DCGANでポケモン生成
今回はkaggelで配布されているデータセット https://www.kaggle.com/kvpratama/pokemon-images-dataset を教師データ(正解画像)として用います。
実際のコードは以下からダウンロードできます。
https://github.com/Kohey1480/pokemon_dcgan
同じ階層にデータセットを用意しimagechange.py->pokemon_dcgan.pyの順で実行してください。
教師データについて
配布されているポケモンデータセットは第7世代721体のポケモンのメガシンカやフォルムチェンジを含んだの819枚画像で、256(pixel)×256(pixel)×3(channel)になっています。メモリのオーバーフローを避けるため今回使うデータは64(pixel)×64(pixel)×3(channel)に圧縮しました。
DCGANの簡単な説明
詳しくは論文 に書いてありますが、DCGANは以下のように構成されています。
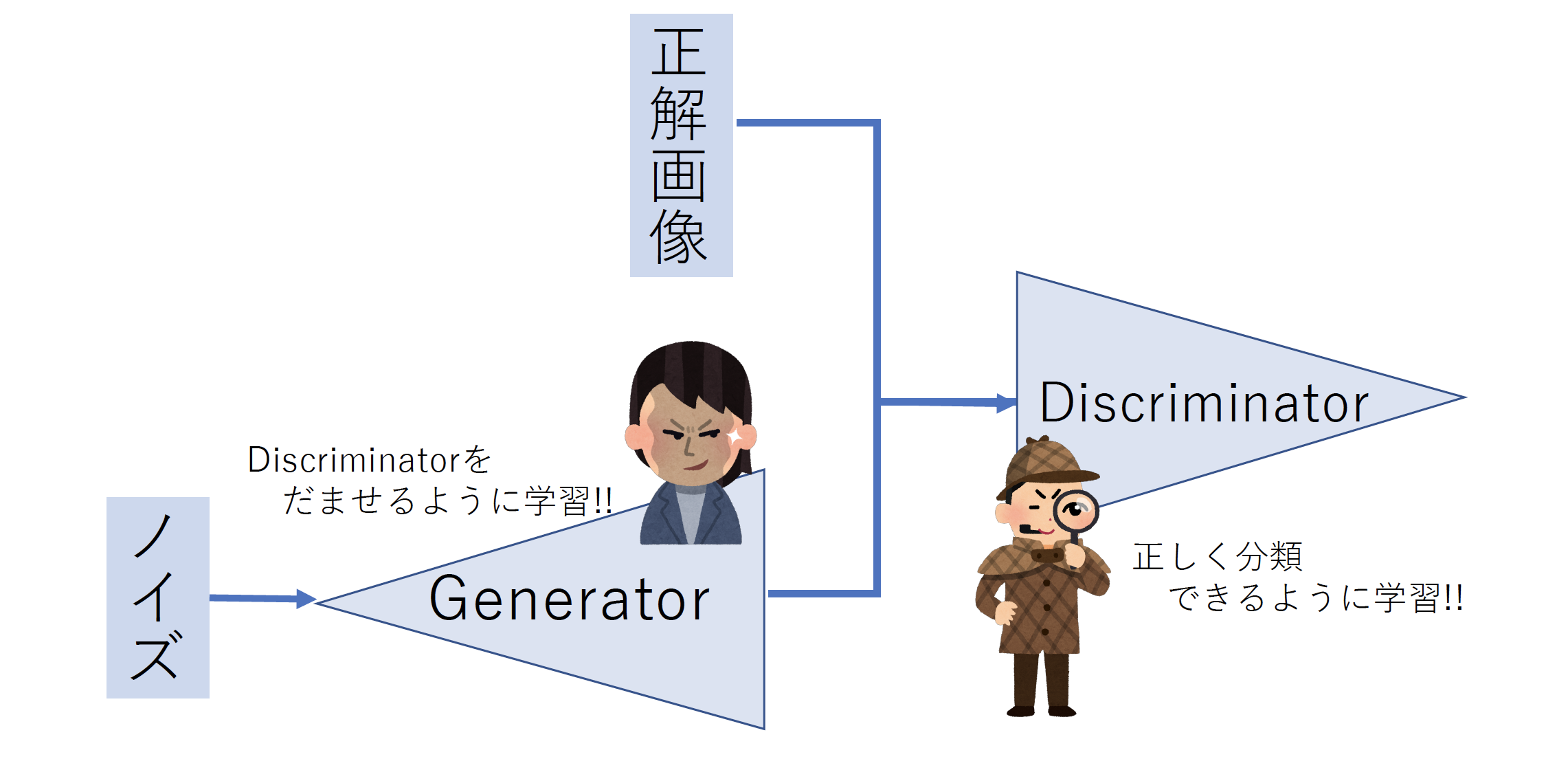
大まかに言うとGeneratorとDiscriminatorで構成されていて、ランダムに生成されたノイズからGenerator部分で画像を生成し、
Discriminator部分では実際の画像であるかgeneratorであるかを判別するようにできていて、Discriminator正しく判断し、generatorは学習されたDisciminatorをだませるように学習を行っていくという構成です。
実装
まず、Generatorについては、UpSampling2Dという関数を用いて、畳み込みの逆方向の操作を行うことで画像を生成していきます。また、
・ 出力層の活性化関数はtanhを用いる
・ バッチノルムを用いる。
といったテクニックがあるようです。
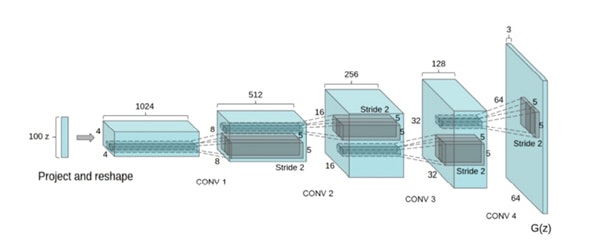
今回実装したGenerator部分のニューラルネットワークは以下のコードで構成されています。
def generator(self):
noise_shape = (self.z_dim,)
model = Sequential()
model.add(Dense(128 * 16 * 16, activation="relu", input_shape=noise_shape))
model.add(Reshape((16, 16, 128)))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(3, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
model.summary()
return model
Discminatorについては畳み込みニューラルネットワーク(CNN)で構成されていて出力層については、正解画像か生成された画像であるか生成された画像であるかの2クラス問題であるため、出力層のノードは1個か2個でもどちらでもよく、1個で設定されているものが一般的であるようであるが、直感的にわかりやすくするために今回は出力層のノードを2個で構成しました。
また、DCGANに限ってはDiscmininatorは
・ pooling層ではなくストライド幅を大きくした畳み込み層を用いること
・ 全結合層を用いないこと(層が深ければ深いほど用いないほうが良い)
・ 活性化関数はLeakyReLUを用いること
・ バッチノルム用いること
などといったテクニックがあるようです。
def build_discriminator(self):
img_shape = (self.img_rows, self.img_cols, self.channels)
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
#model.add(ZeroPadding2D(padding=((0, 1), (0, 1))))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(GlobalAveragePooling2D())
model.add(Dense(2, activation='sigmoid'))
model.summary()
return model
結果
以下100000epoch学習した推移です。

↓100000epoch学習後の出力です。

ポケモンっぽい...??
(これでもパラメーターやネットワークのチューニングに数日かかりました。)