私はコウメ太夫が比較的好きだ。
彼に遭った最初で最後の機会は、まだ私が小学生の頃。
ショッピングモールで**"徒然なるままに書き散らしたコウメ日記"**に興じる彼に出会った。
その時のネタは今でも覚えている。
「(チャンチャヵ チャン×2 チャチャンヵ チャン×2)×2
最近目が悪いので。
コンタクトにしてみたら。
自分の頭が禿げてる事を知りました。 チクショウ。」
子供ながらに思った。
**「消え去る日は近い」**と。
私の直感的予測は当たり、2年もしないまま彼は芸能界の表舞台から姿を消した。
そこから時は流れること十数年、Twitterで不死鳥の如く復活を遂げる彼を目撃した。
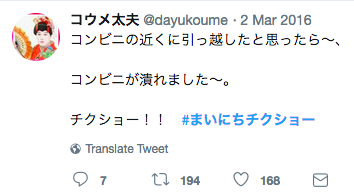
彼は2016年3月、何を思ったかチクショーネタを毎日つぶやく、
**"#まいにちチクショー"**キャンペーンを始動させた。
最初のtweetのいいね数はわずか160台と、始まりは静かだったが、
時間が経つに連れて下記のようなフォロワーが増えていった。
【事例1:コウメ太夫のネタを評価する者と、その評価を評価する者】
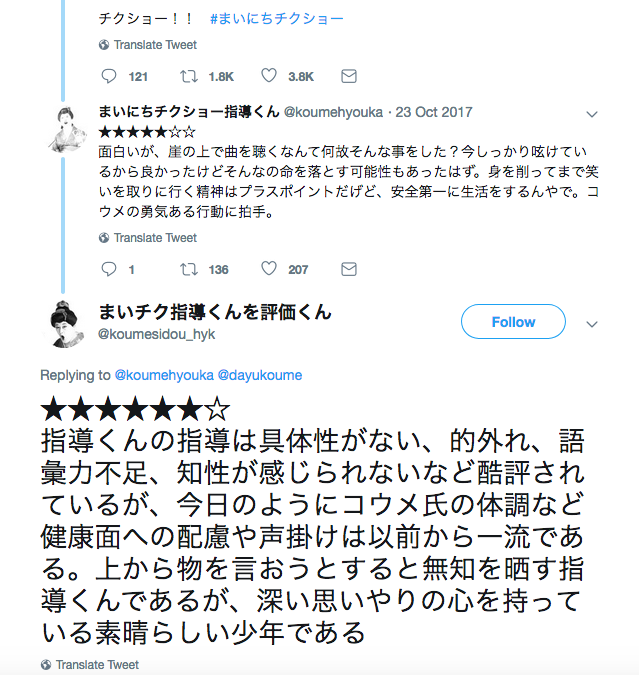
【事例2:コウメ太夫のネタをvisualizeする者】

【事例3:コウメ太夫のネタを哲学的視点から解釈する者】
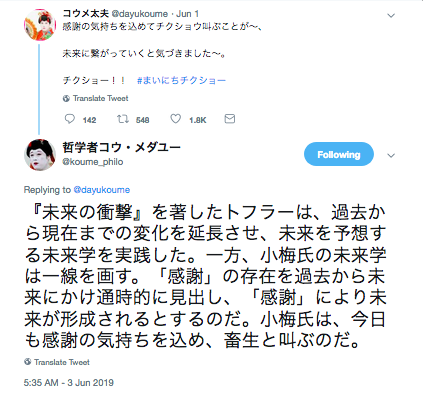
このようなフォロワーの増加に比して、彼のツイートの人気(=いいね,RT)は上昇しているように感じる。
今では1万RT以上のネタもあるほどだ。
このようにコウメ太夫のネタを媒介として、様々なコンテンツが生まれ、それらが相互作用し合い全体の価値が向上していくネットワークは、プラットフォームの様相を呈していると言えるだろう。
このプラットフォームの全体像を図式化すると下記のようになると考える。
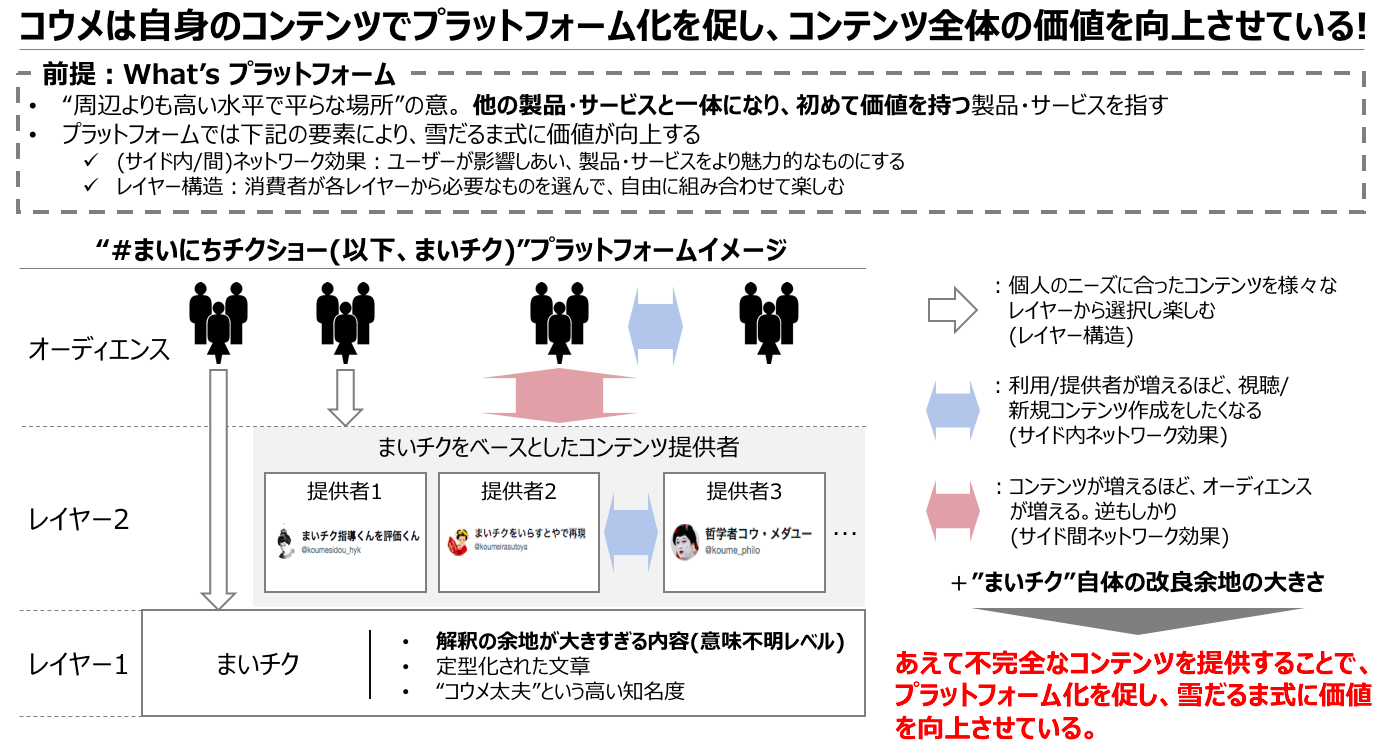
(「プラットフォームの教科書」(根来龍之)を参考に作成)
そう。
もうお分かりの通り、2019年6月現在、コウメ太夫はGAFA(Google, Apple, Facebook, Amazon)顔負けのプラットフォームを構築し、"芸人@Twitter"界のプラットフォーマーとして君臨しつつあるのだ。
そして今回その証明を、Facebookが開発した"Prophet"という時系列解析ライブラリを用いて行いたいと思う。
目的とゴール
**目的:**コウメ太夫の人気が上昇傾向にあるという仮説を立証する。
**ゴール:**時系列解析ライブラリ"Prophet"を用いて、コウメ太夫のtweetに対するいいね数の時系列変化を出力し、右肩上がりに上昇していることを確認する。
**サブミッション:**コウメ太夫が次いつバズるかを予測できるか、検証する。
Prophetとは?
Facebookが開発した時系列予測ライブラリ。
特筆すべきは、時系列データのトレンドを把握できるだけでなく、トレンドの変化点の検出も出来ること。
しかも、めちゃくちゃ簡単に。
もちろん回帰タスクも可能。
重回帰やSVR等の線形/非線形回帰モデルとは異なり、基本的には説明変数を必要としない。
どちらかというとARIMA(SARIMA)モデルのように、時系列でみたときのデータの変動からトレンド曲線を導出するアルゴリズム。
Prophetでは予測線をスプライン曲線(与えられた任意の点の各点を滑らかに結ぶ曲線)として表現している。モデル式は下記。
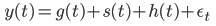
g(t)がトレンド成分、 s(t)が季節成分、 h(t)が祝日などのイレギュラーな効果成分、 εが誤差項となる。
(詳細は論文を確認願います。)
やりたいことの流れ
おおまかに
- コウメ太夫の"#まいにちチクショー"タグを含む全ツイートそれぞれのいいね数およびtweet日付を取得、データフレーム化
- いいね数の時系列変化をProphetを用いて分析
- (サブ)学習期間&テスト期間に分割し、時系列予測の予測精度を検証
と言った感じ。
実行環境
Python 3.7(Anaconda3系)
macOS Mojave 10.14.1
Jupyter Notebook
実行
ライブラリのインポート
まず、必要なライブラリをインポートする。
import tweepy
import re
import pandas as pd
import datetime as dt
from fbprophet import Prophet
import seaborn as sns
sns.set_style(style="ticks")
Prophet用のライブラリが未インストールの場合は、
ターミナルからpipでインストールする。
$ pip install fbprophet
Anacondaでインストールの場合は下記を実行。(こちらのほうがトラブルが少ない様子)
$ conda install -c conda-forge fbprophet
tweepy(Tweet情報取得用)のインストールは下記
$ pip install tweepy
tweet取得の準備
TwitterAPI経由でtweetデータを取得するためには、予めAPIキー、アクセストークンを取得する必要がある。
# キーの設定
consumer_key = "XXXXXXXXXXXXXXXXXXXXXXXX"
consumer_secret = "XXXXXXXXXXXXXXXXXXXXXXXX"
access_token = "XXXXXXXXXXXXXXXXXXXXXXXX"
access_secret = "XXXXXXXXXXXXXXXXXXXXXXXX"
取得方法は下記のサイトを参考にすると良いかも。
https://qiita.com/yokoh9/items/760e432ebd39040d5a0f
次に、取得対象のユーザーを設定する。対象はもちろんコウメ。ついでに取得するtweet数もここで設定。
## 取得対象の設定
# user_idの設定(”@〜”のユーザーIDをサイト(https://idtwi.com/)で数字に変換した後、こちらに代入)
USERid = "391900115"
# 取得したいツイート数の設定
numberOfTweets = 5000
APIキーを用いて、tweetデータを取得する準備をする。
# ユーザーのtweetを取得
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_secret)
api = tweepy.API(auth, wait_on_rate_limit = True)
wait_on_rate_limit = TrueはAPI制限回避のためのおまじない。(今回何度もAPIを叩くわけではないので、必要ないかも)
tweetデータの取得
カーソルオブジェクトを取得。tweepyのcursorを使うと、api.user_timeline メソッドなど 1 ページずつ結果を戻してくるメソッドのページネーションを考慮しなくても良くなるそう。
aTimeLine = tweepy.Cursor(api.user_timeline,id=USERid).items(numberOfTweets)
numberOfTweetsは冒頭で設定した取得ツイート数。
続いて取得したオブジェクトから必要なデータを抽出&整形する。
取得するデータ対象は"#まいにちチクショー"タグが含まれる、コウメ太夫のtweet全て。
t_txt = [] # Tweetのテキスト情報を格納(今回は不要)
t_num = [] # Tweetの日付、いいね数、RT数などを格納
cnt = 1
for tweet in aTimeLine:
## 数値・日付情報取得
fav = tweet.favorite_count
rt = tweet.retweet_count
date = str(tweet.created_at)[:10]
## テキスト情報取得・クレンジング
T = tweet.text.replace('\n','')
if "#まいにちチクショー" in T and "RT @" not in T:
T = re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", T)
T = T.replace('コウメ太夫のチクポーレディオ#', '')
T = T.strip()
T = T.replace('#まいにちチクショー', '')
T = T.replace('\u3000', '')
T = T.replace('チクショー!!', '')
t_txt.append([cnt, T])
t_num.append([cnt, date, fav, rt])
cnt += 1
tweetデータの集計
日付データの欠損を考慮しつつ、取得したデータからデータフレームを作成する。
### データ作成
## 取得データを集計
data = pd.DataFrame(t_num, columns = ["index", "date", "fav", "rt"])
data = data.set_index("index")
data = data.groupby("date")
data_agg = data[["fav","rt"]].sum()
## 今日までの日付リスト生成
date = dt.date(2016, 3, 1)
today = dt.date.today()
duration = (today-date).days
date_list = []
for i in range(duration):
date_list.append(date)
date += dt.timedelta(days=1)
date_list = [str(n) for n in date_list]
date_list_df = pd.DataFrame(date_list, columns = ["date"])
## 結合
dataset = pd.merge(date_list_df, data_agg, on = "date", how = "left")
dataset =dataset.fillna(0)
dataset = dataset.set_index("date")
予測精度を評価するために、学習データとテストデータを作成する。
各データセットの期間は下記。
[学習期間]
・2016-03-01~2019-02-28
→まいにちチクショーが開始した日から丸々3年間。年別のトレンドを掴むためにも、年単位での設定が良いと思われる。
[テスト期間]
・2019-03-01~2019-06-17とする。
→学習期間end~この記事を執筆した日から5日前までにした。感覚的にいいねの伸びは5日程度で落ち着くと考えたので。
# データ準備
train_data = dataset[dataset.index.get_loc("2016-03-01"):dataset.index.get_loc("2019-02-28")]
test_data = dataset[dataset.index.get_loc("2019-03-01"):dataset.index.get_loc("2019-06-17")]
test_data = test_data.reset_index(drop = True)
train_data = train_data.reset_index()
Prophetでモデル構築するための最後の準備。
Prophetの予測では、日付データの変数名を"ds"、トレンドを確認したい対象の変数名を"y"とする必要があるそう。
今回は"いいね数(fav)"を対象とする。(RT数を対象とする場合は"rt"を"y"に変更する。)
train_data = train_data.rename(columns = {"date":"ds", "fav":"y"})
Prophetの実行
早速Prophetモデルを学習させる。
m = Prophet(yearly_seasonality = True, weekly_seasonality = True)
m.fit(train_data)
たった二行でモデルの学習が完了してしまう。すごい。
yearly_seasonality は対象の変数に年間の周期性があると思われる場合にTrueにする。
weekly_seasonality も同様。
そして、最後に予測期間を120日として予測を実施し、結果をplotする。
future = m.make_future_dataframe(periods = 120)
forecast = m.predict(future)
m.plot(forecast)
結果を確認する
まずいいね数の、3年間の推移を確認する。
コウメ太夫の長年の努力の結果が写実される、世紀の一瞬...!圧倒的緊張感...!
どうだ...!
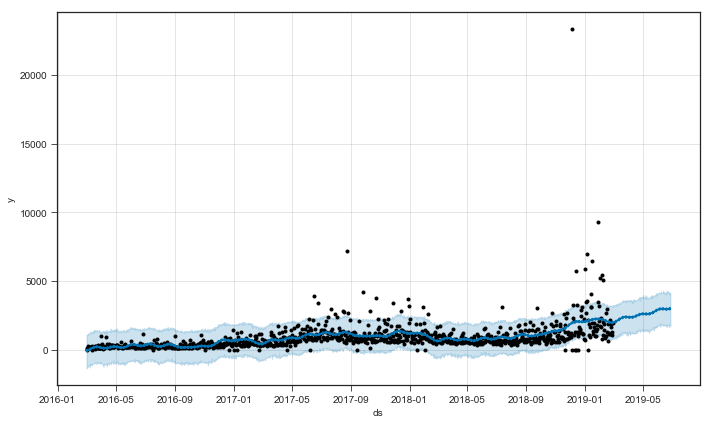
このグラフを見る限り、なんとなく右肩上がりに見えるのではないだろうか...!?
ちなみにこのグラフの中で外れ値とも言える、2018年年末に25,000近くのいいねを獲得したtweetは下記であった。

どうした、めちゃくちゃ面白いではないか (失礼)
更に細かく見てみよう。
Prophetにはplot_componentsというメソッドが存在する。
m.plot_components(forecast)
これを実行すると、簡単に下記のトレンドを確認することが出来る。
まず学習期間(+予測期間)全体でのトレンドを確認する。
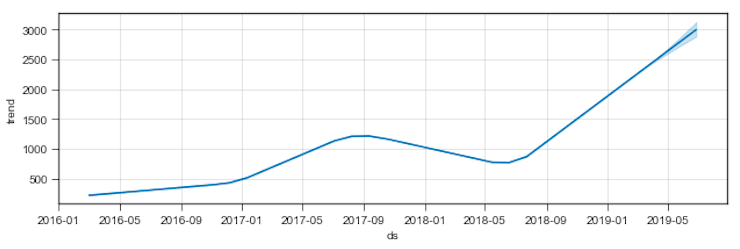
これは紛うことなく右肩上がりのトレンド。
コウメ太夫が年々人気になっている証といえるだろう。よかった、本当によかったコウメ太夫。
あなたが日々積み重ねてきた努力は着実に実を結んでいる、自信を持って今の道を進んでいってほしい。
この時点で私の仮説は立証され、目的は達成された。
一方で、このplot_componentsメソッドには上記のほか、
下記のグラフも出力されるので、ついでに見てみる。
1.1週間の曜日別のトレンド
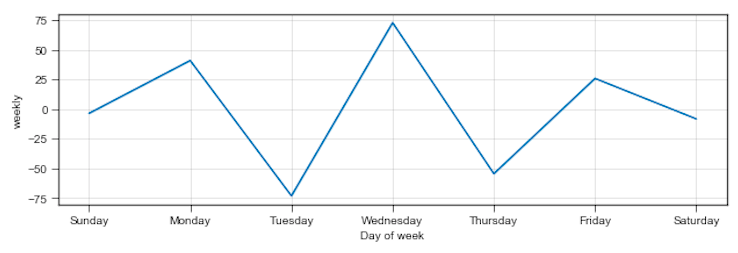
この図を見る限り、月、水、金にいいねの山が来る様子。
もしとっておきのネタが思いついたら、ぜひ月、水、金のいずれかの曜日にtweetすると良いかもしれない。
2.1年の月別のトレンド
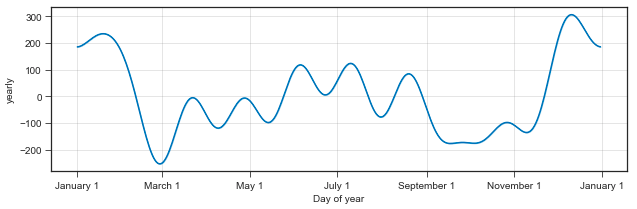
図を見る限り、年末年始にいいね数の山が来ている。また、7~8月あたりにも小さな山が乱立していることから、長期休暇にあわせていいねが増える傾向にあることがわかる。
もしとっておきのネタが思いついたら、ぜひ年末年始、夏休みにtweetすると良いかもしれない。
(2019-10-02 追記:縦軸の意味はこの方が丁寧に説明してくださっているので、参考にしてください。https://github.com/facebook/prophet/issues/392)
おまけ
過去のトレンドから、未来のいいね数を予測できないかを検証してみる。
prophetから出力したデータから、テスト期間のデータ(=予測結果データ)を抽出し、
同期間の実績データと照らし合わせ、どれくらいあたっているかを確認する。
精度評価指標はMAPE(平均絶対パーセント誤差)を選択。
forecast = forecast.set_index("ds")
result = forecast[forecast.index.get_loc("2019-03-01"):forecast.index.get_loc("2019-06-17")+1]
result = result.iloc[:, -1]
result = result.reset_index(drop = True)
test = test_data.join(result)
test = test[test['fav'] != 0]
test["MAPE"] = abs((test["fav"]-test["yhat"])/test["fav"])*100
test["MAPE"].mean()
結果は...
88.9%
約90%の誤差。。。つまり、いいね数の実績値が100とした時、
予測値が190位になってしまっているということ。
やっぱりバズり予測は簡単ではなさそうね。
さいごに
彼にこのTipsが届くように祈っている。
また、Pythonを触り始めてからまだ日が浅いので、稚拙なコードが散見されると思います。
質問・指摘等ありましたら、ぜひ気軽コメントください。
LOVE コウメ。