Andrej Karpathy 氏のブログ記事
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
の翻訳です。
翻訳の誤りなどあればご指摘お待ちしております。
リカレントニューラルネットワークには何か魔法のようなところがあります。画像説明(Image Captioning)のために初めてリカレントニューラルネットワークの訓練をした時のことを、私はまだ覚えています。わずか数十分間の訓練で、最初のベイビーモデル(適当に選んだハイパーパラメータを持つ)は、意味を成すのかどうかという画像について、すばらしい説明を生み出し始めました。モデルの単純さの割に結果の品質は、時に、それまでの予想を打ち砕きますが、これがその時でした。当時この結果がとても衝撃的だったのは、一般的に RNN は訓練することが難しいと思われていたためでした(より多くの経験により、私は逆の結論に達しました)。ほぼ1年早送りして:私は常に RNN を訓練し続け、何度もその力と丈夫さを目の当たりにしてきましたが、その魔法のようなアウトプットはいまだに私を面白がらせます。この記事では、その魔法の一部を共有します。
文字単位でテキストを生成する RNN を訓練し、「どうしてそれが可能か?」という疑問について考えてみる。
ところで、この記事と一緒に、多層 LSTM に基づく文字レベルの言語モデルを訓練可能な GitHub 上のコード を公開しています。テキストの大きなかたまりを与えると、似たようなテキストを一度に1文字ずつ生成することを学習します。また、以下の実験を再現するために使用することもできます。でも、先走りはやめましょう。RNN とは一体なんでしょうか?
リカレントニューラルネットワーク
シーケンス。あなたのバックグラウンドによっては、疑問に思われるかもしれません:何がリカレントネットワークをそこまで特別にするのか?普通のニューラルネットワーク(およびたたみ込みネットワーク)の目立つ制限は、その API が制約されすぎてきる、ということです。これらは、固定サイズのベクトル(例えば、1つの画像)を入力として受け取り、固定サイズのベクトル(例えば、さまざまなクラスの確率)を出力として生成します。それだけではありません。これらのモデルは、一定量の計算ステップ(例えば、モデルの層の数)により、このマッピングを行います。リカレントネットがよりエキサイティングである主な理由は、ベクトルのシーケンス上で動作可能という点にあります。入力シーケンス、出力シーケンス、一般にはその両方です。いくつかの例によって、これをより具体的にします。
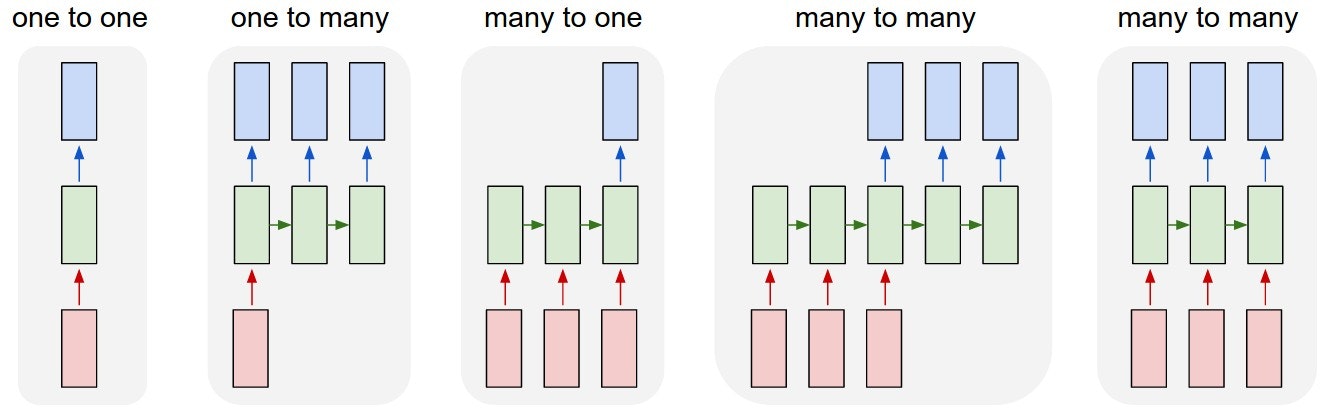
各矩形はベクトル、矢印は関数(例えば、行列の乗算)を表す。入力ベクトルは赤、出力ベクトルは青、緑のベクトルは RNN の状態(詳細はすぐに説明)を保持。左から右へ:(1) RNNなしで処理するバニラ・モード、固定サイズの入力から固定サイズの出力へ(例:画像分類)。(2) シーケンス出力(例:画像説明。1つの画像を取り、言葉の文を出力)。(3) シーケンス入力(例:感情分析。与えられた文を、ポジティブまたはネガティブな感情表現に分類)。(4) シーケンス入力とシーケンス出力(例:機械翻訳。RNN は英語の文を読んでフランス語の文を出力)。(5) 同期されたシーケンス入出力(例:ビデオ分類。ビデオの各フレームにラベル付け)。リカレント変換(緑)は固定されており、好きなように何回も適用することができるため、すべてのケースで、シーケンスには予め指定された長さの制約がないことに注意。
ご想像のとおり、初めから一定数の計算ステップに制限されている固定ネットワークに比べ、演算のシーケンス体制ははるかに強力です。そのため、より賢いシステムの構築を志す者にとっては、魅力的です。また、すぐ後で説明しますが、入力ベクトルと状態ベクトルを固定の(ただし学習された)関数で組み合わせることによって、RNN は新たな状態ベクトルを生成します。これは、プログラミングの観点では、特定の入力といくつかの内部変数を持つ固定のプログラムを実行していると解釈できます。このように見ると、RNN は本質的にはプログラムを表現します。実際、任意のプログラムを(適切な重みで)シミュレートできるという意味で、RNN はチューリング完全であることが知られています。でも、ニューラルネットにおける普遍近似定理と同様、これについてはこれ以上深入りするべきではありません。私が言ったことは忘れてください。
普通のニューラルネットの訓練が関数の最適化であるならば、リカレントネットの訓練はプログラムの最適化である
シーケンス不在下でのシーケンシャル処理。入力や出力がシーケンスであることはあまり無いのではないか、と考えるかもしれませんが、理解すべき重要な点は、入出力が固定ベクトルだとしてもシーケンシャルな方法で処理するためにこの強力な形式を利用可能だ、ということです。例えば、下の図は DeepMind の2つのすばらしい論文の結果です。左側は、アルゴリズムが、画像のあちこちに注目点を操作するリカレントネットワーク・ポリシーを学習します。具体的には、ハウス番号を左から右へ読むことを学習します(Ba et al.)。右側は、リカレントネットワークが逐次的にキャンバスに色を加えることを学習し、数字画像を生成します(Gregor et al.)。


左:RNN がハウス番号を読むことを学習。右:RNN がハウス番号を描くことを学習。
留意点は、データがシーケンスの形式でない場合でも、それをシーケンシャルに処理することを学習する強力なモデルを定式化して訓練することができる、ということです。あなたは今、固定サイズのデータを処理するステートフルなプログラムを学んでいます。
RNN 計算。それで、これはどのように作動するのでしょうか?重要な点は、RNN は見かけによらず単純な API を持っている、ということです。RNN は、入力ベクトル $x$ を受け取り、出力ベクトル $y$ を生成します。しかし、この出力ベクトルの内容は、今与えられた入力だけでなく、過去に与えられた入力の全履歴に、かなり影響されます。クラスとして書かれた場合、RNN の API は単一の $step$ 関数から成ります。
rnn = RNN()
y = rnn.step(x) # x is an input vector, y is the RNN's output vector
RNN クラスは、$step$ が呼ばれるたびに更新される、いくつかの内部状態を持ちます。最も単純な場合、この状態は1つの隠れベクトル $h$ から成ります。単純な RNN のステップ関数の実装は以下の通りです:
class RNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y
上記は、普通の RNN の前進パスの仕様を決めます。そのための RNN のパラメータは、3つの行列 $W_{hh}, W_{xh}, W_{hy}$ です。隠れ状態 $self.h$ は、ゼロベクトルで初期化されます。$np.tanh$ 関数はアクティベーションを $[-1, 1]$ の範囲に押しつぶす、非線形性を実現します。どのように作用するのか簡単に述べると:tanh 内に2つの項があります:一方は前の隠れ状態に基づき、他方は現在の入力に基づきます。numpy の $np.dot$ は行列の掛け算です。2つの中間項は加算され、tanh により新たな状態ベクトルに押しつぶされます。数学の表記に慣れているなら、隠れ状態の更新は以下のように記述可能です。$h_t = \tanh ( W_{hh} h_{t-1} + W_{xh} x_t )$ 、ここで tanh は要素ごとに適用されます。
RNN の行列を乱数で初期化します。そして、入力シーケンス $x$ に対しどのような種類の出力 $y$ を得たいか、という選択を表現する何らかの損失関数で測られる、望ましい振る舞いを引き起こす行列を見つけることに、訓練中の作業の大半は費やされます。
ディープに進みます。RNN はニューラルネットワークであり、あなたがディープラーニングの帽子をかぶってパンケーキのようにモデルを積み上げていけば、すべては単調によりよく機能します(正しくなされれば)。例えば、以下のように、2層のリカレントネットワークを作ることができます:
y1 = rnn1.step(x)
y = rnn2.step(y1)
言い換えると、2つの別々の RNN があります:一方の RNN は入力ベクトルを受け取り、第2の RNN は入力として最初の RNN の出力を受け取ります。ただし、これらの RNN のどちらも、バックプロパゲーション中、入出力がすべて適切なベクトルであるかどうかや、各モジュールを流れる勾配について、知らないし気にしません。
ゲッティング・ファンシー。実用上ほとんどの場合、長短期記憶(LSTM)と呼ばれる、上で提示したものとはやや異なる定式化が使われる、と簡潔に述べておきます。LSTM は特定の種類のリカレントネットワークで、より強力な更新式といくつかの魅力的なバックプロパゲーション・ダイナミクスにより、実用上ややうまく機能します。詳細には触れませんが、更新を計算する数式( self.h = の行)がやや複雑になることを除いて、これまで RNN について語ってきたことすべてがまったく同じく通用します。これからは、「RNN/LSTM」という用語を置き換え可能なものとして使用しますが、この記事の実験はすべて LSTM を使用しています。
文字レベル言語モデル
さて、RNN が何なのか、なぜ超エキサイティングなのか、どのように作動するのか、について見てきました。ここでは、RNN に面白いアプリケーションを教えましょう:RNN 文字レベル言語モデルを訓練します。つまり、RNN に巨大なテキストのかたまりを与え、前の文字シーケンスが与えられたときの、次の文字の確率分布をモデル化させてみましょう。これにより、新たなテキストを1文字ずつ生成することができます。
例として、4つの文字「helo」だけを含む語彙があり、訓練シーケンス「hello」で RNN を訓練すると思ってください。訓練シーケンスは実際には4つの別々の訓練例です、すなわち、1. 文脈「h」が与えられた場合の「e」の確率、2. 文脈「he」における「l」の確率、3. 文脈「hel」が与えられた場合の「l」の確率、4. 文脈「hell」が与えられた場合の「o」の確率、です。
具体的には、各文字を 1-of-k エンコーディング(すなわち、語彙におけるその文字のインデックスの位置でのみ1、それ以外はゼロ)によりベクトルにエンコードし、$step$ 関数により、一度に1つずつ RNN に入力します。その後、4次元の出力ベクトル(1文字につき1次元)が得られ、これを、RNN によって各文字に与えられた、シーケンス内で次にその文字が来る確信度、と解釈します。以下に図を示します:
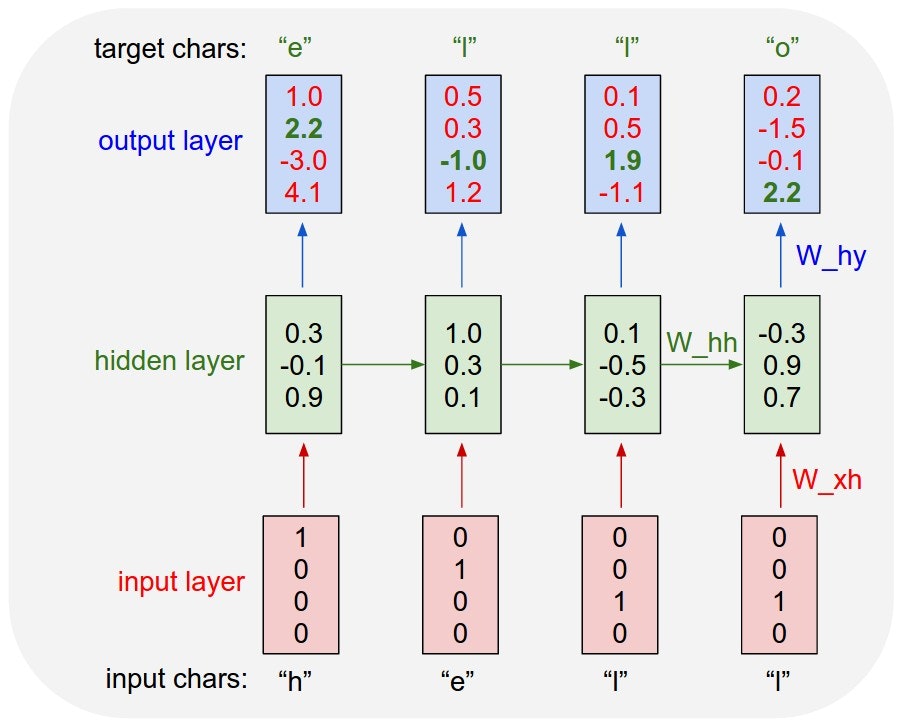
4次元の入出力層と3ユニット(ニューロン)の隠れ層を持つ RNN の例。この図は、RNN に入力として文字列「hell」が入れられたときの、前進パスにおける活性化を示している。出力層には、RNN が次の文字(語彙は「h, e, l, o」)に与える確信度が含まれる。緑色の数字を高く、赤い数字を低くしたい。
例えば、最初の時間ステップに文字「h」を見て、RNN は次の文字が「h」であることに確信度 1.0、「e」に 2.2、「l」に -3.0、「o」に 4.1 を与えます。訓練データ(文字列「hello」)において次の正しい文字は「e」なので、その確信度(緑色)を増やし、他の文字の確信度(赤色)を減らしたいです。同様に、4つの時間ステップのそれぞれにおいて、ネットワークに強い確信度を与えて欲しい、所望する目的文字があります。RNN は全て微分可能な演算で構成されているので、正しい目的のスコア(緑色のボールド数字)を増加させるためにそれぞれの重みをどの方向に調整すべきかを計算するための、バックプロパゲーション・アルゴリズム(これは微分のチェイン・ルールの再帰的な適用)を実行することができます。それから、すべての重みをこの勾配の方向にわずかに動かす、パラメータ更新を実行することができます。パラメータ更新後に RNN に同じ入力を入れると、正しい文字(例えば、最初の時間ステップにおける「e」)のスコアがやや高く(例えば、2.2 から 2.3 へ)、間違った文字のスコアがやや低くなることがわかります。その後、ネットワークが収束するまで何度もこのプロセスを繰り返すことにより、最終的には、正しい文字が常に次に予測されるという点で、予測は訓練データと一致します。
より技術的に説明すると、標準的なソフトマックス分類器(一般的に、交差エントロピー損失とも呼ばれる)をすべての出力ベクトルに同時に使用します。RNN はミニバッチ勾配降下により訓練します。更新を安定させるために、RMSProp や Adam(パラメータ毎の学習率適応法)を私は良く使います。
また、最初に文字「l」が入力されたときには対象は「l」で、2度目には対象は「o」であることに注意してください。RNN は、従って、単独の入力に依存しているのではなく、このタスクを達成するために文脈を追跡する目的で、リカレント結合を使用しています。
テスト時には、RNN に文字を入れて、次に来そうな文字の分布を得ます。この分布からサンプリングし、次の文字を得るためにすぐにそれを再び入力します。このプロセスを繰り返すことによって、テキストをサンプリングできます!次に、RNN を異なるデータセットで訓練し、何が起こるか見てみましょう。
さらに明確にするために、教育目的で、Python/numpy による最小の文字レベル RNN 言語モデルを作成しました。それはたった 100 行ほどの長さです。そして、うまくいけば、文章よりコードを読む方が得意な方であれば、上記の簡潔で具体的かつ有益なまとめが得られます。次に、より効率的な Lua/Torch コードベースで作成された結果例に移りましょう。
楽しいRNN
以下の5つの文字モデルの例はすべて、GitHub で公開しているコードで訓練しました。各ケースの入力は何らかのテキストを含む単一のファイルで、シーケンスにおける次の文字を予測するように RNN を訓練しています。
ポール・グレアム生成器
最初に動作確認として英語の小さなデータセットを試してみましょう。私のお気に入りの楽しいデータセットはポール・グレアムのエッセイを連結したものです。基本的なアイデアは、これらのエッセイには知恵がたくさん詰まっているということですが、残念ながらポール・グレアムは比較的遅筆です。オンデマンドでスタートアップの知恵をサンプリングすることができたら、すばらしいですよね?RNN の出番です。
最近5年間くらいのポール・グレアムのエッセイをすべて連結すると、およそ 1MB のテキストファイル、およそ 100 万文字が得られます(ところで、これはとても小さなデータセットと見なされます)。テクニカル:512 の隠れノード(およそ350万のパラメータ)を持ち、各層の後に 0.5 のドロップアウトを持つ2層の LSTM を訓練してみましょう。100 例のバッチと長さ 100 文字に切り詰めたバックプロパゲーション・スルー・タイムにより訓練します。このような設定で、TITAN Z GPU で、1つのバッチに約 0.46 秒かかります(これは、パフォーマンスにおいて無視できる程度のコストで、50 文字の BPTT により、半分にカットすることができます)。面倒な話はこれくらいにして、RNN からのサンプルを見てみましょう:
「The surprised in investors weren’t going to raise money. I’m not the company with the time there are all interesting quickly, don’t have to get off the same programmers. There’s a super-angel round fundraising, why do you can do. If you have a different physical investment are become in people who reduced in a startup with the way to argument the acquirer could see them just that you’re also the founders will part of users’ affords that and an alternation to the idea. [2] Don’t work at first member to see the way kids will seem in advance of a bad successful startup. And if you have to act the big company too.」
さて、明らかに、上記は残念ながらすぐにはポール・グレアムの代わりにはなりません。しかし、RNN が小さなデータセットによりスクラッチから完全に英語を(コンマ、アポストロフィ、空白の位置も含めて)学習したことを思い出してください。私はまた、自身の引数(例えば、上記の [2] )をサポートすることを学習するところが好きです。時にはそれは、「a company is a meeting to think to investors(会社とは投資家に考えるための会議である)」のように、洞察の煌めきを提供するようなことを言います。もっと見たければ、ここに5万文字のサンプルへのリンクがあります。
温度。また、サンプリング中にソフトマックスの温度をいじることができます。温度を 1 からいくらか低い数値(例えば 0.5 )に下げることにより、RNN は確信的になりますが、そのサンプルに保守的になります。逆に、高い温度は、多くのミス(例えば、スペルミスなど)をするコストで、多くの多様性を与えます。特に、ゼロにとても近い温度に設定すると、ポール・グレアムは以下のように言うかもしれません:
「is that they were all the same thing that was a startup is that they were all the same thing that was a startup is that they were all the same thing that was a startup is that they were all the same」
スタートアップについての無限ループに達したようです。
シェイクスピア
英単語をつづることを学習することができそうです。でも、より多くの構造や文体がデータにある場合にはどうでしょうか?これを調べるために、私はシェイクスピアのすべての作品をダウンロードして、一つの(4.4MB)ファイルにそれらを連結しました。私たちは今ではより大きなネットワークを訓練することができます。ここでは、それぞれ 512 の隠れノードを持つ3層の RNN にトライしてみましょう。ネットワークを数時間訓練すると、以下のようなサンプルが得られます:
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain'd into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.
DUKE VINCENTIO:
Well, your wit is in the care of side and that.
Second Lord:
They would be ruled after this chamber, and
my fair nues begun out of the fact, to be conveyed,
Whose noble souls I'll have the heart of the wars.
Clown:
Come, sir, I will make did behold your worship.
VIOLA:
I'll drink it.
RNN が知っているのは文字だけだ、ということを思い出してください。しかし、話者の名前と内容がサンプルされています。時には、以下のような、比較的長いモノローグの一節が得られます:
VIOLA:
Why, Salisbury must find his flesh and thought
That which I am not aps, not a man and in fire,
To show the reining of the raven and the wars
To grace my hand reproach within, and not a fair are hand,
That Caesar and my goodly father's world;
When I was heaven of presence and our fleets,
We spare with hours, but cut thy council I am great,
Murdered and by thy master's ready there
My power to give thee but so much as hell:
Some service in the noble bondman here,
Would show him to her wine.
KING LEAR:
O, if you were a feeble sight, the courtesy of your law,
Your sight and several breath, will wear the gods
With his heads, and my hands are wonder'd at the deeds,
So drop upon your lordship's head, and your opinion
Shall be against your honour.
実際のシェイクスピアからはこれらのサンプルをほとんど認めることができません。:) シェイクスピアが好きなら、この 10 万文字のサンプルを見てください。もちろん、提供されたコードにより様々な温度で、独自のサンプルを無限に生成することもできます。
ウィキペディア
LSTM は単語をつづることを学習し、一般的な構文構造をコピーすることができるということがわかりました。さらに難易度を上げ、構造化されたマークダウンを訓練してみましょう。具体的には、ウィキペディアの Hutter Prize の 100MB のデータを取得し、LSTM を訓練しましょう。Graves et al. に従い、はじめの 96MB を訓練に、残りを検証に使用し、いくつかのモデルを一晩実行しました。これでウィキペディアの記事をサンプリングすることができます。以下はいくつかの楽しい抜粋です。まず、いくつかの基本的なマークダウン出力:
Naturalism and decision for the majority of Arab countries' capitalide was grounded
by the Irish language by [[John Clair]], [[An Imperial Japanese Revolt]], associated
with Guangzham's sovereignty. His generals were the powerful ruler of the Portugal
in the [[Protestant Immineners]], which could be said to be directly in Cantonese
Communication, which followed a ceremony and set inspired prison, training. The
emperor travelled back to [[Antioch, Perth, October 25|21]] to note, the Kingdom
of Costa Rica, unsuccessful fashioned the [[Thrales]], [[Cynth's Dajoard]], known
in western [[Scotland]], near Italy to the conquest of India with the conflict.
Copyright was the succession of independence in the slop of Syrian influence that
was a famous German movement based on a more popular servicious, non-doctrinal
and sexual power post. Many governments recognize the military housing of the
[[Civil Liberalization and Infantry Resolution 265 National Party in Hungary]],
that is sympathetic to be to the [[Punjab Resolution]]
(PJS)[http://www.humah.yahoo.com/guardian.
cfm/7754800786d17551963s89.htm Official economics Adjoint for the Nazism, Montgomery
was swear to advance to the resources for those Socialism's rule,
was starting to signing a major tripad of aid exile.]]
気になるかもしれませんが、上記の yahoo の URL は実際には存在しません。モデルが生み出した単なる幻です。また、モデルがカッコの開閉を正しく学習していることに注意してください。さらに、モデルが学習した構造化マークダウンがかなりあります。例えば、時々見出しやリストなどが生成されます:
{ { cite journal | id=Cerling Nonforest Department|format=Newlymeslated|none } }
''www.e-complete''.
'''See also''': [[List of ethical consent processing]]
== See also ==
*[[Iender dome of the ED]]
*[[Anti-autism]]
===[[Religion|Religion]]===
*[[French Writings]]
*[[Maria]]
*[[Revelation]]
*[[Mount Agamul]]
== External links==
* [http://www.biblegateway.nih.gov/entrepre/ Website of the World Festival. The labour of India-county defeats at the Ripper of California Road.]
==External links==
* [http://www.romanology.com/ Constitution of the Netherlands and Hispanic Competition for Bilabial and Commonwealth Industry (Republican Constitution of the Extent of the Netherlands)]
時々、モデルは、ランダムだけど有効な XML を生成するモードにはまり込みます。
<page>
<title>Antichrist</title>
<id>865</id>
<revision>
<id>15900676</id>
<timestamp>2002-08-03T18:14:12Z</timestamp>
<contributor>
<username>Paris</username>
<id>23</id>
</contributor>
<minor />
<comment>Automated conversion</comment>
<text xml:space="preserve">#REDIRECT [[Christianity]]</text>
</revision>
</page>
モデルはタイムスタンプや ID などを完全に作り出します。また、適切に、正しい入れ子になった順序で、正しいタグが閉じられる点に注意してください。さらに見たい場合、ここに 10 万文字のウィキペディアのサンプルがあります。
代数幾何(LaTeX)
上記の結果は、モデルが実際、複雑な構文構造をかなりうまく学習することを示しています。これらの結果に触発され、研究仲間(Justin Johnson)と共に、構造化の領域にさらに分け入ることを決め、この本の代数スタック/幾何を入手しました。生の LaTeX のソースファイル(16MB のファイル)をダウンロードし、多層 LSTM を訓練しました。驚くべきことに、結果としてサンプリングされた LaTeX はほとんどコンパイルできます。調査して2、3の問題を手動で解決しなければなりませんが、もっともらしい見栄えの数学が得られます。実にすばらしい:

サンプリングされた(偽の)代数幾何。実際の pdf はこちら。
別のサンプル:

さらにとりとめもない代数幾何。図(右)はすばらしいトライ。
お分かりのように、時々モデルは LaTeX の図を生成しようとしますが、明らかに実際にはそれを考え出してはいません。私は、証明を省略することを選んでいる部分が好きです(左上の「Proof omitted.」)。もちろん、LaTex は比較的難しい構造化された構文のフォーマットを持っていて、私自身完全にはマスターしていないことを心にとめておいてください。例として、以下にモデルからの生のサンプル(未編集)を示します:
\begin{proof}
We may assume that $\mathcal{I}$ is an abelian sheaf on $\mathcal{C}$.
\item Given a morphism $\Delta : \mathcal{F} \to \mathcal{I}$
is an injective and let $\mathfrak q$ be an abelian sheaf on $X$.
Let $\mathcal{F}$ be a fibered complex. Let $\mathcal{F}$ be a category.
\begin{enumerate}
\item \hyperref[setain-construction-phantom]{Lemma}
\label{lemma-characterize-quasi-finite}
Let $\mathcal{F}$ be an abelian quasi-coherent sheaf on $\mathcal{C}$.
Let $\mathcal{F}$ be a coherent $\mathcal{O}_X$-module. Then
$\mathcal{F}$ is an abelian catenary over $\mathcal{C}$.
\item The following are equivalent
\begin{enumerate}
\item $\mathcal{F}$ is an $\mathcal{O}_X$-module.
\end{lemma}
比較的まともなモデルから得られたこのサンプルは、いくつか共通の間違いをしています。例えば、モデルは、\begin{proof} 環境を開始していますが、 \end{lemma} で終了しています。これは手動で修正しなければならない問題の一例で、おそらく依存性の期間が長過ぎることに起因します:モデルは証明をしていた時に、証明だったか補題だったかを忘れました。同様に、\begin{enumerate} を開始していますが、終了することを忘れています。大きな/より良いモデルではあまり見られませんでしたが、それでもこの種のミスは発生します。
Linux ソースコード
構造化データを限界まで駆り立てたかったので、最後のチャレンジとして、コードを使用することに決めました。具体的には、Github 上の Linux リポジトリの全ソースファイルとヘッダーファイルを取得し、単一の巨大なファイル(474MB の C のコード)に連結しました。(元々はカーネルのみを訓練するつもりでしたが、それ自体はたった 16MB ほどでした)。そして、私の GPU にフィットする大きさの3層 LSTM を数日間訓練しました。これらのモデルはおよそ1千万のパラメータを持ちますが、それでも RNN モデルとしては最小限に近いです。結果は超楽しいです:
/*
* Increment the size file of the new incorrect UI_FILTER group information
* of the size generatively.
*/
static int indicate_policy(void)
{
int error;
if (fd == MARN_EPT) {
/*
* The kernel blank will coeld it to userspace.
*/
if (ss->segment < mem_total)
unblock_graph_and_set_blocked();
else
ret = 1;
goto bail;
}
segaddr = in_SB(in.addr);
selector = seg / 16;
setup_works = true;
for (i = 0; i < blocks; i++) {
seq = buf[i++];
bpf = bd->bd.next + i * search;
if (fd) {
current = blocked;
}
}
rw->name = "Getjbbregs";
bprm_self_clearl(&iv->version);
regs->new = blocks[(BPF_STATS << info->historidac)] | PFMR_CLOBATHINC_SECONDS << 12;
return segtable;
}
全体的に、コードは本当にかなりすばらしく見えます。もちろん、それがコンパイル可能だとは思えませんが、生成されたコードをスクロールすると、巨大な C のコードベースにとても良く似ていると感じられるでしょう。RNN がランダムにコードのあちこちにコメントを付けることに注意してください。また、構文エラーがかなり少ないという点で、とても上手です。例えば、文字列やポインタ記法などを正しく使用しています。また、カッコ {[ の開閉が正しく行われ、コードをとても上手にインデントすることを学習しています。共通のエラーは、変数名を追跡できないところです:しばしば未定義の変数(例えば、上記の $rw$)を使用し、一度も使用されない変数(例えば、$int \quad error$)を宣言し、存在しない変数をリターンします。さらにいくつかの例を見ましょう。RNN が学習する、より幅広い操作を示す、別の断片を以下に示します:
/*
* If this error is set, we will need anything right after that BSD.
*/
static void action_new_function(struct s_stat_info *wb)
{
unsigned long flags;
int lel_idx_bit = e->edd, *sys & ~((unsigned long) *FIRST_COMPAT);
buf[0] = 0xFFFFFFFF & (bit << 4);
min(inc, slist->bytes);
printk(KERN_WARNING "Memory allocated %02x/%02x, "
"original MLL instead\n"),
min(min(multi_run - s->len, max) * num_data_in),
frame_pos, sz + first_seg);
div_u64_w(val, inb_p);
spin_unlock(&disk->queue_lock);
mutex_unlock(&s->sock->mutex);
mutex_unlock(&func->mutex);
return disassemble(info->pending_bh);
}
static void num_serial_settings(struct tty_struct *tty)
{
if (tty == tty)
disable_single_st_p(dev);
pci_disable_spool(port);
return 0;
}
static void do_command(struct seq_file *m, void *v)
{
int column = 32 << (cmd[2] & 0x80);
if (state)
cmd = (int)(int_state ^ (in_8(&ch->ch_flags) & Cmd) ? 2 : 1);
else
seq = 1;
for (i = 0; i < 16; i++) {
if (k & (1 << 1))
pipe = (in_use & UMXTHREAD_UNCCA) +
((count & 0x00000000fffffff8) & 0x000000f) << 8;
if (count == 0)
sub(pid, ppc_md.kexec_handle, 0x20000000);
pipe_set_bytes(i, 0);
}
/* Free our user pages pointer to place camera if all dash */
subsystem_info = &of_changes[PAGE_SIZE];
rek_controls(offset, idx, &soffset);
/* Now we want to deliberately put it to device */
control_check_polarity(&context, val, 0);
for (i = 0; i < COUNTER; i++)
seq_puts(s, "policy ");
}
2番目の関数でモデルは $tty == tty$ の比較をしていることに注意してください。これは真ですが無意味です。一方、少なくとも変数 $tty$ はこのときスコープ内に存在します!最後の関数で、コードが何も返さないことに注意してください。関数のシグネイチャが $void$ なので、これはたまたま正しいです。でも、初めの2つの関数は $void$ として宣言され、値を返しています。これもまた、長期の相互作用による一般的なミスの一形態です。
時々モデルは、新たなファイルをサンプリングする時が来たと判断します。これは普通、とても面白い部分です:モデルはまず GNU ライセンスを1文字ずつ列挙し、いくつかのインクルードをサンプルし、いくつかのマクロを生成して、コードに突入します:
/*
* Copyright (c) 2006-2010, Intel Mobile Communications. All rights reserved.
*
* This program is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 as published by
* the Free Software Foundation.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
*
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software Foundation,
* Inc., 675 Mass Ave, Cambridge, MA 02139, USA.
*/
# include <linux/kexec.h>
# include <linux/errno.h>
# include <linux/io.h>
# include <linux/platform_device.h>
# include <linux/multi.h>
# include <linux/ckevent.h>
# include <asm/io.h>
# include <asm/prom.h>
# include <asm/e820.h>
# include <asm/system_info.h>
# include <asm/setew.h>
# include <asm/pgproto.h>
# define REG_PG vesa_slot_addr_pack
# define PFM_NOCOMP AFSR(0, load)
# define STACK_DDR(type) (func)
# define SWAP_ALLOCATE(nr) (e)
# define emulate_sigs() arch_get_unaligned_child()
# define access_rw(TST) asm volatile("movd %%esp, %0, %3" : : "r" (0)); \
if (__type & DO_READ)
static void stat_PC_SEC __read_mostly offsetof(struct seq_argsqueue, \
pC>[1]);
static void
os_prefix(unsigned long sys)
{
# ifdef CONFIG_PREEMPT
PUT_PARAM_RAID(2, sel) = get_state_state();
set_pid_sum((unsigned long)state, current_state_str(),
(unsigned long)-1->lr_full; low;
}
カバーしきれないほど、楽しい部分があります。この部分だけでブログ全体を書くこともできたほどです。ここでは省略しましたが、ここに 1MB のサンプリングされた Linux のコードがありますので、見て楽しんでください。
赤ちゃんの名前生成
もう一つ、楽しいことを試してみましょう。リストアウトされた 8000 の赤ちゃんの名前(ここから得られた名前)を1行に1つずつ含む、巨大なテキストファイルを RNN に入れてみましょう。RNN にこれを入れると、新たな名前を作ることができます!以下にいくつか名前の例を示します。訓練データに含まれないものだけを示しています(90% は含まれません):
Rudi Levette Berice Lussa Hany Mareanne Chrestina Carissy Marylen Hammine Janye Marlise Jacacrie Hendred Romand Charienna Nenotto Ette Dorane Wallen Marly Darine Salina Elvyn Ersia Maralena Minoria Ellia Charmin Antley Nerille Chelon Walmor Evena Jeryly Stachon Charisa Allisa Anatha Cathanie Geetra Alexie Jerin Cassen Herbett Cossie Velen Daurenge Robester Shermond Terisa Licia Roselen Ferine Jayn Lusine Charyanne Sales Sanny Resa Wallon Martine Merus Jelen Candica Wallin Tel Rachene Tarine Ozila Ketia Shanne Arnande Karella Roselina Alessia Chasty Deland Berther Geamar Jackein Mellisand Sagdy Nenc Lessie Rasemy Guen Gavi Milea Anneda Margoris Janin Rodelin Zeanna Elyne Janah Ferzina Susta Pey Castina
ここでもっと見ることが出来ます。私のお気に入りは、「Baby(笑)、Killie、Char、R、More、Mars、Hi、Saddie、With、Ahbort」などです。これは楽しかったです。小説を書く場合や、新たなスタートアップに命名する場合には、極めて有効なインスピレーションになるでしょう。
起こっていることの理解
訓練終了後、すばらしい結果が得られることを見てきましたが、どのように動いているのでしょうか?覆いの下を軽く覗き見するために、2つの手短な実験をしてみましょう。
訓練中のサンプルの進化
まず、モデルの訓練中にサンプリングされたテキストがどのように進化するのか見ることは面白いです。例として、トルストイの『戦争と平和』の LSTM を訓練し、訓練の 100 反復ごとにサンプルを生成しました。 100 反復時点では、モデルはめちゃくちゃにサンプリングします:
tyntd-iafhatawiaoihrdemot lytdws e ,tfti, astai f ogoh eoase rrranbyne 'nhthnee e
plia tklrgd t o idoe ns,smtt h ne etie h,hregtrs nigtike,aoaenns lng
しかし、スペースで区切られた単語の概念を習得し始めていることに注意してください。ただし、たまにスペースを2つ加えています。コンマの後にはほぼスペースが続くことも分かっていません。 300 反復時点で、モデルは引用符とピリオドの概念を習得し始めます:
"Tmont thithey" fomesscerliund
Keushey. Thom here
sheulke, anmerenith ol sivh I lalterthend Bleipile shuwy fil on aseterlome
coaniogennc Phe lism thond hon at. MeiDimorotion in ther thize."
単語はこの時もスペースで区切られていて、また、モデルは文末のピリオドの概念を習得し始めます。 500 反復時点では:
we counter. He stutn co des. His stanted out one ofler that concossions and was
to gearang reay Jotrets and with fre colt otf paitt thin wall. Which das stimn
モデルは最も短く一般的な単語、例えば、「We」「He」「His」「Which」「and」などをつづることを学習しました。 700 反復時点で、さらに英語的なテキストが出始めます:
Aftair fall unsuch that the hall for Prince Velzonski's that me of
her hearly, and behs to so arwage fiving were to it beloge, pavu say falling misfort
how, and Gogition is so overelical and ofter.
1200 反復時点では、引用符と疑問符/感嘆符が見られます。長い単語も学習されました:
"Kite vouch!" he repeated by her
door. "But I would be done and quarts, feeling, then, son is people...."
およそ 2000 反復でついに適切につづられた単語、引用符、名前などが得られ始めます:
"Why do what that day," replied Natasha, and wishing to himself the fact the
princess, Princess Mary was easier, fed in had oftened him.
Pierre aking his soul came to the packs and drove up his father-in-law women.
浮かび上がった絵は、モデルがまず一般的な単語とスペースの構造を発見し、その後急速に単語を学習し始めるということです。短い単語から始まり、最終的にはより長い単語になります。複数の語をまたがるトピックやテーマ(そして、一般には、より長期の依存性)は、もっと後に出始めます。
予測と RNN 内の「ニューロン」の発火の可視化
もう一つの楽しい可視化は、文字について予測された分布を見ることです。以下の可視化では、ウィキペディアの RNN モデルに検証用の文字データ(青/緑色の行で示される)を与え、各文字の下にモデルの次の文字としてのトップ5の推測を(赤字で)可視化しました。推測は、その確率によって色づけされています(暗い赤=とても可能性が高い、白=あまり可能性がない、と判断)。例えば、モデルが次の文字として強く確信している一連の文字があることが分かります(例えば、モデルは http://www. というシーケンスの間、強く確信しています)。
入力文字シーケンス(青/緑色)は、RNN の隠れ表現内の、ランダムに選択されたニューロンの発火に基づいて色づけされています。緑色=とても興奮している、青=あまり興奮していない、だと思ってください(LSTM の詳細に精通している方のために、これは隠れ状態ベクトル、すなわちゲートされて tanh を適用された LSTM のセル状態内の [-1, 1] の間の値です)。直観的には、これは入力シーケンスを読んでいる間の、RNN の「脳」内のいくつかのニューロンの発火率の可視化です。別のニューロンは異なるパターンを探しているかも知れません。以下に、私が見つけ、面白いあるいは解釈可能だと思った(多くはそうではありません)4つの異なるニューロンを示します:
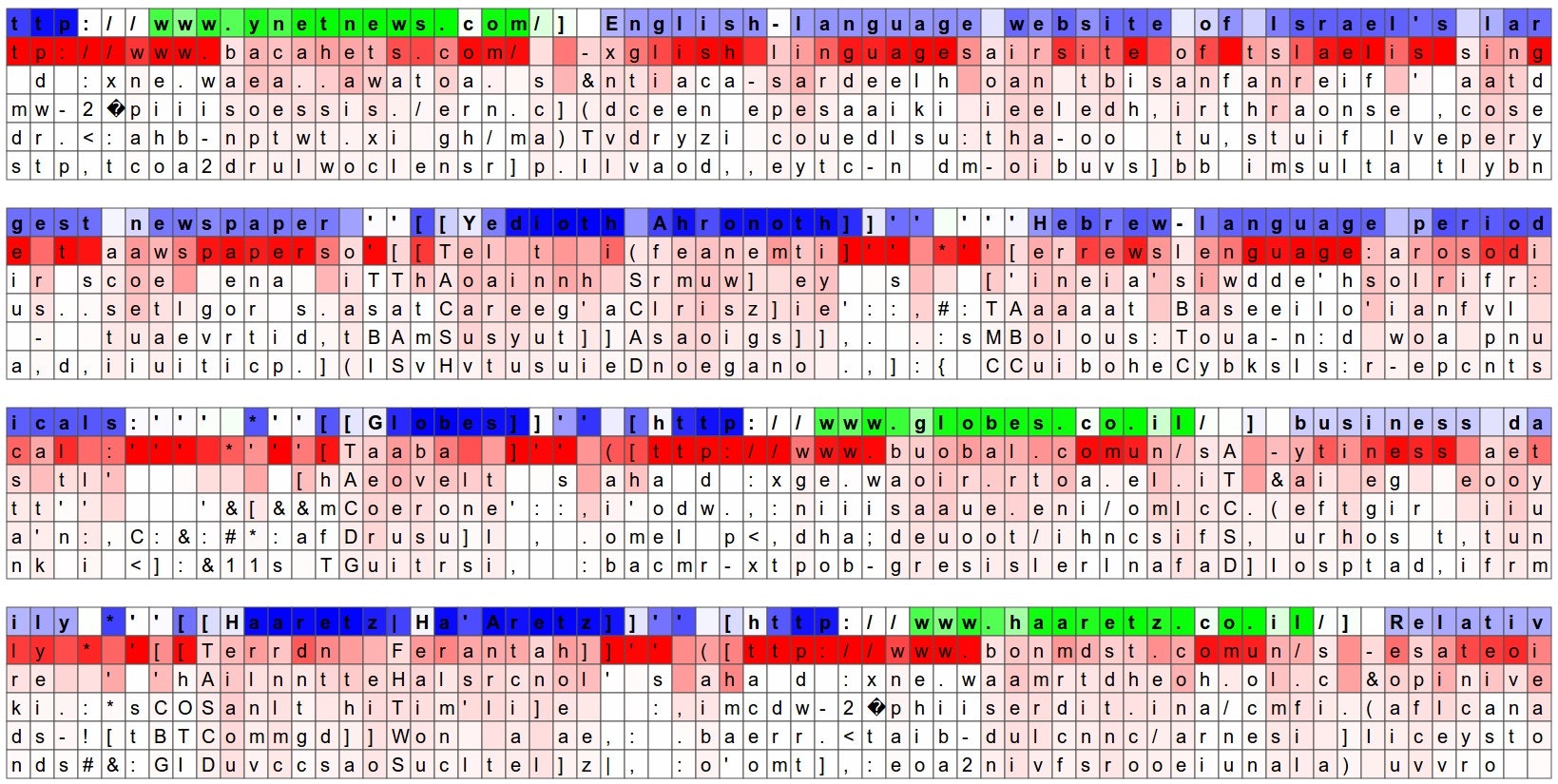
この画像のニューロンは、 URL に非常に興奮し、URL の外でオフになるようである。LSTM はこのニューロンを、URL の中にいるのかそうでないのかを覚えているために使用しているようである。
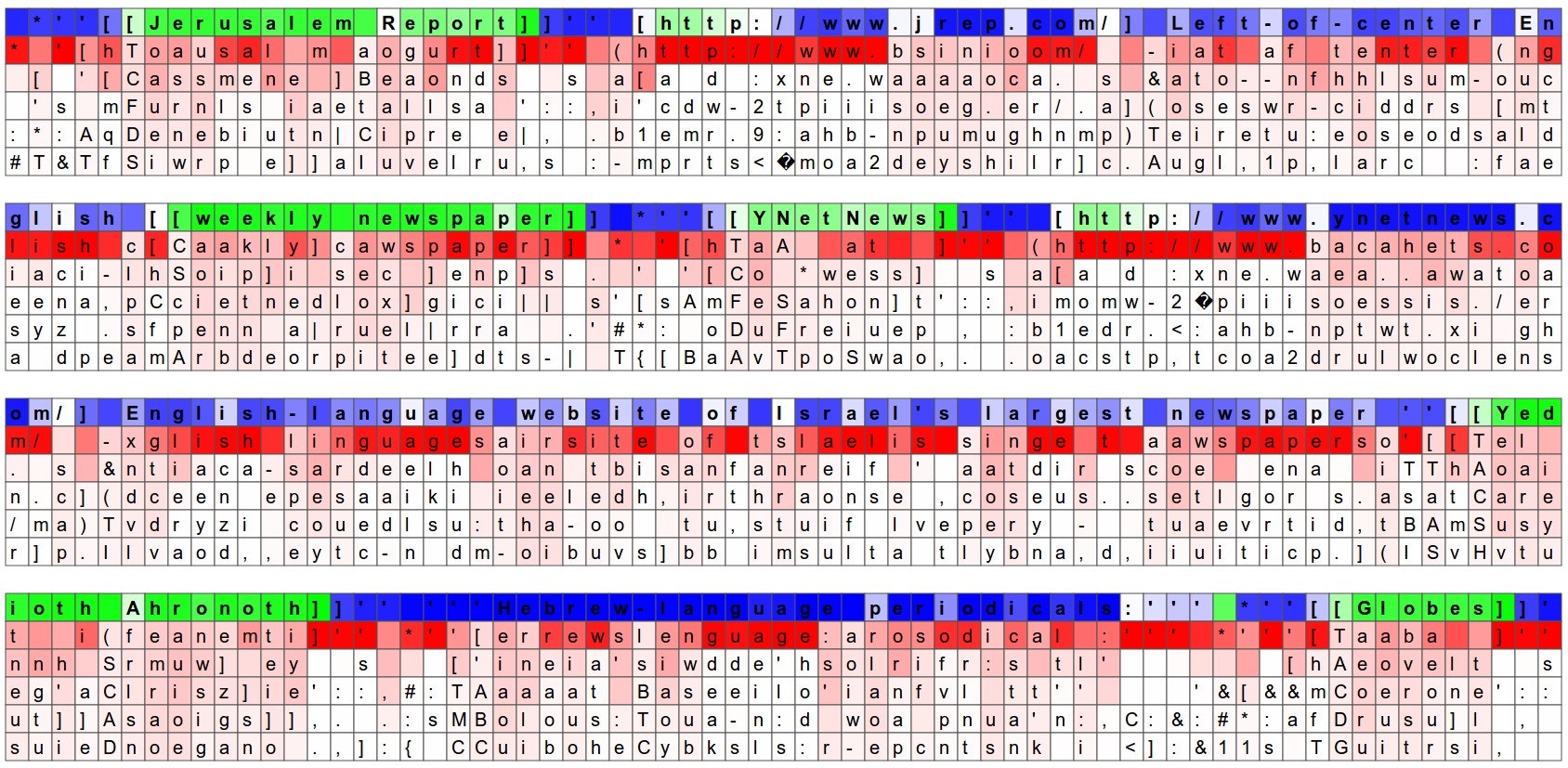
このニューロンは、RNN が [[ ]] マークダウン環境の中にいる時に非常に興奮し、外でオフになる。興味深いことに、このニューロンは、文字「[」を見た直後にはオンにならず、2番目の「[」を待ってから活性化する。モデルが見た「[」が1つか2つかを数えるタスクは、別のニューロンで行われているようである。
このニューロンは一見、[[ ]] 環境にわたって線形に変化している。言い換えると、その活性化は RNN に [[ ]] スコープにわたる、時間に同調する座標系を与える。RNN はこの情報によって、[[ ]] スコープ内でどれだけ前/後ろかに依存して、様々な文字により高い、あるいは低い可能性を与えることが出来る(たぶん?)。

このニューロンは極めて局所的な振る舞いをする:これは比較的静かだが、「www」シーケンスの最初の「w」の直後に急にオフになる。RNN はこのニューロンを、「www」シーケンス内のどの位置かを数え上げるために使用していて、そのため、もう一つ「w」を発行しなければならないか、URL を始めなければならないかを知ることができるのかも知れない。
もちろん、RNN の隠れ状態は巨大で高次元で大規模分散された表現であり、これらの結論の多くはややごまかしと言えます。これらの可視化はカスタマイズされた HTML/CSS/Javascript で作成しています。似たようなものを作りたければ、ここに内部のスケッチがあります。
最も可能性の高い予測を除外することで、この可視化を凝縮し、セルの活性化によって色づけされたテキストだけを可視化することができます。大部分のセルが解釈可能なことを何もしないということに加えて、セルの約 5 %がとても面白くて解釈可能なアルゴリズムを学習したことになる、ということがわかります。
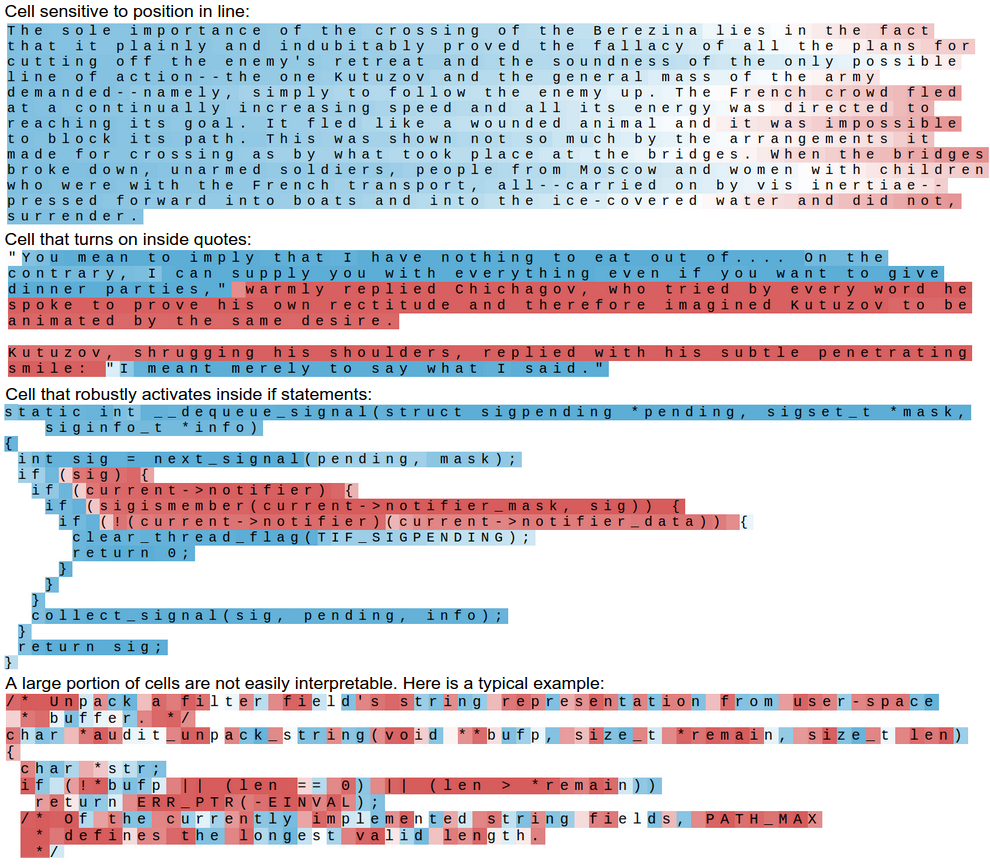

Cell sensitive to position in line: 行内の位置に敏感なセル
Cell that turns on inside quotes: 引用内でオンになるセル
Cell that robustly activates inside if statements: if ステートメント内で強く活性化するセル
A large portion of cells are not easily interpretable. Here is a typical example: セルの大部分は容易には解釈できない。典型的な例
Cell that turns on inside comments and quotes: コメントと引用符内でオンになるセル
Cell that is sensitive to the depth of an expression: 式の深さに敏感なセル
Cell that might be helpful in predicting a new line. Note that it only turns on for some ")": 新たな行の予測に有効かも知れないセル。いくつかの「)」でわずかにオンになることに注意
また、まったくハードコードする必要が無かったということが、美しいです。例えば、次の文字を予測する場合、現在引用の中か外かを追跡することは有効でしょう。単に生データで LSTM を訓練しただけで、モデルはこれが追跡するに値する量だと決定しました。言い換えると、そのようなセルの1つは、訓練中に自らを段階的に調整することによって引用検出セルになり、そのためモデルが最終的なタスクをうまく実行することに役立っています。これは、ディープラーニング・モデル(より一般的に、エンド・ツー・エンドの訓練)の力が何に由来するかという、最もきれいで最も説得力のある例の1つです。
ソースコード
文字レベルの言語モデルの訓練がとても楽しいエクササイズだと確信して下さったことを願っています。私が Github で(MIT ライセンスの下で)公開した char-rnn のコードを使用して、あなた自身のモデルを訓練することができます。これは1つの大きなテキストファイルを取って文字レベルのモデルを訓練します。訓練後、このモデルからサンプリングできます。また、GPU が役に立ちます。GPU が無ければ、CPU での訓練は 10 倍ほど遅くなるでしょう。いずれにしても、何らかのデータで訓練が完了して面白い結果が出たら、私に教えてください!また、Torch/Lua のコードベースで迷子になった場合、それらはすべてこの 100 行の要点の、さらに凝ったバージョンであることを思い出してください。
簡単な余談。コードは、最近私のお気に入りのディープラーニング・フレームワークである、Torch 7 で書かれています。私はほんの数か月前に Torch/LUA を使い始めたばかりですが、簡単ではありませんでした(仕事をするために Github で Torch の生のコードを調べてギッターに質問することに、かなりの時間を費やしました)。しかしコツをつかめば多くの柔軟性とスピードが得られます。過去に Caffe や Theano も使っていました。Torch は、完全ではありませんが、抽象化と哲学のレベルを他のものよりも良くする、と信じています。私の見解では、効果的なフレームワークの望ましい特徴は以下の通りです:
- 多くの機能(スライシング、配列/行列演算、など)を持った、CPU/GPU 透過なテンソル・ライブラリ
- テンソル上で動作し、ディープラーニングの全材料(フォワード/バックワード、計算グラフ、など)を実装した、スクリプト言語(理想的には Python)の完全に独立したコードベース
- 予め訓練されたモデルを簡単に共有できなければならない(Caffe はこれができるが、他のものはできない)
- コンパイル手順が必要無い(または、少なくとも現在の Theano のような方法とは異なる)。ディープラーニングのトレンドは、複雑なグラフの中で時間展開される、より大きく複雑なネットワークの方向である。コンパイルに長い時間を要しないことが重要であり、そうでなければ開発時間は大変苦痛である。第二に、コンパイルによって理解しやすさとログ/デバッグの効率性が失われる。製品の効率化のために開発済みのグラフをコンパイルする選択肢があるのは構わない。
参考文献
記事を終わる前に、より広い文脈の中で RNN を位置づけ、現在の研究の方向性についてのスケッチを提供したいと思います。RNN は近年、ディープラーニングの分野において、かなりの話題と刺激を生み出しました。たたみ込みネットワークと同様に、RNN は世に出て数十年になりますが、その潜在能力は最近ようやく広く認知され始め、その大きな理由は計算資源の発達によるものです。いくつかの最近の動向について簡単に示します(必ずしも完全なリストではありません。そして、この作品の大部分は 1990 年代の研究を利用しています。関連する研究の節を参照してください):
自然言語処理/スピーチの分野では、RNN によるスピーチ-テキスト変換、機械翻訳、手書きテキストの生成、そしてもちろん、それらには強力な言語モデル(Sutskever et al.)(Graves)(Mikolov et al.)が使用されています(文字レベルおよび単語レベルの両方)。現在のところ、単語レベルのモデルの方が文字レベルのモデルよりもうまく機能しますが、これはきっと一時的なものです。
コンピュータビジョン。RNN はまた、コンピュータビジョンにおいても急速に普及しつつあります。例えば、フレーム-レベルのビデオ分類、画像説明(私自身の仕事や他の多くの仕事を含む)、ビデオキャプション、ごく最近のビジュアル質問応答などで RNN が使用されています。コンピュータビジョンの論文における私の個人的なお気に入りの RNN は、ビジュアル・アテンションのリカレント・モデルです。高レベルの方向(一瞥による画像の逐次処理)と低レベルのモデリング(REINFORCE、微分不可能な計算(この場合、画像の周囲を一瞥)を行うモデルの訓練を可能にする、強化学習における方策勾配法の特殊ケースであるルールを学習)の両方のためです。認識において、特に、平面視におけるオブジェクト分類以上に複雑なタスクでは、生の知覚のための CNN の上部に RNN の注目ポリシーをブレンドした、この種のハイブリッドモデルが普及すると、私は確信しています。
帰納的推論、記憶とアテンション。もう一つのとてもエキサイティングな研究の方向は、単純なリカレントネットワークの制限に対処する方に向かっています。1つの問題は、RNN は帰納的ではないということです:RNN はシーケンスをとても良く記憶しますが、一般化することの説得力のあるサインを常に正しい方法で示すわけではありません(もう少ししたら、これをより具体的にする指針を提供するつもりです)。2つ目の問題は、表現のサイズがステップごとの計算量に不必要に束縛されるということです。例えば、隠れ状態ベクトルのサイズを倍にすると、行列の掛け算のためには、各ステップの FLOPS を4倍にする必要があります。理想的には、時間ステップごとの計算量を一定に保つ能力を維持する一方で、巨大な表現/記憶(例えば、ウィキペディア全体や多くの中間状態変数を含む)を維持したいです。
この方向の最初の説得力のある例は、DeepMind のニューラル・チューリングマシンの論文で展開されました。この論文は、大きな外部メモリ・アレイと、計算が行われる小さなメモリ・レジスタ集合(作業用メモリと考える)の間の、読み書き操作を実行可能なモデルへの道を示しました。重要なことに、NTM 論文ではまた、(ソフトかつ完全に微分可能な)アテンション・モデルによって実装された、とても面白いメモリ・アドレッシング・メカニズムが紹介されました。ソフト・アテンションのコンセプトは強力なモデリング特徴であることが判明し、機械翻訳における整列と翻訳の共同学習によるニューラル機械翻訳や、(おもちゃの)質問応答におけるメモリ・ネットワークで紹介されました。私は言いたいです。
アテンションのコンセプトは、ニューラルネットワークにおける最近もっとも面白いアーキテクチャ上のイノベーションである
さて、これ以上詳細には立ち入りたくありませんが、モデルを完全に微分可能に保つため、メモリ・アドレッシングのためのソフト・アテンションの方策は便利です。ただし、残念なことに、注目可能なものは全て注目する(ただしソフトに)ため、効率を犠牲にします。これは、C 言語におけるポインタの宣言と考えて下さい。ただし、特定のアドレスをポイントするのではなくメモリ全体の全アドレス上の分布全体を定義し、間接参照するとポイントされた内容の荷重和が返ります(そのため高価な操作です!)。このことはソフト・アテンションを、注目するためにメモリの特定のチャンクをサンプリングする(例えば、すべてのセルに対して読み書きする代わりに、いくつかのセルに対してある程度読み書きする)ハード・アテンションに置き換えるよう、複数の著者を動機づけました。このモデルははるかに哲学上魅力的であり、スケーラブルであり、効率的ですが、残念なことに、微分可能ではありません。そして、微分可能ではない相互作用のコンセプトに習熟している強化学習の文献(例えば、REINFORCE)から、テクニックを援用する必要があります。これはまさに現在進行中の研究ですが、これらのハード・アテンション・モデルは、例えば、Inferring Algorithmic Patterns with Stack-Augmented Recurrent Nets(スタック増補リカレントネットによるアルゴリズムのパターン推定)、Reinforcement Learning Neural Turing Machines(強化学習ニューラル・チューリングマシン)、Show Attend and Tell(見せる、注目する、告げる)、などで調査されました。
人々。RNN を研究したければ、Alex Graves、Ilya Sutskever、Tomas Mikolov らの論文を推奨します。REINFORCE、より一般に、強化学習と方策勾配法(REINFORCE はその一種)については、David Silver のクラスや、Pieter Abbeel のクラスのどれかを推奨します。
コード。RNN を訓練して遊びたい場合、Theano の Keras や Passage、この記事と共に公開された Torch のためのコード、私が少し前に書いた、生の numpy のための効率的なバッチ LSTM のフォワード/バックワードパスを実装したコードのこの gist が良いようです。また、画像説明に RNN/LSTM を使用した、私の numpy ベースの NeuralTalk や、Jeff Donahue によるこの Caffe の実装を見ることもできます。
結論
RNN について、どのように動作するのか、なぜ大物になったのかを学びました。RNN 文字レベル言語モデルをいくつかの面白いデータセットで訓練し、RNN が向かっている方向について見てきました。RNN の間に多くのイノベーションが起こることを確信してください。私は RNN が知的システムの全面的で重要な構成要素になると信じています。
最後に、この記事にいくつかのメタを加えるために、このブログ記事のソースファイルで RNN を訓練しました。残念なことに、およそ4万6千文字しかなく、RNN に適切に与える十分なデータではありませんが、返されたサンプル(典型的なサンプルを得るために低い温度で生成)は以下のようなものでした:
I've the RNN with and works, but the computed with program of the
RNN with and the computed of the RNN with with and the code
はい、この記事は RNN と、それがどれだけうまく動作するか(works)についてだったので、明らかにこれは動作します(works) :) それでは、また!
編集(追加リンク)
ビデオ:
・ロンドンのディープラーニング・ミートアップ(ビデオ)でこの研究について講演を行いました。
ディスカッション:
・HN ディスカッション
・r/機械学習についての reddit ディスカッション
・r/プログラミングについての reddit ディスカッション
返信:
・Yoav Goldberg はこれらの RNN の結果と n-グラム最大尤度(カウント)ベースラインを比較した
・@nylk は調理レシピで char-rnn を訓練した。グレイト!
・@MrChrisJohnson は Eminem の詩で char-rnn を訓練し、ロボットの声でそれを読ませてラップソングを合成した。陽気だね :)
・@samim はオバマ演説で char-rnn を訓練した。面白い!
・João Felipe はアイリッシュ・フォーク音楽で char-rnn を訓練し、音楽をサンプリングした
・Bob Sturm もまた ABC 記法の音楽で char-rnn を訓練した
・Maximilien による RNN バイブル・ボット
・Learning Holiness は聖書を学習
・Terminal.com のスナップショット。char-rnn を設定し、ブラウザ・ベースの仮想マシンを準備した(@samim に感謝)