はじめに
自然言語処理初めてやります。わくわく。
この記事はQiita x COTOHA APIプレゼント企画】COTOHA APIで、テキスト解析をしてみよう!に参加しています。 景品ほしすぎ! 投稿間に合った。
早速本題。今からやること。
最初にざっと何やるか紹介します。
できたのが以下のやつ↓
python3 bubuduke.py "ヘタクソ"
「お上手どすな」
こんな感じの京都弁翻訳機を作っていきます。
ぶぶ漬けおいしい!やったー!

本記事の流れ
- とりあえずCOTOHA APIを使ってみる(初めて使いました)
- 自然言語処理って何
- テキストを自然言語処理してみる
という流れで、気がついたら上のような便利ツールができているわけですね。めっちゃ簡単。
とりあえずCOTOHA APIを使えるようにする
ここから今すぐ無料登録。メールアドレスを送信してアカウントを作りましょう。できたらログイン。そしたらこんな画面になる。(ここまで宣伝)
このサイトについてはあとでIDとか使うだけなのでこれで一旦終わり。
自然言語処理って何
めっちゃ簡単にいうと人間が普段使っている言葉(=自然言語)を処理すること。いや、そのままやないかい。
これの何が難しいかと言うと、自然言語、中でも日本語がwell-definedでない ということ。
日本語はwell-definedでない
「well-definedでない」というのは、定義によって一意の解釈又は値が割り当てられないということ。
ここでは一文に対して複数の解釈が考えられると言うことですね。
簡単な例を考えてみました。以下の通り。

これを見てうんこを流しちゃダメだと思う人間はいないですよね。
ただ、この文章を文字通り擬似コードで書いてみるとこうなります。
if 流すもの == "トイレットペーパー" then
流していい
あれ?うんこ流せない気がしてきました。
京都弁はその極みである。
今回取り扱ってみようと思った京都弁。例えばこんな感じ。

上のは有名なぶぶ漬けですね。
ぶぶ漬けというのは京都弁ではお茶漬けのことを指すはず。
それなのに、ぶぶ漬けを勧められるということは、もう帰ってくれと言う意味になるんですね。
訳がわからない。
とにかく京都弁は陰湿
もう1つ例を上げてみます。

ごめんなさい脱線が長いですね。
その他にも嫌味な京都言葉がたくさんあるのですが割愛。気になる方はこちらが色々載ってていいと思います。
要するに、京都弁は陰湿で、well-definedでない言葉の極み。
自然言語処理では、こういった自然言語から、単語や構文を情報に照らし合わせて処理していきます。
結局自然言語についての説明しかしていないのですが。今から日本語という自然言語を処理し、こういった陰湿な京都弁"風"のリプライができるbotを実装していきます。
テキストを自然言語処理してみる
ひとまずbotを作る部分は無視して、自然言語処理をやっていきます。
正直言ってここが本質なのでここ以外読まなくていいです。
ここからが本質なのですがCOTOHA 凄すぎてすぐ終わっちゃった。
サンプル1
とりあえず入力を受け付けて、軽く処理してみます。
文章を受け取って名詞だけを返すデモです。
名作を参考にしました。
ライブラリの威力が半端なさすぎて何もわかってなくてもできてしまう。
まずライブラリを入れます。
pip install git+https://github.com/obilixilido/cotoha-nlp.git
作ったコードがこれ。
from cotoha_nlp.parse import Parser
parser = Parser("Client ID",
"Client secret",
"https://api.ce-cotoha.com/api/dev/nlp",
"https://api.ce-cotoha.com/v1/oauth/accesstokens"
)
s = parser.parse(input())
print(" ".join([token.form for token in s.tokens if token.pos in ["名詞"]]))
あとでもう1度掲載しますが、サンプルコードはGitHubに上げているのでそちらもご覧になってください。
このコードを実行してみます。python ファイル名 文字列の順で入力すると文字列を処理した結果が返ってきます。
python samplecode1.py 春はあけぼの。そうだ、京都行こう。
そしたら返ってくる。
>>春 あけぼの 京都
いかがでしょうか。これだけのコードで十分立派な自然言語処理ができました。やばすぎ。
何も理解してない。
京都弁"風"変換スクリプト完成形
続いて、京都弁風botの実装に取り掛かっていこうと思います。
先ほどのサイトからスクレイピングして、抽出した名詞と一致する日本語直訳があればその京都弁を返す。
普通の日本語の入力から作るための流れはこう。
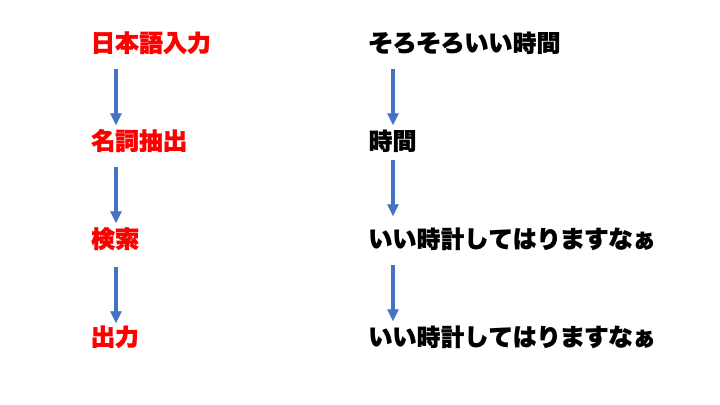
スクレイピングをするのでちょっとライブラリを入れます。
pip3 install requests
pip3 install beautifulsoup4
こんな感じになりました。
from cotoha_nlp.parse import Parser
import requests
from bs4 import BeautifulSoup
import re
parser = Parser("Client ID",
"Client secret",
"https://api.ce-cotoha.com/api/dev/nlp",
"https://api.ce-cotoha.com/v1/oauth/accesstokens"
)
# input
s = parser.parse(input())
# get nouns
nouns = [token.form for token in s.tokens if token.pos in ["名詞"]]
# web scraping
r = requests.get('https://iirou.com/kazoekata/')
soup = BeautifulSoup(r.content, "html.parser")
block = soup.find_all("p")
# output
for noun in nouns:
for tag in block:
if noun in str(tag):
#strongタグ内にある京都弁を切り出し
output = re.findall('<strong>.*</strong>', str(tag))
out = output[0]
out = out.replace("<strong>", "")
out = out.replace("</strong>", "")
print(out)
早速実行。
python bubuduke.py "迷惑やで"
陰湿な京都弁が返ってくる!
>>「お嬢ちゃん、ピアノ上手になったなぁw」
これで自然言語処理パートは終わり。
次回、botを作るだけですね。ジャンルも変わりますし本記事はここまで。
次回やりたいこと
LINEのbotにしたい。
もう少し精度はあげたい。完全一致していない単語でも拾いたい。今のところ対応してる単語がめっちゃ少ないので。
その辺はまた今度書きます。
おわりに
今回使ったコードのリポジトリ
リファレンス
任意の言語、ライブラリ、フレームワーク等では結局公式リファレンスが1番使えます。
最後まで読んでいただきありがとうございました。
景品欲しすぎなので LGTMお願いします。
LGTMが受け付けない方はこの辺参考にいいねにしてね。