こんにちは、Iwaken Lab. Advent Calendar 2023の23日目を担当するKoyaです。
ARデバイスをOSのレイヤから考えて作れるエンジニアになることを目標に色々と頑張っています。最近、GPUアーキテクチャとGPUプログラミングの関係について勉強したら、結構面白かったので記事にしてみました。
この記事の対象者
- GPUアーキテクチャを意識してシェーダを書きたい人
- Deep Learningを勉強しているけど、GPUレベルの実装についてはよく分からない人
* Computer Graphics の側面が強いので、AI だけを勉強している人にとっては少しツラいかもしれません。
この記事を読んで分かること
- 大まかなGPUアーキテクチャ
- 一般的にGPUプログラミングで if文が良くないとされる理由
- 良い if文と悪い if文
- Shader variants による最適化の仕組み
- 良い if文 と Shader variants の違い
- Shader variants の欠点
- 遅延レンダリングのモチベーション
- Compute Shader (GPUプログラミング) の汎用性の高さ
この記事で扱わないこと
- 具体的な実装方法
この記事で書くコードは全て疑似コードです。
実装方法を知りたい方のために、実装方法が書いてあるサイトへのリンクをなるべく載せるようにします。 - 詳細なGPUアーキテクチャ
背景
「具体的にはよく分からないけど、GPUは並列に処理するからif文は良くない」とか「どんな最適化か分からないけど、Shader variantsを使うと良い感じになるらしい」 みたいな記事は割とあると思います。それらを具体的に知るために、GPUアーキテクチャを調べてみると、意味わからんくらい詳細なGPUアーキテクチャの解説が出てきて、げんなりしてしまう方もいるんじゃないでしょうか?(自分です)
もちろん、見る人によっては、それらのサイトはとても参考になると思います。ただ今回は、ソフトウェアによりすぎず、ハードウェアによりすぎない、その中間くらいの記事があったら良いなと思っていた、かつての自分のような人に向けて記事を書いてみました。
GPUの性質
GPUアーキテクチャの説明に入る前に、基本的なGPUの性質を軽くおさらいします。
GPUはCPUに比べ、High Throughput High Latency なシステムです。CPUコアの方がクロック数が高く、計算速度やメモリアクセスなどの単純な性能面ではCPUの方が良かったりします。では、なぜGPUの方が高速に計算ができるかというと、GPUは大量のデータを同時に処理できるからです。
SIMD (Single Instruction, Multiple Data)
GPUの大切な概念の一つにSIMDがあります。名前の通り、一つの命令で複数のデータを処理する、ということです。例えば、レンダリングパイプラインでは、最終的にピクセルシェーダでピクセル単位の計算を行います。このとき、命令が記述されたピクセルシェーダ1つで大量のピクセルデータを処理することになりますよね。これがSIMD的な処理です。
大まかなGPUアーキテクチャ
GPUがどのようにして複数のデータを同時に処理しているのかを知る準備として、大まかなGPUアーキテクチャを見ていきましょう。詳細なアーキテクチャはこの記事では扱わないので、興味のある方はこちらを参照してください。
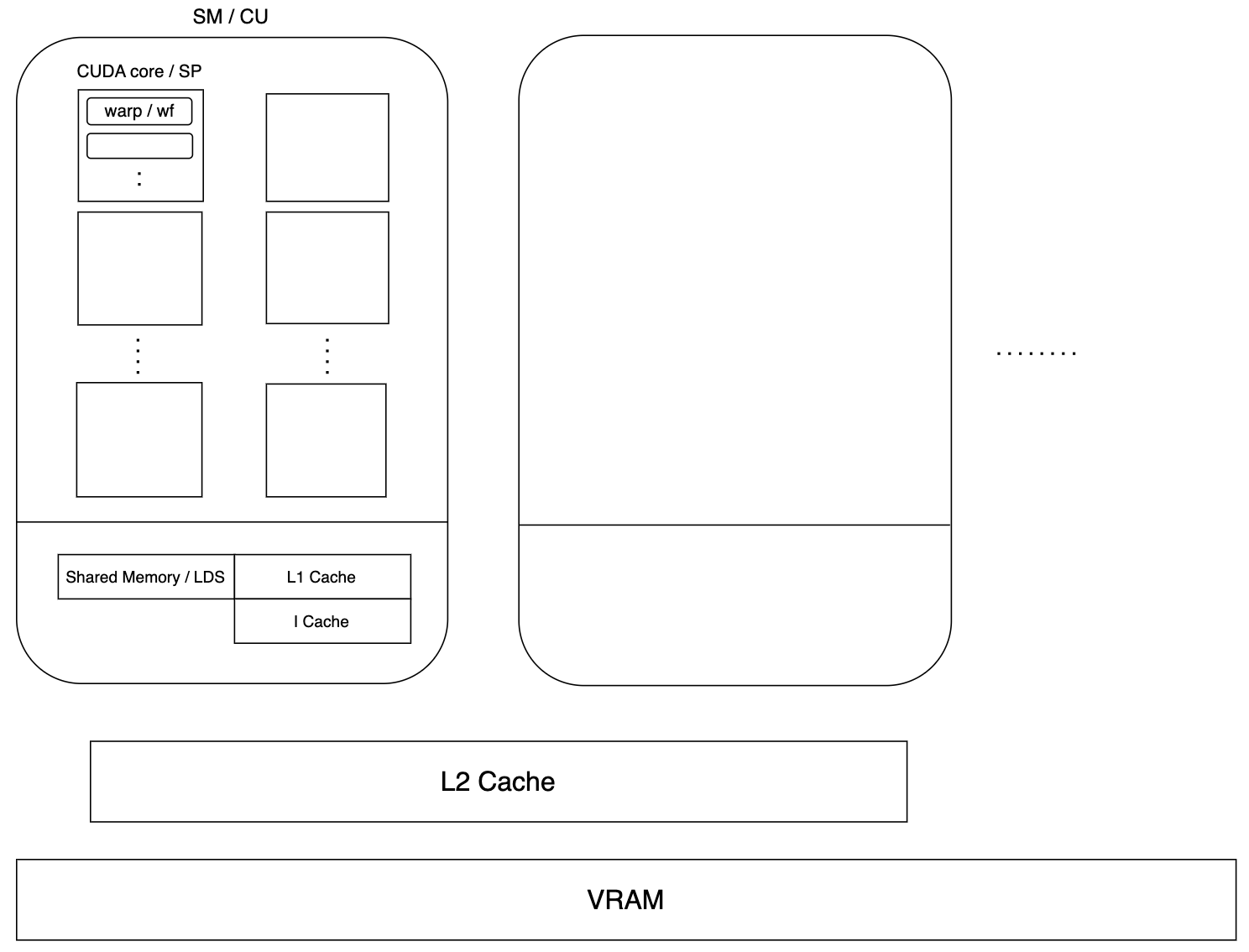
GPUを作る会社によって用語が異なります。上の図の中で / で区切られているのは、左がNVIDIA、右がAMDで使われる用語を意味します。
| NVIDIA | AMD |
|---|---|
| SM (Streaming Multiprocessors) | CU (Compute Unit) |
| CUDA core | SP (Streaming Processor) |
| Warp | wf (Wavefront) |
| Shared Memory | LDS (Local Data Stored) |
以降、この記事ではAMDの用語を使用していきます。
解説
上の図の通り、いくつかの構成要素が階層構造のようになっていて、マクロ的に見ると、GPUはCUを大量に配置する構成となっています。そして、CUの中に複数のSPがあり、各SPがWavefrontという単位で処理を実行していきます。SPがどのように処理を実行しているのかを、次の節以降で詳しく見ていきます。
キャッシュやメモリについて軽く触れておくと、GPU全体で使用されるメモリがVRAMで、CU単位で使用できるキャッシュが L1 Cache や I Cache (Instruction Cache)、複数のCU間で使用できるのが L2 Cache です。GPUの性質で述べたように、GPUのメモリアクセスは遅いため、毎回VRAMへアクセスしなくて済むようにキャッシュが用意されています。
個人的に、キャッシュやメモリの類で一番重要だと思うのは、LDSです。LDSは、CU内にある複数のコア間でデータを共有することができるメモリです。簡単な例としては、頂点シェーダのアウトプットがここに保存されるようです。LDSをうまく活用できることがCompute Shaderの有用性に繋がります。
GPUアーキテクチャと並列処理の仕組み
次のような簡単なピクセルシェーダを考えます。
main(...) {
...
float3 color = ...;
color *= g_Tint;
return color;
}
これをアセンブリ風に変換すると…
load R20 [g_Tint.x]
load R21 [g_Tint.y]
load R22 [g_Tint.z]
load R30 [color.x]
load R31 [color.y]
load R32 [color.z]
MUL R30 R30 R20
MUL R31 R31 R21
MUL R32 R32 R22
みたいな感じになります。R20やR30などはレジスタです。
この1つの命令群に対して、たくさんのピクセルデータを入力して処理することになります。(=SIMD)
ここで、CPUのマルチコア実装について考えてみましょう。CPUでのマルチコア実装の場合、各コア毎にプログラムカウンタがついているため、各コアが独立して処理を進めることができます。これは、全く異なる命令を同時に処理することができるという利点がありますが、ピクセルシェーダのようにデータが異なるだけで全く同じ命令を実行するような場合、わざわざプログラムカウンタなどのコンテキストをデータ毎に用意するのは無駄になります。(ここで言う"コンテキスト"は、コンテキストスイッチなどの文脈で使用されるもののことです)
そこで、GPUでは各Wavefrontが1つのプログラムカウンタを持つようにし、Wavefront内で複数のデータを同時に処理できるような設計になっています。つまり、下の図のように、複数のスレッド間で同じプログラムカウンタを使用するため、各スレッドが全く同じ命令を同時に実行することになります。
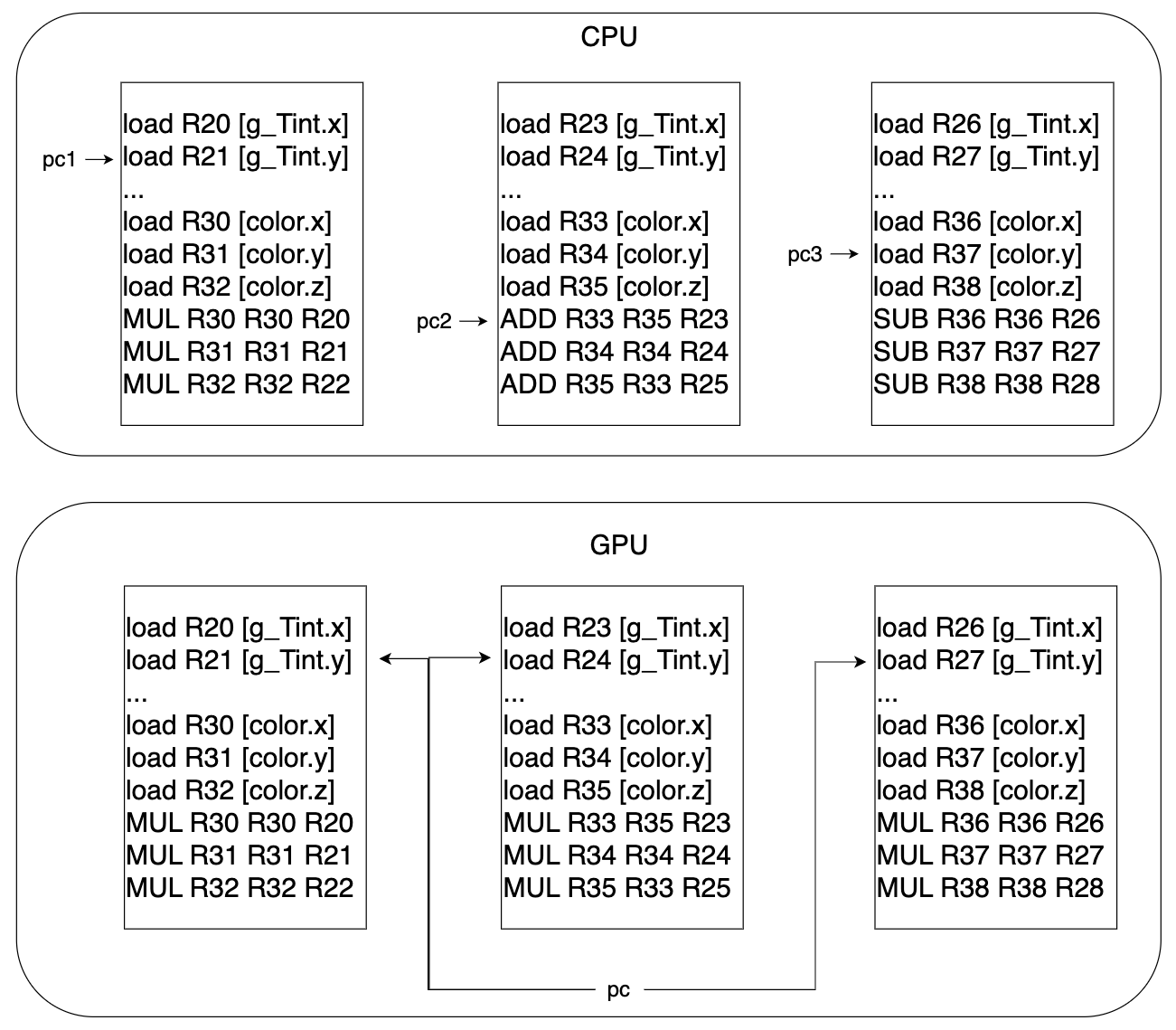
こういった処理を実現するために、GPUには Wavefront や vector register, Register File といったものがあります。
GPUの文脈で「スレッド」という言葉を使いますが、
”1スレッド=1ピクセル(の処理) ”
のように考えると理解しやすいと思います。
Streaming Processor の構成要素

‐ 追記 (2024/08/18) ‐
この図、自分で作成したのですが、RFがSP内にあるように見えちゃいそうですね...
RFは他のメモリのようにCU内にあります。
こちらのサイトにも以下のように書かれていました。
"Each compute unit has an 8KB scalar register file that is divided into 512 entries for each SIMD."
Vector Register
アセンブリ風に変換した疑似コードを思い出してください。コード内で、R20やR30といったレジスタが出てきましたが、それらは以下の画像のように、vector register というベクトル状のレジスタの中の一つのレジスタに対応します。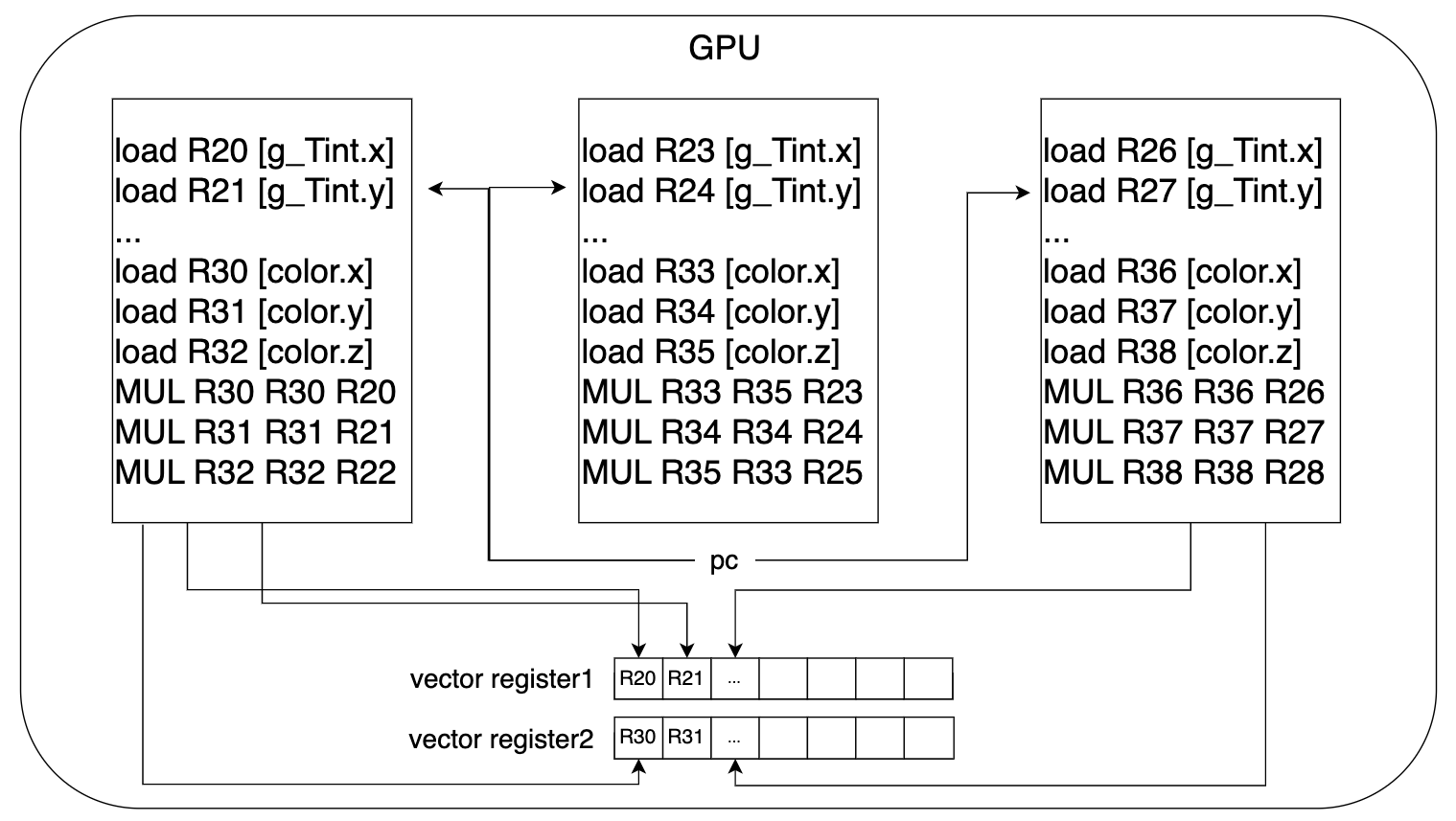
疑似コード内では掛け算が行われていましたが、vector register をベクトル演算のように掛け算することで、複数のデータに対して同時に計算を行うことができます。
一般的に、一つの vector register は 32 もしくは 64 個のレジスタで構成されることが多く、1つのレジスタが4Bほどです。個数が多いほど、より多くのデータを同時に処理することになります。
Wavefront
同時に実行されるスレッド群のことで、GPUによって、32スレッドをひとかたまりとしたWavefrontもあれば、64スレッドをひとかたまりとしたものもあります。
1つのWavefrontにつき1つのプログラムカウンタがあるため、Wavefront内のスレッドは全て同時に処理されます。
Lane
Wavefront内のスレッドは、実際にはレーンと呼ばれます。
1 thread = 1 lane = 1 pixel のように考えると楽だと思います。
RF (Register File)
厳密には、Vector Register File と Scalar Register File がありますが、とりあえず、Vector Register File だけを扱います。
Vector Register File は Vector Register群のことで、全ての Wavefronts は、Vector Register File から必要な数だけ vector register が割り当てられます。
ここまでのまとめ
- 1つのSPの中で複数のWavefrontを処理する。
- Wavefrontは同時に処理されるスレッド群で、Wavefront内のスレッドは同じプログラムカウンタを共有するため、各スレッドが全く同じ命令を同時に実行する。
- 各Wavefrontは Register File から必要な分だけ vecter register が割り当てられる。
- vecter register を用いて計算することで、複数のデータに対して同じ命令を同時に実行することができる。
ここまで、大まかなGPUアーキテクチャを眺めてきました。お疲れ様です!
GPUの中でプログラムがどのように処理されるのか、複数のデータに対してどのようにして命令が同時に実行されるのか、などのイメージがついたでしょうか?
それでは、いよいよ if文 や Shader variants の話に入ります!
Divergence(分岐)
単純な分岐の例として、以下のコードを考えてみましょう。
if (fastPath) {
do_fastRun();
}
else {
do_generalRun();
}
変数fastPathの値によって分岐先が変わるようなコードです。
Wavefront内の全てのスレッドに、この分岐が含まれたコードを走らせたとします。スレッド1では fastPath = true 、スレッド2では fastPath = false だとすると、どちらも同じWavefront内に存在するため、同じプログラムカウンタを使用するのにも関わらず、分岐先が異なってしまいます。
GPUの分岐処理には、Execution Maskというものが使われています。
Execution Maskとは、Wavefront内のスレッド数と同じサイズのビットマスクのことで、1ビットが1スレッドに対応します。スレッドに対応するビットが1なら命令を実行。0なら実行はされるけど結果は無視されます。
上の例で言うと、if の中はスレッド1では実行されるけど、スレッド2では実行されないので、Execution Mask は次のようになります。
| 1 | 0 | ... | ... | ... | ... | ... |
|---|
逆に、else の中はスレッド1では実行されないけど、スレッド2では実行されるので、Execution Mask は次のようになります。
| 0 | 1 | ... | ... | ... | ... | ... |
|---|
このように、fastPathの値に関わらず両方の分岐先を実行しておき、Execution Maskのビット値に応じて結果を採用するか破棄するかを決めるというのが、GPUでの分岐処理になります。
上の例のように単純なケースなら大きな問題にはなりませんが、ピクセルシェーダ内でfor文を使ったライティングの処理をした場合はどうでしょうか。同じWavefrontに含まれているピクセルでも、あるピクセルは5個の光源から照らされる一方で、あるピクセルは8個の光源から照らされる、というようなケースが考えられます。この場合どうなるかというと、本当は5個の光源に対する処理しか必要のないピクセルに対しても、8個分の光源に対するライティングの計算が行われ、必要ない光源3個分の計算結果は破棄されることになります。
まとめると、Wavefront内のスレッド間で分岐先が異なってしまうと、両方の分岐先を実行するため、不必要な計算をするはめになるということです。これが、一般的にGPUプログラミングで if 文を使用することが良くないとされる理由です。
Branch と Diverge の違い
Branch と Diverge はどちらも分岐するという意味ですが、少し違いがあります。
先ほど挙げた例のように、Wavefront内のスレッド間で異なる分岐先にいく場合は Diverge していますが、if文などがあってもWavefront内のスレッドが全て同じ分岐先にいくような場合、Diverge はしておらず、ただ単に Branch しているだけ、ということになります。
良い if 文と悪い if 文
GPUプログラミングで if 文を使用することが良くないとされる理由について述べてきましたが、実は、if文が悪影響を及ぼさないケースがあります。
先ほど見たように、Divergeするif文はパフォーマンスに悪影響を及ぼします。しかし、Wavefront内のスレッドが全て同じ分岐先にいくような、ただBranchするだけのif文はパフォーマンスに悪影響を及ぼしません。例えば、オブジェクト内で不変のスカラー値を用いて条件分岐した場合、オブジェクト内のピクセル間で分岐先が異なるようなことはないため、Divergeしません。
GPUアーキテクチャの説明で vector register というものがありましたが、 vector registerの他に scalar register というものがあります。vector register は Vector Register File から 各Wavefrontに割り当てられるものなので、Wavefront間で共有されませんが、scalar register は Wavefront 間で共有されます。実は、上の例で挙げた、オブジェクト内で不変のスカラー値は、このscalar register内にストアされます。そのため、Wavefront内で分岐することはなく、Divergeしないということになります。こちらの10ページ目を見るとわかるように、Scalar Registerのためのキャッシュの方が早くアクセスできるなどの利点もあります。
ぜひ読んでいただきたいオススメ記事
-
INTRO TO GPU SCALARIZATION – PART 1
こちらの記事は、Execution Maskを使った分岐をgifのアニメーション付きで解説していたり、Scalar Registerを使用することで最適化する方法について、もう少し詳しく述べられていたりして、とてもオススメです。自分の拙い説明のせいで、いまいち理解できなかった方も、こちらを読めば理解できるかもしれません! -
GPU architecture: Revisiting the SIMT execution model
こちらはスライド形式の資料で、GPUアーキテクチャについて説明されています。Execution Maskについての説明が詳しく載っています。
メモリアクセス
Memory Operation
GPUでは、レンダリングの際に似たような場所をテクスチャサンプリングすることが多いので、このスレッド群に対してはこのキャッシュラインを割り当てる、みたいなことをすることで、VRAMとキャッシュの間で無駄にデータをロード/ストアすることを回避し、効率よくデータを取得できるようにしています。
Memory Operation Latency
効率よくデータを取得できるようになるのはいいのですが、このMemory Operation自体が重い処理となっています。GPUの性能を上げるためには、より多くのデータを同時に処理するためにGPUのコア数を増やしていく必要がありますが、GPUのコア数が増えると、各コアがメモリアクセスをするため、メモリアクセス数が増えます。そうなると、ALUによる計算時間やMemory Operationを含めたGPU全体の実行時間のうち、大部分がMemory Operation完了を待機する時間になってしまいます。つまり、コア数が増えるほど、Memory Operation Latencyが長くなっていきます。
遅延の隠蔽
Memory Operation Latencyを隠蔽するためには、空いているハードウェアをなるべく無くす方法が考えられます。例えば、以下の画像のように、あるWavefrontがメモリ用のハードウェアを使用している間は、そのスレッド群に対してALUを割り当てる必要はないため、他のWavefrontがその空いているALUを使用できるようにするということです。
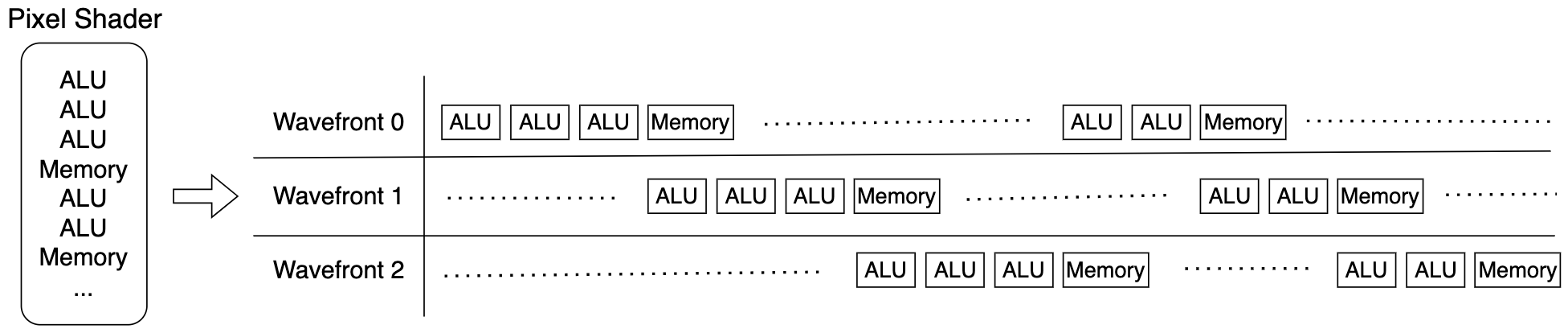
このように複数のスレッドを並行に処理するのは、なんとなくですが、CPUのシングルコアマルチスレッド実装に似ていますね。CPUのシングルコアマルチスレッドのような実装方法では、スレッドを切り替える際、また戻って来れるようにレジスタの値などを一旦メモリにストアしておき、復帰の際にロードする必要があります。このような処理のことをコンテキストスイッチと言うのですが、このコンテキストスイッチはとても重い処理で、かなりのクロックサイクルを費やします。GPUでは、大量のスレッドを実行するため、スレッドの切り替えの度にコンテキストスイッチを行う余裕はありません。したがって、GPUではコンテキストスイッチをせずにスレッドの切り替えをしたいということになります。
コンテキストスイッチをせずにスレッドの切り替えをするには、どうしたら良いでしょうか? そもそも、CPUのマルチスレッド実装でレジスタの値をメモリにストアしないといけないのは、複数のスレッドが同じレジスタを使用するためです。そこで、GPUではスレッド群毎に異なるレジスタを割り当てることで、常にスレッドのコンテキストがアクティブな状態でいられるようにしています。例えば、3つのWavefrontを並行に走らせるなら、1つのWavefrontに1つのレジスタを割り当てるようにすることで、Wavefrontの切り替え時にレジスタの値をメモリにストアしたりする必要がなくなります。
GPUアーキテクチャの説明の際に、Register Fileの説明で、「全ての Wavefronts は、Vector Register File から必要な数だけ vector register が割り当てられる」と何気なく述べていますが、これを事前にやっておくことでコンテキストスイッチ無しでのスレッド切り替えが可能になるので、実は重要な話でした。
Saturate GPU !
GPUは物理的な資源ですから、もちろん、vector register の数にも限りがあります。
例えば、Register File内のvector registerの数が128個で、1つのWavefrontあたり40個のvector registerを必要とするピクセルシェーダを実行する場合、$\lfloor128/40\rfloor=3$つのWavefrontしか並行に走らせることができないということになります。
ピクセルシェーダを修正して、1Wavefrontあたり20個のvector registerだけで良いことになったら、6つのWavefrontを並行に実行することができます。
より多くのWavefrontを並行に実行することができると、より長く遅延を隠蔽することに繋がるため、結果的にスループットが向上します。
このように、より多くのWavefrontを走らせたりして、GPUのハードウェア資源を余すことなく使用することを英語で "saturate GPU" と言ったりします。
GPUアーキテクチャを意識したGPUプログラミングでは、"シェーダが使用するレジスタの数を減らして、GPUを saturate する" というのが肝になリます。
Shader variants/Permutations
Shader variants の説明
Scalar Registerを使用したスカラー値による分岐(scalar if)は Diverge しないため、パーフォーマンスに悪影響が出ないと言う話をしました。
scalar if 以外にも分岐させる方法があります。それが Shader variants です。Shader permutations とも呼ばれます。
Shader variantsは、簡単に言うと #if を使った分岐で、ランタイムでの動的な分岐を可能にします。
例として、以下のように、使用するテクスチャの数が異なるオブジェクトの描画を考えてみましょう。
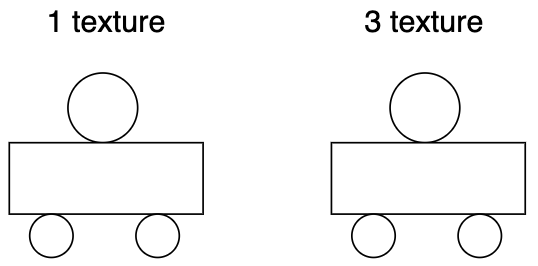
テクスチャの数によって処理を分けるピクセルシェーダを Shader variants を使って書くと、以下のような感じになります。
...
sample(Tex0);
#if USE_MORE_TEX
sample(Tex1);
sample(Tex2);
#endif
...
Shader variantsを使った最適化は、コンパイル時に # 記号を目印にして、たくさんの組み合わせを作り、何回もコンパイルしておくことで、ランタイム中にその中から最適なものを採用することを可能にします。したがって、Shader variantsを使用すると、ランタイムでの動的な分岐が実質的に実現可能となります。
scalar if と Shader variants を使った分岐の違い
テクスチャの数が異なるオブジェクトの描画の例では、Shader variantsを使用しない、次のような実装も考えられます。
...
sample(Tex0);
if (g_useT1)
sample(Tex1);
if (g_useT2)
sample(Tex2);
g_useT1やg_use2は、オブジェクト毎のインスタンスでスカラー値のため、Diverge しません (scalar if)。
では、この実装と Shader variants を使った実装の違いは何でしょうか?
それは、割り当てられるレジスタの数です。
scalar ifを使った分岐では、テクスチャが1つのオブジェクトの描画でも、テクスチャ3つ分のレジスタが必要となります。一方で、Shader variantsを使用した実装では、最適な組み合わせでコンパイルされたものを採用するため、使用するレジスタの個数も最適化されており、テクスチャ1つ分のレジスタだけ割り当てられます。
使用するレジスタの数が少ないと、より多くのWavefrontを並行処理することができ、GPUをよりsaturateできるため、スループットを上げることができるのでした。
Permutation explosion
万能に思えるShader variantsにも欠点があります。
それは、組み合わせの数が膨大なときに、ビルド・ランタイムの両方においてパフォーマンスが落ちてしまうことです。
例えば、以下のように for文を使い、光源の種類に応じてシャドウマップの使用・不使用を分けるとします。
for (i in [obj.g_numLights]) {
Light l = gLight[i];
#ifdef do_Point
PointLight(l, ...);
#endif
#ifdef do_Spot
SpotLight(l, ...);
#endif
DirectionalLight(l, ...);
}
シーンの中には様々なオブジェクトやマテリアルがありますから、それらが持つピクセルシェーダがこのライティングの処理を含んでいた場合、組み合わせの数が爆発的に増えてしまいます。
通常、全ての組み合わせでコンパイルされてからメモリにおかれますが、1つのピクセルシェーダあたり何十個もの予備の組み合わせがある場合、全てをストックしておくメモリスペースはありませんし、もしストックできたとしても、実行時に大量の組み合わせの中から最適なものを選ぶのに時間がかかってしまいます。
それでは、Shader variantsを使わずに、単純な if文を使って実装するべきかというと、そういうわけにもいきません。次の画像を見てください。

オブジェクトの場所によっては、照らされる光源が1個だったり3個だったりするため、オブジェクト内で Diverge してしまいます。
scalar ifも使えない上、Shader variantsも使えないという困った状況になりました。
遅延レンダリングの出番です。
ぜひ読んでほしいオススメ記事
-
(Unity) Shader Compiling
UnityのShader variantsを使った動的な分岐処理の実装について書かれています。 -
The Shader Permutation Problem - Part 1: How Did We Get Here?
Shader variantsのデメリットについて、たくさん書かれています。
ぜひ視聴してほしいオススメYouTube
-
UNITY SHADER VARIANTS - TIPS to Speed Up Your Build Time!
Shader variantsの軽い説明とビルド時間の短縮方法について説明されています。 -
Unityのビルド時間を大幅削減!?Shader Variant Prefilteringの紹介
Shader variantsのビルド時間の短縮方法について紹介されています。
遅延レンダリング(Deferred Rendering)
ピクセルシェーダ内でライティングの場合分けをすると、オブジェクトやマテリアルがたくさんあるときに、組み合わせが爆発的に増える"permutation explosion"となってしまうのでした。それならば、通常のレンダリングパスではライティングを行わず、一度Render Targetに描画してから、スクリーンスペース上でライティングの計算を行えばいいのではないか、というアイデアが遅延レンダリングです。
つまり、レンダリングを2つのパスに分けます。
最初のパスでは、ライティング部分をくり抜いたピクセルシェーダを使って、ライティングに必要な情報をG-bufferというものに書き出します。具体的には、depth, albedo/diffuse/color, normal, specular/material IDなどがあるでしょうか。Offscreen Renderingの要領で、それぞれRender Targetを用意し、1つ1つピクセルシェーダを通してG-bufferへ書き込んでいきます。
次のパスでは、前のパスで書き出したG-bufferを用いてライティングの処理を行います。このとき、オブジェクト毎ではなくスクリーンスペースに対して行われるため、permutation explosionが大幅に緩和されます。デメリットとしては、オブジェクト固有の情報を扱うことができなくなったため、柔軟性が低いことがあります。
visibility buffer
最近では、G-buffer ではなく visibility buffer というものを使うことで、柔軟性を上げることができるようです。G-buffer には albedo や normal map を書き込んでいましたが、visibility buffer にはオブジェクトIDを書き込みます。これにより、どのメッシュ、どの triangle index が、どのピクセルに対応しているのかを知ることができるため、ライティング時にジオメトリを再構成することができます。
再構成に時間がかかってしまいますが、G-buffer よりもメモリにストアするものがシンプルなため、memory transfer が少ないです。また、G-buffer はフォーマットが決まっているため、normal map を2種類ストアするみたいなことはできませんが、visibility buffer ではジオメトリを再構成するため、より柔軟な処理が可能になります。
Tile-Based Deferred Rendering
遅延レンダリングの導入により、permutation explosion を防ぐことができましたが、遅延レンダリングの方のパスには for文があります。Divergence(分岐)のところで、この処理が良くないということを説明し、ぜひ読んでいただきたいオススメ記事としてこちらを紹介しました。この記事のPart2の方で、for文を用いたライティングの最適化が説明されています。Part2の方を少し読んでみると、スクリーンスペースがタイル状に分割されているような図が出てきます。このように、スクリーンスペースを小さいタイル状に分割してライティングする手法を Tile-Based Rendering と言います。1つのタイルは大体、8x8 か 16x16 の大きさです。
各タイルが、それが影響を受ける点源のリストを持つことで、タイル毎にライティングをする際に、影響の受けない点源の処理を省くことができます。タイル内のピクセルは大体同じ点源から影響を受けるので、Shader variants を使わなくても Diverge する確率が低いです。Shader variants を使って組み合わせを生成した場合でも、スクリーンスペースに対してのレンダリングなので組み合わせの数が少なく、permutation explosion しません。
Tile-Based Deferred Rendering は、early z test の際に、オブジェクトのdepthのmin, maxをとっておき、それを元にライティングを行います。min, max の取り方としては、mini frustum というものを用いたものや、ハードウェアの hierarchy depth buffer を利用したものなど、色々あるようです。詳細を知りたい方は、この記事の最後に挙げられているおすすめ記事を参照してください。
Quad
こちらのYouTubeをご覧になられたことあるでしょうか?
大変分かりやすくシェーダについて解説されている動画なのですが、ピクセルシェーダでは隣接する 2x2 のピクセルが同時に処理されるというお話があります。この 2x2 のピクセルのことを Quad と言います。
vector registerを思い返してみましょう。vector registerは 32 あるいは 64 個のレジスタがベクトル状に並べられたもので、ここに入っているデータが同時に処理されるのでした。
Quadは、以下のように vector register 内で必ず隣接するように配置されます。
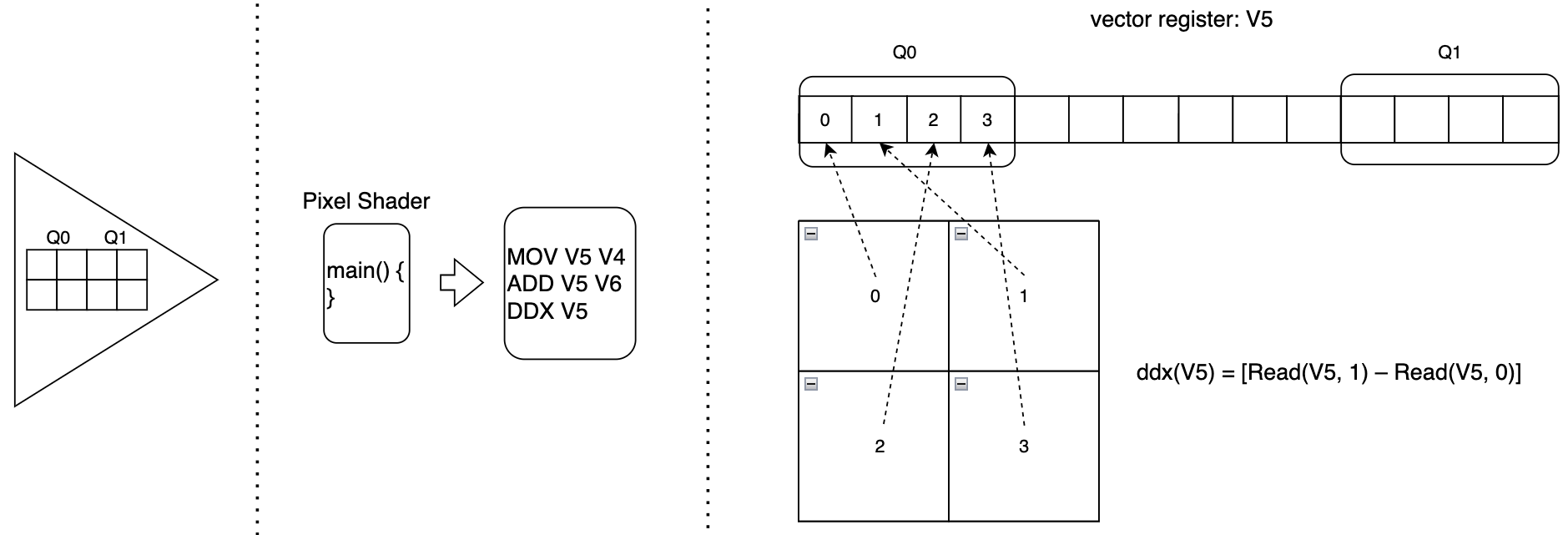
そのため、図にあるように、$ddx(V5) = [Read(V5, 1) - Read(V5, 0)]$ のようにして、ピクセル間の差分を算出できるというわけです。
ちなみに、Mipmap の選定は、テクスチャの解像度からピクセル間の差分を計算し、ddx の値に近いものを選ぶことで実現されます。
例えば、ある Mipmap level のテクスチャの解像度が 1024x1024 であれば、$1/1024 = 0.001$がピクセル間の差分となり、これが ddx の値とほぼ一致していれば、その Mipmap level のテクスチャが採用されます。
上の例では、2つのQuadが同じジオメトリにありますが、以下のように、離れたジオメトリにあるQuad同士でも、同じ vector register 上に入ってしまうことがありえます。

遠く離れたジオメトリに位置するQuadは、点源から受ける影響が大きく異なる可能性が高いです。Pixel Shader内で分岐を描くことが良くない、ということを再認識していただけたでしょうか。
一方で、Tile-Based Deferred Rendering では、タイルという小さい単位に区切って処理するため、遠くはなれたジオメトリの中にある Quads が同じ vector register に入ってしまうことを回避できます。
Compute Shader
遅延レンダリングの応用として、Tile-Based Deferred Rendering について扱いました。
当たり前のように「スクリーンスペースをタイルに分割して〜」とか言っていましたが、冷静に考えてみると、ピクセルシェーダでどうやったらそんな実装ができるんだ?という疑問が残ります。実は、Tile-Based Deferred Rendering は Compute Shader によって実装されます。
Compute Shaderは、通常のレンダリングパイプラインからは独立して動作することができます。GPUがいくら並列処理に強かろうが、通常のレンダリングパイプラインでは Vertex Shader → … → Pixel Shader という一連の流れだけはどうやっても直列になっていました。Compute Shaderは、レンダリングパイプラインと並列に動作可能なため、より柔軟でオーバヘッドの少ない処理を行うことができます。
C++ と Compute Shaderの疑似コード
// C++の疑似コード
Dispatch(x, y, z); // x * y * z = number of groups
// 例: Dipatch(1920/8, 1080/8, 1);
// Compute Shaderの疑似コード
[numthreads(8, 8, 1)] // size of one group
void CSMain(uint groupId, uint threadId) {
uint2 coord = numthreads * groupId + threadId;
...
SyncBarrier(); // wait for all threads in group
...
}
- Dispatch()
パイプラインにおける draw call で、compute shader を走らせる命令です。 - [numthreads(8, 8, 1)]
1グループあたり 8x8 = 64 スレッドという意味。
1グループあたりのスレッド数には上限があります。
1つのグループ内のスレッドは、groupsharedというキーワードを使うことで、LDSでメモリを共有することができます。 - uint2 coord = numthreads * groupId + threadId;
引数から処理対象のスレッドを特定することができます。 - SyncBarrier()
対象のスレッドと同じグループにいる全てのスレッドがこの処理を終えるまで待機して、同期します。
正確な文法などについては、こちらを参考にしてください。
GPUアーキテクチャと Compute Shader
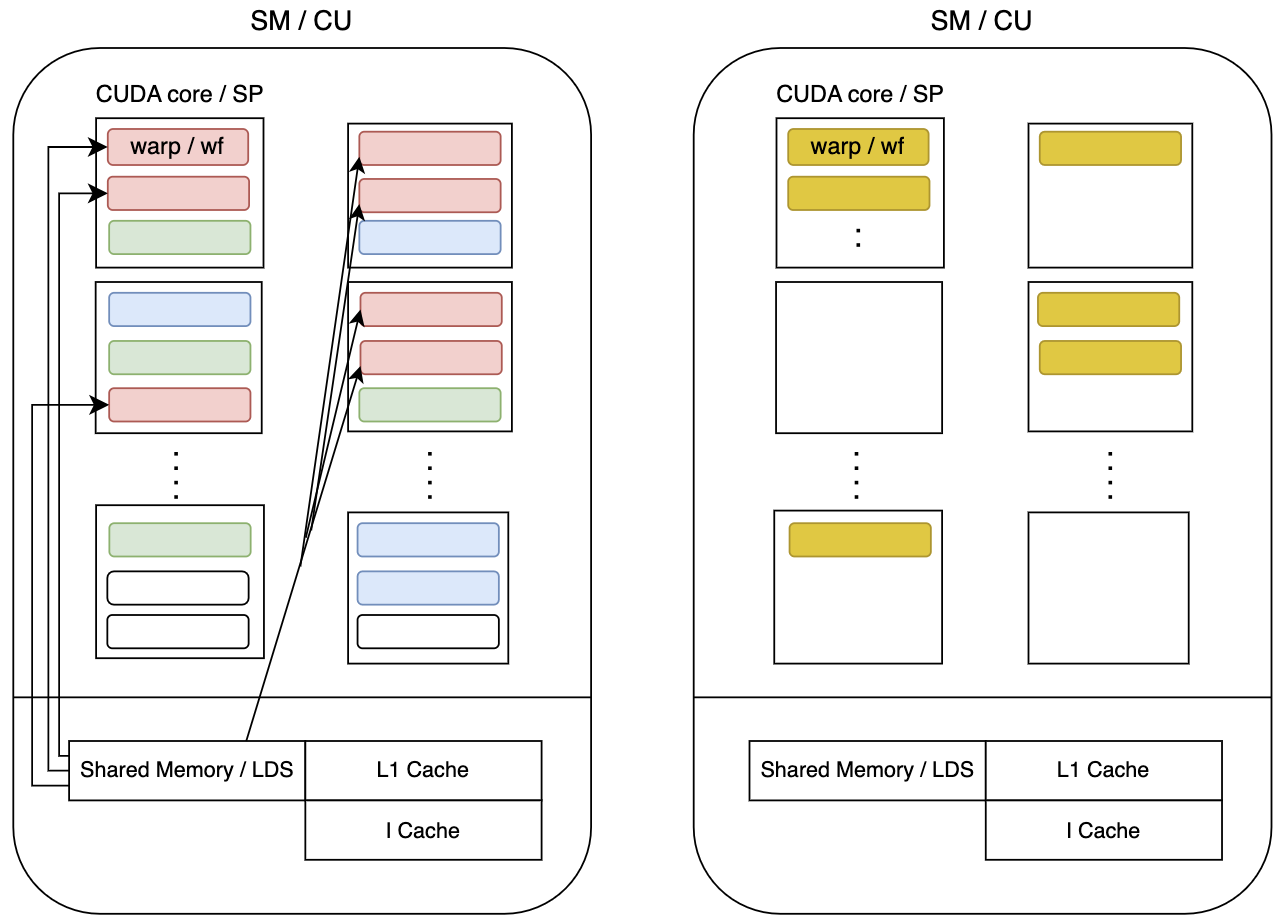
スレッドのグループ毎に色分けしてみました。
1グループ内のスレッドが同じCU内に入りきらない場合、そのグループのスレッド全てが次のCUに入れられます。理由は、1グループ内のスレッドがVRAMではなく、LDSでメモリを共有するためです。
黄色のグループ見てみると、左のCUの下に空きのあるコアがありますが、全部入り切らないため、右側のCUに入れられています。
以上のことを踏まえて、いくつかの例を眺めてみましょう。
Motion Blur
// 疑似コード1
CS_Blur(...) {
for (int dx = -5; dx <= 5; ++dx) {
for (int dy = -5; dy <=5; ++dy) {
pixel = screen_buf[coord + (dx, dy)];
accumulate += pixel * kernelValue;
}
}
}
// 疑似コード2
// Having grouop shared memory with pixels fetched into LDS
groupshared float4 lds_pixel[64][64]
[numthreads(64, 64, 1)]
CS_Blur(...) {
pixel = screen_buf[coord];
lds_pixel[local_coord] = pixel;
GroupSync();
...
Blur using lds_pixel;
...
}
どちらもMotion Blurを実装しています。
疑似コード2では、LDSをプライベートなキャッシュのように使用しているのがポイントです。LDSへのアクセスは、L1・L2キャッシュを使用したGPUメモリアクセスよりも高速です。
Binary Reduction
// 32個の数字の中から最小値を求める疑似コード
[numthreads(32, 1, 1)]
CS_main(...) {
float myValue = buf[coord];
if (myIndex < 16)
myValue = Min(MyValue, ReadLane(MyValue, MyIndex + 16));
if (myIndex < 8)
myValue = Min(MyValue, ReadLane(MyValue, MyIndex + 8));
...
}
これを図にしてみると、以下のようになります。
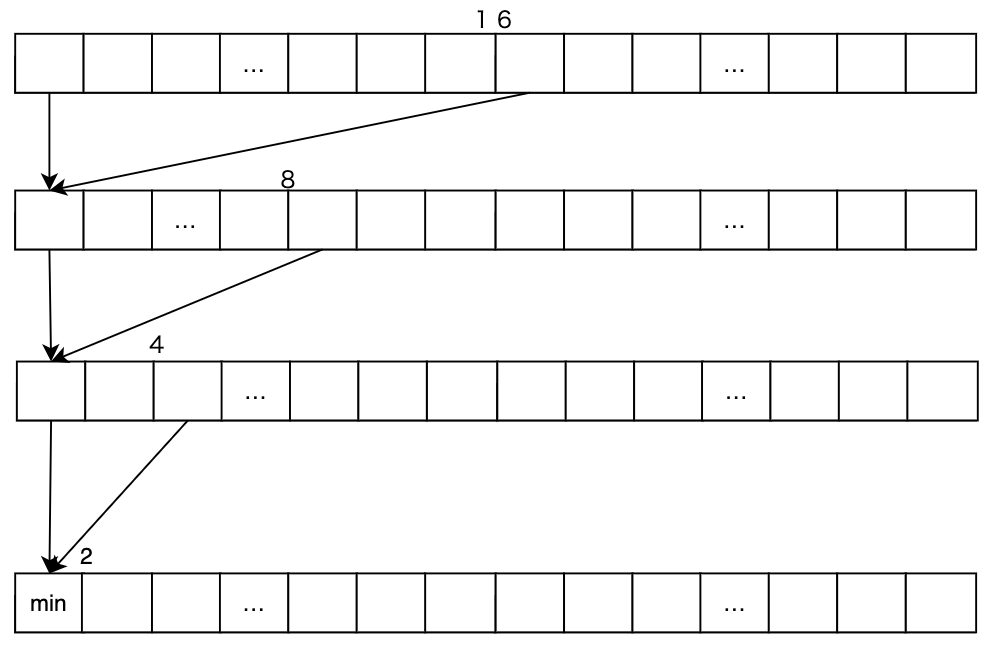
このように Compute Shader を使用すると、超高速に最小値を求めることもできます。
さらに、これをLDSを使って階層的に構成すると…
// 1024個の数字の中から最小値を求める疑似コード
groupshared float lds_mins[1024/32];
[numthreads(1024, 1, 1)]
CS_main(...) {
Read 32 values;
Binary reduce and Get one value;
lds_mins[myIndex/32] = reducedMin;
Sync();
...
}
このように、"32スレッドずつ処理をしながら、それぞれの最小値をLDSにストアしていき、最終的にLDSに入れられたデータの中から最小値を求める" といったようなことが可能になります。
Async Compute
既に述べたように、頂点シェーダやピクセルシェーダはシリアルなパイプライン内での実行となっているため、Idle状態の状態が多くなることがボトルネックになったりするのですが、Async Compute を用いて隙間時間に処理を行うことで、GPUをより効率的に使用することができます。
ぜひ読んでほしいオススメ記事など
- Compute Shader の詳細や実装例
- Tile-Based Deferred Rendering について
- その他
-
C++で学ぶディープラーニング
CUDAプログラミングでGPUプログラミングをするところからフルスクラッチでCNNを作れるようです。 - About G-Buffers in Games (JP: ゲームでのG-Buffer)
-
C++で学ぶディープラーニング
最後に
書き始めた時に想定していたよりも長くなってしまいました…
この記事では踏み込まなかったことはたくさんあるので、ぜひオススメ記事やサイトなどを読んでいただけると嬉しいです。
実は、学部生の頃はAIの研究をしていたのですが、正直、GPUレベルのプログラミングは意識したことがありませんでした。今回、オススメ記事にある Tile-Based Deferred Rendering の実装方法を眺めたときに、なんとなくCNNの実装方法がイメージできたような気がして嬉しかったです。
ここまで読んでいただき、ありがとうございます!お疲れ様でした!
次回の Iwaken Lab. Advent Calendar 2023 は Kuni さんの記事です。
お楽しみに!