サポートベクターマシン
サポートベクターマシンはマージン最大化分類器、サポートベクター分類器、SVMの総称である(他のサイトを見ると総称してSVMと読むと書かれていることが多いが参考文献の定義に則る)。
マージン最大化分類器は単純で直感的な分類器で線形分離が可能なクラスに対してしか適用できないといった弱点がある。サポートベクター分類器はマージン最大化分類器の弱点を克服し、より多くのクラスに適用したものである。またSVMはこれをさらに拡張し非線型分離も可能にしたものである。
本記事ではまずサポートベクターマシンの説明に欠かせない超平面を定義したのちにマージン最大化分類器、サポートベクター分類器、SVMの順に説明する。
超平面
超平面とはp次元空間におけるp-1次元の平坦な部分空間である。
p次元空間における超平面を数式で書くと$$\beta_0+\beta_1X_1+\beta_2X_2+\cdots+\beta_pX_p = 0$$である。p次元空間上の点$\bf{X}$$=(X_1, X_2, \cdots,X_p)^T$が上記の式を満たすとき$\bf X$は超平面上にあると言え、超平面は空間を二つに分けるものであることが式から分かる。つまり$\beta_0+\beta_1X_1+\beta_2X_2+\cdots+\beta_pX_p$の正負によって$\bf X$が超平面のどちら側にあるか調べることができる。
データが二つのクラスに分けられ、線形分離可能な場合ある超平面によりデータを分けることが可能であることは先の説明より自明である。だが、一般的にはこの超平面は無数に存在する。というのもある分離超平面を僅かに上下に移動したり、回転させた超平面もまた分離超平面であるからである。(分離超平面はデータを分けり超平面)
マージン最大化分類器
理にかなった分離超平面を決めるものの一つとしてマージン最大化超平面(データから最も遠くなるような分離超平面)がある。マージン最大化分類器とはマージン最大化超平面でデータを分類することである。マージンとは任意の分離超平面と各データとのユークリッド距離(以後距離と言う)の最小値である。またデータがマージンの内側にあることをマージン違反と言う。マージン最大化超平面を選ぶ理由としては訓練データにおいて大きなマージンを持つものはテストデータにおいけるマージンも大きいと期待され、より正確に分類できるからである。なお、次元が大きいほど過学習を起こしやすい(次元の呪い)。マージン最大化超平面の係数を$\beta_0,\beta_1,\cdots,\beta_p$とするとマージン最大化分類器は$f(x^\ast)=\beta_0+\beta_1 x^\ast_1+\beta_2 x^\ast_2+\cdots+\beta_p x^\ast_p$の符号に基づいて、データを分類する。
次にマージン最大化超平面を求める方法について述べる。訓練データは次のようなn個のデータの集合$x^1,x^2,\cdots,x^n\in\mathbb{R}$とそのラベルを$y_1,y_2,\cdots,y_n\in \lbrace-1,1\rbrace$とする。これに次のような最適化問題を解くことで求めることができる。
$$
\begin{eqnarray*}
\max_{\beta_0,\beta_1,\cdots,\beta_p} M(\text{マージン})\
\text{s.t}\quad \sum^p_{j=1}\beta_j^2=1,\
y_i(\beta_0+\beta_0x^i_1+\cdots+\beta_px^i_p)\ge M\quad\forall i=1,2,\cdots,n
\end{eqnarray*}
$$
第二式、第三式は適切な側にデータが存在し、超平面との距離がマージン以上でなければいけないという制約を課している。マージンの定義から右辺はMではなく0以上で良いのだが余裕を持たせるためにMにしてある。第三式だけで適切な側にデータがあるかどうかの判別は可能だが超平面との距離がマージン以上であるかどうかはわからない。そのため二式目を課すことで下の点と直線の公式(ここでは直線ではなく超平面であるが)$$d=\frac{\beta_0+\beta_1x_1+\cdots+\beta_px_p}{\sqrt{\beta_0^2+\beta_1^2+\cdots+\beta_p^2}}$$
の分母が1となり第三式の左辺が点と超平面の距離となるようにした。これにより超平面との距離がマージン以上であることを満たす。
三つの点と分離超平面の距離が等しくそれがマージンとなっているとき、この点のうちどれかがより内側に移動するとマージン最大化超平面は大きく異なるものとなる。つまり三つの点が分離超平面を支えており、これらの点はサポートベクターと呼ばれる。さらに他の点はマージンの内側に移動しない限り分離超平面を決めるにあたって全く関与していない。これはサポートベクターマシンにおける重要な性質である。
サポートベクター分類器
マージン最大化分類器では全ての訓練データを分類する必要があるので一つでも外れ値があるときはないときと比べてマージン最大化超平面が著しく異なる。また、外れ値のせいで線形分離不能となることがある。外れ値によって変更された分割超平面はマージンが小さくなることがよくある。先にも述べた通りマージンが小さくなるほどその分離超平面の信頼度が下がる。
これらを解決するためにわずかなデータの誤分類を許容した多くのデータを分類できるを作る分類器を考える。つまりサポートベクター分類器を考える。サポートベクター分類器は以下の最適化問題を解くことで超平面を求める。
$$
\begin{eqnarray*}
\max_{\beta_0,\beta_1,\cdots,\beta_p,\epsilon_1,\epsilon_2,\cdots,\epsilon_n}M \
\text{s.t}\quad \sum^p_{j=1}\beta_j^2=1,\
y_i(\beta_0+\beta_1x^i_1+\beta_2x^i_2+\cdots+\beta_px^i_p)\ge M(1-\epsilon_i),\
\epsilon_i\ge 0,\sum^n_{i=1}\epsilon_i\le C
\end{eqnarray*}
$$
Mはマージン、Cは正負のチューニングパラメータである。$\epsilon_i$はi番目のデータが誤った位置(マージン違反も含む)にあることを許容するスラック変数である。これらの定数及び変数についてさらに説明する。まずスラック変数$\epsilon_i$についてである。これはi番目のデータが超平面やマージンのどちら側にあるか示すものである。i番目のデータが正しい位置にある時$\epsilon_i=0$、マージンの内側にある時$\epsilon_i>0$、さらに超平面の誤った側にあるときは$\epsilon_i>1$となる変数である。次にチューニングパラメーターCについて述べる。Cは$\epsilon$の和を制限している。これによって誤った位置にあるデータ数の許容具合を決めることができる。$C=0$の時マージン最大化分類器と同様の分類器になる。 $C>0$の時C個のデータが誤った位置にあることを許容する分類器になる(スラック変数が誤った位置にあるとき1を超えることから言える)。CはCが小さいときはバイアスが小さくなり分散が大きくなる、Cが大きいときはバイアスが大きくなり分散が小さくなるのでバイアスと分散のトレードオフを調整している。マージン最大化分類器ではデータと分離超平面との距離がマージンに等しいデータ(以下マージン上のデータと言う)のみがマージン最大化超平面を決めるのに関与していた。それと同様にサポートベクター分類器ではマージン上のデータと違反しているデータのみが関与している。つまり、マージンの正しい側にあるデータはサポートベクター分類器に影響を与えない(マージン上のデータは除く)。
SVM
次にこれまで紹介した二つの分類器には分類できないクラスの境界が非線形であるケースについて考える。線形回帰などでこのようなケースを考える時は次数を増やして考えるので同様にサポートベクター分類器でも次数を増やして考えてみる。まず簡単なケースとして2次の項を増やして考える。その時の最適化条件は以下の通りである。
$$
\max_{\beta_0,\beta_{1,1},\beta_{1,2},\beta_{2,1},\cdots,\beta_{p,1},\beta_{p,2},\epsilon_1,\cdots,\epsilon_n}M\
\text{s.t}\quad y_i(\beta_0+\sum^p_{j=1}\beta_{j,1}x_i^j+\sum^p_{j=1}\beta_{j,1}x_i^{j^2})\ge M(1-\epsilon_i),\
\sum^n_{i=1}\epsilon_i\le C,\epsilon_i\ge 0, \sum^p_{j=1}\sum^2_{k=1}\beta_{j,k}^2=1
$$
更に高い次元の多項式や$x_ix_j$のような相互作用項を考えることができるが、数を多くすればするほど計算量が大きくなり扱いきれなくなる。これを解決したのがSVMである。SVMはサポートベクター分類器にカーネル法を取り入れたものである。
カーネル法とは誤解を恐れずに言うと与えられたデータの次元を写像によってさらに高次元に分解する方法である。まず次元を増やすことによって線形分離できるようになる例を見せる。

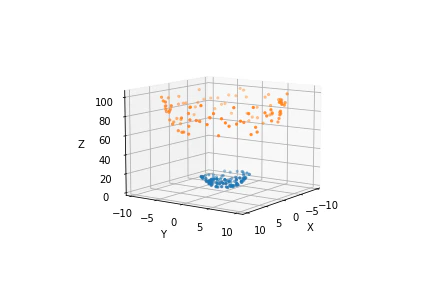
左の図は特徴量がX,Yの二つで線形分不能なデータであるが、右の図のように新たにX,Yの写像であるZ($x^2+y^2$)を第三の特徴料として追加することで線形分離可能になる。このように既存の特徴量の組み合わせを特徴量として新たに加えることによって線形分離不能だったものが可能になることがある。先程の例の場合はグラフを見ると原点からの距離によって分離できることが明らかにわかるが、ほとんどのデータではこのように自明に分離するすることができる組み合わせを発見することは難しい。だが、カーネル法ではこの問題に悩まずに済む。まず、カーネル法の具体的な説明の前に新たな特徴量を用いた分離超平面の計算方法について説明する。データの生の特徴量を$$\boldsymbol{X}=x_1,x_2,\cdots,x_p$$とし、これらの特徴量を組み合わせることによってできた新たな特徴量を$$\boldsymbol{\phi}=\phi_1(\boldsymbol{X}),\phi_2(\boldsymbol{X}),\cdots,\phi_q(\boldsymbol{X})$$と書くこととする。そしてこれまで$\boldsymbol{X}$で計算していた部分を$\boldsymbol{\phi}$に置き換えることで新たな特徴量を用いた計算できる。この方法では新たな特徴量の総数qが大きい場合計算量が非常に大きくなり計算が困難である。これを解決するのがカーネルトリックである。SVMにおけるカーネルトリックとはカーネル関数$K(X,Y)$を用いた次の式を解とする解法である。
$$
f(\boldsymbol{X})=\beta_0+\sum_{n=1}^N \alpha_nK(\boldsymbol{X}, \boldsymbol{X}^n)$$
$\boldsymbol{X}$は新たなデータ。$\alpha$は双対問題によって決められる(双対問題について話すと長くなりすぎるので省略する。詳しくはここ)。カーネル関数は特徴量を用いて次のように書ける。
$$
K(\boldsymbol{X},\boldsymbol{Y})=\sum_{i=1}^q\phi_i(\boldsymbol{X}) \phi_i(\boldsymbol{Y})
$$
これはデータ同士の内積である。つまり、カーネル関数は異なるデータの類似度を表していると考えられる(データの絶対値が1であればcos類似度であることから予想できる)。また、$\phi$が$\boldsymbol{X}$のときはサポートベクター分類器で得られる解を計算できる。つまりサポートベクター分類器で作成できる分離超平面は$$f(\boldsymbol{X})=\beta_0+\sum_{n=1}^N \alpha_n\sum_{i=1}^p x_ix^n_i
$$
と書ける。生の特徴量ではこれで計算できるが、新たな特徴量では次元数がとても大きいことなど様々な要因から同様に計算することが難しい。そのため次のようにカーネル関数を与えることで、特徴量を具体的に与えずに低い計算量で計算することができる(適当な$\phi_i$でカーネル関数を表すことが可能である必要がある)。ここではSVMで使われる代表的なカーネル関数を紹介する。
多項式カーネル
$$
K(\boldsymbol{X},\boldsymbol{Y})=(1+\sum_{i=1}^p\boldsymbol{X}_i\boldsymbol{Y}_i)^d
$$
動径基底カーネル
$$
K(\boldsymbol{X},\boldsymbol{Y})=\exp(-\gamma\sum_{i=1}^p(\boldsymbol{X}_i-\boldsymbol{Y}_i)^2)
$$
計算の簡単な動径基底カーネルの特徴量について考える。
まず以下のようにカーネル関数を変形する($\boldsymbol{X},\boldsymbol{Y}$のように太字にするとバグるので$X,Y$と書く)。
$$
K(X,Y)=\exp(-\gamma\sum_{i=1}^p(X_i-Y_i)^2)\
=\prod_{i=1}^p\exp(-\gamma(X_i-Y_i)^2)
$$
次に特徴量数が非常に大きいとし、総和から積分の形式に変形させる。
$$
K(X,Y) = \sum_{j=1}^q\phi_j(X)\phi_j(Y)=\int\phi_r(X)\phi_r(Y)dr
$$
また、$\phi_r(X)=C\exp(-2\gamma\sum_{i=1}^p(X_i-r)^2)$の形でかけると仮定し、先程の式に代入して変形すると
$$
K(X,Y) = C^2\int\exp(-2\gamma\sum_{i=1}^p(X_i-r)^2)\exp(-2\gamma\sum_{j=1}^p(Y_j-r)^2)dr\
=C^2\prod_{i=1}^p\int\exp(-2\gamma(X_i-r)^2)\exp(-2\gamma(Y_i-r)^2)dr\
=C^2\prod_{i=1}^p\int\exp(-2\gamma(r^2-2(X_i+Y_i)r+(X_i^2+Y_i^2))dr\
=C^2\prod_{i=1}^p\exp(-\gamma(X_i-Y_i)^2)\int\exp(-4\gamma(r-\frac{(X_i+Y_i)}{2})^2dr\
=C^2\prod_{I=1}^p\exp(-\gamma(X_i-Y_i)^2)\sqrt{\frac{\pi}{4\gamma}}\
=C^2\sqrt{\frac{\pi}{4\gamma}}^p\prod_{I=1}^p\exp(-\gamma(X_i-Y_i)^2)\
=\prod_{i=1}^p\exp(-\gamma(X_i-Y_i)^2)
$$
となることより、$C=\sqrt{\frac{4\gamma}{\pi}}^\frac{p}{2}$を代入した$\phi_r(X)=C\prod_{i=1}^p\exp(-2\gamma(X_i-r)^2)$が特徴量であることがわかる。また、動径基底カーネルは無限個の特徴量の組み合わせによって表されるカーネルであることがわかる。
脱線したが以上のカーネルを使用した計算方法で分割超平面を作成することができ、この分類法をSVMと言う。
参考文献
Rによる統計的学習入門