対象とする読者
- RustでISUCONに出場し優勝したい人
- プログラムの最適化に興味がある人
- プログラムの実行速度に飢えているスピード狂の方々(筆者を含む)
きっかけ
Rustのテンプレートエンジンの一つであるAskamaの作者がRustの様々なテンプレートエンジンを比較したベンチマーク結果を公開していました。
このリポジトリのBig tableというベンチマーク結果を見ると、一番速いライブラリでも1つのテンプレートのレンダリングに264マイクロ秒の時間を要していることが分かります。
1つのテンプレートに264マイクロ秒費やすということは、1秒間でわずか3000〜4000個のテンプレートしかレンダリングできないことを意味します。
しかしActix-webは毎秒60万リクエストを捌ける能力を持っており、テンプレートのレンダリングではCPUの待機時間が発生しないことを考えるとこれは大きなオーバーヘッドとなります。
そこで、手元で実験をしながらどこまで高速化できるか試してみてみたところ、結果的にこれらのライブラリよりも優れた速度を達成することができたのでライブラリにして公開することにしました。
成果物
詳しい使い方はUser Guideに書いてありますが、基本的にテンプレートの文法はERubyやEJSと同じで、<% %>で囲まれたブロックにRustのコードを記述するだけです。
<html>
<body>
<% for msg in &messages { %>
<div><%= msg %></div>
<% } %>
</body>
</html>
Rustから呼び出す際にはderive macroを使ってTemplateOnceトレイトを実装します。
# [derive(TemplateOnce)]
# [template(path = "hello.stpl")]
struct HelloTemplate<'a> {
messages: &'a [String],
}
fn main() {
let ctx = HelloTemplate {
messages: &[String::from("foo"), String::from("bar")];
}
println!("{}", ctx.render_once().unwrap());
}
derive(TemplateOnce)という記述を加えることにより、コンパイル時にテンプレートを読み込み、テンプレートをレンダリングするためのRustのコードを自動生成するという仕組みになっています。
ちなみにSailfishという名前はバショウカジキの英名からきていますが、最近の研究ではバショウカジキはそれほど速くないらしいです(それでもウサイン・ボルトと同じくらい)。1 2 3 4
最適化の軌跡
Big tableベンチマークの概要
行数100, 列数100の行列をHTMLのテーブルとして出力します。Sailfishの文法だとこんな感じになります。
<table>
<% for r1 in &table { %>
<tr>
<% for r2 in r1 { %>
<td><%= r2 %></td>
<% } %>
</tr>
<% } %>
</table>
今回はこれをどこまで高速化できるのか試してみました。
簡単な最適化
1. std::write!を使った愚直な実装
use std::io::Write;
let mut output = Vec::<u8>::new();
write!(&mut output, "<table>").unwrap();
for r1 in &table {
write!(&mut output, "<tr>\n").unwrap();
for r2 in r1 {
write!(&mut output, "<td>{col}</td>", col = r2).unwrap();
}
write!(&mut output, "</tr>\n").unwrap();
}
write!(&mut output, "</table>").unwrap();
ご存知の方は多いと思いますが、Rustのwrite!マクロは基本的に遅いです。
これは、write!が内部的に動的ポリモーフィズムで実装されていることや出力フォーマット指定などを考慮していることに起因します。
2. String::push_strを使って置き換える
write!は遅いのでString::push_strを直接呼び出して高速化します。
use std::fmt::Write;
let mut buffer = String::new();
buffer.push_str("<table>");
for r1 in &table {
buffer.push_str("<tr>");
for r2 in r1 {
buffer.push_str("<td>");
write!(buf, "{}", *r2);
buffer.push_str("</td>");
}
buffer.push_str("</tr>");
}
buffer.push_str("</table>");
80%くらい速くなりました。
3. itoaクレートを使う
まだwrite!マクロが一箇所残ってしまっているので、itoaクレートを使って数値を文字列に変換します。
- write!(buf, "{}", *r2)?;
+ itoa::fmt(&mut buffer, *r1);
さらに80%くらい速くなりました。
4. String::push_strを再実装する
String::push_strは内部的にはVec::extend_from_sliceを呼び出しているのですが、私の環境ではどうもこの関数の呼び出しが遅いようでした。
そこで(どうしてそういう発想に至ったのかは分からないのですが)String型をラップしたBufferという構造体を作ることにしました。
struct Buffer {
inner: String
}
impl Buffer {
...
#[inline]
fn push_str(&mut self, data: &str) {
let size = data.len();
self.inner.reserve(size);
unsafe {
let p = self.inner.as_mut_ptr().add(self.inner.len());
std::ptr::copy_nonoverlapping(data.as_ptr(), p, size);
self.inner.set_len(self.inner.len() + size);
}
}
}
Stringの代わりにこの構造体を使うことで60%ほど速くなりました。
5. reserveの呼び出しを制限する
アセンブリ5とFrameGraphを確認したところ、reserve関数の呼び出しがインライン化されておらず、またその呼び出しがボトルネックになっていたので、push_strの実装を書き換えました。
- self.inner.reserve(size);
+ if size > self.inner.capacity() - self.inner.len() {
+ self.inner.reserve(size);
+ }
なんとこれだけでさらに1.5倍の速度を達成しました。
6. レンダリングの文字列の長さを記憶する
上記の変更にも関わらず、Buffer::reserve関数の呼び出しが依然としてボトルネックになっていました。
最近のmallocは速いので、多少多めにメモリを確保してしまってもパフォーマンスの劣化はそれほど大きくなりません。
そこで、それまでのレンダリングで出力された文字列の長さの最大値を記憶し、その分だけ予めメモリを確保することにします。
static CAPACITY_HINT: AtomicUsize = AtomicUsize::new(0);
let capacity_hint = CAPACITY_HINT.load(Ordering::Acquire);
let mut buffer = Buffer::with_capacity(capacity_hint);
buffer.push_str("<table>");
for r1 in &table {
buffer.push_str("<tr>");
for r2 in r1 {
buffer.push_str("<td>");
buffer.push_int(*r2);
buffer.push_str("</td>");
}
buffer.push_str("</tr>");
}
buffer.push_str("</table>");
let new_capacity_hint = buffer.len();
if new_capacity_hint > capacity_hint {
CAPACITY_HINT.store(new_capacity_hint, Ordering::Release);
}
これでさらに80%ほど高速化しました。
なお、実際には掲示板サイトのようにレンダリングする度に中身が増えていくケースもあるので、最大値よりも少し多めにメモリを確保することでメモリの再確保を防止しています。
ちなみにこの時点で他のライブラリとの比較結果は以下のようになりました。
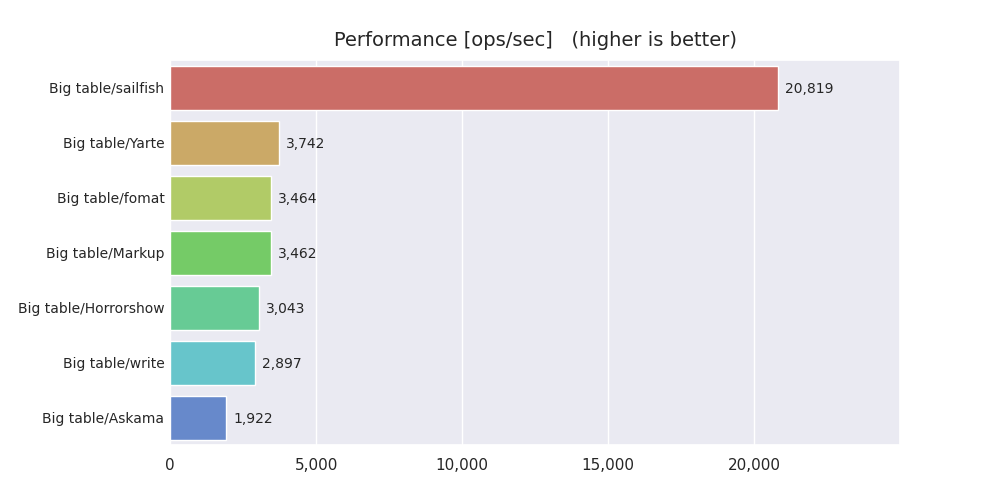
7. Stringを再実装する
アセンブリを見るとString::with_capacityやString::reserveがインライン化されておらず、そのためにreserveが必要がどうかのチェックが無駄に発生していることに気がついたので、思い切ってStringそのものをstd::allocモジュールを駆使して再実装しました。5
これによりさらに10%ほど高速化しました。
宿敵現る
ここまで実験を終えた段階で、他のライブラリと大きな差が出たので、これらの最適化手法をSailfishというライブラリとして公開することにしました。
しかしこのリポジトリを公開してからわずか1日後、yarteというライブラリが新たにTemplateFixedTraitというトレイトとそのderive macroを公開しました。これがとても速く、なんと従来の3倍以上の速度を達成していました。6
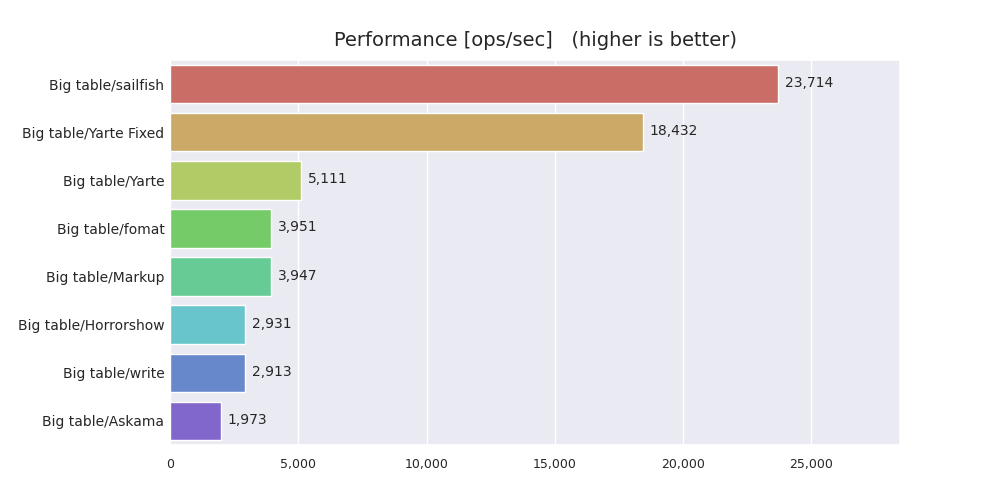
今回はあくまでも「最速」のテンプレートエンジンを作ることが目標であるため、yarteから逃げ切るためにさらに高度な最適化をいくつか施しました。
高度な最適化
1. ループの先頭と末尾を結合する
先程のコードの最内ループについて考えます。
for r2 in r1 {
buffer.push_str("<td>");
buffer.push_int(*r2);
buffer.push_str("</td>");
}
このループでは、最後に</td>を出力し、その後最初に戻って<td>を出力しています。この操作を2回に分けるのは明らかに非効率です。
そこで、末尾の文字列を先頭の文字列をくっつけてまとめて出力するようにコードを改変します。
buffer.push_str("<td>");
for r2 in r1 {
buffer.push_int(*r2);
buffer.push_str("</td><td>");
}
buffer.truncate(buffer.len() - 4);
これにより15%ほど速度を改善しました。
2. 数値の書き込みを高速化する
この時点でボトルネックとなっていたのは、数値を書き込む部分、つまりpush_intを呼び出している部分でした。
これまではitoaクレートを使って数値をバッファに書き込んでいました。しかしitoaクレートでは、予め用意された固定長のメモリ配列に後ろから数値を書き込み、その結果をバッファにコピーします。
もしこれを先頭から書き込めるようにすれば、固定長の配列ではなくバッファそのものに直接書き込むことができます。
これを速く行う方法を探していたところ、itoa-benchmarkというリポジトリを見つけました。
桁数が小さい数値のほうが出現頻度が高いと考えられるので、5桁までの整数で最も優れたパフォーマンスを発揮しているbranchlutという実装をRustに移植しました。これにより、さらに約20%の高速化を実現しました。
ベンチマーク結果
ここまでの最適化を施した結果、以下のようなベンチマーク結果が得られました。
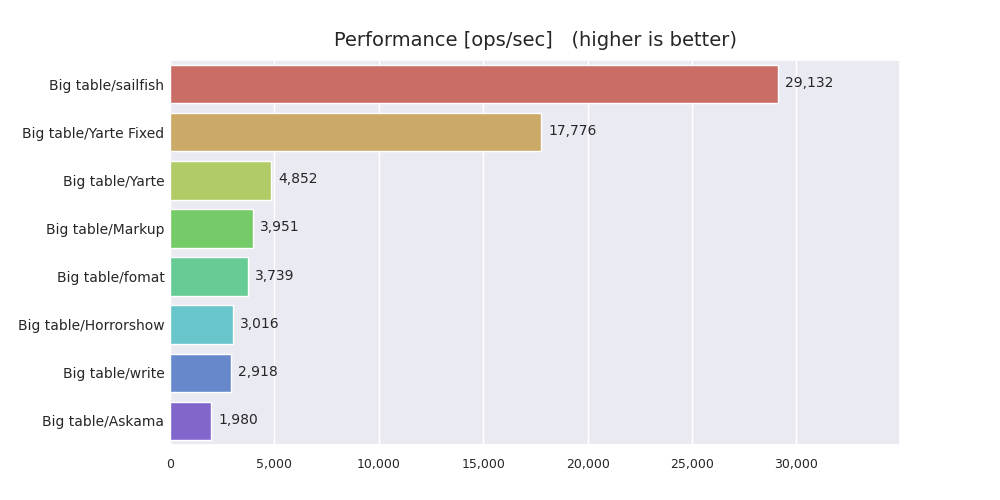
私の知る限り、Rustのライブラリの中では一番速いと思います。
とりあえずはstd::write!の約10倍の速度を達成することができたので、区切りが良いために一度記事にまとめて投稿することにしました。
sailfishで用いられている最適化手法が読者のお役に立てれば幸いです。
今後について
しばらく速度ばかりに焦点を当てていて機能面が疎かになっているので、今後は機能面を充実させていく予定です。
ただし最適化の余地はまだいくつか残っているので、パフォーマンスが改善でき次第、最新のベンチマーク結果をこちらにて更新していきます。
追記(2020/1/24)
「世界最速」と謳っていますが、今回の目的はあくまでBig table benchmarkをどこまで最適化出来るかを試すものであり、他のライブラリを貶したり、あるいは特定のライブラリが他より優れていることを示すためのものではありません。また他のベンチマークにおいても最速であることを保証するものでもありません。
ちなみに現在では他のライブラリのパフォーマンスもかなり上昇してきており、必ずしもsailfishが最速であるとは言えない状況になっています。
-
Sagong W, Jeon W-P, Choi H (2013) Hydrodynamic Characteristics of the Sailfish (Istiophorus platypterus) and Swordfish (Xiphias gladius) in Gliding Postures at Their Cruise Speeds. PLoS ONE 8(12): e81323 ↩
-
Stefano Marras, Takuji Noda, John F. Steffensen, Morten B. S. Svendsen, Jens Krause, Alexander D. M. Wilson, Ralf H. J. M. Kurvers, James Herbert-Read, Kevin M. Boswell, Paolo Domenici, Not So Fast: Swimming Behavior of Sailfish during Predator–Prey Interactions using High-Speed Video and Accelerometry, Integrative and Comparative Biology, Volume 55, Issue 4, October 2015, Pages 719–727 ↩
-
Svendsen, Morten & Domenici, Paolo & Marras, Stefano & Krause, Jens & Boswell, Kevin & Rodriguez-Pinto, Ivan & Wilson, Alexander & Kurvers, Ralf & Viblanc, Paul & Finger, Jean & Steffensen, John. (2016). Maximum swimming speeds of sailfish and three other large marine predatory fish species based on muscle contraction time and stride length: A myth revisited. Biology Open. 5. bio.019919. 10.1242/bio.019919. ↩
-
Iosilevskii, G., & Weihs, D. (2008). Speed limits on swimming of fishes and cetaceans. Journal of the Royal Society, Interface, 5(20), 329–338 ↩
-
ちなみにこのトレイトを使用する場合、あらかじめレンダリング後の文字列の長さの最大値を知っておく必要があります。 ↩