初めましてこなんです!
今回は**”旅行写真フォルダから見えてくるユーザーの傾向”**ということで
**「旅行写真をヒストグラム類似度を基に階層的クラスタで分類する」**プログラムを紹介します!
1. はじめに
改めまして!
卒論の合間にQiitaを書いています。
**こなん(@y_konan)**です。
僕は大学でAI, 自然言語処理がメインの研究室で
**”ユーザーの潜在的嗜好の表出化”**を主に研究で取り扱っています。
今回は、その研究でボツになったシステムの中で、
割と面白いプログラムがあったので、成仏の意味も込めて、記事として残します。
2. プログラムの全体像
1. 旅行写真フォルダのインポート
2. 画像の減色処理
⇒ ヒストグラム同士を比較するので、ある程度まとまった特徴量にしておく
3. ヒストグラムの作成
⇒ 画像のサイズを正規化した上で、減色した画素値の出現分布を表すヒストグラムをリストで表現
4. 階層的クラスタリング
⇒ ヒストグラム類似度により画像群をk平均法を用いてクラスタリング
(scipyのlinkageによって実装)
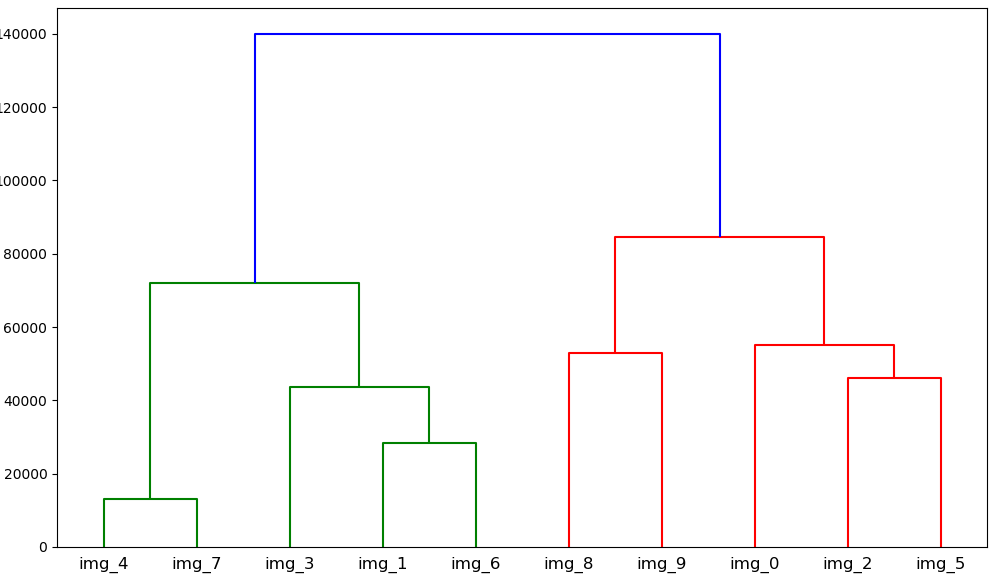
5. デンドログラムの出力
⇒ 記事先頭のグラフ
(scipyのdendrogramによって出力)
3. 実装
-
全体のクラス設計

データ量により実行時間が長くなった際に、部分的に結果を見られるようにするため、main部を分けています。
ではここからプログラムの一部を紹介をしていきます!
※フォルダとファイルを書き間違えているケースが多数あります。
- 減色処理(declease_color.py)
def declease_color(img):
for hei in range(len(img)):
for wid in range(len(img[0])):
for color in range(3):
value = img[hei][wid][color]
if value < 64:
img[hei][wid][color]=32
elif value < 128:
img[hei][wid][color]=96
elif value < 196:
img[hei][wid][color]=160
else:
img[hei][wid][color]=224
return img
R, G, B:0~255を
それぞれ範囲を取り、32, 96, 160, 224の4色に分ける
そして1枚の画像をR×G×B = 4×4×4 = 64色で表現する
(参考:http://web.tuat.ac.jp/~s-hotta/gke/ch2/step22.html)
- ヒストグラムの作成(histogram.py)
# 400×400pixelに正規化
def norm(hist_list):
divide_value = (400*400)/sum(hist_list)
for i in range(len(hist_list)):
hist_list[i] = hist_list[i]*divide_value
return hist_list
# RGBの64色ヒストグラムの作成
def histgram(img):
result = [0]*64
for hei in range(len(img)):
for wid in range(len(img[0])):
#各色の取得
r = img[hei][wid][2]
g = img[hei][wid][1]
b = img[hei][wid][0]
#64通りに振り分け
if r==32:
if g==32:
if b==32:
result[0]+=1
elif b==96:
result[1]+=1
elif b==160:
result[2]+=1
elif b==224:
result[3]+=1
elif g==96:
if b==32:
result[4]+=1
elif b==96:
result[5]+=1
elif b==160:
result[6]+=1
elif b==224:
result[7]+=1
elif g==160:
if b==32:
result[8]+=1
elif b==96:
result[9]+=1
elif b==160:
result[10]+=1
elif b==224:
result[11]+=1
elif g==224:
if b==32:
result[12]+=1
elif b==96:
result[13]+=1
elif b==160:
result[14]+=1
elif b==224:
result[15]+=1
elif r==96:
if g==32:
if b==32:
result[16]+=1
elif b==96:
result[17]+=1
elif b==160:
result[18]+=1
elif b==224:
result[19]+=1
.
.
.
elif g==224:
if b==32:
result[60]+=1
elif b==96:
result[61]+=1
elif b==160:
result[62]+=1
elif b==224:
result[63]+=1
return result
それぞれのpixelを46通りに振り分けてヒストグラムを作成
(この部分が嫌い、、絶対もっと良い方法がある、、)
- クラスタリング(clustering.py)
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from scipy.cluster.hierarchy import linkage, dendrogram, fcluster
from sklearn.datasets import load_iris
def main(listdata, value, filename):
#データラベルの作成
listlabel = []
for row in listdata:
listlabel.append(row.pop(0))
# 階層型クラスタリングの実施
# ウォード法 x ユークリッド距離
linkage_result = linkage(listdata, method='ward', metric='euclidean')
#デンドログラムの作成
plt.figure(num=None, figsize=(12, 7), facecolor='w', edgecolor='k')
dendrogram(linkage_result, labels=listlabel)
#デンドログラムの保存
plt.savefig('./clustering/'+filename+'.png')
#デンドログラムの表示
#plt.show()
#クラスタを分ける距離の基準(maxの何割で切るか)
standard = value*max(linkage_result[:,2])
result = fcluster(linkage_result, standard, criterion='distance')
return result
ウォード法による階層的クラスタリング
4. 実行結果
-
実験条件
実験に用いた画像は以下の10枚です
(画像の名前は1段目の左端から右に0, 1, 2, ...と並べています)
-
実行結果
-
考察
最上部からおよそ50%の位置で切った際には4つのクラスタが出来ました。
それぞれクラスタを名付けるとすると「川と湖」,「空と山」,「暗い画像」,「落ち着いた色の建造物」のようになると思います。色の特徴量だけでもこれぐらいの精度で分けることが可能だと分かりました。
これが研究の中でボツになった理由としては、
人の好む画像には色的な特徴が少なからず出てくるだろうとの
仮説のもとにここまでプログラムを作成してきましたが。。
色による嗜好分析を過信し過ぎていて、想定より結果が出なかったからです。
これ以降の研究では、画像にハッシュタグのようなタグ付けを行い、
画像に加えて、言語的な観点からもユーザーの嗜好分析を行っています。