この記事は Azure Advent Calendar 2020 - Qiita の 22 日目の記事です。
Azure Form Recognizer の日本語 OCR は実際どれくらいの精度なのでしょうか?ビルド済みモデルは使えるのでしょうか?
今回はビルド済みの請求書モデルと、レイアウト&テーブル機能で試してみます。検証に使うデータは画像検索で拾ってきたサンプルのものです。
Form Recognizer のドキュメント - クイック スタート、チュートリアル、API リファレンス - Azure Cognitive Services | Microsoft Docs
Sample UI Tool: Analyze - Form OCR Testing Tool
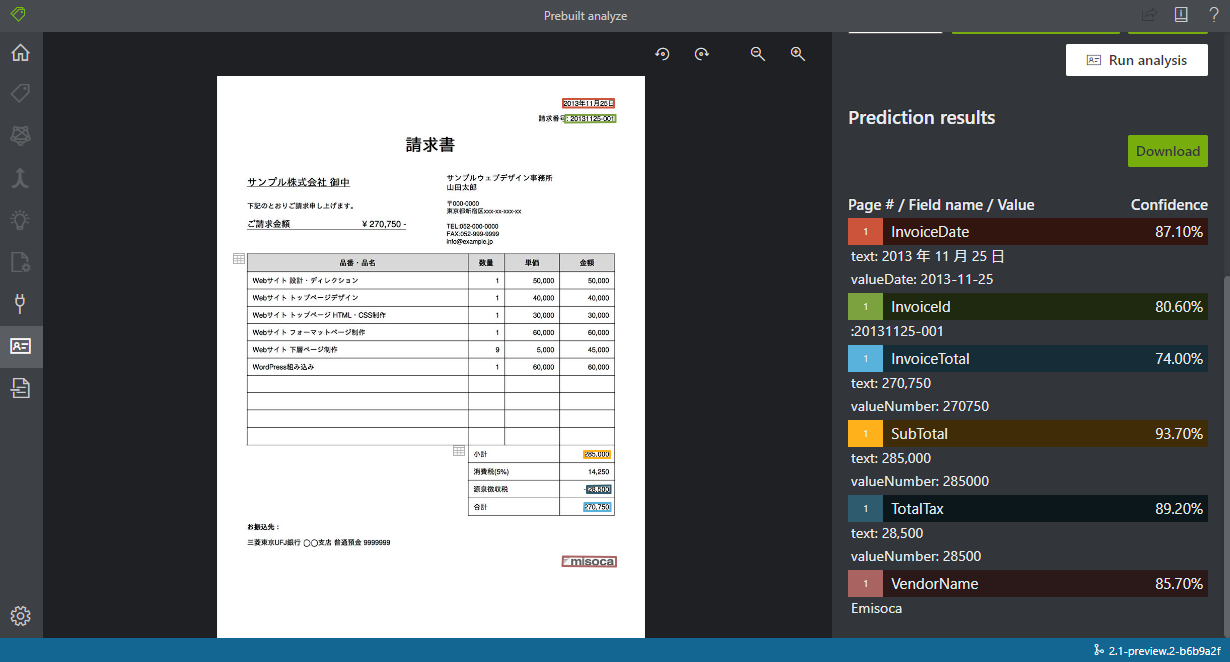
請求書モデル
検出出来た項目は請求日、請求書 ID, 合計、小計、税額、業者名の 6 つで、税額のみ違うかなと思いました。また、英語だと請求先の住所だったり電話番号なども検出できるので、そのまま使うのは少し物足りないかなと思います。
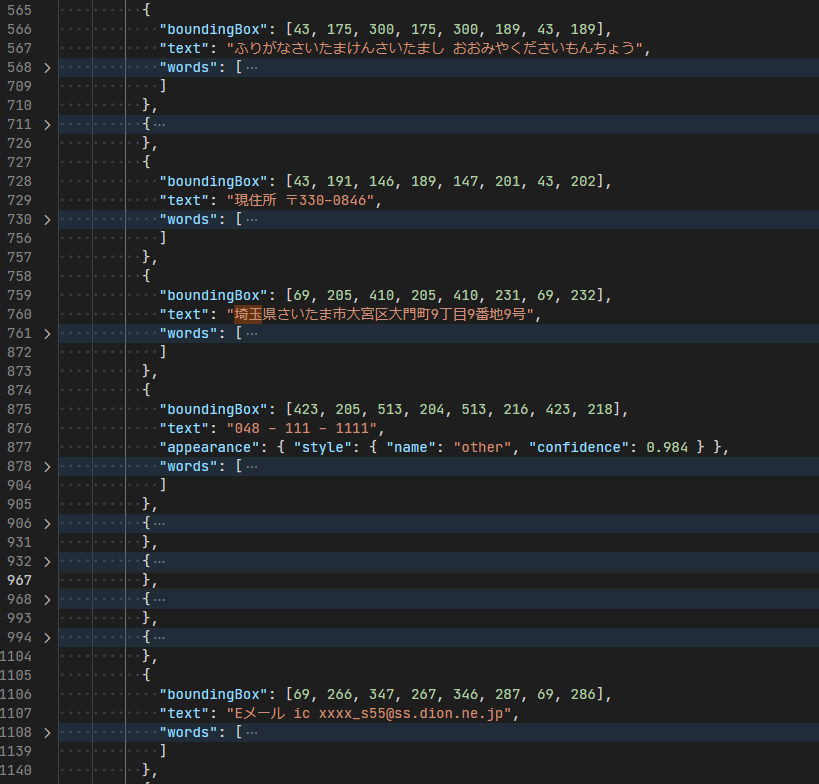
テーブルレイアウトで検出されている日本語や、請求書ではなくただの日本語として検出されている部分は普通に使えそうです。漢字とカタカナの間などに変なスペースが存在することが比較的多いように見えるので、スペースは削る必要がありそうです。
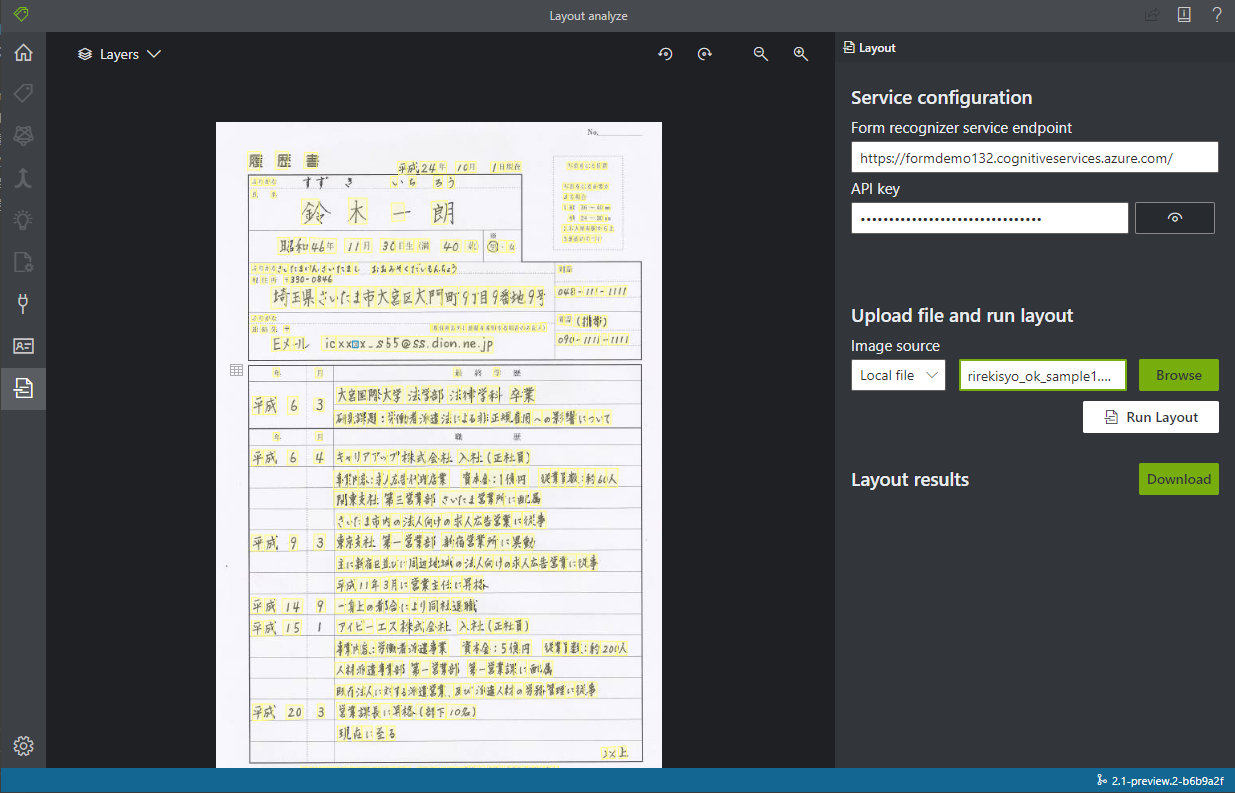
レイアウト&テーブル
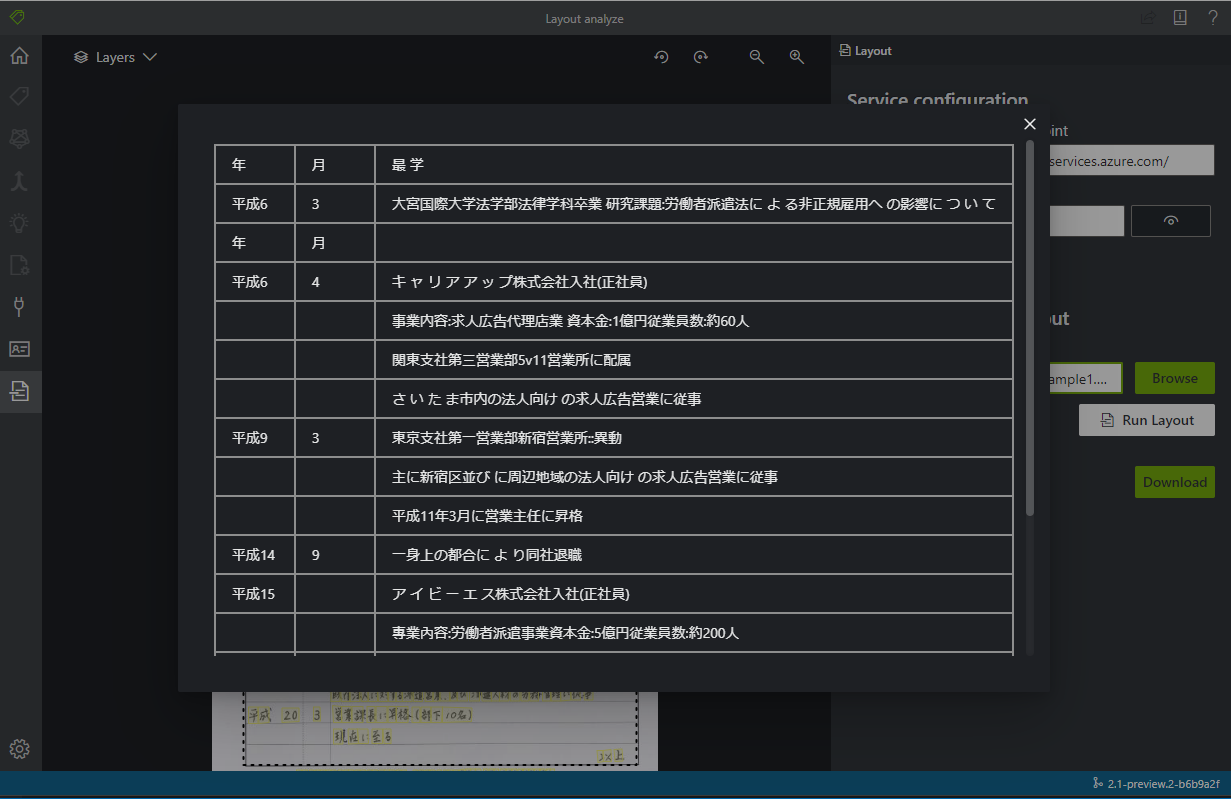
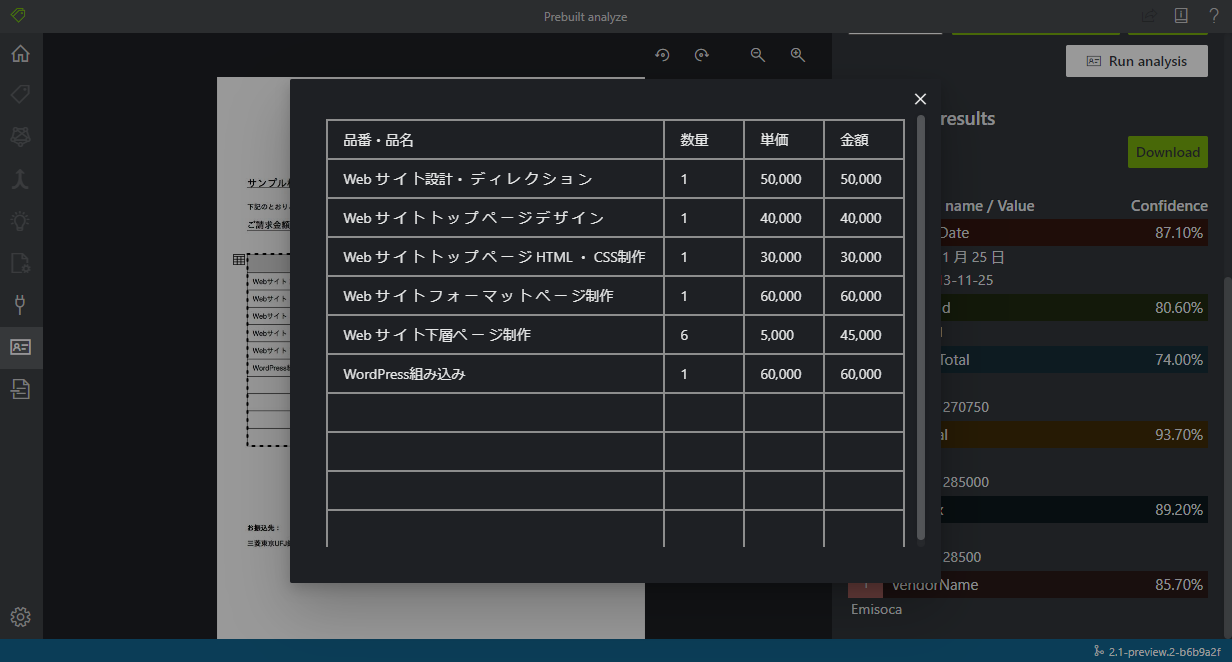
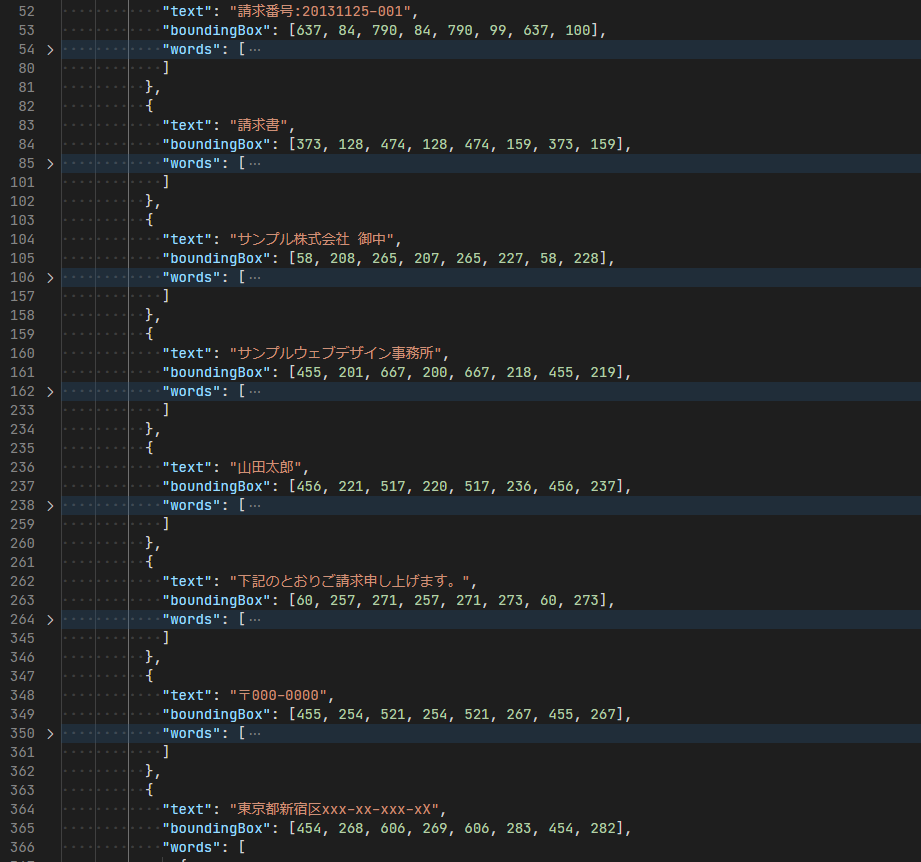
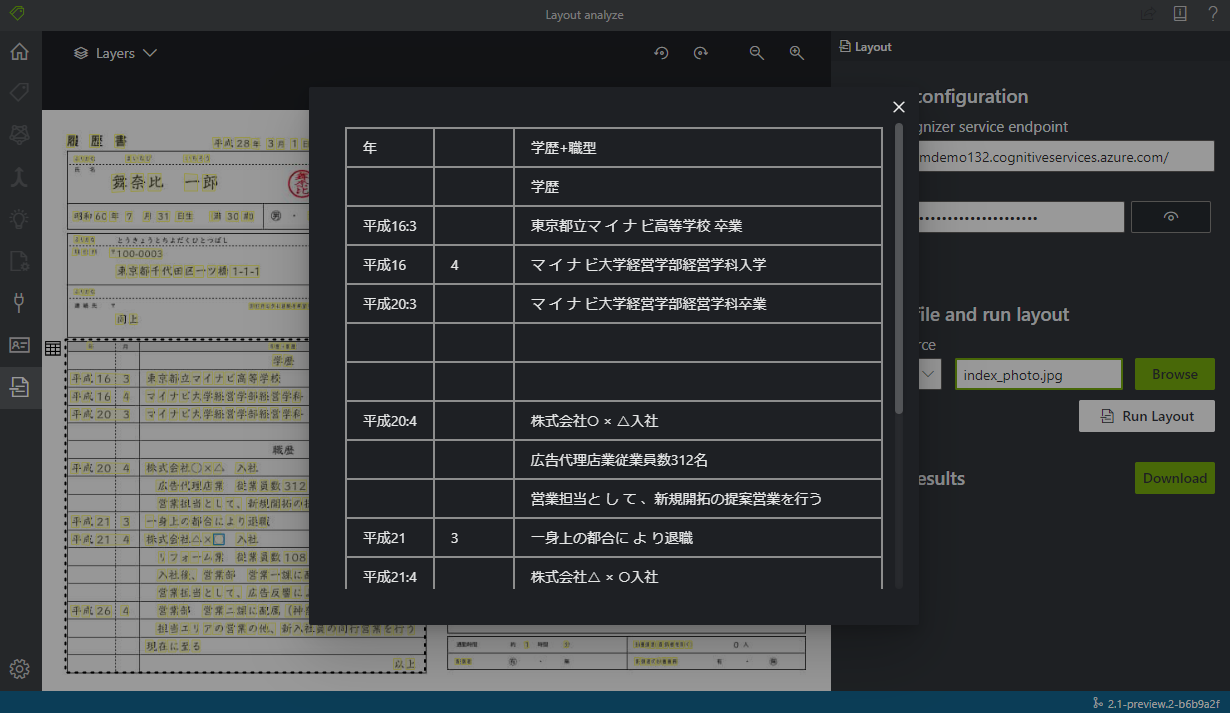
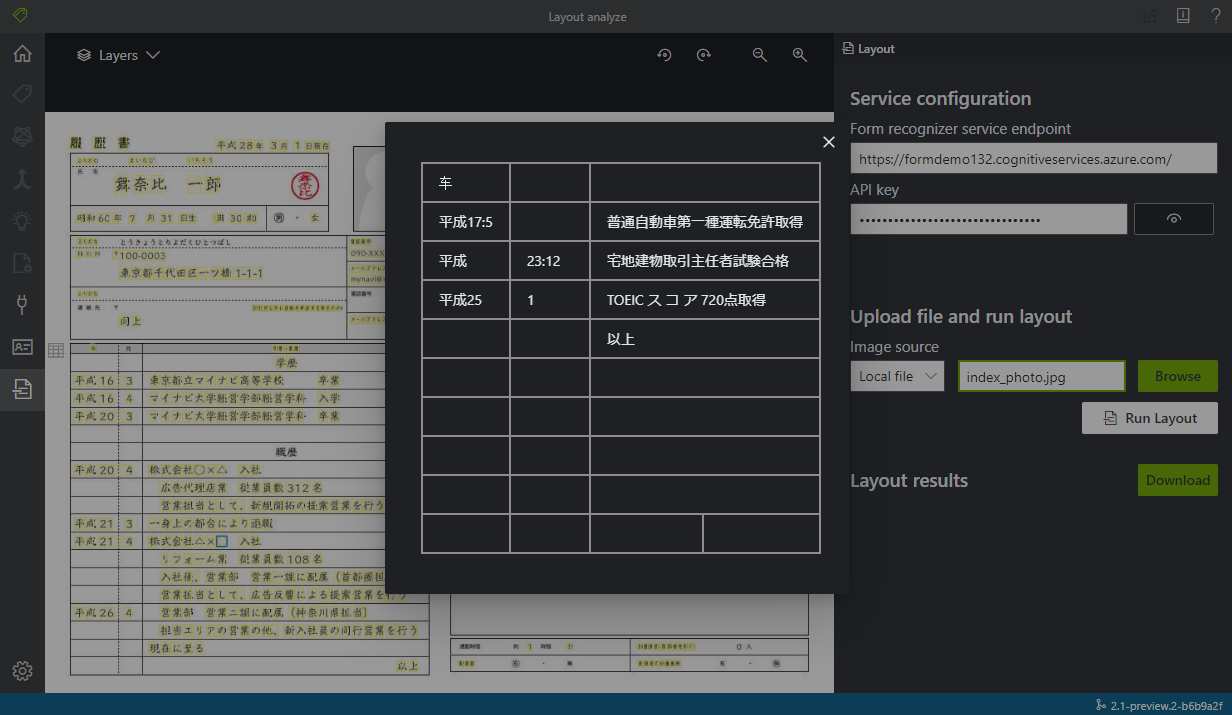
黄色マーカーが文字として検出された部分です。また二つのテーブルが検出されています。
大体の文字は正しく検出されていますが、一部抜けがあったり、テーブルを区切っている波線が : として文字検出されていたりしますね。このサンプル画像が 950 x 710 pixel なので、少し文字が潰れてしまう解像度なのも原因かもしれません。 PDF ではまた違った結果になるようにも思えます。
それと志望動機の大枠レイアウトは一行ずつ文字が検出されるようです。これを一つの文章として認識させたいなら位置判定の処理を書かないといけませんね。個人的な希望ではテーブルと同じく枠ごとに検出されて、一つの文章で検出されて欲しかったです。
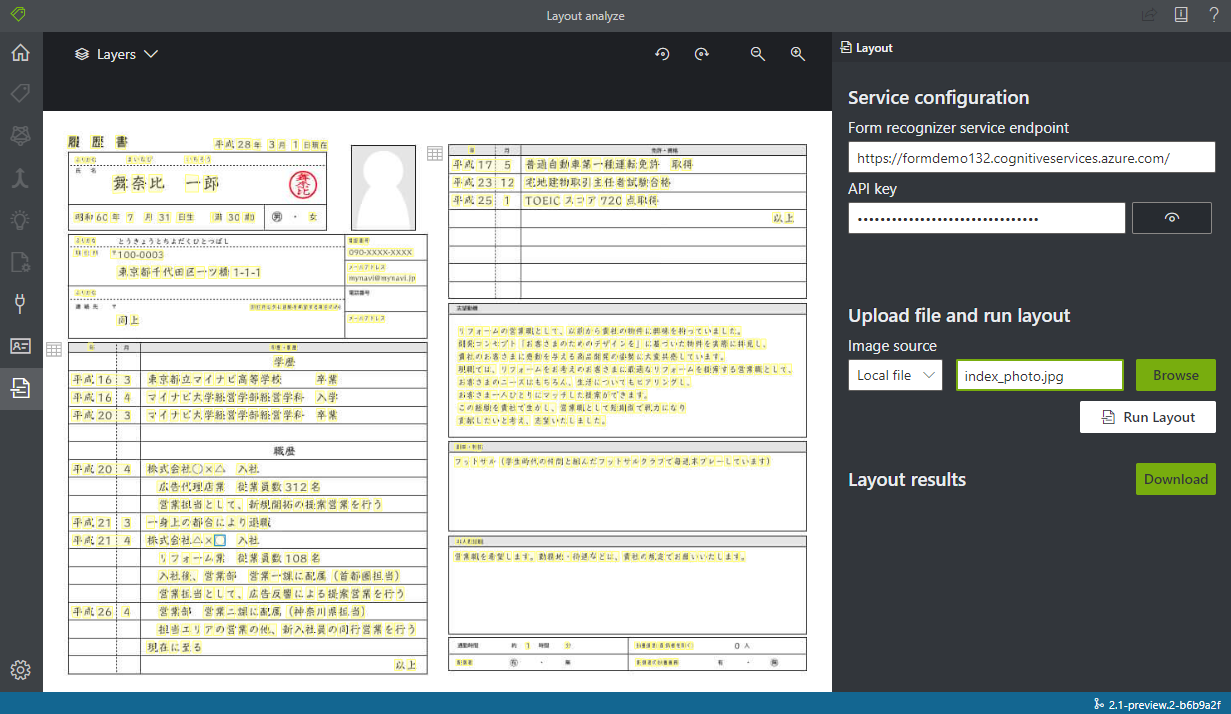
手書きの文字を検出してみる
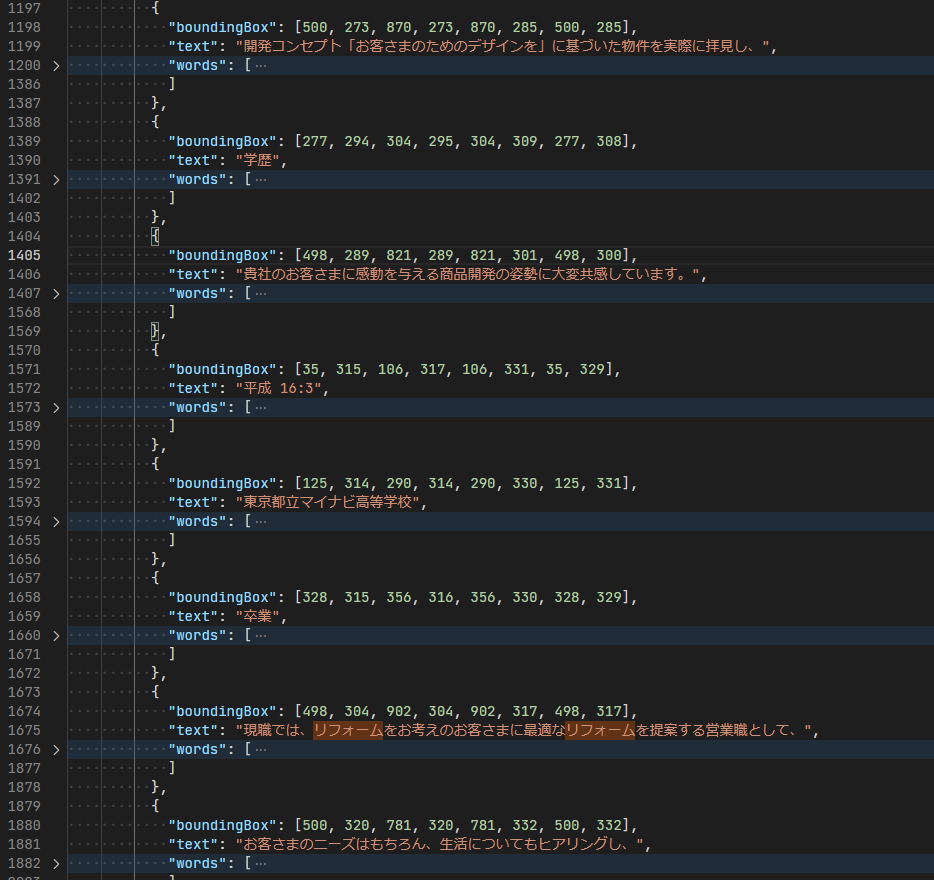
おまけです。この人は比較的字が上手いのか、ほぼ正しい日本語の検出されているように見えます。
今回は載せませんが、僕みたいに凄く文字が適当な人だとかなり適当に検出されてしまうため要注意です。この精度でダメな場合はもっと高精度な OCR を使って手書き→文字データ(検出されやすいフォント)に変換して、その後 Form Recognizer を使う、などが必要ですね。