概要と投稿の背景
本投稿では、Firestore の DB 設計の基礎についてまとめます。
私は普段、都内の企業で Flutter エンジニアとして勤務しています。最近は Python/Django のバックエンド API や、Nuxt.js/Vue.js による Web フロントエンドのタスクにも取り組むことがあるのですが、業務レベルで Firestore を使いこなすような機会はありません。
ですが、趣味や個人で使用する範囲のアプリケーションを開発する際には、DB としての Firestore の便利さ・手軽さ・それでいて高機能な面に魅力を感じており、最近では NoSQL データベースや Firestore の特徴をうまく捉え、メリットを活かしながら、いろいろな規模のサービスを Firestore を用いて実現している例もかなりあるようです。
これから行おうとしている個人開発でも、Firebase を使いたいと思っているのですが、これを機に Firestore の DB のより良いデータモデリングについて基本を学んでみようと思い、Firebase の公式チャンネルから公開されている "How to Structure Your Data" という動画を一通り観ることにしました。
Firebase には、公式が提供するこのような解説動画やドキュメントが豊富にあり、非常に学びやすい環境が整っている一方で、英語に苦手意識があると、そういった貴重な情報も理解するのを億劫に感じてしまう方もいるかもしれません。
今回は、自身の頭の整理も兼ねて、上記の動画のほとんど全てのセリフに字幕を付けるような感覚で、できるだけ日本語で自然に読めるよう翻訳しました。
日本語として自然に読めるようにした以外には、内容そのものはなるべく忠実に翻訳するようにしましたので、私の独りよがりの理解ではなく、Firebase 公式がまとめる通りのコンテンツを学べるようにしたつもりです。
これから Firestore を勉強してみる方や、次作るアプリでは Firestore でのより良い DB 設計にしていきたいなと思っている方の参考になれば幸いです。
動画の中では説明のために色々なイラスやアニメーションも出てくるので、この文章を字幕的に読みながら、動画を観てみるのも良いかもしれません。
それでは、以下、翻訳です。
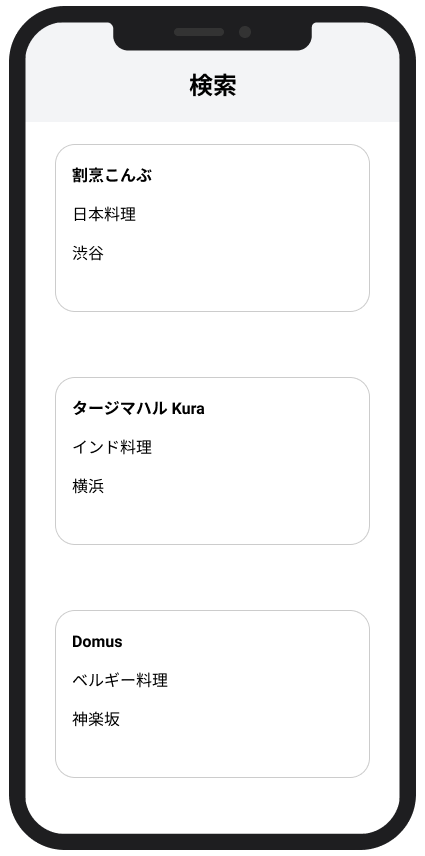
レストランのレビューアプリ
一つ前の動画からも、Cloud Firestore の仕組みを支配する色々なルールがあることをご理解いただけたと思いますが、「どのように Firestore のデータを設計するべきか」ということについて、今回の動画では、理論的に説明していくような話し方ではなく、できるだけ実世界に近い例を取り上げながら説明して行こうと思います。
この動画では Firestore を用いた「レストランのレビューアプリ」を想定して話を進めます。
たとえば、検索ページでは、「ボストンにある日本食レストラン Top 20 を探す」みたいなユースケースがあるでしょう。
そしてその検索結果一覧ページからは、ユーザーはそれぞれのレストランの詳細ページに進んで、そのレストランに関する詳細情報を見ることができる上、一緒に「最近投稿されたレビュー」という項目も掲載されています。
ユーザーがレビューの中身をもっと見たいと思えば、それぞれのレビューをタップして、レビューの詳細画面へと進みます。
... よくあるユースケースのアプリケーションと言えますね。
| 検索 | レストラン詳細 | レビュー詳細 |
|---|---|---|
 |
 |
 |
では、早速「どのような DB 設計でデータを保存していくべきか」を、これから色々な質問に答える形式で考えていくことにしましょう。
レビューデータを保存する場所
まず最初は「レビューのデータはどこに保存するか?」という質問です。
これまでの動画でも同様のレストランのレビューアプリを題材として話をしてきましたが、そこでは「restaurants というコレクションにレストランデータが保存されているとき、特定のレストランに対するレビュードキュメントは、それぞれのレストランのサブコレクションである reviews コレクションに保存していく」という方針を取っていました。
restaurants(コレクション): {
レストラン名:foo
住所:bar
ジャンル:baz
reviews(サブコレクション): {
レビュードキュメント 1: {
名前:松本
レビュー点数:5
レビュー本文:...
},
レビュードキュメント 2: {
名前:浜田
レビュー点数:4
レビュー本文:...
},
...
}
...
}
たしかにレストランデータのそれぞれに、複数のレビュードキュメントをぶら下げるような方針は自然な発想であるとは思いますが、本当にこれが正しい設計であると言えるのでしょうか?
他の案がないか考えてみましょう。
レビューをレストランドキュメントの Array や Map フィールドに保存する
代替案その 1 は「レビューを別々のドキュメントに分けるのをやめてみる」という発想です。どういうことかというと、レビューデータを個別のドキュメントにせずに、それぞれのレストランドキュメントに reviews というフィールドを Array や Map で持つことにして、この reviews フィールドを Array や Map で定義してにレビューを保存していくという作戦です。
restaurants: {
レストランドキュメント 1: {
レストラン名:foo
住所:bar
ジャンル:baz
reviews(Array): [
{
名前:松本,
レビュー点数:5,
レビュー本文:...,
},
{
名前:浜田,
レビュー点数:4,
レビュー本文:...,
},
]
}
...
}
ユーザーが特定のレストランの詳細画面を閲覧するとき、当然その時点でそのレストランデータのドキュメントを取得しているので、そのレストランに対して投稿されたレビューデータ一覧も既に取得できています。嬉しい副作用として、ドキュメントの読み取り回数を減らすことができていることにも気付くでしょう。
しかし、もう少し考えてみると、そこまで良い案ではないような気もしてきます。
たとえば、ユーザーが「ボストンにある日本食レストラン Top 20 を探す」ユースケース、つまり「レビューの平均点の Top 20 を検索する」といったユースケースがある場合、Firestore の DB に保存されている全てのレストランの情報を取得し、そのひとつひとつのレビュー得点を取得しない限り、レビュー得点の TOP 20 を決定できないので、かなり無駄が多いことが分かります。
さらに、Firestore にはひとつのドキュメントに保存できるデータサイズに 1 MB の制限がある上、ひとつのドキュメントが保存できるフィールドにも最大 20,000 個という上限があるので、レビューがそれ以上に集まるようなレストランがあれば破綻してしまいます。
もしくは、「アプリケーションに投稿された(レストラン横断で)最新のレビュー 10 件を取得する」というようにレビューを検索・抽出することもできません。
つまり、レビューを何らかの条件で絞り込んだり、並び替えたりするには、Firestore の DB 内の全てのレストランデータをレビューデータと一緒に取得したものを、クライアントで処理する必要があるということです。
ということで、代替案 1 が抱える問題は見えてきたので、やはり「レビューデータは、レストランドキュメントのフィールドではなく、reviews という何らかのコレクションに保存していく」という方針が良さそうです。
レビューをサブコレクションではなく、トップレベルのコレクションとして定義する
では、reviews というコレクションは、restaurants コレクションの「サブコレクションとして」定義するのではなく、restaurants コレクションとは「全く別のトップレベルのコレクションとして」定義するのはどうでしょう?
restaurants(トップレベルコレクション): {
レストランドキュメント 1: {
レストラン名:foo
住所:bar
ジャンル:baz
}
...
},
reviews(トップレベルコレクション): {
レビュードキュメント 1: {
名前:松本
レビュー点数:5
レビュー本文:...
},
レビュードキュメント 2: {
名前:浜田
レビュー点数:4
レビュー本文:...
},
...
}
...ここからの話は面白いですよ。
「トップレベルコレクションに reviews を定義する」と聞いて、あなたが感じる第一印象は、
「え、ダメでしょ。『あるレストランに投稿されたレビューを取得する』という一番典型的なユースケースが大変になりそうだし」
という感じかもしれません。
しかし、心配はいりません。思い出してください。
Cloud Firestore のクエリは十分速いので、トップレベルに定義した reviews コレクションの中の 300 万件のレビューの中から "Todd's Tacos" という特定のレストランのレビューを取得してくる時間的コストと、あるレストランの下に作った単一の reviews サブコレクションのレビュードキュメントを全件取得してくる時間的コストとは、実質大して変わらないのです。
そして、もっと重要なのは、そのようにトップレベルに reviews コレクションを作っておけば、たとえば全く別のユースケースで「特定のユーザーが書いたレビュー一覧を取得する」みたいなことも簡単に実現できる訳です(collectionGroup クエリがリリースされる以前は、レストランごとの個別のサブコレクションにレビューを保存していく方法では、そのようなユースケースに対応するにはちょっと面倒な対応が必要でした)。
一方で、トップレベルの reviews コレクションにレビューがたくさん保存されて規模が大きくなってくると、ちょっと困ったことも起こってきます。
たとえば「ある特定のレストランに投稿された複数のレビューを、日付順やレビューのスコア順に並べる」といったユースケースには複合インデックスの生成が必要になることです。もしサブコレクションにそれぞれのレストランに対するレビューを保存していれば、そういう面倒は必要ありません。
他にも、セキュリティルールを記述することを考えると、(今回のレストランのレビューアプリに当てはまるかは分かりませんが)トップレベルのコレクションに保存されているデータよりも、ある親コレクションのサブコレクションにデータが保存されている方が、「親のデータに対する読み書きを許すかどうか」の条件を元に、子であるサブコレクションに対するアクセスを制御することができるので、記述すべきセキュリティルールの数が少なくて済む、セキュリティルールが書きやすいといったメリットでは、サブコレクションを用いる方針の方に分があります。
という感じで、reviews コレクションを「トップレベルコレクション」にするのか「サブコレクション」にするのかという判断については、「どちらもあり得る」というというのが結論です。
私自身、それぞれのパターンがアプリケーションやサービスによって使い分けられているのを見てきました。正直に言うと、以前までの動画でサブコレクションのパターンを題材として話してきた理由は「Firestore は "shallow" なクエリ、つまり大きなデータセットの全体をダウンロードすることなく操作できる(Firebase 公式ドキュメントの "shallow" の説明を参照)機能をサポートしているんだよ!」というのを強調したかっただけなんです。
ですので、今後の動画でもデモの目的としてサブコレクションのパターンを用いて説明を行うこともあるでしょうが、「トップレベルコレクション」にするか「サブコレクション」にするのか、というのは皆さんがそれぞれの状況に合うように自由に選んでください。
レビューデータの一部(スニペット)をレストランドキュメントに保存しておく
さて、それではここからは、もう少し高度な内容も見ていくことにしましょう。
今回取り上げているレストランのレビューアプリでは、レストランの詳細画面の中に、そのレストランの情報に加えて、直近 10 件のレビューが表示されています。このレビューは、レストランのサブコレクションか、あるいは、トップレベルのレビューコレクションに保存していくということですが、どちらにせよこのレストランの詳細画面を表示するのに、
- レストランドキュメントを 1 個
- レビュードキュメントを 10 個
合計 11 個のドキュメントの読み取りを行う必要があることが分かります。
ここで、典型的なユーザーのアプリの使い方を想像してみましょう。
おそらく「レストラン一覧から気になったレストランの詳細画面に進んでみて、レビューをざーっと読んで、またレストラン一覧に戻って、また次のレストランの詳細を見てみる」といった感じでしょう。何度も繰り返すと、この 11 回の読み取りが繰り返されて、読み取り回数が結構かさんできそうです。
もし、このようなドキュメントの余計な読み取り回数を削りたいと思ったら、やはり、レストランドキュメントのフィールドに直近 10 件分のレビューを保存しておいた方が良さそうな気がしてきました。
しかし、レストランドキュメントのフィールドに保存しておくのは、10 件のレビューの全情報でなくとも、「各レビューの文章の最初の 100 文字だけと、見出し、レビューを書いたユーザー名」くらいでも良いかもしれませんね。レストラン一覧に表示するのに十分な程度のレビューデータの一部(スニペット)だけを予めレストランドキュメントに保存しておくというのが、冒頭の例との違いです。
restaurants(トップレベルコレクション): {
レストランドキュメント 1: {
レストラン名:foo
住所:bar
ジャンル:baz,
レビューデータの一部(スニペット): [
{
レビューワー:松本
見出し:...,
レビューの最初の 100 文字:...
},
{
レビューワー:浜田
見出し:...,
レビューの最初の 100 文字:...
},
...
]
}
...
},
そうすると、あるレストランの詳細画面を開く度に合計 11 件のドキュメントを毎回読み取ってコストが増えてしまう事態は避けられます。上で述べた通り、大抵のユーザーは、レストラン詳細を開いて、レビューはざーっと流し見する程度と考えられるので尚更です。
もしユーザーが、あるレビューを詳しく見たい、全文を読みたいと思い、そのレビューをタップしたときには、今度はそのレビュードキュメントを一つ読み取れば良いだけです。
そもそも、このアプリのユースケースを考えれば、レビューを常に最新の状態で同期しておく必要性はおそらくそれほどないでしょう。あるレストランに新しいレビューが書かれたかどうか、最新のレビューはどうなっているかを、毎秒毎秒何度も確認するようなユーザーはほとんどいないと考えられるからです。また、そのようなレビューの更新・同期をしたければ、きっといつか別の動画で説明しますが、Cloud Functions を使うこともできます。
つまり、このようなユースケースやアプリのコアバリューも考慮しながら、どのような DB 設計をするか、Cloud Functions をどう使うかなどを、開発者である皆さん自身が考えて決めれば良いということです。
「そんなはっきりしない言い方参考にならないよ...」
なんていう反応も聞こえてきそうですが、それがソフトウェアを開発するということなのです。
真偽値の保存の仕方
それでは、次の話題に移りましょう。
今度は「レストランに紐づく真偽値はどのように保存しておくと良いか」という話です。
- レストランが予約可能か?
- 団体での利用は OK か?
- 子どもも楽しめるレストランか?
みたいなことを参照するユースケースです。
2 ヶ月前の動画では、「ドキュメントの真偽値フィールドにその値を直接保存する」か「Map フィールドに項目名と真偽値のキー・バリューペアとして保存するか」のどちらかが良いだろうと紹介していましたが、今回はさらに一つ加えて、単に「フィールド名: ["予約可能", "団体 OK", "子どもも楽しめる"]」のような Array フィールドを保存しておくのも良い例だということを紹介しておきます。
レストランドキュメント: {
レストラン名:foo
住所:bar
ジャンル:baz
...
...
// パターン 1(真偽値を直接保存)
予約可能: true
団体 OK: true
// パターン 2(Map フィールドに保存)
Map:{
予約可能: true,
団体 OK: true,
}
// パターン 3(Array フィールドに保存)
Array: ["予約可能", "団体 OK"]
}
ただし、いまはまだ Firestore では複数の array_contains の条件でクエリを発行できないことは覚えておいてください。「子どもも楽しめて、予約 OK のレストランを探す」といったユースケースがあるなら、この例は使えませんね。
ユーザーごとのアクセス権限を DB の設計に反映する
では、さらに次の例に進みましょう。次に考えるのは「あるドキュメントにアクセスできるユーザー一覧を保存しておく」といったユースケースです。
「他のユーザーと何かを共同編集するアプリ」を考えるとイメージがつきやすいと思います。
あるユーザーが、他のユーザーを招待して、その他人ユーザーに、自身の所有する何らかのデータを閲覧したり、編集したりするのを許可する、といった場面があるでしょう。
このような場合には、「誰にその閲覧や編集の権限を与えているか」を管理・保存する必要があります。
レストランのレビューアプリで言えば、レストランの管理者ユーザーが、同僚や部下の何人かのユーザーに限定して、レストラン情報の編集を許可するような場面です。
これまでセキュリティルールについてはあまり言及して来ませんでしたが、詳しい内容は次の動画としましょう。しかし、ここでセキュリティルールについて知っておいてほしいのは、セキュリティルールによって、特定のドキュメントにアクセスできるユーザーを制御できる、ということです。
つまり、レストランの管理者ユーザーが、同僚・部下ユーザーのユーザー ID を、あるドキュメントの配列フィールドに保存しておいて、「その配列フィールドに含まれるユーザー ID のユーザーだけが、このレストランドキュメントのフィールドを編集できる」といったことを実現できるということです。
レストランドキュメント: {
レストラン名:foo
住所:bar
ジャンル:baz
編集者ユーザー: [user-1, user-2, user-3]
}
さらに、配列フィールドではなく、Map フィールドのキーにユーザー ID を、バリューに「編集者」や「オーナー」といった権限を付与する、といった方法も良さそうです。
レストランドキュメント: {
レストラン名:foo
住所:bar
ジャンル:baz
役割: {
user-1: オーナー,
user-2: 編集者,
user-3: 編集者,
}
}
これをセキュリティルールで表現するならば、 documents.roles.userID == "editor" みたいなことができます。
とても便利な感じがしますが、このように「特定のデータに対するアクセス権限を特定のユーザーのみに許可している」場合には、その都度「どのユーザー ID がどのような権限をもっているのか」という情報を伴うドキュメントを読み込んで検証を行う必要があるということで、「ユーザー ID とそれに対応するユーザー権限が漏洩しそうな気がして、ちょっと気持ち悪い」と思うかも分かりません。
でも、おそらく大丈夫。
ユーザー ID はそのアプリの中だけでしか用いない(メールアドレスのように、複数の異なるアプリケーションで同じものを使わない)一意のデータで、ユーザー ID が割り出されたところで、そのユーザー ID を持つユーザーが誰なのかを特定するようなことは、まあできません。
「おそらく大丈夫」とか「(個人を特定するのは)まあできない」と言われても、セキュリティ的に完全には安心できないようにも思えますが、そんなときには、次の 2 通りの方法のどちらかで対応すると良いでしょう。
1 つ目は、そのような上位の編集権限をもつユーザーを、レストランドキュメントのサブコレクションの中に、ドキュメント ID をそれぞれのユーザー ID に一致させて保存し、そのドキュメントの中に、そのユーザーがもつ権限を記述しておくという方法です。
レストランドキュメント: {
レストラン名:foo
住所:bar
ジャンル:baz
...
...
編集権限ユーザー(サブコレクション):{
ユーザードキュメント (user-1): {
権限:オーナー
}
ユーザードキュメント (user-2): {
権限:編集者
}
ユーザードキュメント (user-3): {
権限:編集者
}
}
}
2 つ目は、「プライベートデータ」とでも名付けたサブコレクションを作っておいて、ここに「誰にどの権限があるか」という情報を持っておき、このデータはパブリックにしないようにします。このようなパブリックには公開しないコレクションは、社内の営業チームだけが参照するような想定のデータを保存したり、もしくは Cloud Functions がトリガーとして各種の API を実行するためのデータとして使用するようなユースケースで役に立つでしょう。
レストランドキュメント: {
レストラン名:foo
住所:bar
ジャンル:baz
...
...
プライベートデータ(サブコレクション):{
たった一つの秘密のドキュメント: {
役割: {
user-1: オーナー,
user-2: 編集者,
user-3: 編集者,
},
秘密の情報: XXX
}
}
}
今回の例ではどちらの方法でも大丈夫そうですが、皆さんの開発するアプリではどういう状況になりそうか、ぜひよく考えてみてください。
お気に入りのレストランを保存する
いよいよ最後の例を取り上げます。そして、今までの中でおそらく一番重要かもしれません。
「ユーザーがお気に入りのレストランを保存しておく機能はどう実現するか?」という例です。
これは
- あるユーザーは複数のレストランをお気に入りに登録することがある
- あるレストランは複数のユーザーからお気に入りにされることがある
という、多対多のリレーションシップの例であり、Firestore のような NoSQL の DB では度々問題になることがあります。
このレストランレビューアプリの DB のどこかに、ユーザーデータを保存する users コレクションを定義しているとしましょう。
お気に入りを保存していくための最初の選択肢は、「ユーザードキュメントの配列フィールドに、そのユーザーがお気に入りに登録しているレストランの ID を保存していく」というものです。
users: {
ユーザーのドキュメント 1: {
名前: 大谷
年齢: 26
お気に入りのレストラン:[rest-1, rest-2, rest-3]
},
ユーザーのドキュメント 2: {
名前: ダルビッシュ
年齢: 34
お気に入りのレストラン:[rest-1, rest-4, rest-5]
},
ユーザーのドキュメント 3: {
名前: 前田
年齢: 33
お気に入りのレストラン:[rest-2, rest-3]
}
}
Firestore の機能によって、そのような各ユーザードキュメントのお気に入りリストのフィールドに、新しい要素を追加したり、お気に入りから外したいレストランの ID を削除したりするのは簡単です。
アプリを起動するときに、このお気に入りリストに保存されたレストラン ID の一覧をクライアントのどこかに保存しておけば、レストラン一覧の中からレストラン ID が一致するものに、ハートマークやスターマークを付けて、お気に入りのレストランを区別するのはできそうです。
しかし、この方法だと「お気に入りのレストラン一覧をクエリで取得する」というのが難しくなります。もしやりたければ、お気に入りリストに保存されたレストラン ID の一つ一つに対して、別々にクエリを発行する必要があり、そこまでしてやっと「私のお気に入りのレストラン一覧」を表示すること材料が集まります。
もしくは、少しマシな方法として、Cloud Functions の呼び出し可能関数で、それと似たことをやることになるでしょう(これについてはまた別の動画で言及します)。あんまり良い UX にはならなさそうですね。絶対に受け入れられないという程にひどいという訳でもないでしょうが。
もし、このような「私のお気に入りのレストラン一覧」を表示するユースケースがそれほど頻繁に発生するものではないなら、むしろ全然アリな解決策です。
一方、もし「私のお気に入りのレストラン一覧」を表示するユースケースが頻繁に起こるなら、もう少し簡単に良いパフォーマンスを実現するために「非正規化データ」を使うことにします。
というのは、単にお気に入りのレストランの ID のリストを保存しておくのではなく、「私のお気に入りのレストラン一覧」を表示するために必要なデータを一通り Map で保持しておくという方法です。
この比較的大きな Map にはレストラン名、料理のカテゴリー、レストランの住所などが保存されておけば、「私のお気に入りのレストランページ」を表示する材料としては十分です。その中から特定のレストランの詳細ページへ進みたければ、そのレストランの ID を用いるなどして必要なクエリを発行すれば良いだけです。
しかし、ちょっと覚えておかないといけないのは、もし以前お気に入りにしておいた "Todd's Tofu Hut" という日本料理レストランが、いつの間にかハンバーガーレストランになっていたとき、この "Todd's Tofu Hut" をお気に入りにしていた全てのユーザーを抽出して、皆の「「私のお気に入りのレストラン一覧」」の中の "Todd's Tofu Hut" の情報を、日本料理屋からハンバーガー屋さんに更新しないといけないということです。
しかし、これは十分に実現可能です。
というのも、全てのユーザーの中から、お気に入りフィールドの "Todd's Tofu Hut"(ID: rest_1 とする)のレストランデータの値が空文字 "" より大きいというクエリ、つまり
usersRef.where("favorites.rest_1", ">", "")
のようなクエリを発行することで、"Todd's Tofu Hut" をお気に入りにしていた全てのユーザーを抽出することができるので、彼ら/彼女らのお気に入りレストランである "Todd's Tofu Hut" を、日本料理屋からハンバーガー屋さんへ、Cloud Functions で一気に更新できるからです。
この方法で考慮しておく必要があるのは、それぞれのユーザードキュメントに保存する情報が増えるので、1 MB のドキュメントサイズおよびフィールド数 20,000 までの制限があるということですね。
そこで、一人のユーザーがお気に入りに登録しておけるレストランの数に上限を設けておくと良いでしょう。
「私はお気に入りのレストランが 500 個もあるの!」なんて人には、
「お気に入りってなんですか...?」
と聞いてみると良いでしょう。
あれ、哲学的なこと言っちゃいましたかね...?
他の選択肢として、お気に入りのレストランの ID はリストとしてユーザードキュメントのフィールドに保存しておいて、さらにサブコレクションの中に、「私のお気に入りのレストラン一覧」を表示するのに必要な非正規化データを持っておくのも良いでしょう。
さらには、全ユーザー横断で、各ユーザーのお気に入りレストランのサブコレクションを array_contains で検索すれば、「あるレストランをお気に入りに含んでいるユーザー一覧を取得する」みたいなこともできます。こうしておくと、いろいろなユースケースに対応できそうですね。ただし、array_contains で発行できるクエリには 20,000 件までの上限があるので、やはりユーザーがお気に入りにしておけるレストランの数には、ちょうどよい上限を設けておくのが得策だと思われます。
...と説明してきましたが、実は私が考える今回のユースケースで最も良さそうな選択肢は、「全く別のトップレベルのコレクションである favoriteRestaurans コレクションに、全ユーザーのお気に入りのレストランを保存していく」という方法です。このドキュメントに、お気に入りにしたユーザーの ID、レストランの ID、そして各ユーザーの「私のお気に入りのレストラン一覧」を表示するのに必要な一部の情報(スニペット)を保存しておけば、いろいろなユースケースに応じることができます。
全員のお気に入りコレクション(トップレベルコレクション):{
お気に入りドキュメント 1: {
お気に入りにしたユーザー:user-1,
レストラン:rest-1,
スニペット:{
レストラン名: foo
住所: bar
ジャンル: baz
}
},
お気に入りドキュメント 1: {
お気に入りにしたユーザー:user-1,
レストラン:rest-2,
スニペット:{
レストラン名: foo
住所: bar
ジャンル: baz
}
},
お気に入りドキュメント 3: {
お気に入りにしたユーザー:user-1,
レストラン:rest-3,
スニペット:{
レストラン名: foo
住所: bar
ジャンル: baz
}
},
お気に入りドキュメント 4: {
お気に入りにしたユーザー:user-2,
レストラン:rest-1,
スニペット:{
レストラン名: foo
住所: bar
ジャンル: baz
}
},
お気に入りドキュメント 5: {
お気に入りにしたユーザー:user-3,
レストラン:rest-2,
スニペット:{
レストラン名: foo
住所: bar
ジャンル: baz
}
},
}
あるユーザーがお気に入りにしたレストランを取得するにしても
collection("favoriteRestaurans").where("user_id", "==", "user-1")
レストランで絞り込むにしても
collection("favoriteRestaurans").where("rest_id", "==", "rest-1")
発行すべきクエリはとても簡単です。
さらには各ユーザーの「私のお気に入りのレストラン一覧」を表示するための非正規化データも、たとえ、あるレストランが日本料理やからハンバーガー屋さんになってしまっとしても、上のようなクエリを発行して抽出されたドキュメントに対して、簡単に一括更新ができそうです。
ですので、今回の例では、「全く別のトップレベルのコレクションである favoriteRestaurans コレクションに、全ユーザーのお気に入りのレストランを保存していく」という選択肢を推します!
さて、これまでにたくさんの例を通じてより良い Firestore の DB 設計について考えてきました。
- どのようなときにドキュメントにするか、Map フィールドにするか
- どのようなときにサブコレクションにするか、配列フィールドにするか、個別のトップレベルコレクションにするか
など、この動画を観る前よりも皆さんが詳しくなり、より良いセンスが身についていると嬉しく思います。
そして、皆さんお気づきかもしれませんが、Firestore の DB 設計の方針に関する選択肢は、どれをとってもトレードオフで、唯一の正解みたいなものはあまり存在しません。
ですので、もしこの動画で紹介したのとは異なる良い方針や構成を思いついたなら、ぜひそれでやってみてください!そしてコメント欄でシェアして下さい!
それでは次の動画でお会いしましょう。
え、お腹空いたって?
それなら、"Todd's Tofu Hut" に行こうか。
そういえばあの店、いまはハンバーガー屋さんになっちゃたって聞いたよ。いやいや豆腐バーガーじゃなくて、お肉のハンバーガーね。
なんで店の名前は変えないんだろ。聞いてみよ。
ん、そっちは違う Todd だよ。
じゃあ、行こうか。
終わりに
翻訳は以上です。いかがでしたか?
動画は 14 分程度と決して長くはありませんが、多くのことが学べる教材だと思います。
動画でも述べられているように、作りたいアプリのユースケースや、開発者である私たちが何を許容できるか・できないか、などの基準によって、より良い Firestore の DB 設計の選択肢には色々な可能性があるようですが、公式が説明する網羅的で汎用的な知識を学ぶチャンスとして、皆さんの学習の参考になれば幸いです。
また、動画内で何度か言及されている Firestore の Security Rules についても
「Firestore Security Rules の書き方と守るべき原則」
という投稿を過去にしておりますので、ご興味のある方はご覧ください!