画像生成モデル(Diffusion model)をONNXに変換する際、モデル内のxFormersが原因でエラーが起きたので、解決方法を残します。
ONNXとは
ONNXは、TensorFlowやPyTorchの様々な機械学習フレームワーク間で、モデルを相互運用可能にするためのオープンフォーマットです。
詳細な説明は、以下を含めた他記事を参考にしてください。
xFormersとは
xFormersは、Transformersの研究と応用を加速することを目的に開発されたPyTorchベースのライブラリです。例えば、Stable Diffusionを用いた画像生成において、高速化やVRAM使用量の削減のために使われています。
エラーの原因
今回発生したエラーの原因は、xFormersのMemory-efficient attentionでした。そこで、調査のために、memory_efficient_attentionのみのモデルを対象として、ONNXへの変換を試みます。
実行環境は以下の通りです。
- Python 3.10.12
- CUDA 12.1
- Pytorch 2.5.1
- onnx 1.17.0
import torch
import torch.nn as nn
from xformers.ops import memory_efficient_attention
torch.manual_seed(42)
class XformersAttentionModel(nn.Module):
def __init__(self, dropout_p=0.0):
super(XformersAttentionModel, self).__init__()
self.dropout_p = dropout_p
def forward(self, query, key, value, attn_bias=None):
output = memory_efficient_attention(
query, key, value,
attn_bias=attn_bias,
p=self.dropout_p
)
return output
if __name__ == "__main__":
# モデルインスタンス
model_xformers = XformersAttentionModel().cuda()
# ダミー入力
dummy_query = torch.randn(1, 8, 128, 64, device="cuda")
dummy_key = torch.randn(1, 8, 128, 64, device="cuda")
dummy_value = torch.randn(1, 8, 128, 64, device="cuda")
# ONNXモデルに出力
torch.onnx.export(
model_xformers,
(dummy_query, dummy_key, dummy_value),
"model_xformers.onnx",
opset_version=17,
input_names=["query", "key", "value"],
output_names=["output"],
)
...
RuntimeError: Found an unsupported argument type c10::SymInt in the JIT tracer. File a bug report.
やはりできません。こちらのissueでもあるように、基本的にxFormersはONNXをサポートしていないようです。
一方、xFormersのドキュメントでは、memory_efficient_attentionをスクラッチで書く方法が記載されていました。これを使えば、ONNXに変換できるかもしれません。
スクラッチで書く
実際に書きましょう。クラス以外は先ほどのコードとほぼ同じです。
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(42)
class EquivalentAttentionModel(nn.Module):
def __init__(self, dropout_p=0.0):
super(EquivalentAttentionModel, self).__init__()
self.dropout_p = dropout_p
def forward(self, query, key, value, attn_bias=None):
scale = 1.0 / query.shape[-1] ** 0.5
query = query * scale
query = query.transpose(1, 2)
key = key.transpose(1, 2)
value = value.transpose(1, 2)
attn = query @ key.transpose(-2, -1)
if attn_bias is not None:
attn = attn + attn_bias
attn = attn.softmax(-1)
attn = F.dropout(attn, self.dropout_p)
output = attn @ value
return output.transpose(1, 2)
if __name__ == "__main__":
# モデルインスタンス
model_equivalent = EquivalentAttentionModel().cuda()
# ダミー入力
dummy_query = torch.randn(1, 8, 128, 64, device="cuda")
dummy_key = torch.randn(1, 8, 128, 64, device="cuda")
dummy_value = torch.randn(1, 8, 128, 64, device="cuda")
# ONNXモデルに出力
torch.onnx.export(
model_equivalent,
(dummy_query, dummy_key, dummy_value),
"model_equivalent.onnx",
opset_version=17,
input_names=["query", "key", "value"],
output_names=["output"],
)
すると、無事にONNXに変換できました。Netronで確認します。
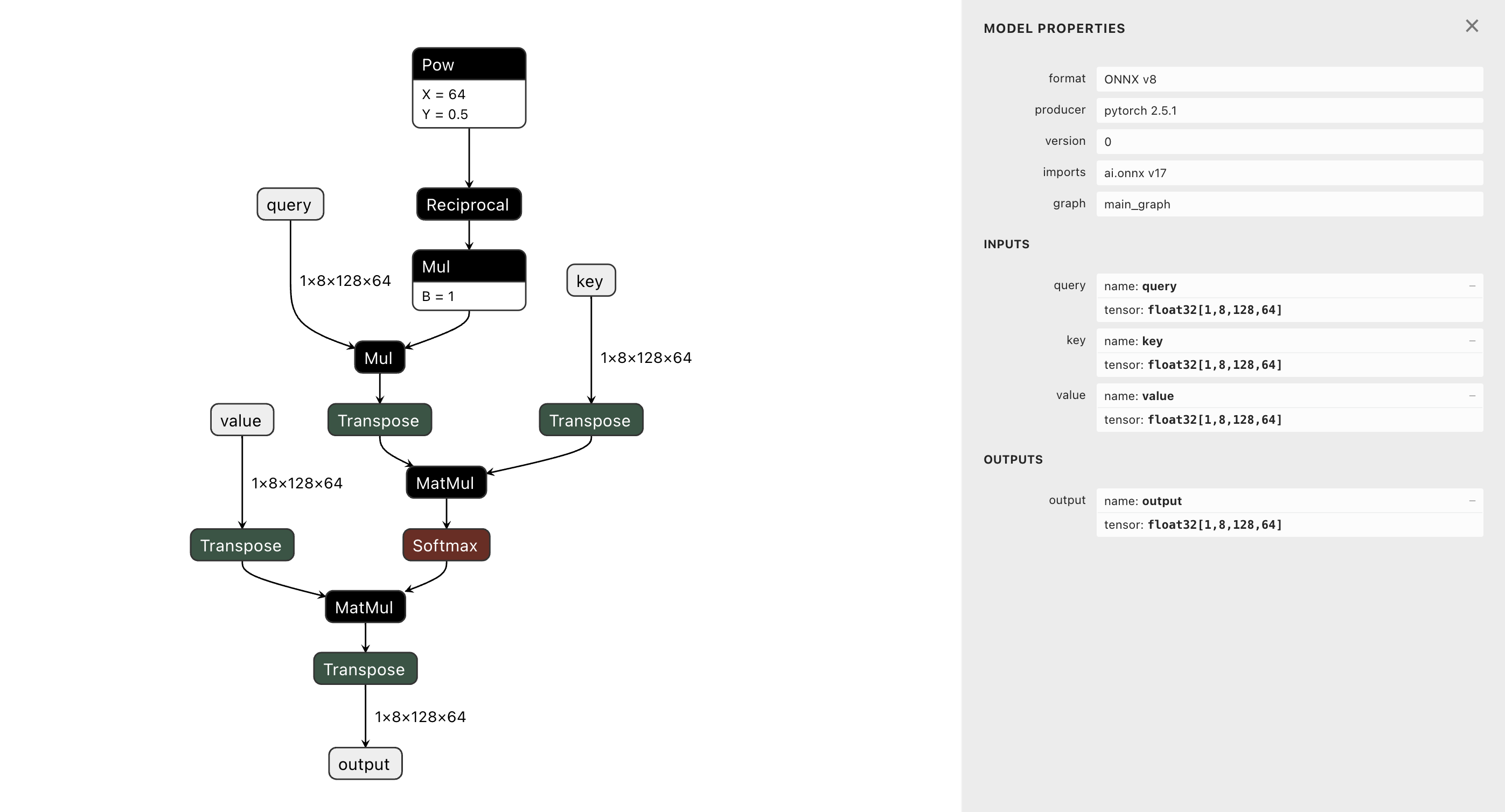
精度の検証
スクラッチで書いたことによって、どの程度精度に影響が出るか確認します。
xformersを使ったモデルとONNXモデルそれぞれに対して、同じ入力を与えて、出力の差の最大値を表示します。
import numpy as np
import torch
import onnxruntime
from xformers_attention import XformersAttentionModel
torch.manual_seed(42)
model_xformers = XformersAttentionModel().cuda()
sess = onnxruntime.InferenceSession("model_equivalent.onnx")
# ダミー入力
dummy_query = torch.rand(1, 8, 128, 64, device="cuda")
dummy_key = torch.rand(1, 8, 128, 64, device="cuda")
dummy_value = torch.rand(1, 8, 128, 64, device="cuda")
# 出力を計算
output_xformers = model_xformers(dummy_query, dummy_key, dummy_value)
output_onnx = sess.run(
None,
{
"query": dummy_query.cpu().numpy(),
"key": dummy_key.cpu().numpy(),
"value": dummy_value.cpu().numpy(),
},
)[0]
# 差分を表示
diff = output_xformers.cpu().numpy() - output_onnx
max_difference = np.abs(diff).max()
print("Max difference:", max_difference)
Max difference: 2.9802322e-07
差は最大でも10の-7乗オーダーなので、ほぼ気にしなくていいでしょう。
おわりに
今回のコードは以下にまとめてあります。
また、本記事を書くにあたり、以下の記事を参考にさせていただきました。
おまけ
- xFormersを使ったモデル(GPU)
- xFormersをスクラッチに書き換えたモデル(GPU)
- ONNXモデル(CPU)
で実行速度を比較しました。
import time
import torch
import onnxruntime
from xformers_attention import XformersAttentionModel
from equivalent_attention import EquivalentAttentionModel
torch.manual_seed(42)
model_xformers = XformersAttentionModel().cuda()
model_equivalent = EquivalentAttentionModel().cuda()
sess = onnxruntime.InferenceSession("model_equivalent.onnx")
# 計測用のイベント
start_event_xformers = torch.cuda.Event(enable_timing=True)
end_event_xformers = torch.cuda.Event(enable_timing=True)
start_event_equivalent = torch.cuda.Event(enable_timing=True)
end_event_equivalent = torch.cuda.Event(enable_timing=True)
# ダミー入力
dummy_query = torch.rand(1, 8, 128, 64, device="cuda")
dummy_key = torch.rand(1, 8, 128, 64, device="cuda")
dummy_value = torch.rand(1, 8, 128, 64, device="cuda")
# Xformersモデルの計算時間を測定
start_event_xformers.record()
output_xformers = model_xformers(dummy_query, dummy_key, dummy_value)
end_event_xformers.record()
torch.cuda.synchronize()
# Equivalentモデルの計算時間を測定
start_event_equivalent.record()
output_equivalent = model_equivalent(dummy_query, dummy_key, dummy_value)
end_event_equivalent.record()
torch.cuda.synchronize()
# ONNXモデルの計算時間を測定
start = time.time()
output_onnx = sess.run(
None,
{
"query": dummy_query.cpu().numpy(),
"key": dummy_key.cpu().numpy(),
"value": dummy_value.cpu().numpy(),
},
)[0]
end = time.time()
# 計算時間を取得
time_xformers = start_event_xformers.elapsed_time(end_event_xformers)
time_equivalent = start_event_equivalent.elapsed_time(end_event_equivalent)
time_onnx = (end - start) * 1000
# 計算時間の差を表示
print("Xformers Model Time (ms):", time_xformers)
print("Equivalent Model Time (ms):", time_equivalent)
print("ONNX Model Time (ms):", time_onnx)
Xformers Model Time (ms): 0.5304319858551025
Equivalent Model Time (ms): 713.9911499023438
ONNX Model Time (ms): 1.3279914855957031
ONNXがいい速さしてます。まあ元のモデルがAttention一つだけなので、比較になるのかは怪しいですが...
あと、スクラッチにするとこんなにも遅くなるんですね。