SJISで出力したつもりが、UTF8で出力される...
以下のようなケースの際に文字列がSJISで出力できず結構沼ったので備忘として残しておきます。
- SJISのテキストファイルを読み込む
- Powershellで文字列編集する
- 編集したファイルを出力する
一般的にPowershellでSJIS出力Out-Fileコマンドレットの"-Encocing"を”Default"指定する方法が挙げられますが、
自分の場合、この方法で出力するとUTF8でファイルが出力されてしましました。
結論
日本語が含まれていないテキストを"-Encoding Default"で出力してもUTF8扱いとなる。
実例
実際にSJISファイルから日本語が含まれていない文字列のみを出力したファイルの文字コードを確認します。
SJISファイルの作成
まずSJISのテキストファイルを作成します。
ファイル名:sjis.txt
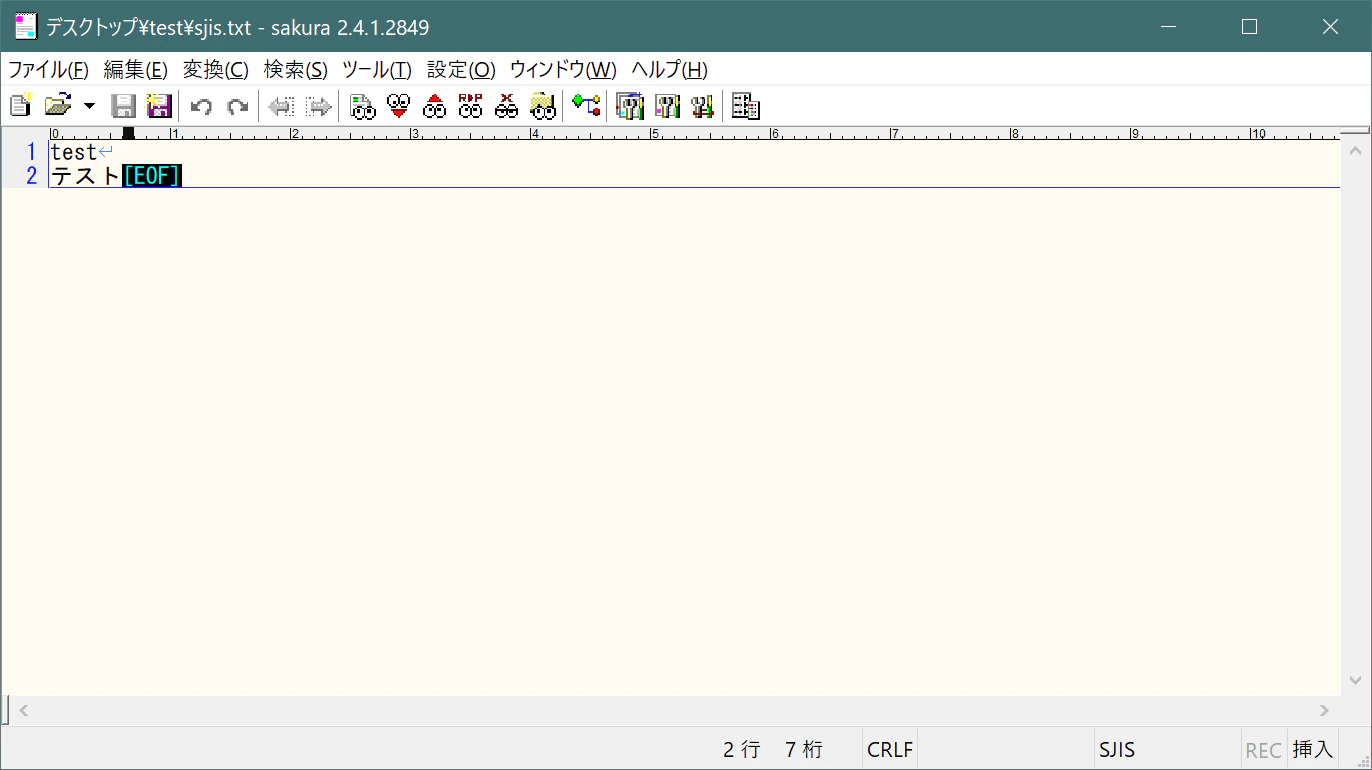
尚Windows10標準のメモ帳だとSJISはANSI表記になります。
文字列の抽出
以下のコマンドラインで前出の"sjis.txt"から文字列"test"を抽出し、
ファイル名"extract.txt"として出力します。
※カレントディレクトリは"sjis.txt"を内包するディレクトリとする。
Get-Content ".\sjis.txt" | ? {$_ -eq "test"} | Out-File -Encoding default ./extract.txt
この際に"-Encoding"オプションのパラメータを"Default"にします。
尚、このDefaultの値はシステムでアクティブとなっているコードページが使われるようです。
アクティブとなっているコードページは以下のコマンドで確認できます。
> chcp
現在のコード ページ: 932
> $OutputEncoding.WindowsCodePage
932
CP932はShift-JIS規格を基にマイクロソフトが独自に拡張したもので、
まぁとりあえずWindowsでのSJISの実装なんだと解釈しております。
もしDefaultのコードページが異なる場合、"-Encoding default"でSJIS出力されないので注意が必要です。
出力されたファイルを確認する
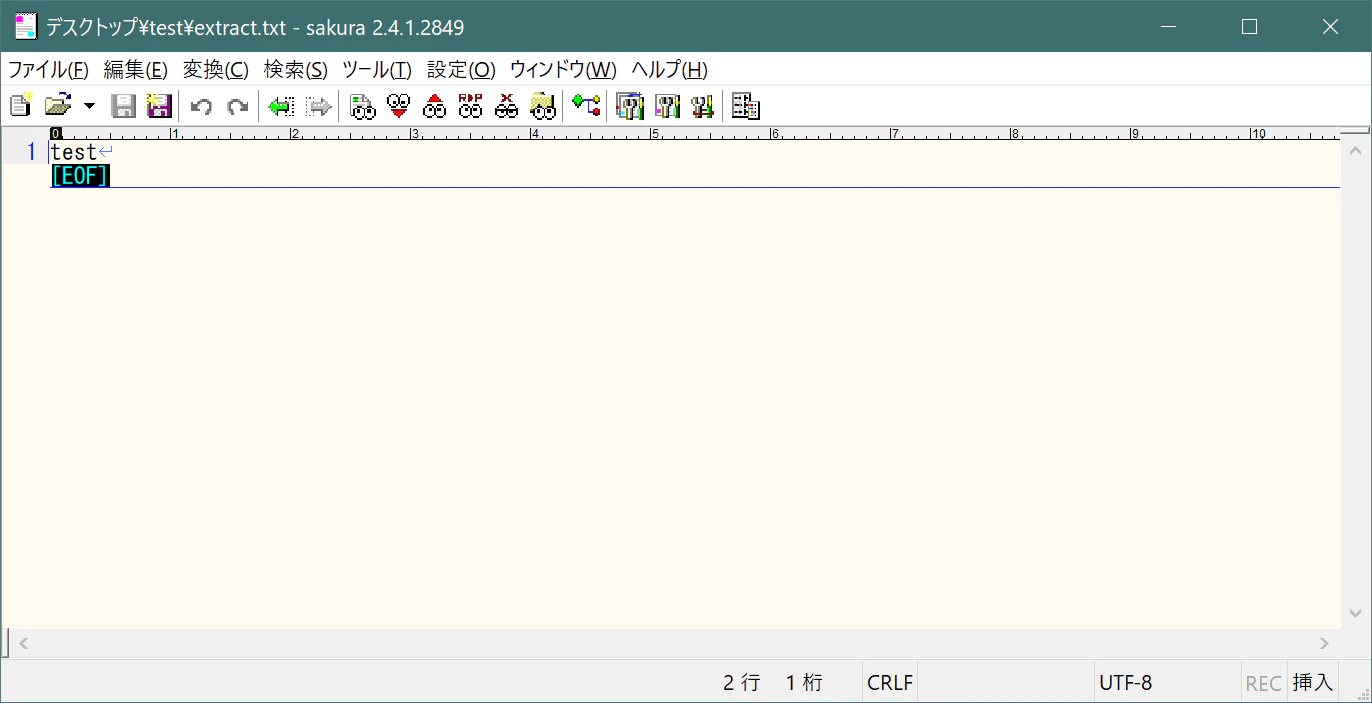
文字コードがUTF-8に変わっています。
ファイルに日本語を追記する
先ほどUTF-8と化したテキストファイルに対して、
以下のコマンドを実行し日本語を追記します。
Add-Content .\extract.txt -Value "テスト" -Encoding Default
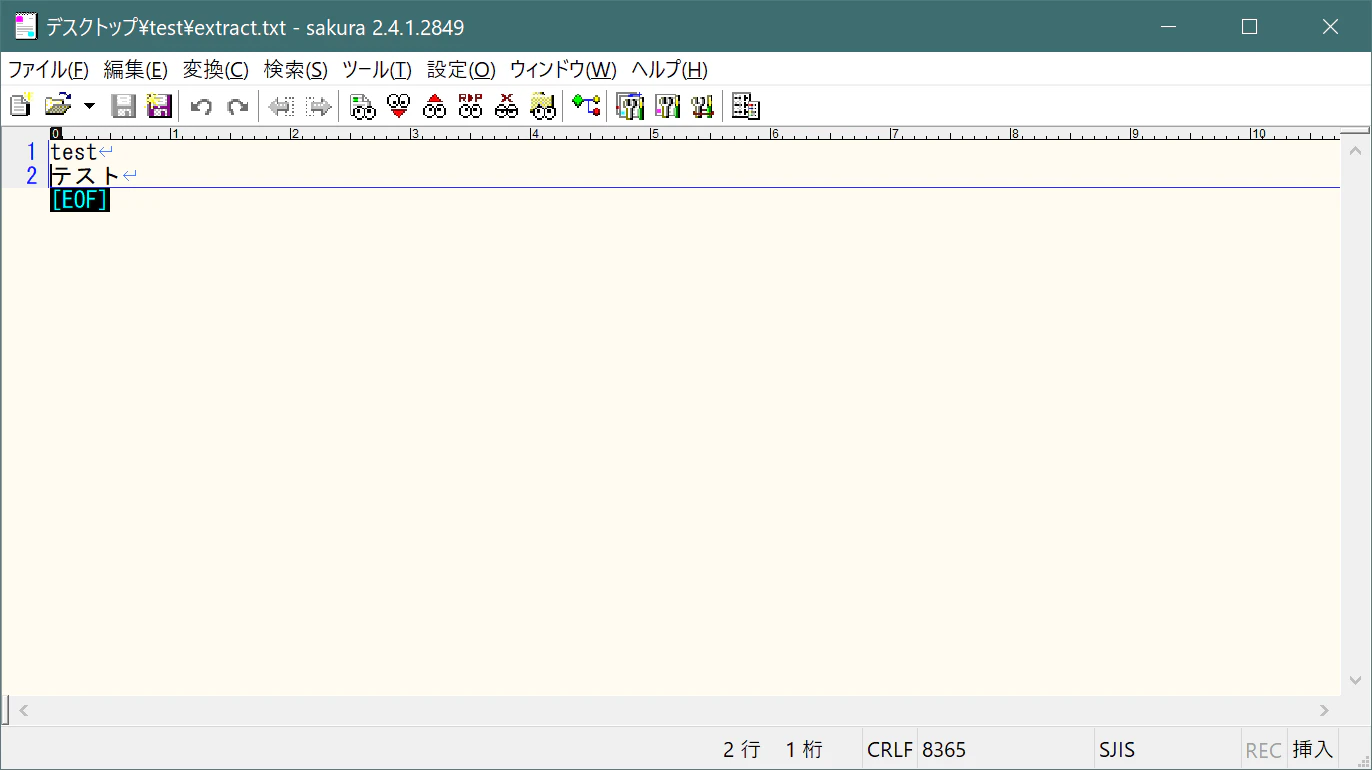
あら不思議
ファイルがSJISに変わってますね。
要因
UTF8もSJISもASCIIに対する後方互換があるため。
実はUTF8もSJISも7bit(0~127)までが共通である。
この範囲はASCIIコードの範疇でであり、アルファベットなど一部文字コード同じなのである。
故にアルファベットのみのテキストなどASCIIの範疇の場合は文字コードの判別が正しくできない。
もっと言えばどちらにも解釈できると言った方が正確かもしれない。
BOMのような仕組みがあれば、
テキストエディタはそれをもとに文字コードを判別するが、
BOMが無い場合などはエディタ各々のアルゴリズムに則り自動判別される模様。
先述の例の場合、
- 元のファイル「sjis.txt」から文字列"test"を抽出したファイル「extract.txt」はASCIIコード圏内のため、UTF8ともSJISともとれる。
- 実際にどちらで認識するかはエディタなどアプリ側の判別方法による。
- 日本語で文字列を追記することで、SJISとして認識される。アルファベットはASCIIコード圏内のためUTF8からSJISに解釈が移っても文字化けは起こらない。
こんなところでしょうか。
余談
細々した疑問はあるのだけれど一旦腑に落ちました。
また余裕のあるときにも掘り下げたいなと思います。
文字コードの世界は奥深く難しいですね。
参考