三浦さんとの出会い
最初にお会いしたのは下記でLT登壇を一緒にした時だと思います。その後の懇親会で話したのが最初の記憶です。
https://jawsug-sapporo.doorkeeper.jp/events/94378
JAWS FESTA 2019でもスタッフ側だったので話すことがあったはずなのですが、ハンズオン講師で緊張していてほとんど覚えてないですが、この時ぐらいにアーキテクチャ見てAppSyncの方が良さそうだなーと思って、JAWS-UG札幌恒例の居酒屋で飲みながら話した記憶があります。
その辺はJAWSDAYSの2022で触れてくれているので見てみてください。(10分ぐらいから・・・)
AppSyncとは
AppSyncが発表されたのは2017年のre:Inventです。最初はプレビューでしたが2018年4月13日にGAされました。
AppSyncとはGraphQLをマネージドで提供してくれているマネージドサービスです。基本的な使い方は三浦さんがまとめてくれているので下記を見てみてください。
簡単にいうとAPI Gatewayを拡張したようなもので下記の特徴があります。
・リクエストするエンドポイントは一つだけ
・Query(GET),Mutation(POST、PUT、DELETE)、Subscriptionという概念でアクセス
・データソースという考えが、DynamoDB、OpenSearch、RDS(一部)、HTTPエンドポイント、EventBridgeに対応
・データソースを指定すると、中身を解読して、CRUDの操作に必要なものを自動生成(簡単なCRUDしか作成してくれなく、業務で使う場合は追加修正が必要)
AppSyncのポイント
私的なAPI Gatewayと比較した場合のおすすめポイントは下記です。
・データソースという概念で、バックエンドの開発工数の削減、Lambdaレスでデータにアクセス
→人数少なく、規模がそこまで大きくなければメリット出ると思います。
・認証機能
→Cognitoを認証基盤にした場合、アノテーションで簡単に権限管理ができます。
@aws_auth(cognito_groups: [<Cognitoのグループ>]
・クラス定義
→amplify codegenというコマンドを使って、クライアント側のアクセスに必要な定義情報を作成してくれます。
・クライアントでリアルタイムに検出できるSubscriptionが使える。
→毎回全件のデータを取得してではなく、更新されたものだけをリアルタイムにプッシュで配信するがイメージ近いと思います。
・オフライン機能があり、データの整合性など考慮してマージしてくれる。
→これは取り扱うのに癖があり今回で語り尽くせないので、どこか別の機会で深堀します。
使いにくい点は学習コストだと思います。あとはデバッグにしくいということも多少あるかなー慣れの問題ですが・・・
AppSyncの改善ポイント
今年アップデートされた内容を振り返ってみたいと思います。
Javascriptで記述することは過去のアップデートで対応されましたが、今年のアップデートで全てのリゾルバで使えるように。(すでにVTLで書いたものを変更するは大変なんで変換ツールとか提供してくれないかなー)
データソースにEventBridgeが対応したので、簡単にAWSのサービス連携できるようにもなりました。
CloudWatchのメトリクスが追加になってます。Subscriptionsが成功失敗した場合のメトリクスの確認が可能です。
AppSyncのAPIをPrivateで構築できるようになりました。まだ使い道を思いついてません。
複数のAppsyncを一つのAppSyncに統合できるようにもなりました。マイクロサービスアーキテクチャなどでAppSyncを分離している場合この機能は嬉しいと思います。私は嬉しい方のタイプです。
個人的には下記が嬉しいのですが、AppSync使う場合は、システム要件に応じて、DynamoDB、OpenSearch、RDSを使い分けるパターンが多く、最近はRDSを選ぶパターンが多いです。(RDSを選ぶのは基幹システムのようなシステムが多いからです。)
その辺簡単に構築できるようになりました。またAurora ServerlessがDataAPIにも対応したので使いやすくなったのも嬉しいポイントです。
DataAPIが使えるようになり簡単に開発できるようになったので試してみましょう
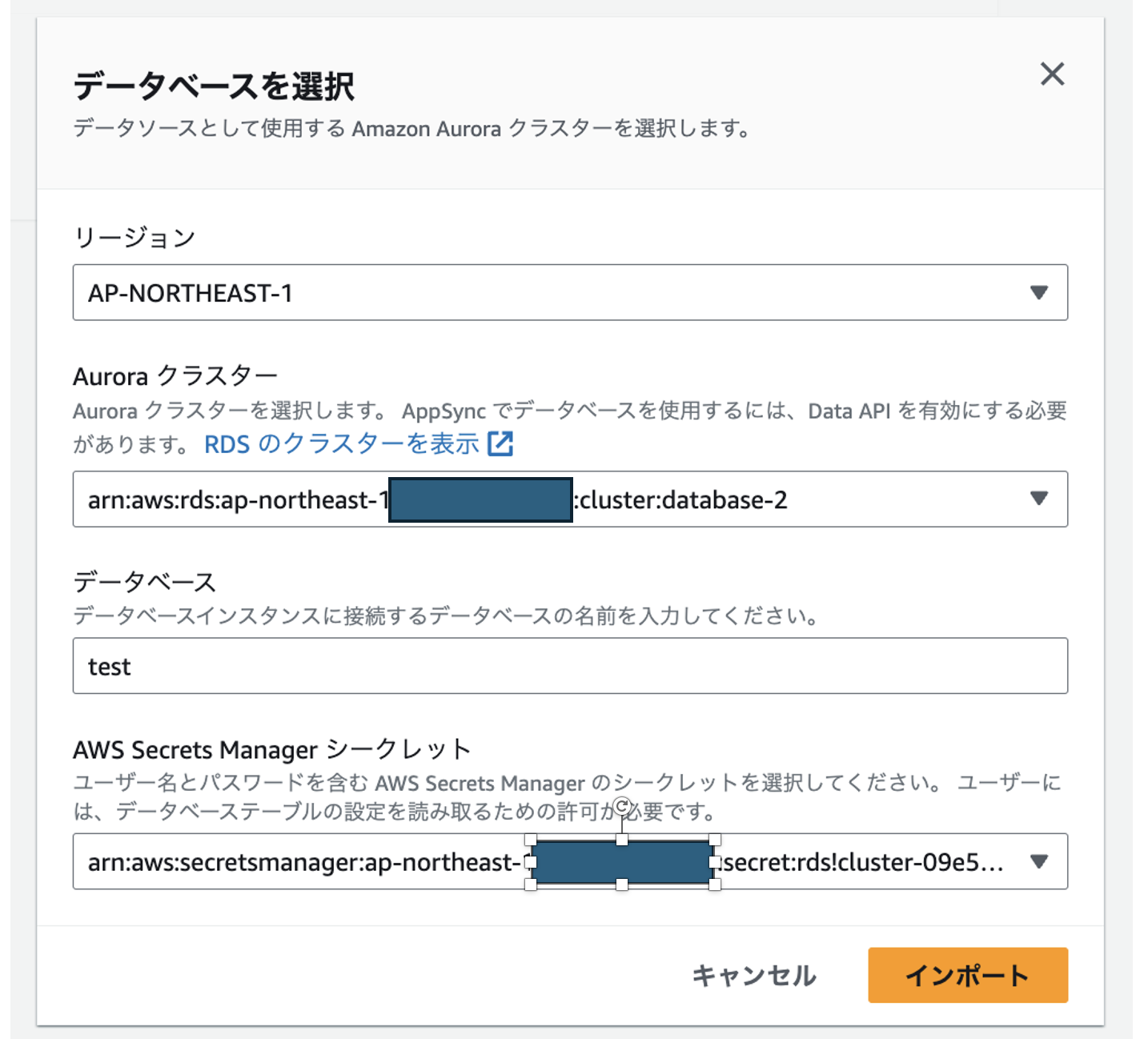
1.Aurora PostgreSQLを起動します
手順は割愛しますが、デフォルト設定から変更が必要なポイントを下記に列挙します。
・PostgreSQLを選択する。
・Severles v2を選択する。
・認証情報はSecretManagerに格納する。
・DataAPIを有効にする。
・データベース名を設定する。(今回はtestにしました。)
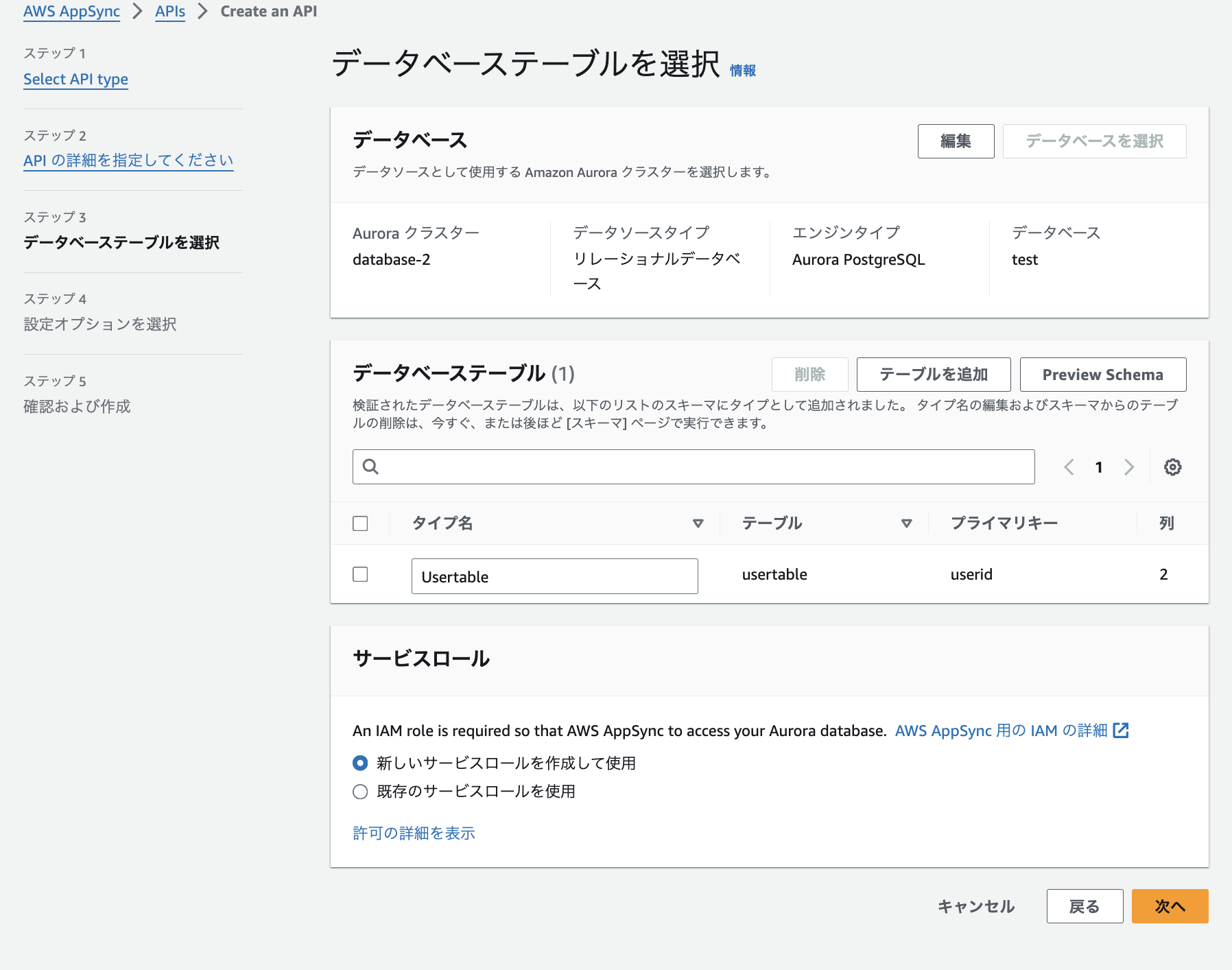
2.作成したデータベースにテーブルを作成してください。今回はお試し用に下記テーブルを作成しました。
CREATE TABLE usertable (
userid VARCHAR(255) PRIMARY KEY,
name VARCHAR(255) NOT NULL
);
3.下記手順でAppSyncをAurora PostgreSQLに接続します。
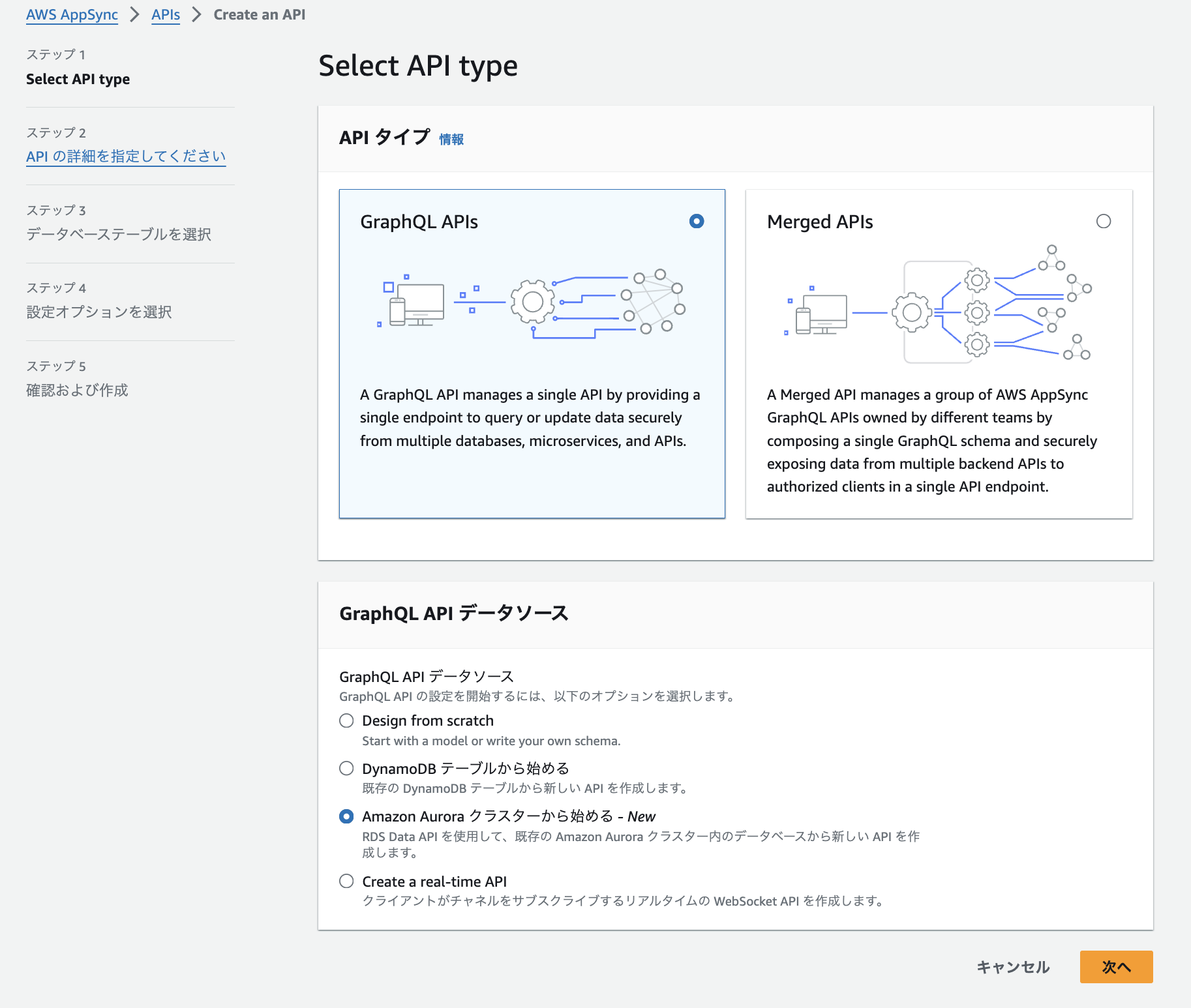
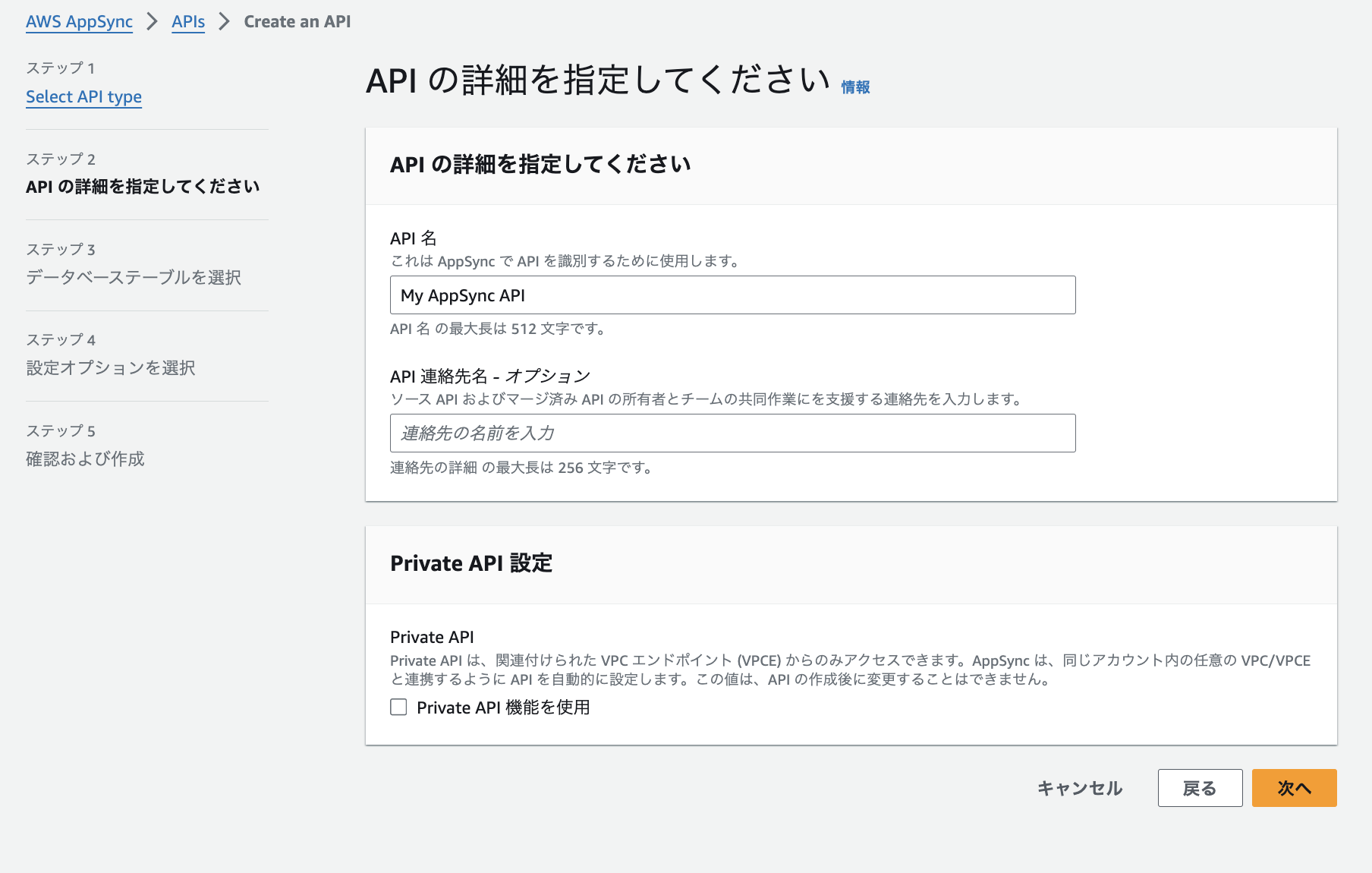
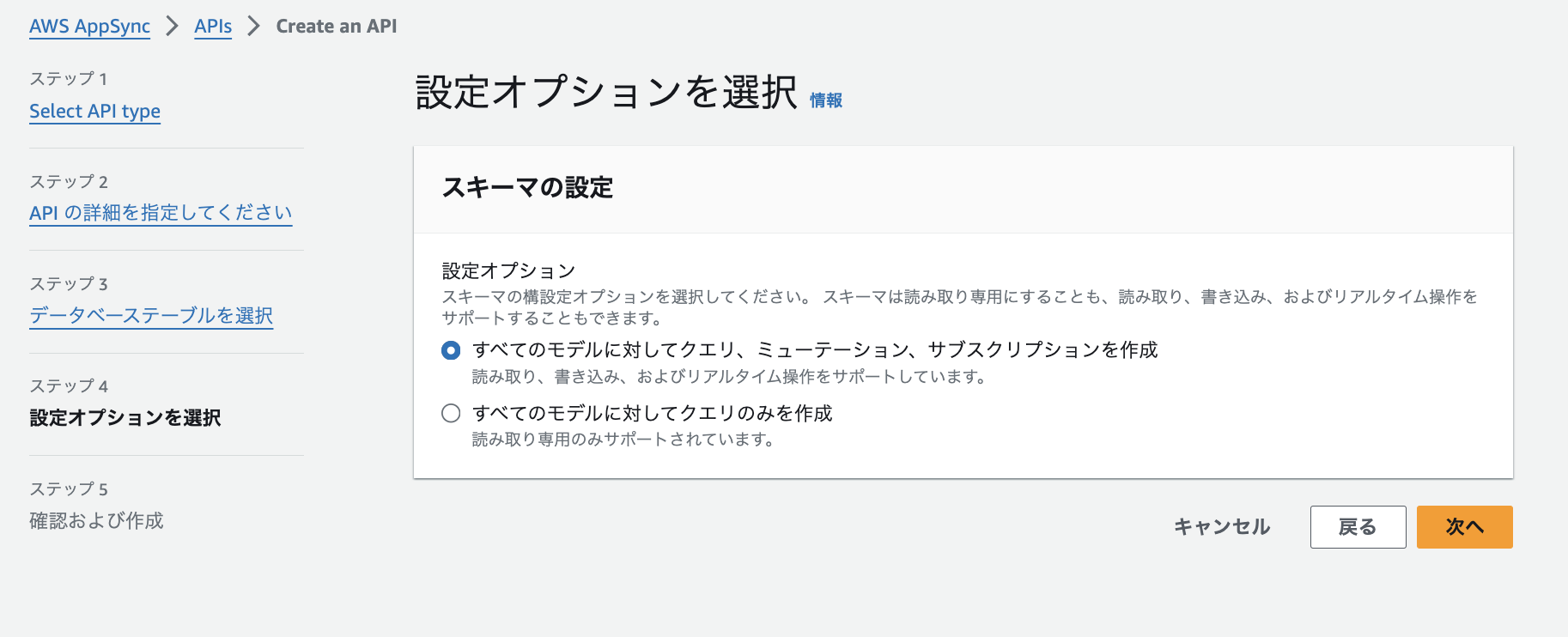
設定はこれだけで完了です。
3.どのようなものが作成されたかを確認しながら動作確認します。
クエリを開くとテーブルの構造を読み取りデフォルトで、登録処理と参照処理が作成されていました。
実際の業務で使う場合はこれだけでは足りないので追加が必要ですが、マスタ画面などであれば、
登録と参照はバックエンド側の処理は不要です。
実際に動作確認してみます。
「実行する」から、createUsertableを選択して、クエリ変数を適切な値に変更してください。
デフォルトの値では、useridにスペースが入っていてエラーになります。
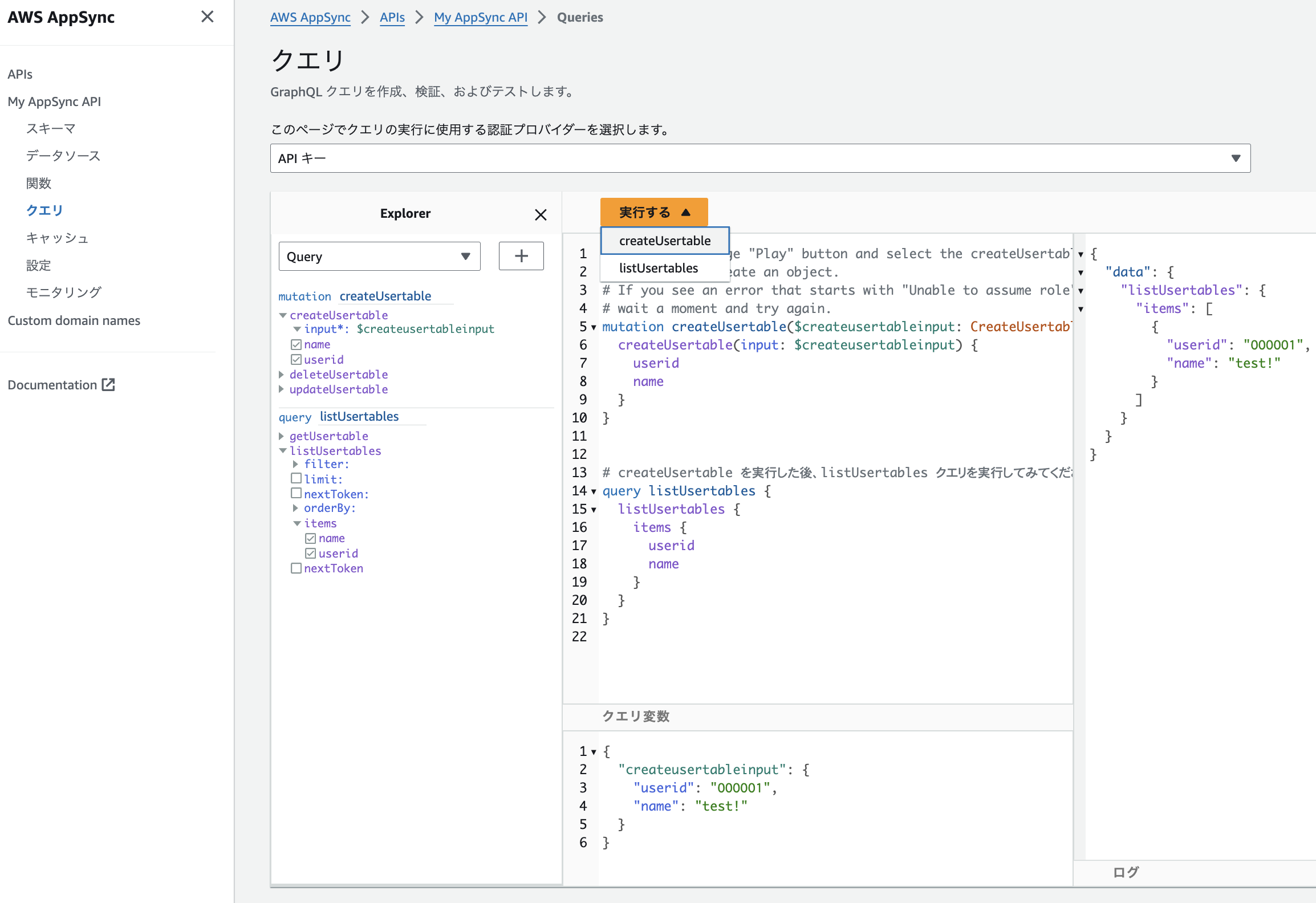
実行するとこれだけで登録されていますので、次は参照で登録されたデータを確認してましょう。
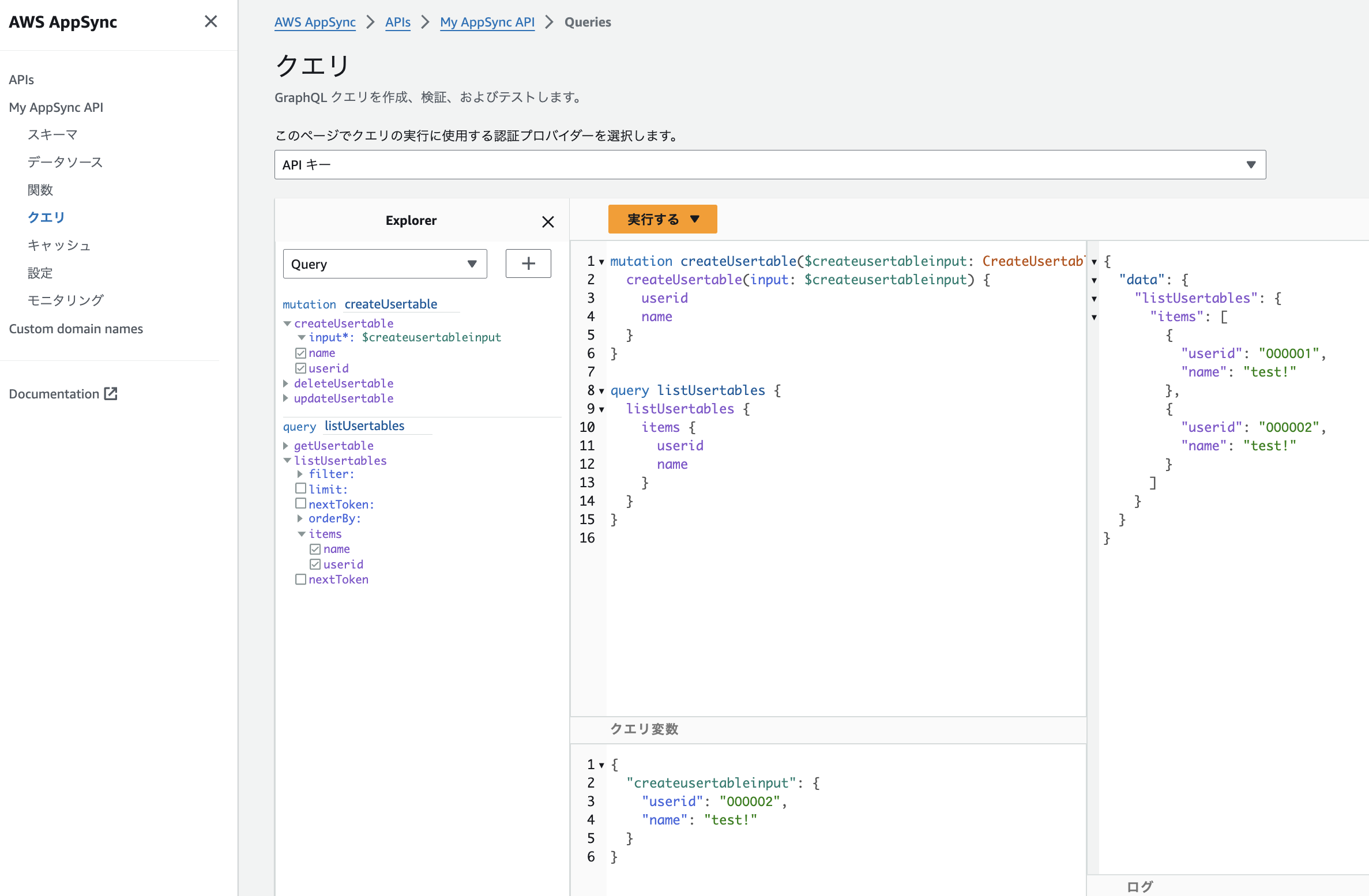
「実行する」から、listUsertableを選択すると、登録したデータを取得されたことが確認できます。
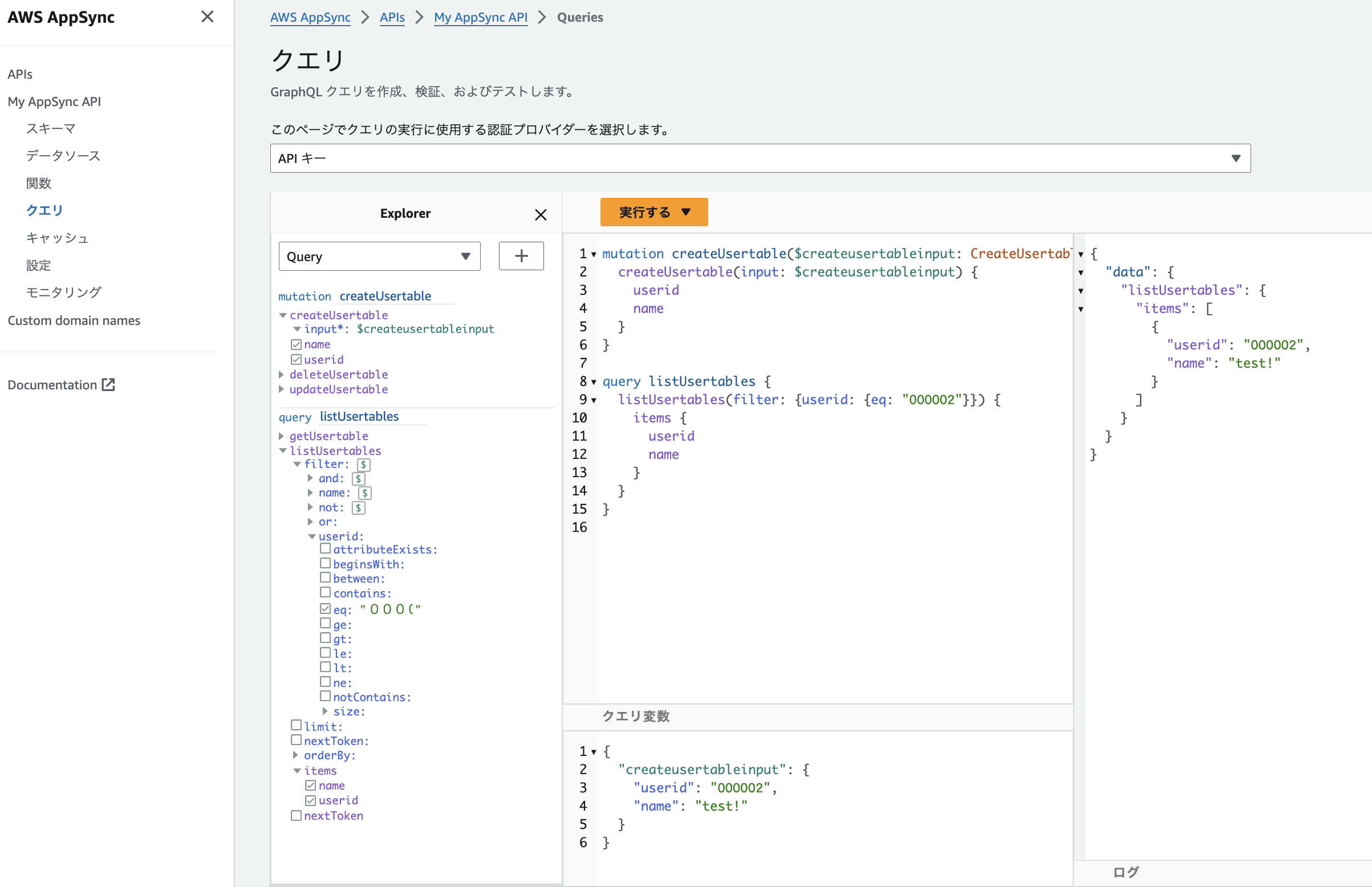
デフォルトで作成された定義でも絞り込み条件が設定できるので試してみます。
左にあるフィルタで000002の情報だけ取得するようにしてみましょう。
簡単にフィルタリングできることが確認できたと思います。
いかがでしょうか?データベースに繋ぐだけで、ある程度必要な処理が作成されて神機能だと
思っています。
今後はテーブル件数が多い場合など、さまざまなパターンで検証してみようと思います。
最後に
この辺でなんか使ってみたくなってきたかもーと思いますが、一番の懸念はリクエストに関する点です。
下記で三浦さんが触れてくれているのでご一読を。
これは利用者に対しての通知しか来てなく、記事にはなってないのですが、re:Invent中に改善通知来てたので紹介です。
2024 年 1 月 10 日に AWS AppSync はリクエストトークンのデフォルトクォータを 1 秒あたり 2,000 から 10,000 へ引き上げる予定です。また、AWS AppSync では AppSync におけるサブスクリプション機能の最大使用量を制御するため、調整可能なサービスクォータもリリースする予定です。それらの新しいクォータでは、API ごとのインバウンドメッセージレート (デフォルト値:10,000)、API ごとのアウトバウンドメッセージレート (デフォルト値:1,000,000)、API ごとの 1 秒あたりの接続レート (デフォルト値:2,000)、および API ごとの同時接続数 (デフォルト値:10,000) の最大値を設定します。お客様は Service Quotas コンソール[1] で、これらのクォータの上限緩和をリクエストすることが可能です。
これでAppSyncで懸念されることは1つ解消されましたね!リリースされたら、どんな動きに変わったのか試してみて、まとめたいと思います。来年の宿題・・・
この内容が皆さんの参考になれば幸いです。