はじめに
最近、海外を中心にOCRや文書画像解析技術に関連する新しいサービスが活発にリリースされています。本記事では、文書画像解析サービスを構成する要素技術や論文についての内容を雑多に紹介したいと思います。論文は文書画像解析OSSにも採用されていたりするようなものを中心に紹介します。
文書画像解析とは
文書画像解析とは画像として保存された文書データを解析する技術の総称です。例えば、写真で撮影したレシートや請求書の画像から金額情報を抽出したり、画像として保存されたPDFから情報を抽出するようなユースケースに対して適用する技術です。最近はLLMの流行の件もあり、RAGを用いたLLMへのデータ連携、LLMの学習データセットの構築のためのデータ抽出といった目的のために新しいサービスなども登場しています。
研究では、Document Image AnalysisやDocument Understadingといった分野になります。CVPRなどコンピュータービジョン系の学会で扱われるのはもちろんですが、文書画像解析を専門に扱うInternational Conference on Document Analysis and Recognition (ICDAR)といった世界的な学会も存在しまます。
文書画像解析技術要素としては、画像から文字情報を取得する技術であるOCRが最もイメージしやすいと思います。文書画像解析はOCR以外にも様々なタスクがありますので、紹介したいと思います。
OCR(Optical Character Recognition)
画像内に存在するテキストの位置や文字クラスを識別する技術です。OCRといっても実はさらにいくつかの分野に細分化されます。
書類文字認識(Document Text Recognitioin)
紙に書かれた文字情報を抽出、認識するタスクです。レイアウトや文字の記入方法によって、読み取り難易度や採用される技術が異なります。
文字の記入方法による違い
- 活字OCR : 機械で印字された文字を認識します
- 手書きOCR : 人手によって書かれた文字を認識します
- 数式OCR : AIを用いて、数式を認識し、LaTex形式の文字列などに変換します。
文書レイアウトによる違い
-
定型書類OCR : 書類のレイアウトが固定されており、読み取りたい文字の位置が決まっているような書類を対象とします。免許証やマイナンバーカードなど該当します。これらは正しく位置合わせさえできていれば、事前に読み取りたい情報が含まれる領域を指定し、その領域の文字を読み取ることで解決できます。
-
非定型書類OCR : 入力される書類のレイアウトが決まっておらず、認識したい情報がどこにあるかわからないような書類を対象とします。レシートや請求書などが該当します。一般的に全文OCRを行った後に、情報の抽出処理(Key Information Extraction: KIE)を実行し、必要な情報を抽出します。
情景文字認識(Scene Text Recognition)
看板などの情景内に含まれる文字を認識するタスクです。Document OCRと比較して、文字のフォントや記述方向(縦書き、横書き、湾曲、etc)の多様性、歪み、ブレ、ノイズなどの撮影条件が厳しく、難易度が高い傾向にあります。

OCRを実現する方法
OCRは文字検出モデルで画像内の文字位置を推定し、個別の文字位置を推定した後に、文字認識モデルで文字カテゴリを予測するような2-stageの予測フェーズで構成されます。
文字検出(Text Detection)
単純に考えると、個別の文字を切り出して、文字画像をクラス分類をとけば良いとのでは?と考えると思いますが、文字単位の処理ではなく、文字列単位で処理する方法が一般的に精度は良いです。1文字ごとの文字の位置の予測は、非常に精細な精度が要求されるため、文字列単位で検出するよりもタスクの難易度が高くなります。
検出対象の文字列は回転していたり、湾曲していたりします。斜めの文書に対して、一般的な物体検知モデルと同様に[x,y,w,h]のバウンディングボックスで予測すると、バウンディング内に上下の行の関係のない文字が映り込んでしまい、認識モデルの認識性能が低下します。そのため、物体検知モデルではなく、セグメンテーションモデルなどでポリゴン形式で予測可能なモデルが多く採用されます。アーキテクチャとしては、ResNetやEfficientNetといった一般的なCNNモデルをバックボーンとして持つ、UNET構造のシンプルなアーキテクチャのセグメンテーションモデルが用いられたりします。例として、CRAFTやDBNetなどがあります。
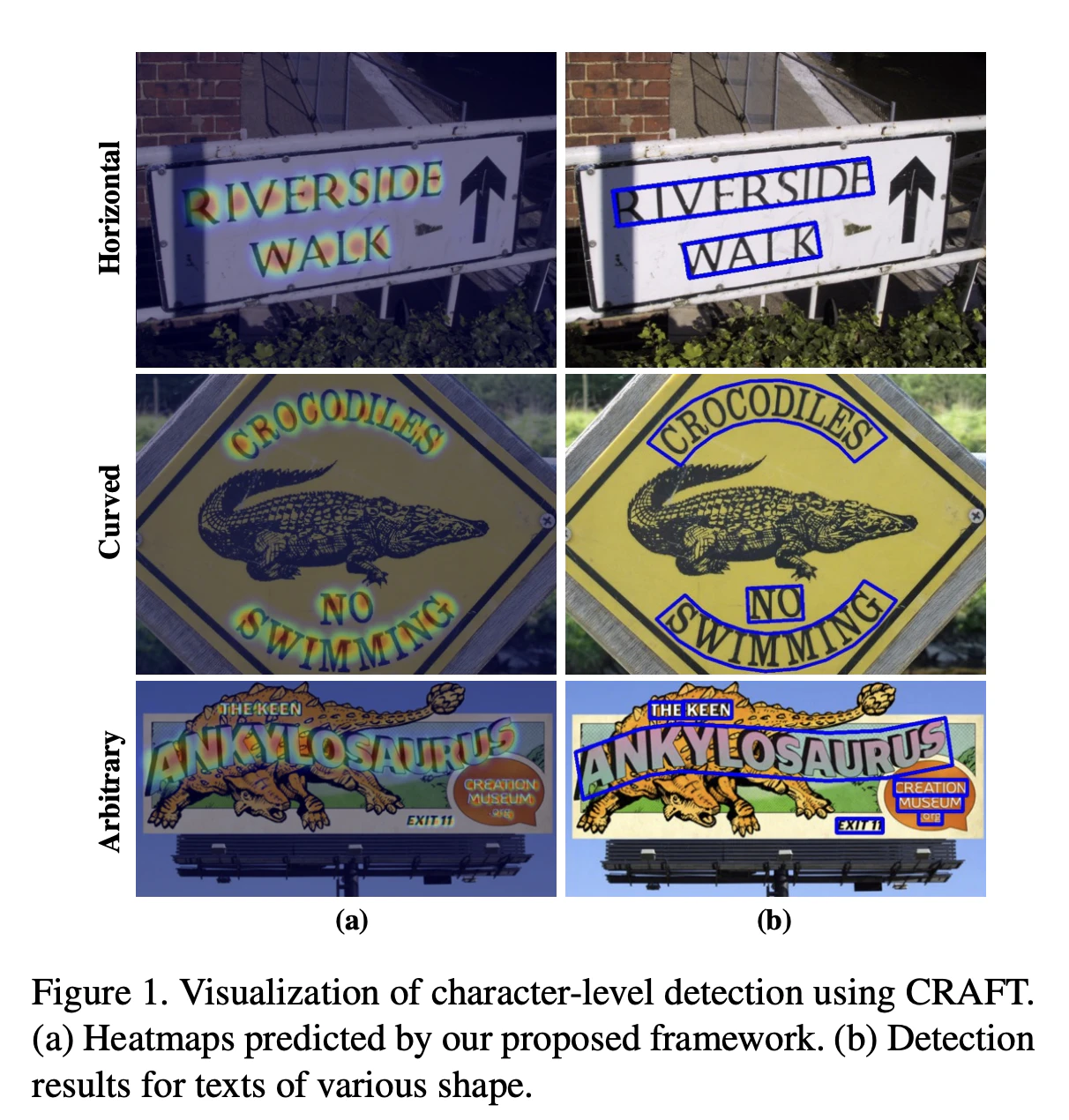
引用元: https://arxiv.org/pdf/1904.01941
多くのセグメンテーションモデルの弱点として、後処理が煩雑になり、処理速度が低下するといった課題があります。対策として、文字列領域の曲線をベジエ曲線で近似し、ベジエ曲線のコントロールポイントを回帰タスクとして予測するABCNetなどがあります。

文字認識(Text Recognition)
文字検出モデルによって、文字列単位で画像データを切り出すことで、文字認識のフェーズで前後の文字言語的な情報を用いて、文字を予測することが可能なり、精度が高くなりやすい傾向にあります。文字列認識モデルとては、CNNで画像をembeddingし、Encoder-Decoderモデルで自己回帰的に前後の文字の文脈を考慮し、予測するモデルが用いられます。SRNやPARSeqなどがあります。
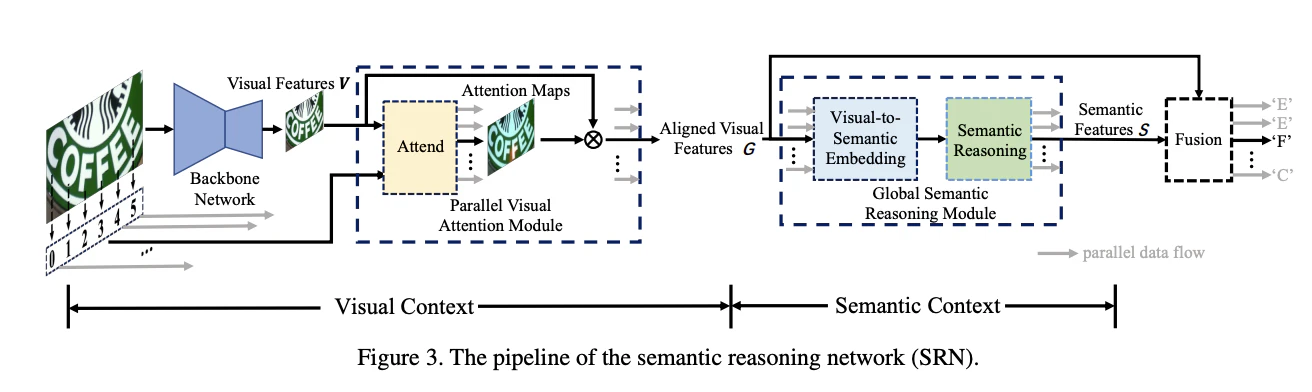
E2E OCR(Text Spotting)
2-stageで構成される文字検出と文字認識のタスクをE2Eで実現する(Text Spotting)場合もあります。昨今の研究としては、TESTRなどDETRをベースとしたアーキテクチャで実現する方法(Text Spotting)が主流ですが、2023年のICDAR2023で行われたコンペティションHierarchical Text Detection and Recognitionの結果を見ると、個別で学習したモデルの方がいまだに高い傾向にあるようです。
合成データの活用
OCRのモデルの学習には、合成データセットがよく用いられます。論文でも合成データと実データをミックスしたデータセットで学習されることが一般的です。OCRが対象とする文字は活字であれば、機械によって印刷された文字であるため、合成データでも実物に近いデータが得られるため、効果が大きいです。自動で生成からアノテーションまで一貫して、行えるため、効率的に大量のデータを生み出すことができます。OCRの合成データの生成のための、OSSとしてsynthtigerなどがあります。
文書レイアウト分析(Document Layout Analysis: DLA)
文書レイアウト分析とは、文書のレイアウト構造を解析し、文書の構成要素を抽出、分類します。文書のタイトル、見出し、段落、ヘッダー、フッター、数式、ページ番号といったテキスト行のグループの位置やカテゴリを識別したり、画像内に含まれる、表や写真、グラフなどの位置を判別するタスクです。タスクを解決手段として、セグメンテーションモデルやYOLOシリーズやDETR系の物体検知モデルが使われたりします。また、レイアウト画像データセットにも合成データが用いられることも多く、最近の発表されていたDocLayout-YOLOなどで合成データの生成方法が紹介されています。

情報抽出(Key Infomation Extraction: KIE)
文書画像から、氏名や住所、生年月日、請求金額など特定の情報に紐づく文字列を抽出する方法です。KIEは位置情報や辞書、正規表現、文字の位置情報などを用いてヒューリスティックに設計されたアルゴリズム解決できる場合も多くあります。しかし、氏名などの固有名詞、非定型書類など事前に記載の位置がわからないケースにAIを用います。AIベース方法としては、事前にOCRで取得した文字列とその位置情報、画像全体の情報をTransfomerベースのモデルへの入力として与え、予測する方法であるLayoutLMシリーズやOCRを使わずに画像のみを入力として与え、E2Eで抽出したい情報を予測する方法として、Donutなどもあります。

表画像解析(Table Understainding)
文書画像内に含まれる表の検知や表の構造の認識するタスクになります。まずは、文書画像内のDLAモデルで表の位置を特定した後に、各表画像に対して、表構造認識(Table Structure Recognition: TSR)を適用します。表構造認識とは、表に含まれる行や列、セルの位置を特定したり、セル結合、ヘッダーといったセルの種類を認識する処理です。TSRを実現するためのアプローチとしては、Top-Downアプローチ:表の行や列、セル結合の位置を画像モデルで検知し、後処理でセルの位置やテーブルの構造を簡単なアルゴリズムで再構築するTable Transfomerや表画像をモデルに与え、表構造を表すHTMLシーケンスへの変換をOCRフリーで実現する方法などもあります。
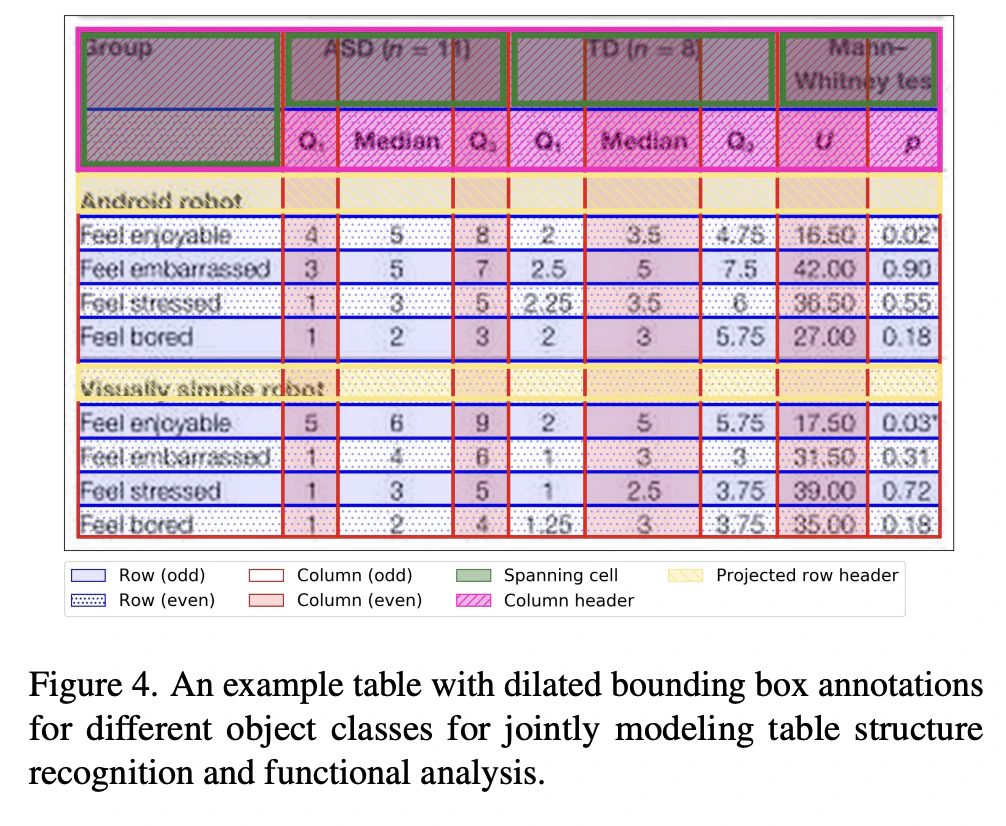
その他のタスク
- 書類画像の歪み、回転補正: OCRやレイアウト解析の前に歪みや回転の補正をかけることで後段の処理を実現しやすい画像に補正します
- 書類分類: 書類のカテゴリを分類します。例えば、その書類がレシートであるのか、領収書であるのか、請求書であるのかのように書類の種別を識別します。画像だけで行う方法や画像と文字情報を組み合わせてLayoutLMなどでマルチモーダル情報を用いて、解く方法もあります。
- 読み順推定: レイアウトと文字の情報を使ってその書類に含まれる文章をどのような順序で読むかを推定するタスクです
- etc..
最近の研究の動向としては、これまで個別で議論されてきたOCRやテーブル画像解析、レイアウト解析などのタスクを単一モデルに統合して、解決しようといった内容が増えてきている印象です。例えば、OMNIPARSERなど
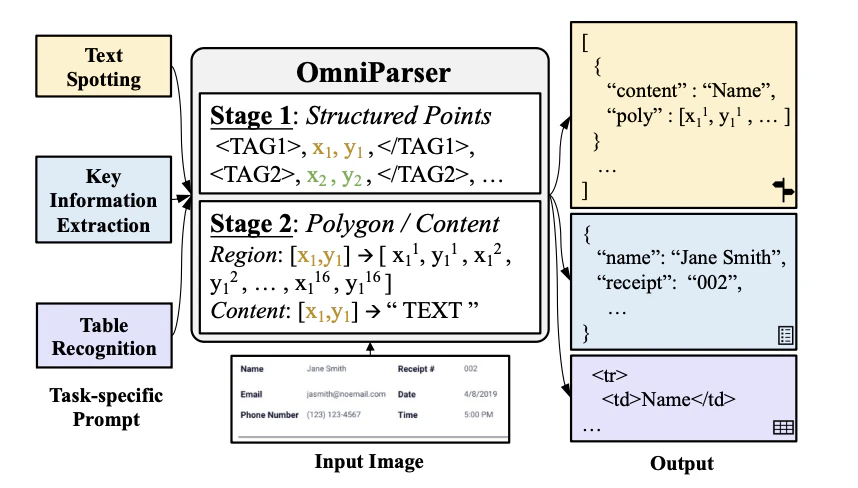
文書画像解析のためのサービス
クラウドサービス
この辺は、言わずもがな有名な文書画像解析のクラウドサービスです。これらを内部で使っているベンダーは多い印象です。
ローカルサービス
OCR OSSは以下のようなものがあります。Paddle OCRやEasy OCRは海外製のOSSですので、日本語向けに最適化されているものではなく、日本語文書に対してはそこそこの性能といった印象です。Tesseractは古くからあるOSSのOCRですが、あまり精度がよい印象はないです。国産のOSSとして国立国会図書(NDL)の事業の一環で開発されたOCRが公開されています。こちらは古典的な文書データで学習されたものなので、現代文書に対しての適用は難しいと思われます。もちろん、ユースケースや要求精度にもよりますが、日本語文書に対して、高い精度を実現できるものはないという印象です(個人の感想です)
最近、文書画像解析を行うサービスが次々と登場しています。OCRだけでなく表やレイアウト解析機能を有しており、読み取った文書をMarkdonwなどに変換して、エクスポートすることが可能です。
※日本語に対応していないものあります。
- docling
- zerox
- Surya OCR ※OSSではなく、商用は条件付きで有償
- Llama OCR
- mPLUG-DocOwl
最後に
文書画像解析技術に関して簡単に紹介しました。OCRはすでに終わった技術だと思われることがありますが、意外とタスクの幅は広く、さまざまな課題があり、いまだに活発に議論がされている技術分野です。本記事をきっかけに少しでも興味を持っていただけると幸いです。