はじめに
SQL苦手...と認識していたので、参考文献を読んでみて、気になるところを実験してみました。
主旨としてはindex絡みのSELECT文のパフォーマンスについての記事になります。
前提
簡易の受注管理システムを想定する。
- 顧客(users table)
- 商品(items table)
- 注文(orders table)
- 注文明細(order_items table)
注文の検索に関して、下記のような要件があると想定する。
-
注文を顧客名でlike検索したい。 -
注文を注文日で検索したい。このとき、等号だけでなく範囲でも検索したい
ER図

データボリューム
db: order_1k
+------------+------------+-------------+------------------+
| item_count | user_count | order_count | order_item_count |
+------------+------------+-------------+------------------+
| 100 | 100 | 1000 | 2000 |
+------------+------------+-------------+------------------+
db: order_10k
+------------+------------+-------------+------------------+
| item_count | user_count | order_count | order_item_count |
+------------+------------+-------------+------------------+
| 100 | 1000 | 10000 | 20000 |
+------------+------------+-------------+------------------+
db: order_100k
+------------+------------+-------------+------------------+
| item_count | user_count | order_count | order_item_count |
+------------+------------+-------------+------------------+
| 100 | 10000 | 100000 | 200000 |
+------------+------------+-------------+------------------+
db: order_1m
+------------+------------+-------------+------------------+
| item_count | user_count | order_count | order_item_count |
+------------+------------+-------------+------------------+
| 100 | 100000 | 1000000 | 2000000 |
+------------+------------+-------------+------------------+
db: order_10m
+------------+------------+-------------+------------------+
| item_count | user_count | order_count | order_item_count |
+------------+------------+-------------+------------------+
| 100 | 1000000 | 10000000 | 20000000 |
+------------+------------+-------------+------------------+
実験
実験1: indexを使用した場合としない場合の、レコード量に対する検索速度の劣化はどれくらいか、という視点
注文を注文日で検索したい。このとき、等号だけでなく範囲でも検索したい
実験1-A: = で比較した結果
SELECT * FROM orders where ordered_on = '2012-01-02';
| count of records | unindexed(sec) | indexed(sec) |
|---|---|---|
| 1000 | 0 | 0 |
| 10000 | 0.01 | 0 |
| 100000 | 0.07 | 0.01 |
| 1000000 | 0.8 | 0.07 |
| 10000000 | 5.79 | 1.44 |

実験1-B: < で比較した結果
SELECT * FROM orders where ordered_on < '2012-07-01';
| count of records | unindexed(sec) | indexed(sec) |
|---|---|---|
| 1000 | 0 | 0 |
| 10000 | 0.02 | 0.02 |
| 100000 | 0.16 | 0.13 |
| 1000000 | 0.99 | 0.92 |
| 10000000 | 8.59 | 8.16 |
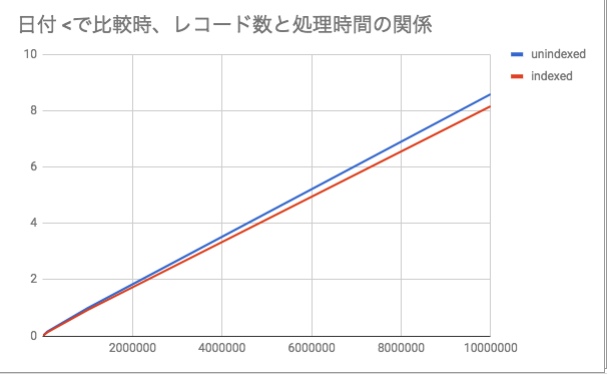
実験1の考察
実験1-Aは予想通りでしたが、実験2は1-Bは予想と外れたことで学べるものがありました。
実験2において、indexを貼っている場合と貼ってない場合で、実行時間が変わらない理由は、実行計画が変わらないからです。下記がindexが張っている場合のexplainの出力で、indexを使っていません。
mysql> explain(SELECT * FROM orders where ordered_on < '2012-07-01');
+----+-------------+--------+------------+------+------------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | orders | NULL | ALL | ordered_on_index | NULL | NULL | NULL | 9981215 | 50.00 | Using where |
+----+-------------+--------+------------+------+------------------+------+---------+------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
これは、下記のように理解しました。
前提としてordersテーブルのordered_onカラムは、
2012年の日付がランダムに振られるようになっている(カーディナリ値: 365)。
=で比較した実験1-Aでは、全レコードの約1/365のヒットが予測される。
index上で捜査してからアドレスをもとにテーブルを読みにいったほうが速いと
オプティマイザが判断したため、indexが使用された。
<で比較した実験1-Bでは < '2012-07-01'で比較しているため、
全レコードの約1/2のヒットが予測される。
全表走査したほうが速いとオプティマイザが判断したため、indexは使用されなかった(貼ってあっても)。
つまり、indexを貼っていてもindexが使われないというケースは、厳密には2つに分けたほうがいいといえます。
- 論理的にindexで検索することが不可能なケース(
<>での検索などは2分木検索で検索ができない) - 論理的にはindexで検索することができるが、それよりパフォーマンスがいい案(全表走査)が存在するので、indexをあえて使わないケース
もう少し詳しく知りたい方は参考文献の索引を作成したのにパフォーマンスが悪いケースを参照ください。
実験2: カーディナリ値の影響はどれくらいか、という視点
実験1-Bの結果を踏まえて、カーディナリ値の影響を予想してみると。
まずカーディナリ値が低い場合、そもそもindex貼ってあっても使われないと予想されます。
なぜなら例えば(男: 1、女: 2)みたいなものだと、全レコードの約1/2がヒットすることが期待されるからです。
どのあたりからindexを使うようになるのか、が一つ観察のポイントになりそうです。
一方で、カーディナリ値の影響というのは、(ランダムに値が代入されることを仮定すれば)言い換えると、ヒットする割合の影響はどうか、ということになりますね。
よってヒットする割合が変化していったときに、indexありとindexなしではどういう差が産まれるのかという点も観察してみたいと思います。
実験に際して、ordersテーブルに配送地域を表す整数型のカラム(area_kind)を追加しました。
また、ordersのレコード数が100万で実験します。
テーブルの更新毎に統計情報を更新します。
実験2-A: どのあたりからindexを使うようになるのか
EXPLAIN(SELECT * FROM orders WHERE area_kind = 1);
ここでアクシデントが、下記のようにカーディナリ値が2のときですでにindexが使われるという結果に。
| cardinality of area_kind | index used? |
|---|---|
| 2 | yes |
| 3 | yes |
あれ半分くらいだとindex使わないんじゃ...実験1-Bと結果/考察と矛盾するなぁ...と思っていたらなんとなく原因が分かりました。
実験1-Bのとき
mysql> EXPLAIN(SELECT * FROM orders WHERE ordered_on < '2012-07-01');
+----+-------------+--------+------------+------+------------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | orders | NULL | ALL | ordered_on_index | NULL | NULL | NULL | 995988 | 50.00 | Using where |
+----+-------------+--------+------------+------+------------------+------+---------+------+--------+----------+-------------+
今回の実験2-Aのときで、カーディナリ値が2のとき。
mysql> EXPLAIN(SELECT * FROM orders WHERE area_kind = 1);
+----+-------------+--------+------------+------+-----------------+-----------------+---------+-------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-----------------+-----------------+---------+-------+--------+----------+-------+
| 1 | SIMPLE | orders | NULL | ref | area_kind_index | area_kind_index | 5 | const | 497994 | 100.00 | NULL |
+----+-------------+--------+------------+------+-----------------+-----------------+---------+-------+--------+----------+-------+
比較してみるとrows(そのSELECT分をうつと何件ヒットするのかのオプティマイザの予想)が全然違うんですね。
前者のやつは予想が大きく外れています。本来ヒットは半分くらいしかない(とデータを入れた僕自身は知っている)のに、
オプティマイザの予想では100万行中ほぼ全件なんじゃないかと予想しています。
一方後者のやつは、予想が正確です。約半数の50万件くらいがヒットするんじゃないかと予想されています。
ほぼ全件ヒットするなら、indexで走査するより全表走査したほうが速い!という感じで、
実験1-Bではindexが使われなかったということですね。
とはいえ、本来もっと複雑な判断をオプティマイザはしていると思うので、
このあたりもっと詳しくみたい場合、EXPLAINの経過をもっと詳細にみれるみたいなのでこちらを参考に試し
てみるのもいいかもしれません。
実験2-B: ヒットする割合が変化していったときに、indexありとindexなしではどういう差が産まれるのか
SELECT * FROM orders WHERE area_kind = 1;
| cardinality of area_kind(ratio) | unindexed(sec) | indexed(sec) |
|---|---|---|
| 1 (1.0) | 0.58 | 3.33 |
| 2 (0.5) | 0.38 | 1.91 |
| 3 (0.3) | 0.38 | 2.72 |
| 4 (0.25) | 0.31 | 1.14 |
| 5 (0.2) | 0.28 | 1.14 |
| 10 (0.1) | 0.25 | 1.87 |
| 20 (0.05) | 0.34 | 0.26 |
| 30 (0.03) | 0.64 | 0.09 |
| 40 (0.025) | 0.22 | 0.10 |
| 50 (0.02) | 0.25 | 0.08 |
| 100 (0.01) | 0.21 | 0.04 |

今回のケースだと、カーディナリ値が20付近で処理時間が逆転しています。
実験3: indexが貼られているカラムと、貼られていないカラムを検索したらどうなるのか、という観点
WHERE indexされているカラム=xxx AND indexされてないカラム=yyyとしたときはどうなるんだろう、という実験です。
この実験は単純に確かめたいだけです。
予想1
btree indexの構造上、貼ってないのが1つでも条件に入った時点でindex使うのは無理。
予想2
indexがカラムAとカラムBに個別に貼ってあった場合(複合indexが貼られていない)も、WHERE A=1 AND B=2のようにしても無理。
前提
mysql> show columns from orders;
+------------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| ordered_on | date | NO | | NULL | |
| user_id | int(11) | NO | MUL | NULL | |
| area_kind | int(11) | YES | | NULL | |
+------------+---------+------+-----+---------+----------------+
mysql> show index from orders;
+--------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+--------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| orders | 0 | PRIMARY | 1 | id | A | 998490 | NULL | NULL | | BTREE | | |
| orders | 1 | fk_user_id | 1 | user_id | A | 101212 | NULL | NULL | | BTREE | | |
| orders | 1 | ordered_on_index | 1 | ordered_on | A | 366 | NULL | NULL | | BTREE | | |
+--------+------------+------------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
予想1の結果
予想1は間違っていました。
予想したときは、頭の中にindex走査中でwhere句を満たすレコードのアドレスを見つけないといけないという縛りがあったのですが、そんなことはなかったです(安心)
ちょっとこの部分の公式の説明を見つけれられなかったのですが、おそらく起きていることとしては
- カラムordered_onに貼ってあるindexでを使ってindex走査(ordered_on='2012-09-01')し、絞りこみを行う
- 絞り込まれたレコードの中からarea_kind=1を満たすレコードを返す。
ということが起きていると思います。この挙動もオプティマイザの判断によってまちまちかと。
mysql> explain(SELECT * FROM orders WHERE ordered_on='2012-09-01' AND area_kind=1);
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | orders | NULL | ref | ordered_on_index | ordered_on_index | 3 | const | 2770 | 10.00 | Using where |
+----+-------------+--------+------------+------+------------------+------------------+---------+-------+------+----------+-------------+
予想2の結果
これも外れましたwww
予想1の結果からより少ない数にindex走査内で絞込ができる、とオプティマイザが思っているindexで絞り込みがされた後、テーブル内でもう一方の条件の絞り込みを行うのかと思ってたのですが、
実際は、両方のindexで別々にindex走査して、その結果を(index_1にもindex_2にもあるアドレス)結合して、そのアドレスをもとに返しているようです。この挙動もオプティマイザの判断しだいだと思います。
mysql> explain(SELECT * FROM orders WHERE ordered_on='2012-09-01' AND user_id=1);
+----+-------------+--------+------------+-------------+-----------------------------+-----------------------------+---------+------+------+----------+-----------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------------+-----------------------------+-----------------------------+---------+------+------+----------+-----------------------------------------------------------+
| 1 | SIMPLE | orders | NULL | index_merge | fk_user_id,ordered_on_index | fk_user_id,ordered_on_index | 4,3 | NULL | 1 | 100.00 | Using intersect(fk_user_id,ordered_on_index); Using where |
+----+-------------+--------+------------+-------------+-----------------------------+-----------------------------+---------+------+------+----------+-----------------------------------------------------------+
実験4: 意図的な非正規化(joinの回避)の影響はどれくらいか、という視点
予想はjoinしない分、非正規化したほうが速い、という予想です。
注文を顧客名でlike検索したい。
正規化されている場合
SELECT o.*
FROM orders o INNER JOIN users u ON o.user_id = u.id
WHERE u.name LIKE '%aa%'
;
結果 => 1.76秒
+----+-------------+-------+------------+------+---------------+------------+---------+---------------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------------+---------+---------------+-------+----------+-------------+
| 1 | SIMPLE | u | NULL | ALL | PRIMARY | NULL | NULL | NULL | 99671 | 11.11 | Using where |
| 1 | SIMPLE | o | NULL | ref | fk_user_id | fk_user_id | 4 | order_1m.u.id | 9 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------------+---------+---------------+-------+----------+-------------+
意図的に非正規化されている場合
joinしなくていいように、ordersテーブルにuser_nameカラムを持たせておきます。
SELECT * from orders WHERE user_name LIKE '%aa%';
結果 => 0.79秒
mysql> explain(SELECT * from orders WHERE user_name LIKE '%aa%');
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | SIMPLE | orders | NULL | ALL | NULL | NULL | NULL | NULL | 997920 | 11.11 | Using where |
+----+-------------+--------+------------+------+---------------+------+---------+------+--------+----------+-------------+
結果/考察
これはさすがに予想は当たりました。よかったです。
ただ、これくらいの差なら、本来他にもjoinしなければいけないテーブルがあり、それらを非正規化した場合のinsert/updateによる整合性の調整とかを加味すると、やっぱり非正規化ってほとんど100%しないほうがいいな、と思いました。
まとめ
すべての実験からいえることですが、indexを使うにあたって。
when => どういう時に使われるのか
how=> どうやって使われるのか
を抑えておく必要があるなと再認識できました。(当然のことですいません)
また僕のとても安易でシンプルな予想が、たくさん間違っていたことを確認できたのもすごく勉強になりました。
そのときの状況によってオプティマイザが動的に実行計画を立てる、という性質のものなので、やはり難しい!
このそのときの状況によってオプティマイザが動的に実行計画を立てるという性質があることによって、
index貼るのかどうかの判断、非正規化するかのどうかの判断のために計測したいときは、
実際本番で入るであろう非常に正確で綺麗なデータを用意しないと意味ないな、と改めて感じました。
また、explainの出力を理解するのも同じように大事なことでした:)
実行環境
MySQL: '5.7.21'
実行環境: docker(公式imageからbuild)
参考文献
達人に学ぶ SQL徹底指南書
達人に学ぶDB設計 徹底指南書
すごくわかりやすいindexの説明
POSTD リレーショナルデータベースの仕組み
公式 最適化
索引を作成したのにパフォーマンスが悪いケース