正しさは相対的な概念である。 Bertrand Meyer [1]
Bertrand Meyer氏は「契約による設計」という概念から例外を導出し、例外の必要性をエレガントに説明しています。また、彼の説明に則れば今までの議論と比べて例外をいくぶんか形式的に扱えるようになります。契約による設計を学ぶ前に、プログラムの正しさについてもう一度考えてみましょう。
プログラムの正しさ
あるプログラムが正しいかどうかを判定するにはどのようにすれば良いでしょうか。最も簡単な方法は、あるプログラムの正しさを形式的に定義する事です。より直接的に言えば、あるプログラムの正しさを簡単な論理式で表現します。その論理式が真ならばそのプログラムは正しい。偽ならばそのプログラムは正しくありません。
これだけだと関数の戻り値を検査すれば良いだけのようにも聞こえます。しかし、そう簡単な話ではありません。純粋でない言語の場合、処理の前後で副作用が発生している可能性があります。例えば、処理を呼び出すたびにデータの内容が書き換わることがあるでしょう。なるほど、戻り値だけを調べるだけでは済まなさそうです。
さらに、ある処理が呼び出される前提となる条件を考える必要があります。例えば整数の除算を考えてみましょう。除算処理は除数に0が来た時のみ失敗します。除数が0でない全ての整数において成功します。処理によっては、呼ばれる前の前提が成否に大きく影響をあたえるものがあります。
これらを加味して、ある処理が呼ばれる前後で成り立つ条件を考えれば、その処理の正しさを表現できたことになるはずです。それらを便宜上「正しさの条件」と呼ぶことにしましょう。
ある処理が呼ばれる前に成立すべき条件を事前条件、ある処理が呼び出された後に成立すべき条件を事後条件と呼びます。事前条件、処理、事後条件の3組を考えることでその処理の正しさを判定することができます*1。
これで処理の正しさを考えることが出来ました。次に、データの正しさを考えましょう。データが正しくなければ、そのデータを用いた処理も正しくはないでしょう。
データは処理とは違い、呼ぶ呼ばれるの関係にありません。そのため、常に成り立つ1つの条件を考えれば良いでしょう。このような、データが常に満たすべき条件を不変条件と呼びます。例えば、自然数の不変条件は「0以上」です*2。
ここで、「成功」と「失敗」をより形式的に定義することができます。成功とは「関係データの不変条件が常に成り立ち、事前条件が成り立ち、処理が呼ばれ、事後条件が成り立つ」場合を指します。失敗とは「関係データの不変条件がいずれかの時点で成り立たない、又は事前条件が成り立たない、又は処理呼び出し後の事後条件が成り立たない」場合を指します。つまり、正しさの条件が成り立てば成功。成り立たなければ失敗です。
例:スタック
例としてスタックの正しさについて考えてみましょう。スタックを実装する言語は何でもいいのですが、ここではRubyで書いてみましょう。
class Stack < Struct.new(:arr)
def push(value)
arr << value
end
def pop()
arr.slice! -1
end
end
さて、考えるべきはStackクラスの不変条件と、pushとpopの事前条件と事後条件です*3。
最初にStackクラスの不変条件です。これはarrアクセサがArray相当、つまり<<又はslice!メソッドを持つことです。厳密にはarr.<<やarr.slice!の操作についても規定すべきですが、Ruby文化とも合いませんのでここでは省略します。Stackクラスの不変条件はarr.respond_to? '<<' and arr.respond_to? 'slice!'です。
次にpushメソッドの事前条件を考えてみましょう。しかし、pushメソッドは特に前提となる条件がありません。値を終端に追加するだけですので、当然です。つまり、事前条件がありません。言い換えれば、常に事前条件は満たされます。よって、pushメソッドの事前条件はtrueです。
pushメソッドの事後条件は、arrの終端にvalueを追加したことです。これを論理式で直接表現する事は出来ません。何故なら、追加された事を確かめるには処理が呼び出される前のarrと比較する必要があるからです。そこで、事後条件でのみ、処理が呼び出される前の値にアクセスできるようold(expr)という構文を導入しましょう。そうすると、事後条件はarr.length - old(arr).length == 1 and arr.last == valueと書けます。
そしてpopメソッドの事前条件ですが、これは厄介です。arrが空配列の場合はどうでしょう。「空のスタックからpopする」という行為はどのような意味があるのでしょうか。ひとまずここでは空スタックのpopを正しくないと仮定します。そうすると、事前条件全体はarr.length != 0と書くことができます。
最後にpopメソッドの事後条件ですが、呼び出される前のarrの終端から値を取り出して返しているかどうかです。しかし、これも直接論理式で表現できません。何故なら、処理が返した値を参照できないからです。そのため、処理が返した戻り値をresult()でアクセスできるよう拡張しましょう。そうすると、事後条件はold(arr).length - arr.length == 1 and result() == old(arr).lastと書けます。
以上をコメントとして記述してみましょう。
# 不変条件: arr.respond_to? '<<' and arr.respond_to? 'slice!'
class Stack < Struct.new(:arr)
# 事前条件: true
# 事後条件: arr.length - old(arr).length == 1 and arr.last == value
def push(value)
arr << value
end
# 事前条件: arr.length != 0
# 事後条件: old(arr).length - arr.length == 1 and result() == old(arr).last
def pop()
arr.slice! -1
end
end
失敗の原因
事前条件、事後条件、そして不変条件を考えると、処理が失敗する可能性としては
- 事前条件が成り立たない
- 事後条件が成り立たない
- 不変条件が成り立たない
の3通りの組み合わせであることがわかります。ここでは各々の条件が独立に成り立たない場合について詳しく分析してみましょう。各々の条件の失敗の組み合わせを考える必要はありません。何故なら、これら3つの条件の内、どれか1つの条件でも成り立たなければ処理の失敗が決まるからです。
事前条件が成り立たない
事前条件が成り立たない場合、処理は失敗します。もし事前条件が表明されていた場合、その処理が失敗するかどうかは処理の呼び出し側から確認できます。事前条件を満たすように呼び出せば成功、そうでなければ失敗です。
だとすれば事前条件を満たすべき責任とは処理の呼び出し側にあるのでしょうか。より端的に言えば、事前条件が偽となる失敗が起きたとすれば、呼び出し側が悪いのでしょうか。
これが成り立つにはある条件が必要です。それは「事前条件で呼び出された全ての処理が呼び出し側から呼び出せること」です。例えば先程のスタックプログラムを考えてみましょう。popメソッドの事前条件はarr.length != 0です。しかし、Stackの呼び出し側からはarr.lengthが呼び出せないため、呼び出し側はStackのpopメソッドを適切に呼び出す事ができません。
ではarr.length == 0を返すempty?メソッドをStackクラスに定義したとします。この場合、popメソッドの呼び出し側はempty?メソッドを調べることで安全にpopメソッドを呼び出すことができます。
Stackクラスはこれで呼び出し側にとってもフェアな実装となりました。empty?メソッドは実装が簡潔なので事前、事後条件は省略しています。
# 不変条件: arr.respond_to? '<<' and arr.respond_to? 'slice!'
class Stack < Struct.new(:arr)
def empty?
arr.length == 0
end
# 事前条件: true
# 事後条件: arr.length - old(arr).length == 1 and arr.last == value
def push(value)
arr << value
end
# 事前条件: not empty?
# 事後条件: old(arr).length - arr.length == 1 and result() == old(arr).last
def pop()
arr.slice! -1
end
end
まとめましょう。事前条件で呼び出された全ての処理が呼び出し側から呼び出せる場合、事前条件が成り立たない責任は処理の呼び出し側にあります。何故なら、呼び出し側は合法的に事前条件の合否を判断できる手段を有していたにも関わらず、それを怠ったためです。さらに言えば、事前条件が満たせない場合、呼び出し側には回避手段がありますが実装側にはどうしようもありません。
事前条件が成り立つ時、処理は正しく呼ばれていることが保証されます。
事後条件が成り立たない
事後条件が成り立たない場合も、処理は失敗します。これはどちらが悪いのでしょう。実装側でしょうか?それとも呼び出し側でしょうか?
事前条件の時は呼び出し側に責任がありました。しかし、「事前条件で呼び出された全ての処理が呼び出し側から呼び出せること」という実装側の責任を果たした上での呼び出し側の責任です。これは、事前条件は引数等呼び出し側がコントロール可能なものを対象としているためです。では、事後条件は何を対象に扱っているかというと、主にその処理の結果です。これは呼び出し側にはどうすることもありません。
事後条件が成り立たない責任は実装側にあります。何故なら、実装側は事後条件を満たすような処理が実装できると表明しているにも関わらず、それを怠ったためです。さらに言えば、呼び出し側には事後条件を正しく満たすような努力の余地がありません。
事後条件が成り立つ時、処理は正しく実装されていることが保証されます。
不変条件が成り立たない
不変条件が成り立たない場合も、処理は失敗します。ここで、不変条件が呼び出し側の責任だと仮定してみましょう。であれば、データは外部から不変条件を満たしたり破壊したりすることができます。これは好ましくありません。カプセル化とは、不変条件を満たすようなデータの抽象化だと考えることができます。もし適切にカプセル化されているのであれば、呼び出し側からデータの不変条件に手を加えられるべき道理はありません。
不変条件が成り立たない責任は実装側にあります。ここでいう実装側とは、データとそれに関係する処理全ての実装を行ったものを指します。例えばオブジェクト指向プログラミングでは両者は不可分なものとして一体化され、「オブジェクト」と呼ばれます*4。つまり、不変条件はオブジェクトが適切に実装されている限りにおいて、常に満たされます。
不変条件が成り立つ時、オブジェクトは正しく実装されていることが保証されます。
契約による設計
今まで、「実装側」と「呼び出し側」という2人のプログラマを登場させました。そして、あるプログラムの失敗を3通りに分け、各々の場合でどちらが悪いのかについて議論しました。Bertrand Meyer氏は正しさの条件が2者間の契約とみなせることに気づきました。契約、つまり呼び出し側の負うべき義務とそれによる権利、実装側の負うべき義務とそれによる権利を正しさの条件から説明できると考えたのです。
以下に3つの条件を契約とみなした時の呼び出し側と実装側の義務と権利についてまとめてみました。とは言え不変条件は登場しません。不変条件は特定処理の呼び出しに関せず常に成り立つべき正しさだからです。
| 当事者 | 義務 | 権利(≒利益) |
|---|---|---|
| 呼び出し側 | 処理を適切に呼び出す(事前条件を満たす) | 処理が成功する(事後条件が満たされる) |
| 実装側 | 処理やオブジェクトを適切に実装する(事後条件を満たす) | 処理が適切に呼ばれる(事前条件が満たされる) |
この考えに則った設計手法を契約による設計(DbC: Design by Contract)と呼びます。ここでは例外についてのみ考えるため、設計手法としての契約による設計は扱いません。
空スタックのpopは正しくないのか?
Stackクラスの例ではpopメソッドの事前条件をnot empty?と決めました。しかし、RubyのArrayクラスのpopメソッドは、配列が空の場合nilを返します。もっと言えば、現在の実装arr.alice! -1はarrが空の時nilを返します。これはどちらが正しいのでしょうか?
答えは、場合による、です。「正しさの条件」とは言い換えれば「正しさの定義」です。つまり、ここで述べた3つの条件による「正しさ」とは「仕様」のことです。空スタックのpopを正しいとしてnilを返しても良いですし、正しくないとして失敗させても良いです。どのような仕様にするかは要求を鑑みてプログラマが自分で判断する必要があるというだけの話です。契約のメタファーを借りれば、プログラマは要求に合うようにプログラムの正しさを定義する権利があります。もちろん、プログラムを定義した正しさを満たすよう適切に実装する義務の上での権利です。
契約が破られるとき
契約という概念を考えた時、失敗を以下のように再定義できます。
ルーチンが契約を満たす状態で実行を終えた場合、そのルーチンコールは成功である。成功しなければ失敗である。 [1]
そして、契約と失敗から例外を再定義できます。
ルーチンの失敗によって、そのルーチンの呼び出し側に例外が発生する。 [1]
前日に述べたように、例外は回復するか通知するかのどちらかです。
ルーチンの実行中に例外が起き、ルーチンがその例外から回復しない場合に限り、そのルーチンコールは失敗となる。 [1]
例外から回復とは、その処理の契約を満たすように出来るかということです。回復できれば成功です。できなければ失敗なので、処理の呼び出し元へ例外が投げられます。
Meyer氏は個々の契約の違反は本質的な問題では無いと考えました。つまり、彼の言葉を借りれば「戦闘の1つには負けても戦争そのものに負けたわけではない」のです。ある処理の契約違反を別の処理が尻拭いしてくれれば、それで良いというわけです。
この関係を図にまとめてみました。例外が契約の観点から見事に説明できています。
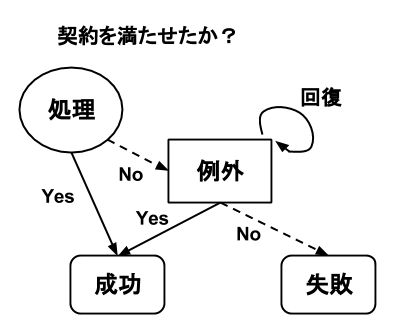
責任不在の失敗
以下の文は筆者による私見です。Meyer氏は『オブジェクト指向入門』ではIO操作に対する契約について言及していません。
最後に、契約の概念の限界性について述べます。契約の考えに則れば、あらゆる失敗は処理の呼び出し側もしくは処理の実装側の責任でした。責任がどちらか一方に定まるという性質が契約の大原則でした。
ここで、受け取ったパスからファイルの内容を読み取るfile_read関数を考えてみましょう。そして、そのfile_read関数の事前条件を考えます。どのような事前条件が書けるでしょう。
file_readはファイルパスを受け取るので、その受け取ったファイルパスにファイルが存在するかどうかというものを事前条件として考えられそうです。ひとまずis_exist関数の存在を仮定すれば、file_read関数は以下のようになります。
# 事前条件: is_exist(path)
def file_read(path)
...
end
つまり、file_read関数は、受け取ったパスにファイルが存在している場合は常に成功します。そう、こんなことはありえません。我々はどこで道を間違えたのでしょうか。
全ての処理は大きく2種類に分けることができます。契約を満たせば必ず成功するもの。そして、契約を満たしていてもときおり失敗するものです。これは信頼性の問題です。厳密に言えば全ての処理は後者です。つまり、全ての処理は契約を満たしていても常に成功するとは限りません。
整数同士を足し合わせるadd関数があるとします。これは整数を受け取る限り、常に成功しそうです。しかし、実際の処理を行うCPUが壊れていれば失敗します。要件にもよりますが、大抵の場合はCPUの誤作動は想定しません。これも正しさ条件の1つです。プログラム全体の事前条件として、CPUは正しく動くという暗黙の条件があるのです。
ではファイルAPIはどうでしょう。同じことで、HDDが不調かもしれません。OSの割り込みによるタイミングの問題で失敗するかもしれません。ファイル操作はCPUよりも不安定なので、大抵の場合はプログラム全体の事前条件として受け入れることはできません。ファイル、DB、HTTP通信等は一般に信頼性が低く、事前条件を満たしても成功するとは限りません。
ここで、無理やり契約の考えを貫いてみましょう。file_read関数を適切に呼び出した場合、つまり事前条件をみたすように呼び出した場合、呼び出し側の義務は終了です。では、その上でfile_read関数が失敗すれば実装側の問題なのでしょうか。しかし、契約とは正しさです。正しくない動作とは、つまるところバグです。
事前条件違反は顧客側(筆者注:この記事で言う呼び出し側)にバグがある証拠である。
事後条件違反は供給者側(筆者注:この記事で言う実装側)にバグがある証拠である。 [1]
では、file_read関数の失敗は実装者によるバグなのでしょうか。仮にバグだとしてもどうしようもありません。何故ならそのバグは取り除けないからです。どのように慎重に実装を行ったとしても、file_read関数の信頼性を他の処理、例えばスタック操作と同程度にまで引き上げるのは困難です。
file_read関数の存在、もっと一般に、IO操作は契約の概念が適用できません。何故なら、契約を満たしても失敗する可能性があるからです。そして、その失敗は誰の責任でもありません。ただ、運が悪かっただけです。もう一度試してみれば上手くいくかもしれません。
注釈
*1: この3組、及び3組を用いたプログラムの正しさについての研究をTony Hoarが行ったことから、3組をホーア・トリプルと呼ばれ、以下のように書き表します。
{P} C {Q}
Pはprecondition、Qはpostcondition、Cはcommandの意味です。
また、単純なホーア・トリプルではプログラムCの正しさを完全に表現することはできません。何故なら、Cが停止しない可能性があるためです。そのため、単純なホーア・トリプルはプログラムの部分的な正しさしか表現できません。
PやQの停止性については、ここでは考えません。
*2: ここでは自然数を0以上の整数としています。
*3: ここではいくつかの条件を省略しています。本来は{P} C {Q}においてCに副作用を認める限り、P, Qはプログラム上のあらゆる作用を記述する必要があります。また、PやQの内部で別の処理を呼び出す事の正しさについてもここでは無視しています。しかし、この記事の本質はプログラムの正しさを検討することではありません。ここでの正しさは例外を考える程度のものでよいので、厳密な意味での正しさは扱いません。
*4: Meyer氏は著書『オブジェクト指向入門』にて契約による設計を提唱しました。そのため、彼の説明はオブジェクト指向プログラミングに依存しています。しかし、現代的なプログラミング言語であればデータに対する何らかの抽象化機構が提供されているはずです。例えばMLに由来する多くの関数型言語はモジュールによってデータと操作の一体化が可能です。ここで言うオブジェクトとは抽象データ型(ADT: Abstract Data Type)を実現する1手法程度の意味に過ぎません。
参考文献
[1]: 『オブジェクト指向入門 第2版 原則・コンセプト』 Bertrand Meyre, 翔泳社 2007