情報検索・検索技術 Advent Calendar 2021 の 11 日目の記事です。前回は @sz_dr さんの「ちょっとテクい検索ランキングをVespaで実現する」でした。
この記事では BERT を使った文書検索手法 Birch について解説します。
先日、「最新の情報検索手法を知るにはどうしたらいいの...という人に向けたコンテンツまとめ記事2021」という記事を公開しました:
上記の記事では、ニューラル検索手法や最新の情報検索手法を知るためのコンテンツ紹介にとどめましたが、今回の記事では実際にニューラル検索手法の一つである Birch について解説します。
Birch について
Birch は EMNLP-IJCNLP 2019 で採択された「Cross-Domain Modeling of Sentence-Level Evidence for Document Retrieval」という論文の手法です:
上の論文のベースとなっているのがこちらの arXiv に公開されているこちらの論文です:
著者は Zeynep Akkalyoncu Yilmaz, Wei Yang, Haotian Zhang, Jimmy Lin です。最後の著者である Jimmy Lin はカナダの Waterloo 大学に在籍する教授です。Castorini という研究チームを構成していて情報検索と自然言語処理のための様々なツールを公開しています:
では、「Cross-Domain Modeling of Sentence-Level Evidence for Document Retrieval」の論文に沿って解説していきます。まずは背景からです。
背景
ここでは、背景について書きます。まずアドホック検索へのニューラル手法の応用とその真の進歩について説明し、次に情報検索タスクへの BERT の応用について説明します。
アドホック検索へのニューラル手法の応用とその真の進歩
まず、重要なのがアドホック検索へのニューラル手法の応用とその真の進歩についてです。
-
アドホック検索
- アドホック検索とは、ユーザのニーズを満たすような適合文書を獲得するスタンダードな検索タスクです。文書を検索する最初の段階では、クエリに含まれる単語を持つ文書絞り込みます。最初の段階の手法として、Bag-of-Words と呼ばれる単語マッチング手法ベースの BM25 などが代表的です。
-
ニューラル検索手法
- BM25 などでランク付けされた文書に対して、次の段階で再ランク付けを行います。再ランク付けでニューラル検索手法を適用します。このようなモデルをリランカーモデルと呼びます。ニューラル検索手法は、検索タスクにしていて機械学習手法を応用することでより精度よく検索を行う方法で、近年様々な提案がされています。
-
ニューラル検索の真の進捗
- 提案された多数のニューラル検索手法が真に進捗をもたらしたとは断言しづらい状態があります。例えば、ニューラル検索モデルの性能を向上する一つの方法として、検索エンジンの行動ログデータを利用する方法があります。しかし、大量の行動ログデータを使えるのは Google など検索エンジンを提供している一部の企業のみです。
- 2019 年の研究では、提案されているニューラル検索手法のほとんどがより精度の低い古い手法と比較して精度が向上したと主張していて、実際には大きく進捗していないことが報告されています:Critically Examining the "Neural Hype": Weak Baselines and the Additivity of Effectiveness Gains from Neural Ranking Models, SIGIR 2019
著者らは研究において重要なことは数値を比較して勝利を示すことじゃなく、知識を得ることが重要だと述べています。また、既存研究を基にしてベースラインの設定と評価をより強固にすることの重要性を主張しています。その上で、ニューラル検索手法をどのように適応すれば真に性能向上するような手法を提案できるかということを検討しています。
情報検索タスクへの BERT の応用
次に重要な話が、情報検索タスクへの BERT の応用についてです。
-
BERT (Bidirectional Encoder Representations from Transformer)
- Google が提案した深層学習手法による大規模汎用言語モデルであり、自然言語処理分野の様々なタスクにおいて高い性能を示しています:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
- 詳細についてはわかりやすい日本語の解説記事をご確認ください: はじめての自然言語処理 BERT を用いた自然言語処理における転移学習 | オブジェクトの広場
-
BERT を使った検索手法
パッセージ検索タスクでは BERT を適用することで性能が向上することが明らかになっています。しかし、アドホック文書検索タスクで BERT を活かすにはまだいくつかの課題が残っています。
課題と解決方法
背景を踏まえた上でニュース記事のアドホック検索タスクに BERT を適用する上では以下の課題があります。
-
BERTは最大入力シーケンス長である 512 を超えるようなトークン数の長い文を入力として扱えない
- 事前学習済みの BERT モデルの仕様上、計算のメモリ制約などから入力できる単語数は 512 と制限があります。
- 実際にこの論文で利用している TREC Robust 04 データセットでは、文書の単語長の中央値が 679 であり、単語長が 512 以上の文書は 66% もあります。
そこで、文書の各文について適合性判定を行うという解決手段を提案しています。しかし、次の問題があります:
-
ほぼ全てのニュース記事テストコレクションにおける適合性判定ラベルは個々の文ではなく文書に対するアノテーションのみ
- 情報検索のテストコレクションにおけるデータは一般にクエリと文書に対して、適合・非適合が与えられていて、一つ一つの文に与えられているというデータはありません。
- BERT の制限により文単位で処理をしたいが、クエリと文に対する適合性判定ラベルがあるようなデータは、ニュース記事のドメインでは存在していません。
そこで、ニュース記事ではない別ドメインのデータにおける文レベルの適合性判定ラベルがあるデータをモデルの学習に使うという解決手段を提案しています。驚くことに、別ドメインのデータを使っても性能が向上することが明らかになりました。
手法
ここでは手法について書きます。以下に手法の全体像を示します。
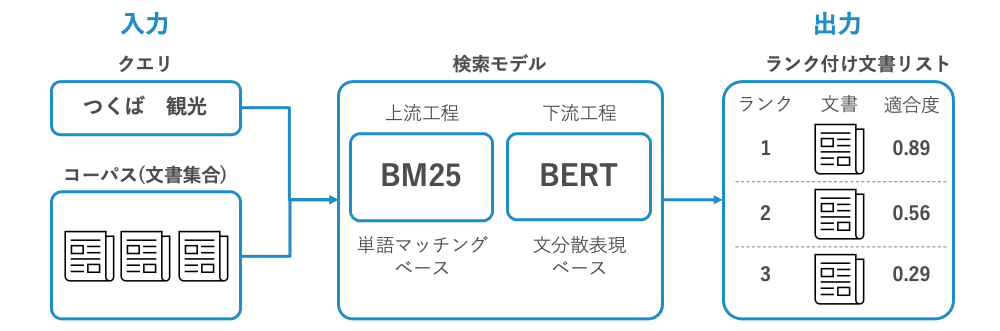
入力と出力
入力は、クエリと文書集合です。クエリは Google で検索するときなどに入力する「つくば 観光」などの比較的短い単語列です。クエリはユーザの情報ニーズを表します。文書集合は複数の文書からなる文書集合です。通常、文書集合は膨大な数の文書数です。文書集合の要素である各文書は比較的長い単語列から構成されます。課題のところで述べたように、この文書の長さが BERT を適用する上での課題となってきます。
出力は、クエリに対する適合度でランク付けされた文書のリストです。適合度が高いほどクエリに対して文書が適合していることになり、適合度が低いほどクエリに対して文書が適合していないことになります。
検索モデル
BM25
検索モデルはクエリと文書の適合度を検索します。検索モデルは2段階で構成されます。BM25 と BERT です。BM25 は強力な教師なし検索モデルです。単語の出現頻度や文書の長さなどを考慮して文書の適合度を計算します。BERT は大規模汎用言語モデルを用いた深層学習手法です。クエリと文を分散表現に変換して適合度を計算します。
BERT
BM25 は単純な単語のマッチングによる手法であり計算時間は比較的高速ですが、BERT は潜在的な意味空間におけるベクトルのマッチングによる手法であり計算時間は低速です。そこで、最初に BM25 で膨大な文書の中から適合文書を絞り込み、上位 k 件の文書についてのみ BERT による計算を行うようになっています。BERT で適合スコアを計算する際には、文書を直接入力することはできないので、文単位に分割して、それぞれの文に対して適合スコアを計算します。適合スコアが最も高いような文は文書全体のスコアを表す代替的な役割を果たすことがわかっているのでこのようにします。
BERT への入力は次のようになります:
$$
[[\rm{CLS}], q_1, q_2, ..., q_i, [\rm{SEP}], s_1, s_2, ..., s_j, [\rm{SEP}]]
$$
$[\rm{CLS}], [\rm{SEP}]$ は BERT 特有の制御トークンです。$q \in Q$ はクエリ単語、$s \in S$ は文の単語です。入力したクエリに対する文のスコアを $[\rm{CLS}]$ に基づいて算出します。
def tokenize_two(self, a, b):
tokenized_text_a = ['[CLS]'] + self.tokenizer.tokenize(a) + ['[SEP]']
tokenized_text_b = self.tokenizer.tokenize(b)
tokenized_text_b = tokenized_text_b[:510 - len(tokenized_text_a)]
tokenized_text_b.append('[SEP]')
segments_ids = [0] * len(tokenized_text_a) + [1] * len(tokenized_text_b)
tokenized_text = tokenized_text_a + tokenized_text_b
# Convert token to vocabulary indices
indexed_tokens = self.tokenizer.convert_tokens_to_ids(tokenized_text)
return indexed_tokens, segments_ids
入力の a がクエリで、b が文です。文の長さはクエリに合わせて 512 を超えないように調整されていますね。
BM25 と BERT の線形結合スコア
クエリに対する文書の適合スコア $S_{f}$ はクエリに対する文書のスコアと文レベルのスコアの線型結合です。計算式は次の通りです:
$$
S_{f} = \alpha \cdot S_{\rm{doc}}+(1-\alpha) \cdot \sum_{i=1}^{n} w_{i} \cdot S_{i}
$$
$S_{\rm{doc}}$ は文書自体の BM25 スコアであり、$S_{i}$ は文レベルの BERT スコアです。$n$ は文書の中で上位何件の文のスコアを利用するかというパラメータです。上位 $n$ 件の文を $w_i$ で重み付けして足し合わせます。$\alpha$ は BM25 スコアと BERT スコアの比重を決めているといえます。ハイパーパラメータである $n$ は交差検証、$\alpha, w$ はグリッドサーチによって求めます。
実験設定
ここでは実験設定について書きます。
実験環境
- NVIDIA Tesla P40 GPUs
- PyTorch v1.2.0
BERT モデル
- BERT Large (uncased, 340m parameters)
データセット
学習データは、クエリに対して基本的に文に対する適合性判定ラベルがついたデータセットとなっています。面白いのは単純な文で構成されているデータだけではないという点で、これらのデータを使っても性能が向上しているというのは様々な気づきを与えてくれます。
| 学習データセット | 説明 |
|---|---|
| TREC MB: TREC Microblog Tracks | 2011年から2014年に編成された TREC Microblog Tracks のデータセットでクエリとツイートの適合性で構成。 |
| MS MARCO: MAchine Reading COmprehension | Microsoft Bing 検索エンジンの検索ログからサンプリングされたクエリと Web 文書から抽出された文の適合性で構成 |
| TREC CAR: TREC Complex Answer Retrieval | TREC CAR は質問応答(QA)タスクのデータセットであり、クエリと段落の適合性で。各クエリは、Wikipedia の記事のタイトルとセクションタイトルを連結したものです。 |
テスト時のデータはクエリに対して文書の適合性判定ラベルがついたデータセットとなっています。学習時にテスト時のデータが一切使われていないことも重要なポイントです。
| テストデータセット | 元データ | クエリ数 | 文書数 |
|---|---|---|---|
| TREC Robust04(2004) | The New York Times ニュース記事データ | 250 | 50万 |
| TREC Common Core17(2017) | The Washington Post ニュース記事データ | 50 | 180万 |
| TREC Common Core18(2018) | The Washington Post ニュース記事データ | 50 | 60万件 |
評価指標
| 評価指標 | 説明 |
|---|---|
| AP | 平均精度。 |
| P@20 | 上位 20 件の適合率。 |
| NDCG@20 | 上位 20 件の NDCG。検索モデルの評価指標としてよく用いられます。 |
実験結果
ここでは実験結果について書きます。以下に論文から引用した結果の図を示します。
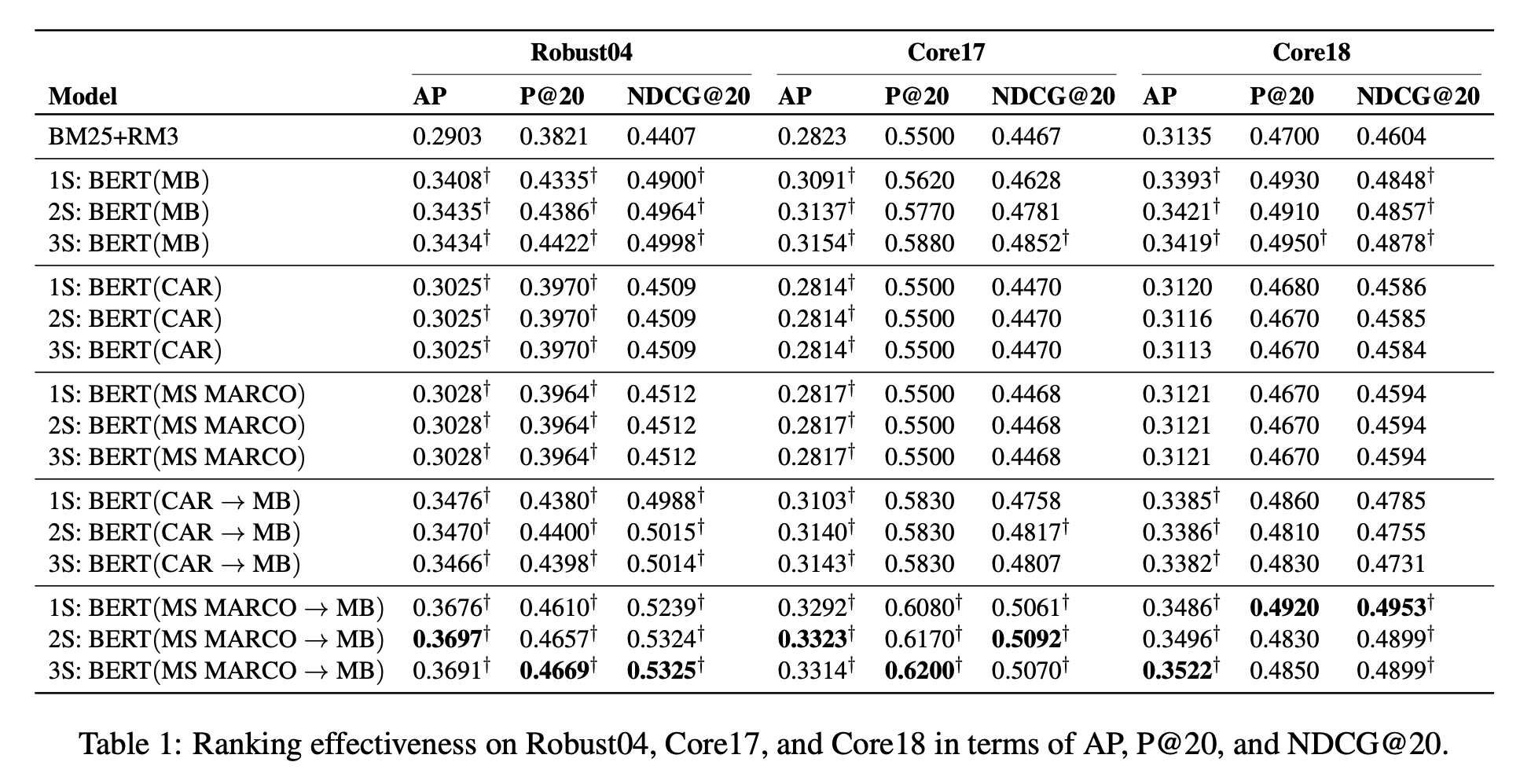
まず表記について確認します。ベースラインとして用いられているのは BM25 と RM3 です。モデルに書かれている 1S, 2S, 3S は上位何件の文レベルの適合性である BERT スコアを使ったかを表しています。BERT(〇〇) は〇〇データセットで fine-tune したことを表しています。BERT(〇〇->□□) は〇〇データセットで fine-tune した後に□□データセットで fine-tune したことを表しています。また、$\dagger$ はベースラインの BM25+RM3 に対して t-検定にボンフェローニ補正を行った結果 p < 0.01 で統計的に優位であることを表しています。
次に結果について確認します。個々のモデルでは、Web データである MS MARCO よりもツイートデータである MB を fine-tune に使った方が性能が良くなっています。不思議ですね。文単体で内容が完結しているような表現が重要なのでしょうか。複数のデータセットを使って fine-tune した結果では MS MARCO と MB を使った結果が最も良くなっています。全体を見ても複数のデータセットを使うことでより性能が向上することがわかります。
再現実験
この論文は以下のリポジトリにコードと実験方法が公開されています。以前再現実験を行ったことがありますが、このリポジトリに従って行うと全く同じ結果を再現できます。ありがたいですね。
ただし、再現実験をする際の注意として Robust04 のデータ利用に申請が必要な点と、マシンスペックとマシンリソースが一定必要な点のハードルがあります。
ちなみに実は、筆者は NII(国立情報学研究所) が主催する情報検索のためのテストコレクションを構築する NTCIR という国際ワークショップにてウェブ文書検索タスクである NTCIR-15 WWW-3 にて Birch を応用して 1 位を獲得したことがあります。再現性が高く、再現しやすかったことの恩恵を受けました。気になる方はご一読いただけると嬉しいです:
まとめ
今回の記事では「Cross-Domain Modeling of Sentence-Level Evidence for Document Retrieval」という論文の手法について紹介しました。
論文から、アドホック文書検索において BERT を適用できること、検証したいドメインでの検証したい構成のデータセットを持っていない場合でも別ドメインのデータを使うことで性能向上が可能なことが明らかとなりました。
実際にプロジェクトで開発するシステムや研究において、論文で提案されている BERT の適用方法は参考になるかと思います。さらに詳しい BERT を使ったニューラル検索手法についてはこちらの論文が参考になります、分量は多めですがぜひ読んでみてください:
また、紹介した論文を引用している論文を見ることで、どのような改善が提案されるかを観測できます:
Cross-domain modeling of sentence-level evidence for document retrieval を引用している論文
おまけ
チームの名前とツールの名前について
- Castorini
- Castorini はイタリア語でビーバーの複数形を意味するようです。ロゴを見ても分かる通りでカナダですからビーバーになっているんでしょうね。(推測です)
- Anserini
- こちらは英語で鳥のガン亜科を言葉です。こちらもロゴを見て分かる通りでカナダガンに由来するんでしょうね。(多分)
- Birch
- こちらは英語で白樺を意味する言葉です。ビーバーが住処を作るために切る木が白樺なのでそれに由来するんですかね。
ちなみに Jimmy Lin のチームの別の論文として「H2oloo at TREC 2020: When all you got is a hammer... Deep Learning, Health Misinformation, and Precision Medicine」という論文があるんですが、これは大学が Waterloo なので Water から $H_2O$ というダジャレみたいな名前になっています。自前で開発するツールや論文にキャッチーな名前をつける際の参考にしたいと思います。
間違えやすい情報検索の用語について
- Relevance: 関連性と訳されがちですが、情報検索の文脈では「適合性」とすることが多いように思います。
- Bag-of-Words: 単語の袋と訳される場合を見ますが、Bag は多重集合のことでありこの言葉が意味しているのは「単語の多重集合」です。(参考までに:多重集合 - Wikipedia)