はじめに
クラスタリングアルゴリズムの中でもk-meansと並んで有名なのがDBSCANです.
今回は理解を深めるためにできるだけシンプルな構成で,実装してみます.
単純に使いたいだけなら,scilit-learnの実装などを利用する方が簡単です.
目次
DBSCANアルゴリズム
DBSCANは密度ベースのクラスタリングアルゴリズムです.
多くの密度ベースアルゴリズムの基本となっており,比較的シンプルなアルゴリズムになっています.
DBSCANではパラメータ$\epsilon$と,$MinPts$を与えることによって動作します.k-meansと違ってクラスタ数を事前に指定する必要はありません.
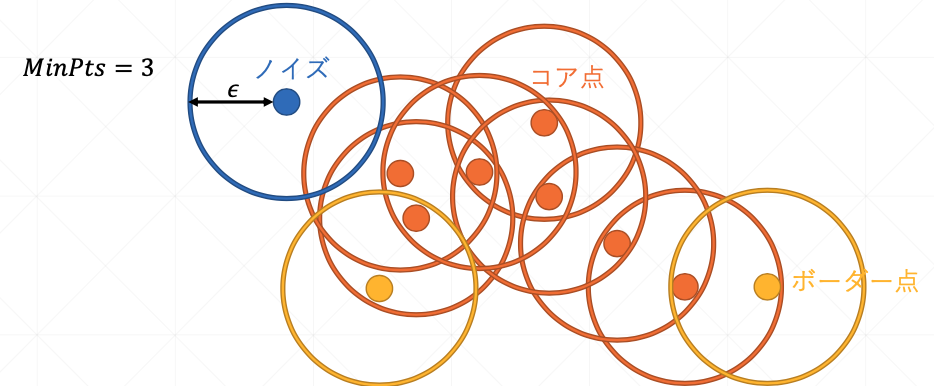
core point
データ点$p$に対して,距離半径$\epsilon$以内にある点を$\epsilon$-近傍点と呼び,
$$N_{\epsilon}(p)= \lbrace q \mid q \in P,d_{p,q} \leq \epsilon \rbrace$$
と表記します.$d_{p,q}$は$p$と$q$の間の距離です.距離はユークリッド距離やチェビシェフ距離などが用いられます.このような$\epsilon$-近傍点に対して
$$\lvert N_{\epsilon}(p) \rvert \geq MinPts$$
を満たすような点をcore pointと定義します.
直感的にはcore pointはクラスターの中核となるような点です.
クラスタの定義
core pointである点$q$に対して,$p \in N_{\epsilon(q)}$は点$q$から点$p$へと直接到達可能な点と定義します.また,$p_1,...,p_n$に対して$p_i$から$p_{i+1}$がそれぞれ連鎖的に直接到達可能な時,$p_1$は$p_n$から到達可能な点であると言います.
到達可能は非対称な関係なので,対象な関係に拡張したものを密度連結であると言います
$q$がcore pointである時に$q$から直接到達可能な点$p$はborder pointといいます.
一方で,core pointの定義を満たさず,かつ全てのcore pointから到達可能で無いような点のことをnoiseと呼びます.
直感的にborder pointはクラスタの境界付近に存在する点で,noiseは外れ値となるような点のことです.
これらを踏まえて以下の二つのような条件を満たす空で無い集合のことをクラスタと定義します.
- 全ての$p,q$に対して,$p \in C$から$q$に到達可能な時,$q \in C$を満たす.(Maximarity)
- 全ての$p,q \in C$に対して,$p$は$q$と密度連結である.(Connectivity)
実装
では実際に実装してみます.
アルゴリズム
def fit(self, X):
self.points = [Point(x) for x in X]
for p in self.points:
if not p.visited:
p.visit()
neighborPts = self.rangeQuery(p)
if len(neighborPts) < self.min_samples:
p.pointType = "NOISE"
else:
p.pointType = "CORE"
self.expandCluster(p, neighborPts)
self.label += 1
ここでは受け取ったデータ配列を順にスキャンしていきます.まだスキャンしていないに対して,core pointの定義を満たさなければnoise,満たしていればcore pointとしていきます.
core pointとなるような点に対してはexpandClusterでクラスタを拡大していきます.
def expandCluster(self, p, neighborPts):
p.label = self.label
for q in neighborPts:
if not q.visited:
q.visit()
neighborPts_q = self.rangeQuery(q)
if len(neighborPts_q) >= self.min_samples:
q.pointType = "CORE"
neighborPts.extend(neighborPts_q)
if q.label == -1:
q.label = self.label
expandClusterでは受け取ったcore pointに対してrangeQueryを用いて$\epsilon$-近傍点を探索し,到達可能な点を同じクラスタに割り当てていきます.noiseで場合にはクラスタ番号は-1になっています.
このようにexpandClusterを用いてcore pointから到達可能な点を全て探索していくことによって同じクラスタに属している点の集合を拡大していきます.呼び出し元のfitに戻った時には与えたcore pointの属するクラスタの点は全て探索しきっているので,次のクラスタに移ります.
実験
上で実装したアルゴリズムの中を使って簡単な実験を行います.
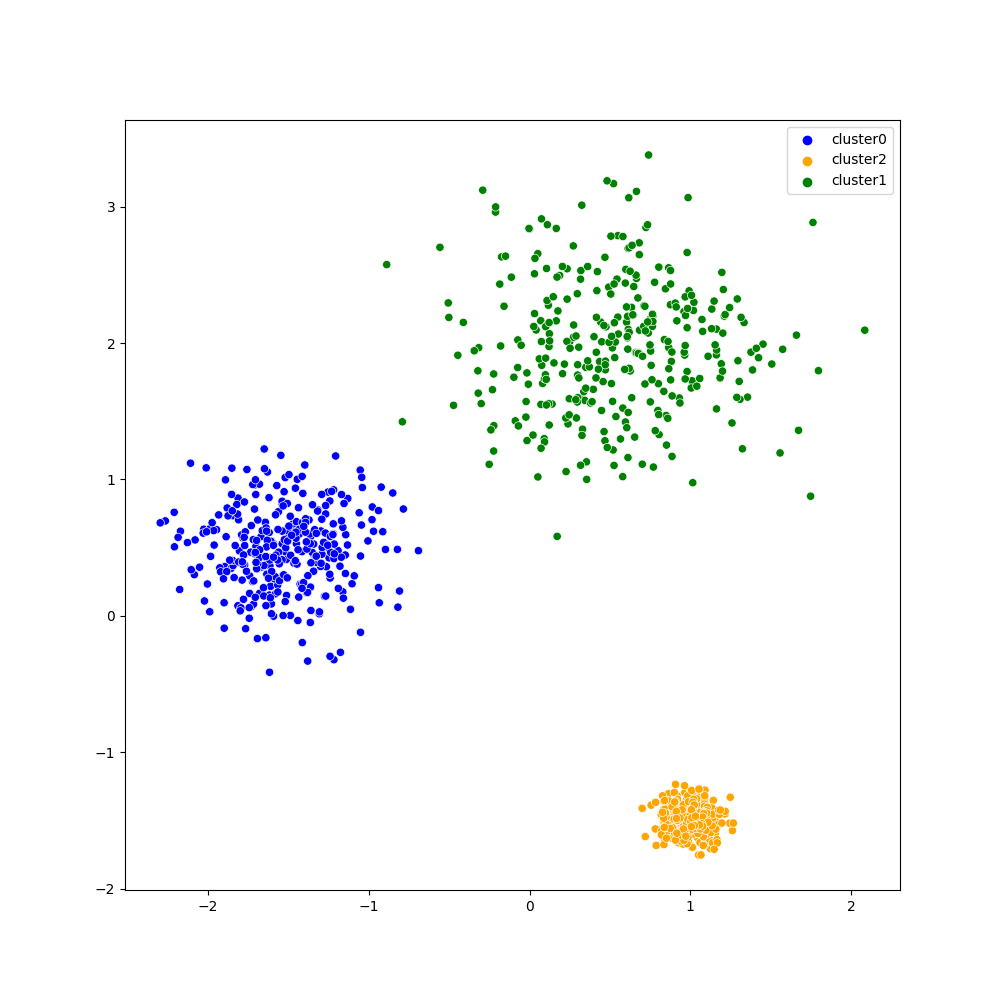
実験では上図のような2次元,3クラスタの簡単な合成データセットを用います.
$\epsilon=0.2,MinPts=10$とした時のDBSCANの結果が下図のようになっています.
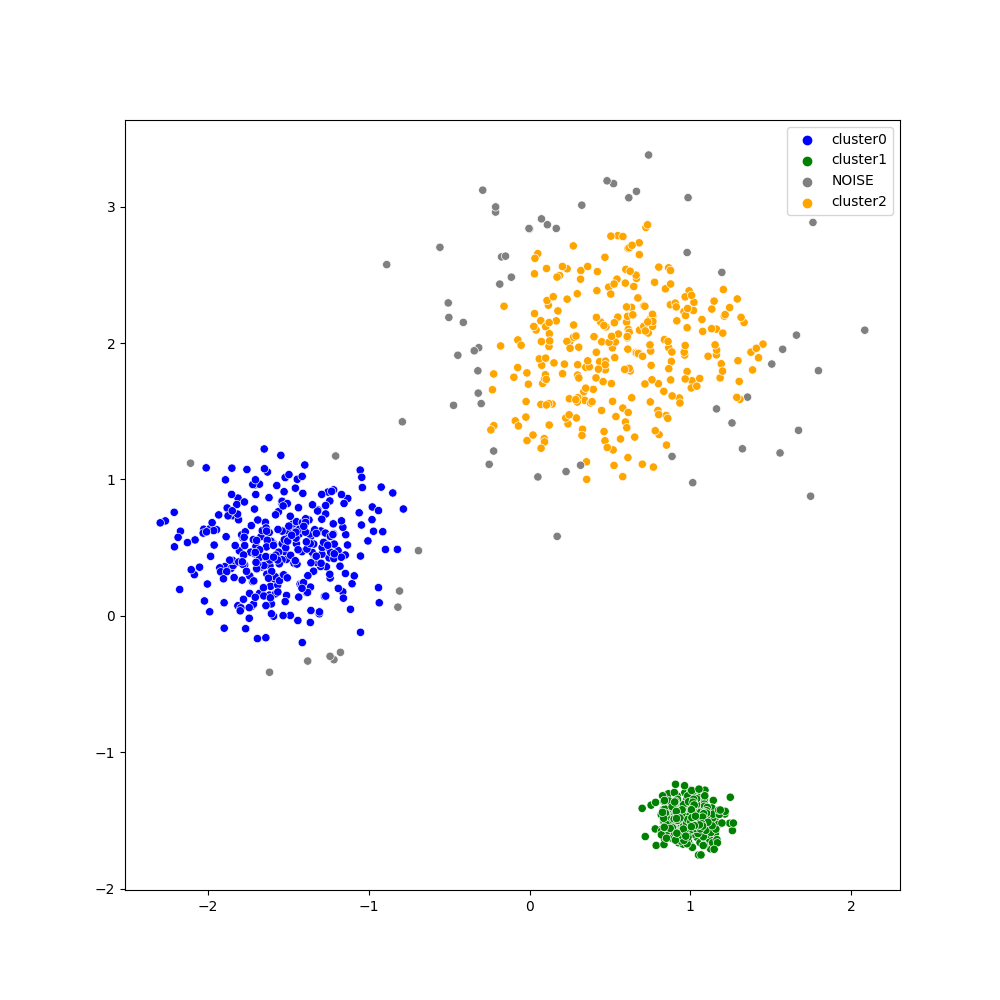
各クラスタがうまく抽出できていることがわかります.
また,分散の大きいクラスタでは外側の外れ値がnoiseとして灰色の点になっています.DBSCANはこのように外れ値に対してロバストなクラスタリングアルゴリズムでもあります.
まとめ
DBSCANアルゴリズムは,
- クラスタ数を指定しなくて良い
- 任意の形状のクラスタを抽出できる
- 外れ値に対してロバスト
などの利点がある優秀なアルゴリズムでありながら,割と簡単に実装できました.
発展手法では木構造を用いたrangeQueryの高速化や,全ての点を探索せずにクラスタリングする手法などいろいろ提案されているので注目です.
ソースコード
ソースコード全体はgithub上にあります.
https://github.com/kotaYkw/DBSCAN