモニタリングできるようになった。
この時点で実店舗として運営できる形が見えてきており、1日あたりのクラウドのコストは約$3ほどだった。
※サーバーレスで実現していたことがコストインパクトにおいて非常に大きかった。
また様々なイベントや企業などにデモ店舗を出展し、直接ユーザー体験を間近に見聞きすることで今まで得られなかった見知が多く得られた。
ここまでを通して非常に重要なことは以下の3点
- ペーパープロトタイピングはユーザーの実体験の中に埋め込んでこそ進化を発揮する
- 高速に改善すること(超重要)
- 顧客体験を直接聞ける -> 得られるものが全然違う
実際にユーザーが横で使っているのを見たことありますか?は全てのサービス開発者は考えるべきことだと思う。
シーズン4
サービス管理の省力化を進める。
- ハードウェアの外注
- 今まで自前でセンサーや棚を作っていたため耐久性や携帯性が悪かった。
- セキュリティの基本は抑える
- MQTTや各種機器データの取り扱いにおいて、スピードが重要だからといってないがしろにしてはいけない。
実店舗のオープンに向け着々と準備を整える。
シーズン5
実店舗のオープンと展開を実施する。
秋葉原にいよいよ実店舗をオープンした。
https://cafe.classmethod.jp/
またそれと同時に事業会社や教育機関とのコラボで、ITや自社に興味のない・知らないお客様からフィードバックを得る。
- 高齢層はアプリ?なにそれ?状態なのでブラウザで利用できるWebアプリを提供
- 若年層はアプリ無いんですか?の要望が多くネイティブアプリを提供
- 境界が無い方が入りやすいかと思っていたら、真逆の意見でゲートがある方が入りやすい方が多かった
上記すべてが現場から得たユーザーの声であり、事業化しなければ見えてこなかった。
いかに今までお客様の求めるものを提供できていなかったかを痛感した。
シーズン6
更なる進化とより良いユーザー体験を実現する。
- プリント基板
- デイジーチェーンを導入しデータと電源1本化することで配線をシンプルに
- 入店ゲート
- 深センの工場に発注して国内で加工
- Suica対応
- 魅せるレイアウトに対応するセンサー
- 複数名同時入店に対応するロジック
- コンテナ型店舗を作った
まとめ
早く始めて早く改善することで、フィードバックを高速に反映して改善を繰り返すことができる
- 体験を考える
- 文化を考える
- 技術を考える
これらを実践することで、より良いユーザー体験ひいてはより良いサービスを実現できる。
ハイブリッド/マルチVPC環境を構成するAWSネットワークの完全理解
元記事 : https://dev.classmethod.jp/cloud/aws/developoers-io-2019-aws-hybrid-network/
本セッションはAWS事業本部のソリューションアーキテクト・マネージャである菊池修治さんからハイブリッド/マルチVPC環境のネットワーク構成についてのセッションでした。
ハイブリッド/マルチVPC環境とは複数のVPCやオンプレが相互に接続する環境のことを指し、これらを取り巻く環境と構成する要素を用いて実現方法を解説頂きました。
複数環境の通信を適切に制御するルーティング
AWSにおけるGatewayは以下の4点が存在する
- Internet Gateway(IGW)
- Virtual Private Gateway(VGW)
- VPC Peering(PCX)
- Transit Gateway (TGW)
Transit Gatewayが2018年のre:Inventで発表されるまでは3つしか存在しなかった。
TGWが登場したことでハイブリッド/マルチVPC環境がシンプルになり、より扱いやすくなった。
本セッションではTGWの登場による変化と、TGWを用いた実運用パターンを解説していく。
Transit Gatewayが登場する以前
下記制限があり、Transit Gatewayがない時はVPCを跨いだ通信は不可能だった。
- VPC Router
- VPC Router(ルートテーブルでいうところのlocal)のルートテーブルは編集が可能
- Virtual Private Gateway(VGW)
- Customer Gatewayと隣接するVPC Routerが自動で設定されてしまうためルートテーブルは編集できなかった。
- VPC Peering(PCX)
- ピアリング先と隣接するVPC Routerが自動で設定されてしまうためルートテーブルは編集できなかった。
そのため全てのVPCやオンプレを1対1で繋がなければならなかった。
Transit Gatewayが登場後
TGWが登場したことによりハイブリッド/マルチVPC環境におけるネットワーク環境の設定が大きく変化した。
TGWで実現できる機能は主に下記2点になる。
- Hub型で接続が可能
- ルートテーブル編集可能
イメージとしてはVPCルートテーブルがsubnetルートテーブルのように柔軟に設定できるようになった。
ただしその反面、慎重に設定しないと思わぬセキュリティホールや意図しない通信が可能になってしまうため注意が必要。
Transit Gatewayの基本
下記順序に沿ってTGWを利用する。
- Transit Gatewayの作成
- アタッチメントの作成
- TGWルートテーブルの作成
- TGWルートテーブルとアタッチメントのアソシエーション
- TGWルートテーブルの設定
- VPCルートテーブルの設定
Transit Gatewayの作成
セッションではコンソールからでしたがCLIで作成してみました。
$ aws ec2 create-transit-gateway \
--description "for poc" \
--tag-specifications 'ResourceType=transit-gateway,Tags=[{Key="Name",Value="maintenance-poc"},{Key="Environment",Value="sandbox"}]' \
--region ap-northeast-1 \
| tee ./tgw_poc.json
{
"TransitGateway": {
"TransitGatewayId": "tgw-079106e54d63cd110",
"TransitGatewayArn": "arn:aws:ec2:ap-northeast-1:123456789012:transit-gateway/tgw-079106e54d63cd110",
"State": "pending",
"OwnerId": "123456789012",
"Description": "for poc",
"CreationTime": "2019-11-04T18:53:12.000Z",
"Options": {
"AmazonSideAsn": 64512,
"AutoAcceptSharedAttachments": "disable",
"DefaultRouteTableAssociation": "enable",
"AssociationDefaultRouteTableId": "tgw-rtb-0df59aaeeac7779d1",
"DefaultRouteTablePropagation": "enable",
"PropagationDefaultRouteTableId": "tgw-rtb-0df59aaeeac7779d1",
"VpnEcmpSupport": "enable",
"DnsSupport": "enable"
},
"Tags": [
{
"Key": "Name",
"Value": "maintenance-poc"
},
{
"Key": "Environment",
"Value": "sandbox"
}
]
}
}
Route設定の⾃動化がTransit Gateway作成時に設定可能
- Default route table association
- アタッチしたVPC/VPN/DXが⾃動でルートテーブルにアソシエーションする
- Default route table propagation
- アタッチしたVPC/VPN/DXへの経路が⾃動でTGWルートテーブルに追加する
全ての接続先に相互通信が必要なら有効化しておくと設定が簡略化できるが、後からの変更(有効化/無効化)はできないことに注意する
CLIの場合--optionsで下記設定が可能になります。
{
"AmazonSideAsn": long,
"AutoAcceptSharedAttachments": "enable"|"disable",
"DefaultRouteTableAssociation": "enable"|"disable",
"DefaultRouteTablePropagation": "enable"|"disable",
"VpnEcmpSupport": "enable"|"disable",
"DnsSupport": "enable"|"disable"
}
上記の場合特に設定していないのでデフォルト値で作成されています。
{
"AmazonSideAsn": 64512,
"AutoAcceptSharedAttachments": "disable",
"DefaultRouteTableAssociation": "enable",
"DefaultRouteTablePropagation": "enable",
"VpnEcmpSupport": "enable",
"DnsSupport": "enable"
}
アタッチメントの作成
こちらもCLIで作ってみます。
$ aws ec2 create-transit-gateway-vpc-attachment \
--transit-gateway-id tgw-079106e54d63cd110 \
--vpc-id vpc-0aa95077a4ff2bda2 \
--subnet-ids subnet-0e1a7dd8b5cc44537 \
--tag-specifications 'ResourceType=transit-gateway-attachment,Tags=[{Key="Name",Value="maintenance-poc"},{Key="Environment",Value="sandbox"}]' \
--region ap-northeast-1 \
| tee ./tgw_poc_attachment.json
{
"TransitGatewayVpcAttachment": {
"TransitGatewayAttachmentId": "tgw-attach-0160ec1881e5757b6",
"TransitGatewayId": "tgw-079106e54d63cd110",
"VpcId": "vpc-0aa95077a4ff2bda2",
"VpcOwnerId": "123456789012",
"State": "pending",
"SubnetIds": [
"subnet-0e1a7dd8b5cc44537"
],
"CreationTime": "2019-11-04T19:01:24.000Z",
"Options": {
"DnsSupport": "enable",
"Ipv6Support": "disable"
},
"Tags": [
{
"Key": "Name",
"Value": "maintenance-poc"
},
{
"Key": "Environment",
"Value": "sandbox"
}
]
}
}
TGWルートテーブルの作成
こちらもCLIで作成してみます。
aws ec2 create-transit-gateway-route-table \
--transit-gateway-id tgw-079106e54d63cd110 \
--tag-specifications 'ResourceType=transit-gateway-route-table,Tags=[{Key="Name",Value="maintenance-poc"},{Key="Environment",Value="sandbox"}]' \
--region ap-northeast-1
| tee ./tgw_poc_route_table.json
{
"TransitGatewayRouteTable": {
"TransitGatewayRouteTableId": "tgw-rtb-0219c133a90cfa92d",
"TransitGatewayId": "tgw-079106e54d63cd110",
"State": "pending",
"DefaultAssociationRouteTable": false,
"DefaultPropagationRouteTable": false,
"CreationTime": "2019-11-04T19:06:41.000Z",
"Tags": [
{
"Key": "Name",
"Value": "maintenance-poc"
},
{
"Key": "Environment",
"Value": "sandbox"
}
]
}
}
TGWルートテーブルとアタッチメントのアソシエーション
上記で作ったものをCLIで紐づけていきます。
aws ec2 associate-transit-gateway-route-table \
--transit-gateway-route-table-id tgw-rtb-0219c133a90cfa92d \
--transit-gateway-attachment-id tgw-attach-0160ec1881e5757b6 \
--region ap-northeast-1
| tee ./tgw_associate.json
エラーが発生しました。
An error occurred (Resource.AlreadyAssociated) when calling the AssociateTransitGatewayRouteTable operation: Transit Gateway Attachment tgw-attach-0160ec1881e5757b6 is already associated to a route table.
対象のアタッチメントを確認してみましょう。
{
"TransitGatewayAttachments": [
{
"TransitGatewayAttachmentId": "tgw-attach-0160ec1881e5757b6",
"TransitGatewayId": "tgw-079106e54d63cd110",
"TransitGatewayOwnerId": "123456789012",
"ResourceOwnerId": "123456789012",
"ResourceType": "vpc",
"ResourceId": "vpc-0aa95077a4ff2bda2",
"State": "available",
"Association": {
"TransitGatewayRouteTableId": "tgw-rtb-0df59aaeeac7779d1",
"State": "associated"
},
"CreationTime": "2019-11-04T19:01:24.000Z",
"Tags": [
{
"Key": "Environment",
"Value": "sandbox"
},
{
"Key": "Name",
"Value": "maintenance-poc"
}
]
}
]
}
何やら作った覚えのないルートテーブルに紐づけられていますので、ルートテーブルを確認してみます。
{
"TransitGatewayRouteTables": [
{
"TransitGatewayRouteTableId": "tgw-rtb-0219c133a90cfa92d",
"TransitGatewayId": "tgw-079106e54d63cd110",
"State": "available",
"DefaultAssociationRouteTable": false,
"DefaultPropagationRouteTable": false,
"CreationTime": "2019-11-04T19:06:41.000Z",
"Tags": [
{
"Key": "Environment",
"Value": "sandbox"
},
{
"Key": "Name",
"Value": "maintenance-poc"
}
]
},
{
"TransitGatewayRouteTableId": "tgw-rtb-0df59aaeeac7779d1",
"TransitGatewayId": "tgw-079106e54d63cd110",
"State": "available",
"DefaultAssociationRouteTable": true,
"DefaultPropagationRouteTable": true,
"CreationTime": "2019-11-04T18:53:35.000Z",
"Tags": []
}
]
}
冒頭で注意したDefaultRouteTableAssociationが悪さしているみたいですね。
正しいルートテーブルへ変更しましょう。
aws ec2 disassociate-transit-gateway-route-table \
--transit-gateway-route-table-id tgw-rtb-0df59aaeeac7779d1 \
--transit-gateway-attachment-id tgw-attach-0160ec1881e5757b6 \
--region ap-northeast-1
| tee ./tgw_disassociate.json
{
"Association": {
"TransitGatewayRouteTableId": "tgw-rtb-0df59aaeeac7779d1",
"TransitGatewayAttachmentId": "tgw-attach-0160ec1881e5757b6",
"ResourceId": "vpc-0aa95077a4ff2bda2",
"ResourceType": "vpc",
"State": "disassociating"
}
}
無事にデフォルトのルートテーブルから切り離せました。
再度任意のルートテーブルへのアソシエーションも完了しました。
$ aws ec2 describe-transit-gateway-attachments \
--transit-gateway-attachment-ids tgw-attach-0160ec1881e5757b6 \
--region ap-northeast-1
{
"TransitGatewayAttachments": [
{
"TransitGatewayAttachmentId": "tgw-attach-0160ec1881e5757b6",
"TransitGatewayId": "tgw-079106e54d63cd110",
"TransitGatewayOwnerId": "123456789012",
"ResourceOwnerId": "123456789012",
"ResourceType": "vpc",
"ResourceId": "vpc-0aa95077a4ff2bda2",
"State": "available",
"CreationTime": "2019-11-04T19:01:24.000Z",
"Tags": [
{
"Key": "Environment",
"Value": "sandbox"
},
{
"Key": "Name",
"Value": "maintenance-poc"
}
]
}
]
}
$
$ aws ec2 associate-transit-gateway-route-table \
--transit-gateway-route-table-id tgw-rtb-0219c133a90cfa92d \
--transit-gateway-attachment-id tgw-attach-0160ec1881e5757b6 \
--region ap-northeast-1
{
"Association": {
"TransitGatewayRouteTableId": "tgw-rtb-0219c133a90cfa92d",
"TransitGatewayAttachmentId": "tgw-attach-0160ec1881e5757b6",
"ResourceId": "vpc-0aa95077a4ff2bda2",
"ResourceType": "vpc",
"State": "associating"
}
}
デフォルトのルートテーブルをいじる場合はこれで問題ないのですが、任意のものを紐づけたい場合毎回この作業が発生するのは手間なのでDefaultRouteTableAssociationについてはよく考えるべきですね。
TGWルートテーブルの設定
こちらもさくっとCLIで設定してしまいましょう。
aws ec2 create-transit-gateway-route \
--destination-cidr-block 10.0.0.0/16 \
--transit-gateway-route-table-id tgw-rtb-0219c133a90cfa92d \
--transit-gateway-attachment-id tgw-attach-0160ec1881e5757b6 \
--region ap-northeast-1
| tee ./tgw_route_configure.json
{
"Route": {
"DestinationCidrBlock": "10.0.0.0/16",
"TransitGatewayAttachments": [
{
"ResourceId": "vpc-0aa95077a4ff2bda2",
"TransitGatewayAttachmentId": "tgw-attach-0160ec1881e5757b6",
"ResourceType": "vpc"
}
],
"Type": "static",
"State": "active"
}
}
VPCルートテーブルの設定
上記で作ったものをルートとして追加してみます。
aws ec2 create-route \
--destination-cidr-block 10.0.0.0/16 \
--transit-gateway-id tgw-079106e54d63cd110 \
--route-table-id rtb-0902ae39621e4aaa3 \
--region ap-northeast-1
{
"Return": true
}
$ aws ec2 describe-route-tables \
> --route-table-ids rtb-0902ae39621e4aaa3 \
> --region ap-northeast-1
{
"RouteTables": [
{
"Associations": [
{
"Main": false,
"RouteTableAssociationId": "rtbassoc-009a72a445d417a73",
"RouteTableId": "rtb-0902ae39621e4aaa3",
"SubnetId": "subnet-0e1a7dd8b5cc44537"
},
{
"Main": false,
"RouteTableAssociationId": "rtbassoc-01830131a48945c42",
"RouteTableId": "rtb-0902ae39621e4aaa3",
"SubnetId": "subnet-06fe747a862387dda"
}
],
"PropagatingVgws": [],
"RouteTableId": "rtb-0902ae39621e4aaa3",
"Routes": [
{
"DestinationCidrBlock": "10.0.0.0/16",
"TransitGatewayId": "tgw-079106e54d63cd110",
"Origin": "CreateRoute",
"State": "active"
},
{
"DestinationCidrBlock": "192.168.0.0/16",
"GatewayId": "local",
"Origin": "CreateRouteTable",
"State": "active"
},
{
"DestinationCidrBlock": "0.0.0.0/0",
"GatewayId": "igw-0a3be406fa801cef4",
"Origin": "CreateRoute",
"State": "active"
}
],
"Tags": [
{
"Key": "Name",
"Value": "maintenance-dev-public"
},
{
"Key": "Environment",
"Value": "develop"
},
{
"Key": "Service",
"Value": "maintenance"
},
{
"Key": "Region",
"Value": "ap-northeast-1"
}
],
"VpcId": "vpc-0aa95077a4ff2bda2",
"OwnerId": "123456789012"
}
]
}
無事にルートが追加されています。
あとは対向先でもアタッチメントとルートを追加して、TGWのルートテーブルにこちら側のルートテーブルを作成してあげれば疎通が取れるようになります。
[ec2-user@ip-192-168-1-139 ~]$ ping 10.0.0.37
PING 10.0.0.37 (10.0.0.37) 56(84) bytes of data.
64 bytes from 10.0.0.37: icmp_seq=1 ttl=254 time=0.879 ms
64 bytes from 10.0.0.37: icmp_seq=2 ttl=254 time=0.784 ms
64 bytes from 10.0.0.37: icmp_seq=3 ttl=254 time=0.712 ms
64 bytes from 10.0.0.37: icmp_seq=4 ttl=254 time=0.789 ms
^C
--- 10.0.0.37 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3061ms
経路制御の利用パターン
TGWを用いての経路制御の主なパターンとして下記が考えられる。
- 特定のVPC間のみ通信を許可
- 特定のVPCのリソースを共有
- インターネットへのOutbound経路を集約
- インターネットへのOutbound経路を集約 + VPC間の通信制御
上記において、Transit Gatewayの下記の特徴を以って柔軟に対応することができる。
- TGWはRoute tableを複数持てる
- 一つのアタッチメントがアソシエーションできるルートテーブルは一つのみ
- アタッチメントとルートテーブルのアソシエーションは、アタッチ メントから⼊ってくる通信がどの宛先に通信可能かを紐付け
- 通信先相互で同じルートテーブルに紐付ける必要はない
ルートテーブルの優先度は以下の順に優先される
- ロンゲストマッチ
- VPCターゲット(static/propagatedで同じ)
- VPN(static)
- DirectConnect GW(propagated)
- VPN(propagated)
まとめ
ハイブリッド/マルチVPC環境での通信はルーティングが重要なポイントになる。
Transit Gatewayの登場により以下が実現できるようになり、煩雑だったピアリングやVPN接続などがシンプルに構成できるようになった。
- ハブ型構成が可能になった
- 柔軟なルート制御が実現できる
柔軟になった分、セキュリティ周りでの穴に要注意する。
サーバーレスの基本とCI/CD構築 & 運用 〜システムは動いてからが本番だ〜
元記事 : https://dev.classmethod.jp/event/report-developers-io-2019-tokyo-serverless-ci-cd-devops/
本セッションはCX事業本部の藤井元貴さんのサーバーレスの基本的な考えや概念の解説とそれをCI/CDによって実現することで得られるメリットについてのセッションでした。
サーバーレスの基本
AWS公式の形で考えるサーバーレス設計というデザパタ集みたいなのはサーバーレス入門におすすめ
サーバーレスとはサーバーの管理を意識する必要のないサービスのこと(インフラのマネージドサービス)で、開発者は以下のような恩恵を受けられる
-
サーバー(物理)の導⼊や管理が不要
-
使いたいときにすぐ使える
-
従量課⾦なので使った時間や量に対して課⾦
-
OSバージョンアップやセキュリティパッチなどが不要
-
冗⻑化やスケールアップ/スケールアウトが⾃動
-> 結果としてやりたいこと‧作りたいものに注⼒できる
サーバレスでよく利用されるAWSサービス
- Lambda
- DynameDB
- Kinesis
- API Gateway
- CloudFormation
- S3
- Cognito
- IoT Core
これらを組み合わせてサービスやシステムを実現する。
サーバーレスの運用
システム開発における大前提として、
- 大事なのはシステムを育てていくことであり、構築して終わりではない。
- サービスのスケールとトラブルは比例する。
上記をより効率的に推進するためにはCI/CDをうまく利用して高速に開発を回すことが重要になる。
また、エラー通知なども最初期から準備してあると開発スピードの向上にインパクトが大きい。
これらを踏まえ、サーバーレス開発において重要なことは以下の3つ
- 設計・開発作業
- リリース作業
- エラー等の監視
下記はDevelopers.IO 2019 FUKUOKAで発表された資料で、サーバーレス開発を初めた方向けにおすすめの資料
サーバーレス開発の勘所
CI/CDやってみた
そもそもCI/CDとは?
- Continuous Integration:継続的インテグレーション
- いつでも正しく動くようにしておこう
- CD (Continuous Delivery):継続的デリバリー
- いつでもデプロイ(リリース)できるようにしておこう
1において具体的なアクションは、テストコードを書くこと
2において具体的なアクションは、デプロイを自動化すること
CI/CDを利用することで下記の早期発見に役立てることができる
- テストコードで見つけられないミス
- ファイルのミス:typo / syntax
- 権限エラー:IAMの不足
- 開発環境との差分によって発生するエラー
サーバーレスにおけるテストを大まかに分けると以下の2つに別れる。
- ユニットテスト
- Lambdaコードの動作確認
- Lintチェック
- E2Eテスト
- WebAPIに対するテスト
ユニットテスト
ユニットテストにおけるコツとしては、
- メソッド化(処理の分離)
- interfaceの利用
- handlerをロジックから分離する
が挙げられる。
しかし、AWSサービスに絡むテストを実施するのは難しい。(CRUD操作やR/W操作など…)
実施方法としては以下の3点をおすすめする。
- Mockを使い擬似的にリクエストを返す
- SDKを叩いたことにする -> dummy dataを返すようにする
- Interfaceを定義して利用する
- 本番用 / テスト用のコードを書く(Dependency Injection)
- LocalStackを使う
- Dockerで起動しローカルでAWSサービスが擬似的に再現ができる -> 対応サービス結構多い
Overview
LocalStack spins up the following core Cloud APIs on your local machine:
API Gateway at http://localhost:4567
Kinesis at http://localhost:4568
DynamoDB at http://localhost:4569
DynamoDB Streams at http://localhost:4570
Elasticsearch at http://localhost:4571
S3 at http://localhost:4572
Firehose at http://localhost:4573
Lambda at http://localhost:4574
SNS at http://localhost:4575
SQS at http://localhost:4576
Redshift at http://localhost:4577
ES (Elasticsearch Service) at http://localhost:4578
SES at http://localhost:4579
Route53 at http://localhost:4580
CloudFormation at http://localhost:4581
CloudWatch at http://localhost:4582
SSM at http://localhost:4583
SecretsManager at http://localhost:4584
StepFunctions at http://localhost:4585
CloudWatch Logs at http://localhost:4586
EventBridge (CloudWatch Events) at http://localhost:4587
STS at http://localhost:4592
IAM at http://localhost:4593
EC2 at http://localhost:4597
例えばDynamoDBだとendpointをローカルに書き換えるだけでふつーにSDK使える
上記のような方法を利用して、ユニットテストを実現する。
E2Eテスト
E2Eテストでの確認観点
- HTTPステータスコード
- 不正なリクエスト時、4xxになっている? 正常なリクエスト時、200になっている?
- 応答内容(Responseパラメータ)
- 期待通りの応答内容になっている?
E2Eテストの⽅法
単体テストと同じようにコードを書いており、以下のような流れで実施している
- データの準備
- DynamoDBにテスト⽤のデータを格納する
- テスト実⾏
- デプロイしたAPIを叩いてテストする(requestsライブラリ)
- データのお⽚付け
- DynamoDBのテスト⽤データを削除する
デプロイとリリース
各環境をアカウントごとに分けることで、誤操作によるシステムへの影響を軽減している。
開発 / 結合 / ステージング / 本番 の4環境
CircleCI自体には強い権限を与えない。
万が一Credentialが漏れた場合、IAM AdminAccessだと非常に危ないため。
デプロイ時に不足する権限はAssumeRoleを利用して一時的に強い権限を与える
- 指定のロールにAssumeRoleできる権限のみ持つIAMユーザー(CircleCIユーザー)を作成
- CloudFormationの操作が可能なRoleを作成をする
- CloudFormationにFullAccessを与えるRoleを作成する(ユーザーではなくCloudFormationに権限を与える)
- CircleCIユーザーがAssumeRoleを利用して、CloudFormationをキックする
- CloudFormationにてデプロイを走らせる
CI/CDで便利になるとはいえ、セキュリティには細心の注意を払わなければならない。
監視と通知、がんばるぞい
監視を設定する上でまずは以下を考える
- 知りたいこと
- なぜ知りたいのか?まで考える
- どうやって検知するか?
- CloudWatch Logs/Elasticsearch Service/SaaSなどを検討する
- 通知条件
- 閾値やエラー条件を明確にする
- 通知方法
- LambdaやSNS,SaaSなどを用いて任意の通知先に任意のタイミングで通知する
Lambda / Lambda以外 / APIヘルスチェック で監視項目をカテゴライズしている。
- Lambda監視の場合
Lambda -> CloudWatch logs -> kinesis -> Slack(Lambda)
サブスクリプションフィルタ
Lambda(非同期) -> SQS(DLQ) -> Slack(Lambda)
- Lambda以外監視の場合
Cloudwatch Alart -> SNS -> Slack(Lambda)
- API監視の場合
Route53のヘルスチェック
上記のようにカテゴリごとに検知や通知に利用するサービスを変えている。
まとめ
CI/CDを構築することが目的ではなく、CI/CDを利用して⾼速に改善を繰り返すサイクルを作る。
またそれに付随して監視内容を考え、必要な通知を実現することでより高速に改善サイクルを回すことが可能になる。
Amazon CultureとAWSの設計思想 ~マイクロサービスアーキテクチャとアジャイル開発~
本セッションはアマゾン ウェブ サービス ジャパンの亀田治伸さんによるAWSの文化や開発における思想、社内の評価制度までお聞きすることができました。
Amazonのサービス開発
Working-Backwords法を利用してサービス開発を進めていく
アイディアのフローとしては、
顧客 -> アイディア -> プレスリリース(FAQ) -> ユーザーマニュアル
といった形でユーザー体験やフィードバックを元にサービス開発へとつなげていく。
上記は、既知のことを文書化するのではなくこれからの顧客体験を明確化・詳細化するためのプロセス。
プレスリリースを書き上げること自体が目的ではない。
ワード2枚 -> それを超える場合はFAQに外だし -> 顧客体験をビジュアライズ
プレスリリースを書くためには明確に簡潔に書く必要があるため、プレスリリースを模したものをドキュメントとして共有する。
上記を元に議論して/討議して/質問する
Amazonの評価
Amazonの評価制度において他の企業と大きく違うのが以下の点
- KPI達成は論理的に起こり得ない
- 年初に立てた目標が低いからという評価がされる
- 目標はチャレンジングである必要があり、創意工夫のプロセスとその結果が評価される
- Worked, not Worked双方の考察を出す
- その過程の論理思考を評価対象とする(特にnot Workedを見られる)
- 逆にKPIの達成率はあまり考慮されない
ほぼ全ての判断はBi-Directional(引き返し可能)であり、引き返し不可能な判断は一般社員には訪れない
Narrative(文書)文化
なぜやるかは非常にシンプル
- 本人がいなくとも存続する
- パワーポイントは講演者と聴講者のリズムに依存する
- パワーポイントで発生する論理破綻は、講演者のバックグラウンドに依存する
※ちなみにここでNarrative化されたものはやがで公式ドキュメントへと進化していく
マイクロサービスアーキテクチャ
マイクロサービスアーキテクチャとはService Oriented Architecture(SOA)であり、各々が機能を提供するサービスの集まりのことである。
特徴としては以下3点
- 単一の目的
- HTTPSのAPIでのみ連携
- お互いはブラックボックスでの開発
メリット
お互い干渉が無く、シンプルな目的のもと開発が進んでいくため1つ1つのサイクルが早い
デメリット
リポジトリ爆発的に増える
Amazonはシステム元々モノリシックなシステムだあった。
密結合でありメンテナンス、ビルド・テストが困難な状況に陥っていた。
影響範囲がわからない物理的な範囲がある -> 歴が長い人しか判断できない -> 新しい人が活躍できない
結果として組織の成長阻害要因として大きなハードルになった。
マイクロサービスとスクラム開発
アマゾンは開発チームの構成においてTwo-Pizza Teamsルールを採用している。
そのチームの特徴は以下の2点
- 主体性
- 小さくそれぞれが自律的に動ける組織
- 自律性
- 何を作るか実行まで全ての権限を持つ
Two-Pizza Teamsは6-8人のチーム
スクラムは3-9人のチーム
上記を見ると混合しがちだが、性質は全く別である。
こと自律性においては開発からリリースの判断まで自分たちで決定権を握っている。
チームがリリースに対して責任を持って自分たちでリリースできないのであればマイクロサービスアーキテクチャである意味がない
-> POに持っていって、POのGOサインでリリースするスタイルとは明確に違う
これらを踏まえると果たしてマイクロサービスアーキテクチャにおいてスクラム開発とは適切なのか?
Cloud Naticveだからアジャイルは安易な考えに過ぎない
-> アジャイルだからドキュメントは後回しにしようと考えがち。
アジャイルソフトウェア開発宣言とは要約すると、顧客へ提供しうる価値の最大化を目指すこと
アマゾンのサービス開発においてNarrativeなしには開発はスタートしない。
マイクロサービスとサーバーレスの関係
マイクロサービスアーキテクチャはHTTPSのAPIでのみ連携しているため、サービスが疎結合なため実験が容易にできる
マイクロサービスにおいて、全てはリクエスト型のイベントドリブンが好ましい。
それを実現するためにサーバーレスは以下の点から親和性が高いと思う。
- リソースは伸縮可能
- REST Full, Statelessに則りセッション等は腹持ちしない
- API経由で操作
- 冪等性が保たれているためCI/CDのサイクルが早く回せる
ただし、サーバーレスはCloud Naticveアーキテクチャにおいて必須ではない(相性がいいだけ)
マイクロサービスにおけるリリース
マイクロサービスアーキテクチャにおいて各サービスはHTTPSのAPIでのみ連携しているため、APIへの改修、新規APIリリースは最大限の注意が必要
マイクロサービスにおいてAPIベースでリリースフローは変化する
API改修あり -> ドキュメンテーション -> 議論/評議
API改修なし -> リリース
まとめ
権限委譲できないのであればマイクロサービスアーキテクチャには弊害でしかならない
-> 通常のレガシーなチームより権限を与えるため
新規サービスはマイクロサービス, 既存サービスは今まで通り、という考え方もあり
マイクロサービスアーキテクチャにこだわる必要性はない。
マイクロサービスアーキテクチャにおけるAPIの扱いは慎重に行わなければならない。
AWS CDKの基本と実例
元記事 : https://dev.classmethod.jp/cloud/aws/developoers-io-2019-tokyo-cdk/
本セッションはCX事業本部の加藤諒さんによる、AWS構築の歴史とCDKの使い方や利点などをお話しいただきました。
AWS構築の歴史
| 第一世代 | 第二世代 | 第三世代 | 第四世代 |
|---|---|---|---|
| 手順書 | スクリプト | プロビジョニングツール,DOMs | CDK |
手順書
- エクセルとかにスクショぺたぺた
- デプロイに操作時間がかかる
- 人が操作するのでミスが怒る
- マネージメントコンソールは頻繁に更新される
- 手順書はいつか腐る
ちょこっとEC2ほしいとか、新しいサービスを試す時以外極力使わないほうが良い
スクリプト
- CLI/SDKを使ってAWSリソースを作成
- 冪等性・ロールバック処理の実装が必要
- デプロイ後パラメータの変更が実装
- マネージメントコンソールのアシストがない
プロビジョニングツール
- AWSリソースを宣言的に作成
- 冪等性があり継続的なデプロイを実現しやすい
- 複雑な条件分岐やループが難しい
- マネージメントコンソールのアシストがない
Document Object Models(DOMs)
- GoFormation, Tropsphere, etc -> CloudFormationを利用する
- 冪等性があり継続的なデプロイを実現しやすい
- プログラムベースなので条件分岐やループが容易
- マネージメントコンソールのアシストがない
どんどんサービスが増えてきてIaCのコード量がどんどん増えていく
CDK
- コードでAWSリソースの定義を書く
- CFnのテンプレートを生成する
- AWS公式曰く、CDKとはAWS構築のフレームワーク
コードで書けることにより…
- 型があり、IDEの支援を受けられる
- 前処理をコードでかける(makeファイル的な)
- 条件分岐やループを容易に書ける
- リソース定義を継承して拡張できる
CDKによる抽象化
例えばLambdaからデータストアへのアクセスを実現しようとした場合
- Lambda作成
- S3, DynamoDBアクセス権限を持つIAMポリシーの作成
- IAMロールの作成
- ロール、ポリシーの関連付け
- ロールとLambdaの関連付け
const lambda1 = new lambda(...);
const lambda2 = new lambda(...);
const bucket = new s3(...);
const table = new dynamodb(...);
bucket.grantReadWrite(lambda1);
bucket.grantReadWrite(lambd);
table.grantReadData(table);
cdk.jsonに環境ごとにパラメータを書ける
{
"context": {
"prj": "hoge-app",
"dev": {
"bucket_name": "hogehoge-dev"
},
"stg": {
"bucket_name": "hogehoge-stg"
},
"prd": {
"bucket_name": "hogehoge-prd"
}
},
"app": "node index"
}
AWS CDKでテストを行うべき理由
- CDKに頻繁にアップデートがある
- 2週間に1回はアップデートしているため、影響範囲を把握する必要がある
- 意図した変更が行われたか確認したい
AWS CDKのテストパターン
- Snapshot tests
- 生成されるCFn全体の差分を比較
- Fine-grained tests
- CFnリソースが存在するか比較
- 既存リソースへの破壊的な変更が無いかを検知する
- Varidations tests
- Stack作成時に受け付けるパラメータのテスト
AWS CDKを使う実際の流れ
- AWS CLIが使える状態
- Node.jsが使える状態(≧10.3)
# ディレクトリ作成
$ mkdir sample && cd sample
# バージョンを指定する場合
$ nodenv local 12.8.0
# CDKの初期設定(ディレクトリがからでない場合は--forceオプションを利用)
$ npx cdk init app --language=typescript [--force]
# ソースコード用のディレクトリ作成
$ mkdir src
# handlerファイル作成
$ vi/src/index.py
# デプロイ準備(S3とか作成) #アカウントに対して一回
$ npm run cdk [--profile hogehoge] bootstrap
# ビルド
$ npm run build
# デプロイ実施
$ npm run cdk [--profile hogehoge] deploy
# 削除
$ npm run cdk [--profile hogehoge] destroy
AWS CDKを学ぶ際に見るべきもの
AWS CDK Workshop
AWS公式チュートリアル
AWS公式ドキュメント
はてなブログ
Developers IO
CDKのテスト
クラスメソッドさんのCDK記事
最近のAuroraのアップデート使いこなし術 〜 ServerlessやMulti-Masterどんな時に利用する? 〜
本セッションはAWS事業本部 コンサルタント部 シニアソリューションアーキテクトの大栗宗さんによる、去年のre:Inventから発表されたAuroraの機能の使い分けやベストプラクティスをお話しいただきました。
Amazon Auroraとは
- re:Invent 2014から登場
- MySQLとPostgresSQLのDBエンジンが利用可能
- DBストレージ部分がクラスター化されていてスケーラビリティと高可用性を備えている
- Log Structure Storage
※興味ある方は論文を推奨
Aurora Serverless
Aurora Serverlessの特徴としては以下
- DBインスタンスをスケールしてくれる
- スケール時のApplicationインパクトは無い
- 負荷予測が困難な場合やテスト用などコスト最適化が図れる
- 通常のAuroraより割高
インスタンス切り替わりのイメージとしては以下
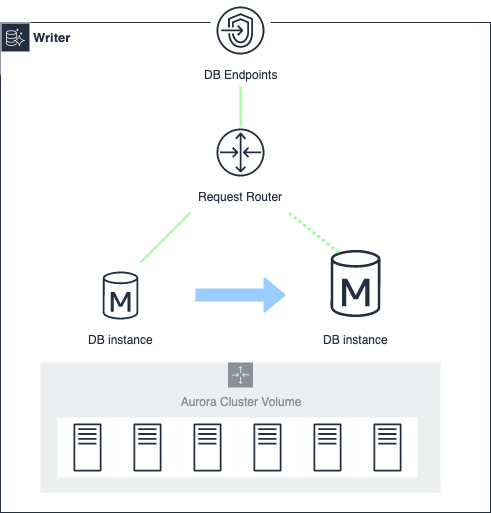
インスタンス切り替わり時に少し遅く感じるかもしれない
Aurora Parallel Query
- ストレージノード側にあるCPUを利用し処理を分割してプッシュダウン
- OLTPデータの分析クエリ
-
Aurora_pqパラメータで有効化/無効化変更可能
大量データの分析クエリはRedshiftなどを推奨
Custum Endpoint
既存のDBエンドポイントは以下の3つだった
- インスタンスエンドポイント
- クラスタエンドポイント
- リーダーエンドポイント
カスタムエンドポイントの特徴としては以下
- WriterやReaderを自由に組み合わせ可能
- WebとBIのようにワークロードごとにアクセスが分けることが可能
- 振り分けはDNSレベルでのラウンドロビン方式
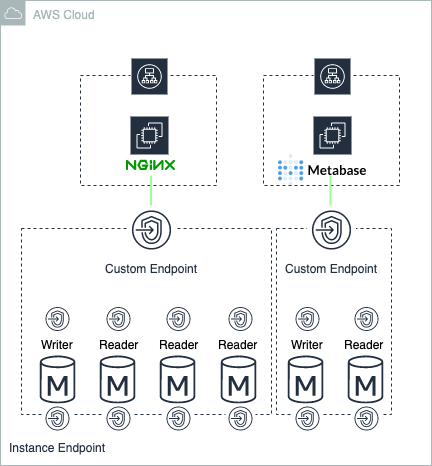
インスタンスの増減時に動作
- フェイルオーバー時Readerへのみ振り分け可
- 名前解決も追随する
- AutoScalingの増減に対応
Aurora Global Database
別リージョンへのレプリケーション
Replication Server/Agentがストレージ層で処理をする(ストレージに直接書き込む)
メリット
- RPO(目標復旧時間)が短く低価格なDRサイトが構築できる
- インスタンスの負荷が少ないため、待機系はインスタンスサイズを落としたりできる
ただし、DRリージョンのキャパシティ不足でDB起動できないかったり、切り戻し時のデータ復旧などは別途考慮が必要
Aurora MySQL ServerlessのData API
AWS API経由でAurora Serverlessにインターネットからアクセスできる機能
IAM認証が可能でhttpアクセスやトランザクションも可能
Data APIの構成
-
トランザクションなし
-
ExecuteStatement APIorBatchExecuteStatement APIを実行 -
そのままコミットされる
-
トランザクションあり
-
最初に
BeginTransaction APIを実行 -
EndpointがTransactionIDを発行してトランザクションを維持する
-
Statementを実行する
-
CommitTransactionaction API経由でCOMMITを実行してトランザクションを終了する
メリット
- VPCの外側から自由にアクセスできる
- AppSync経由でAuroraにアクセスできる
- Lambdaを挟まず実現する場合に使いやすくなる。
- Lambdaからアクセスがしやすい
Lambda VPCのコールドスタンバイが高速になった結果、利用用途が減りつつある。
Aurora MySQLのMulti-Master Cluster
Multi-Master Clusterとは、書き込み可のDBインスタンスを複数作れるのでより高い可用性を実現できる。
またAZレベルの障害でも書き込みを継続させるため、複数のAZにDBインスタンスを配置できる。
※キャッシュ情報もレプリケーションされているためパフォーマンスが落ちない
Multi-Master Clusterの特徴
- 楽天的な同時実行制御が推奨されている
- DBインスタンス間で同データを更新すると書き込み競合が発生する
- グローバルな書き込み後読み取りがサポートされている
Active/Activeの利用戦略
- シャーディングしてデータごとにアクセス先を固定する
- 更新の競合が同一インスタンス内に閉じるので性能低下を招きにくい
- ストレージが単一ボリュームなのでリシャーディング時にもデータの再配置が不要
Active/Passiveの利用戦略
- クライアント側でヘルスチェックしてフェイルオーバーを実施する
- フェイルオーバーの切り替えが高速
Multi-Master Cluster利用時の注意点
- 現在は2インスタンスが最大でReaderが作成できないため読み込みのスケールができない
- GRAWはセッション変数で制御可能だがトランザクション開始時にオーバーヘッドが発生する
- DBインスタンスの書き込み競合はデーターページ単位で発生する
競合の制約などを考慮して採用可否を十分に検討する必要がある。
Well-Architected Framework Security Pillar DeepDive~セキュリティからはじめるより良い設計の考え方~
元記事 : https://dev.classmethod.jp/cloud/aws/developers-io-2019-in-tokyo-wa-security-pillar/
本セッションはAWS事業本部の中山順博さんによる、Well-Architected Frameworkを利用したベストプラクティスやセキュリティに基づく設計などをお話しいただきました。
内容がゴツすぎて、完全に時間切れになってしまったので残念でしたw
Well-Architected Frameworkとは?
ざっくりと言ってしまえばシステム運用に関する考え方のこと。
ホワイトペーパーは内容ごっついですが非常に参考になるので、一度読んでおくべき。
AWSのソリューションアーキテクトの方から、Well-Architected Frameworkに則ったレビューを受けることが可能
SAレビューの進め方
- なるべく関係者は参加する
- Well-Architected ToolでのセルフチェックもOK
- W-Aに基づくレビューは監査ではない
- プロジェクトの早い段階で実施することを推奨
※筆者も後日AWSのご担当者とお話しタイミングでお聞きしたところ、最初はSAレビューしてもらって次回以降Well-Architected FrameworkやTrusted Advisorなどを利用してセルフレビューという形がいいんじゃないかとご提案頂きました。
設計原則
認証基盤
- 認証要素
- IDのライフサイクル管理
- 認証要素の強度
- 最小権限
トレーサビリティの担保
- アクティビティの収集
- アクティビティの監視、重要なイベントの検知
- 不正なイベントの検知
全てのレイヤーを保護
- Attack Surface
- 多層防御
自動化
- セキュリティイベントへの対応
- セキュリティリスクの抑制
保存・転送時のデータ保護
- データの分類
- データの保護
人からデータを遠ざける
- データを人が直接扱うリスク
- ツールを介した操作
設計においてセキュリティ面で考えることは腐る程にある。
なので、初期段階でやっておくべきだし全てを担保しようとするのは相当難しい。
ベストプラクティス
以下項目におけるベストプラクティスを考えていく
- 認証・認可
- 発見的統制
- インフラ保護
- データ保護
- インシデントレスポンス
認証・認可
MFAの使用を義務化する
- 基本的にはMFAの管理権限と必要なRoleを引き受ける権限のみに絞る
- MFAでログインしている時には権限を移譲する
- MFAは利用者自身で有効化できる
-
iam:CreateVirtualMFADevice/iam:EnableVMFADeviceなどのみをIAMユーザーに与える
{
"Sid": "BlockMostAccessUnlessSignedInWithMFA",
"Effect": "Deny",
"NotAction": [
"iam:CreateVirtualMFADevice",
"iam:EnableMFADevice",
"iam:ListMFADevices",
"iam:ListUsers",
"iam:ListVirtualMFADevices",
"iam:ResyncMFADevice"
],
"Resource": "*",
"Condition": {
"BoolIfExists": {
"aws:MultiFactorAuthPresent": "false"
}
}
}
{
"Sid": "AllowIndividualUserToManageTheirOwnMFA",
"Effect": "Allow",
"Action": [
"iam:CreateVirtualMFADevice",
"iam:DeleteVirtualMFADevice",
"iam:EnableMFADevice",
"iam:ResyncMFADevice"
], "Resource": [
"arn:aws:iam::*:mfa/${aws:username}",
"arn:aws:iam::*:user/${aws:username}"
]
}
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:root"
},
"Action": "sts:AssumeRole",
"Condition": {
"Bool": {
"aws:MultiFactorAuthPresent": "true"
}
}
}
}
マルチアカウント管理の課題
- IAM管理者に負担が集中する
- Permission boundaryによる権限の移譲
- 組織のセキュリティポリシーを正しく反映させること
- Organizationサービスコントロールポリシーによるアカウント単位でのアクセス制御
Permission boundaryで境界を指定する
- IAM Entityに割り当てることのできる追加のポリシー
- 従来のポリシーと境界の両方で許可されたアクションを実行
- 境界を利用してIAM管理の範囲を制御できる
- 境界内の権限付与は委任された管理者の裁量で決定
Organizationsのサービスコントロールポリシーで管理する
- OUもしくはAWSアカウントにSCPで権限付与できる
- 上位OUの権限は下位アカウントに引き継がれる
IDのライフサイクル管理
ID削除忘れがちなので下記を参考に自動化するとセキュリティ面と運用面の両面から効率化できる
awslabs/aws-well-architected-labs
ここらで時間切れになってしまったので、残念ながらセッション終了してしまいました。
まだまだ為になる部分がたくさんあったので、ご興味あるかたはスライドをご覧になってください。
Well-Architected Framework Security Pillar Deep Dive ~セキュリティからはじめるより良い設計~
AWSのすべてをコードで管理する方法〜その理想と現実〜
元記事 : https://dev.classmethod.jp/cloud/aws/aws-all-iac/
スライド : https://speakerdeck.com/hamadakoji/awsfalsequan-tewokododeguan-li-surufang-fa-sofalseli-xiang-toxian-shi
本セッションはAWS事業本部の濱田孝治(@hamako9999)さんに、AWSにおけるCloudFormationでのInfrastructure as Codeの実現方法とそのつらみなどをお話しいただきました。
CloudFormationの概要
CloudFormation記述ファイルの要素
- Resources -> 必須
- Parameters -> ほぼ必須
- Output -> ほぼ必須
- Mappings -> まあまあ使う
- Conditions -> 扱い注意
※全サービスに対応している訳ではないので注意
CloudFormationを使うメリット
- インフラの管理を簡略化できる
- インフラを簡単に複製可能
- インフラの変更管理が可能
CloudFormation実行方法
- マネコン
- CLI
せっかくコード化したのにコンソール使いますか?
CloudFormationの実行そのものに再現性がないといけない
必然的にCLIでの実行一択になる
CLIでの実行時の注意点
create-stack/update-stackではなくdeployを使う
create-stack/update-stackにはなぜか冪等性がないため
- create -> 2回目以降はエラー
- update -> 1回目はエラー
- コマンドが非同期的に実行される
deployを使う
- 新規も更新もこのコマンドで完結
- チェンジセットが作成される
- コマンドが同期的に実行される
CloudFormationのミスあるある
- stack名かぶりでcode commitをまるっと消しちゃった…警告なし
- 意図しない変更を実施しちゃった
上記はチェンジセットでremoveとかで確認できる
さらに--no-execute-chengesetで実行阻止ができる
CLIでの実行を推奨したが、実行結果はGUIが見やすい
複数リソースを作成する
普通のアーキテクチャ作ろうとするとテンプレートが膨大になる
そのため、スタックやテンプレートの分割を考える必要がある
スタックを分割するときに考えるべきこと
- スタックに含めるリソースの数
- リソースの依存関係
- ライフサイクル
- リソースの変更権限
スタック分割した際に、スタック間でのリソースを参照する方法
- クロススタック参照
- テンプレートの
Outputで指定 -
ImportResourceで呼び出せる
- ダイナミック参照
- パラメータストアやSecret Managerを参照
- シェルで頑張る
- テンプレートを呼び出す前にシェルで頑張ってパラメーターを作る
- 何気に一番汎用性は高い
ECSのタスク定義とサービスの関係のように、参照元を先に変更する必要があるリソースはクロススタック参照してはNG
運用のつらみを理解する
- スタック作成〜削除がいつまでたっても終わらない
- 対応していないプロパティがある
- 循環参照するには書き方に工夫が必要
- Conditionsに頼らない(使わない)
- CloudFormation以外でリソースが変更された時の対処
CloudFormation以外でリソース更新された場合
巻き戻る
Drift Detection(ドリフト検出)
スタックの状態
パイプラインでインフラ構築を自動化する
リポジトリからのパイプライン実行がベスト
その際パイプラインにcfn-nagを組み込んでおくことで、テンプレートから脆弱性を検査することが可能になる。
さらに踏み込んだパイプライン運用
AWS CloudFormation Validation Pipeline
This implementation guide discusses architectural considerations and configuration steps for deploying the AWS CloudFormation Validation Pipeline solution on the Amazon Web Services (AWS) Cloud. It includes links to AWS CloudFormation templates that launch and configure the AWS services required to deploy this solution using AWS best practices for security and availability.
CI/CD Pipeline for AWS CloudFormation Templates on the AWS Cloud Using AWS TaskCat
This Quick Start deployment guide describes how to deploy a continuous integration and continuous delivery (CI/CD) pipeline with AWS TaskCat on the Amazon Web Services (AWS) Cloud, to automatically test and deploy AWS CloudFormation templates from a GitHub repository. AWS CloudFormation templates automate the deployment of the CI/CD environment.
所感
初めての参加でしたが内容盛りだくさんで、今の業務に活きるものが多く得られました。
AWSのサービスは日々進化しており、キャッチアップが非常に大変な中クラスメソッドさんが積極的に発信していただけるのは感謝しかないです。
またその積極的な発信を行うため、既存のサービスに対する理解や豊富な知識があるからこそ為せることだと感じました。
私も負けないよう、新しいサービスを少しでもキャッチアップするために日々研鑽しようと改めて思わされました。
内容ゴツすぎ + 業務にかまけた結果開催から一週間以上経ってしまいました。。
時間作るのも学ばなければいけないと反省しました。。
クラスメソッドのみなさん、お疲れ様でした!