前回,文を「形態素」なる単位に分割する方法を学んだ.今回の可視化編では,形態素解析の結果をベースに,「分析対象の文書がどのような特徴を持つか」を直観的に理解する方法を学ぶ.
登場する用語
- ワードクラウド: 文書中にどの語が多く含まれるかを可視化する手法
- Word2Vec: 文字列である語を,その語が登場する"文脈"を手掛かりに,特徴ベクトル(ゆるふわに言えば,その語を数で表したもの)に変換する手法.
- UMAP: 次元削減手法.多次元(3次元以上)のベクトルを可視化するために用いることが多いが,クラスタリング等の前処理にも使える汎用的な手法.
以下,Google Colabでの実行を想定している.
![]()
テキストのダウンロードと確認
前々回,前処理したテキストをダウンロードする.
!wget https://github.com/ezoalbus/kara_nlp/blob/master/data/cleansed_kara.txt
ダウンロードしたテキストを読み込み,確認する.
with open('cleansed_kara.txt', 'r', encoding='utf-8') as f:
text = f.read()
print(text)
ワードクラウド
準備: 分かち書き
まず,前回と同様の手順で分かち書きを行う.
# janomeのインストール
!pip install janome
次に,ストップワードの除去の準備を行う.ストップワードとは,一般的な使用頻度の多い語であるために,文書の特徴を表さないものを指す.ストップワード取得のためには,前回紹介したGiNZAを使うこともできるが,今回はSlothLibが公開しているものを使用する.
ダウンロード:
!wget 'http://svn.sourceforge.jp/svnroot/slothlib/CSharp/Version1/SlothLib/NLP/Filter/StopWord/word/Japanese.txt'
集合として格納(計算効率のため)
# ストップワード辞書をリストに格納
with open('./Japanese.txt', 'r', encoding='utf-8') as f:
stopword_ls = f.read().splitlines()
# 後で頻繁に検索するので集合にしておく
stopword_set = set(stopword_ls)
名詞の形態素を抽出し,ストップワードであるものを除外する.
from janome.tokenizer import Tokenizer
noun_ls = [] # 名詞の形態素を格納
tokenizer = Tokenizer(wakati=False)
for t in tokenizer.tokenize(text):
word_class = t.part_of_speech.split(',')[0] # 品詞
if word_class == '名詞':
noun_ls.append(t.surface)
# ストップワードの除去
noun_ls = [n for n in noun_ls if n not in stopword_set]
noun_concat_str = ' '.join(noun_ls)
print(noun_concat_str)
ワードクラウドの描画
インストール:
!pip install wordcloud
次に,日本語フォントを利用可能にするための準備を行う.
フォントのインストール:
!apt install fonts-takao-gothic
フォントのファイル(.ttfファイル)のパスを取得:
import matplotlib.font_manager as fm
font_ls = fm.findSystemFonts(fontext='ttf')
jp_font_path = [f for f in font_ls if 'takao' in f][0]
print(jp_font_path)
準備が整ったので,ワードクラウドを作成する.
%matplotlib inline
import matplotlib.pyplot as plt
from wordcloud import WordCloud
# ここで,WordCloud()の引数として,stopwordを指定することもできる(stopwords=<ストップワードの辞書>)
wc = WordCloud(width=600, height=400, background_color='white',
colormap='ocean', font_path=jp_font_path)
plt.imshow(wc.generate(noun_concat_str))
plt.axis('off')
plt.show()
結果:

主要な登場人物の名前が見られる.
Word2Vec & UMAPでの可視化
ワードクラウドでは,文書中に多く登場する語を一目で確認することができるが,出力結果における語の近接関係に意味はない.つまり,ワードクラウド上で近くにあっても"意味的に近い"とは言えない(「意味とは何か」というのは難しい話だが).
ということで,次は語同士の関係も含めて可視化したい.共起関係などを用いて可視化するほうが一般的かと思うが,今回はWord2Vecと汎用的な次元削減手法であるUMAPを用いる.
Word2Vec
まず,語を特徴ベクトルに変換するために,gensimをインストールする.
!pip install gensim
次に,連続した文字列を文に分割する.GiNZAでも可能だが,計算時間の削減のために以下のように雑に行う.
import re
def split_to_sents(text):
"""
文単位に分割(シンプルなルールベース)
"""
sents_ls = re.split(r'\n|。', text) # 本当は,"!"や"?"でも区切りたいところ
sents_ls = [s.strip() for s in sents_ls if len(s) != 0]
return sents_ls
sents_ls = split_to_sents(text)
from pprint import pprint
pprint(sents_ls)
出力:
[..., 'おれがこの令嬢のそばへ近寄ったのは、それからかなり後のある夜会の席だったが、話しかけてみたんだけれど、ろくにこちらを見向きもしないで、軽蔑したように口をきっと結んでいるじゃないか',
'ようし、と、おれは肚の中で思ったんだ、今に仇を討ってやるから! おれはそのころ、たいていの場合、おそろしく無作法者だった',
'それは自分でも気がついていた',
'だがそれより、もっと感じたことは、この『カーチェンカ』が無邪気な女学生というよりは、気性のしっかりした、自尊心の強い、真から徳の高い、それに第一、知恵と教育のある淑女だのに、おれにはそいつが両方ともないってことなんだ',
'おまえはおれが結婚の申しこみでもしようとしたと思うかい? '
'どうしてどうして、ただ仇が討ちたかったばかりだ、おれはこんな好漢なのに、あの女はそれに気づきおらん、といった肚なのさ',
'が、当分は遊興と乱暴で日を送った',
'とうとうしまいに中佐はおれを三日間の拘禁に処したくらいだ',
'ちょうどその時分、親爺がおれに六千ルーブル送ってよこした',
'それはおれが正式の絶縁状をたたきつけて、この後二度と再び無心をしない、『総勘定』を済ましたことにするからと言ってやった結果なんだ',
'当時おれにはなんにもわからなかったんだ',
'こちらへ来るまで、いや、つい、この四五日前まで、というより恐らく今日まで、親爺との金銭関係がどうなっているか、さっぱりわからなかったんだ',
'だがそんなことはどうだってかまやしない、あとまわしだ',
'ところがその六千ルーブルを受け取ったころ、おれは突然、ある友だちがよこした手紙から、自分にとってとても興味のある事実を知ったのだ',
'それはほかでもない、おれたちの中佐が秩序紊乱の嫌疑で当局の不興を買っているということなんだ',
'つまり、反対派の陥穽にひっかかったんだよ',
'で、直接師団長がやって来て、小っぴどく油を絞ったのだ',
'それからしばらくして、退職願いを出せという命令があったのだ', ...]
完全ではないが,この結果でとりあえず妥協する.
次は,分割した文ごとに分かち書きを行う.
# 形態素解析
def wakati(tokenizer, text):
token_ls = list(tokenizer.tokenize(text))
return token_ls
token_ls = []
tokenizer = Tokenizer(wakati=True) # Tokenizerのインスタンス化はforループの外で行う
for sents in sents_ls:
token_ls.append(wakati(tokenizer, sents))
分かち書きの結果を用いて,Word2Vecを適用する.
from gensim.models import word2vec
model = word2vec.Word2Vec(token_ls, size=100, min_count=1, window=5, iter=200)
モデルが学習出来たら,試しに類似語の取得をしてみる.
model.wv.most_similar('アリョーシャ', topn=10)
出力:
[('彼', 0.4988832473754883),
('リーズ', 0.4983484148979187),
('ミウーソフ', 0.4935529828071594),
('イワン', 0.4455975592136383),
('彼女', 0.4432331621646881),
('ラキーチン', 0.42547866702079773),
('僧', 0.42096030712127686),
('イワン・フョードロヴィッチ', 0.4118502736091614),
('フョードル・パーヴロヴィッチ', 0.40699303150177),
('スメルジャコフ', 0.40468165278434753)]
人物名が多く見られる.
UMAP
UMAPとは,次元削減手法のt-SNEの代替手法で,近年ではデータサイエンス領域のみならず,single-cell analysisにおける可視化などにも使われている.
インストール:
!pip install umap-learn
全ベクトルを可視化するとごちゃつくので,登場回数の多い名詞に限ってplotする.
名詞の登場回数を数え,上位100語を抽出.
from collections import Counter
count = Counter(noun_ls) # noun_lsはワードクラウドのところで登場
most_common_noun, n_appearances = zip(*count.most_common(100))
上位100語のwordvecを抽出する.
data = [] # 特徴ベクトル
labels = [] # 単語の文字列
for s in most_common_noun[2:]: # 0, 1番目はゴミなので捨てる
data.append(model.wv[s])
labels.append(s)
n_appearances = n_appearances[2:] # 点の描画サイズを決めるために使う
UMAPで各特徴ベクトルを2次元に落とし,matplotlib.pyplotで散布図をかく.この際,日本語表示に対応させるためにフォントの設定が必要である点に注意.
次元削減:
import umap
%matplotlib inline
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
fp = FontProperties(fname=jp_font_path, size=16)
reducer = umap.UMAP(random_state=42)
embedding = reducer.fit_transform(data)
散布図の描画:
fig, ax = plt.subplots(figsize=(12, 10))
plt.scatter(embedding[:, 0], embedding[:, 1], c='c', s=n_appearances)
for i in range(len(embedding)):
plt.annotate(labels[i], (embedding[i, 0], embedding[i, 1]),
fontsize=12, fontproperties=fp)
plt.show()
結果:
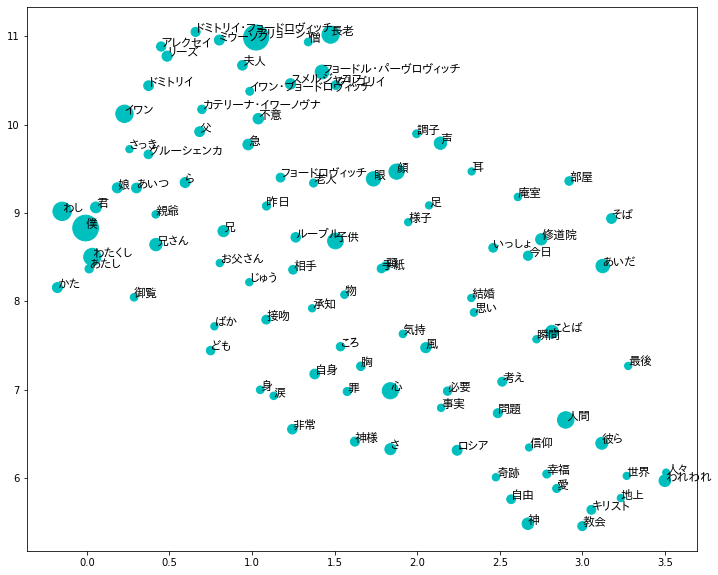
たとえば,信仰に関する語が右下に集まっていることがわかる.
おわり.